实时检测模型yolo-最简单的检测模型
You Only Look Once: Unified, Real-Time Object Detection
论文链接:https://arxiv.org/pdf/1506.02640.pdf
yolo官网:https://pjreddie.com/darknet/yolo/
摘要
提出yolo是一个目标检测模型。之前做目标检测是在已有的检测结果上再做分类,而yolo模型把目标检测看成一个回归问题处理,每张图片被分解成若干个独立的边界框并预测所属类别概率。使用一个简单的神经网络只需评估一次就能直接从所有图片中预测边界框和所属类别的概率。由于整个检测过程是在一个简单的网络中进行,所以可以端对端的直接优化检测性能。
统一网络结构很快。基础的yolo模型处理图像速度为45帧每秒。简易版yolo,即fast yolo,处理图像速度为155帧每秒,而且mAP值是其他实时检测模型的两倍以上。与现在最新的检测系统相比,yolo模型的定位错误率更高,但是不会将背景预测成物体。最后,yolo模型学习到物体非常通用的特征。当从自然图像迁移到其他领域,如艺术领域,yolo模型比DPM和R-CNN等模型检测结果好。
yolo模型
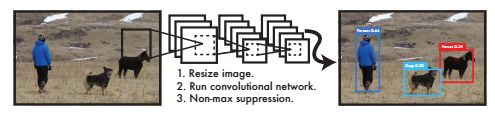
Yolo处理图像是简单直接的,具体步骤如下:
- 将输入图像调整尺寸为448*448;
- 将输入图像读入设计的简单的卷积神经网络中;
- 通过模型置信度设置检测结果的阈值。
Yolo很简单只需一个简单的神经网络就能预测多边界框和分类概率。Yolo训练所有图片并优化检测性能。yolo比传统检测算法的优点有:(1)yolo实时性好;(2)当一个网格中存在一组概率值时,yolo模型不考虑网格的个数B,在预测的时候会分析整个图片信息;(3)yolo模型会学习目标的通用特征。但是yolo模型也有其缺点,它的准确率不是目前模型中性能最好的,yolo能快速的识别物体,但是很难精确定位一些局部目标,例如非常小的目标。
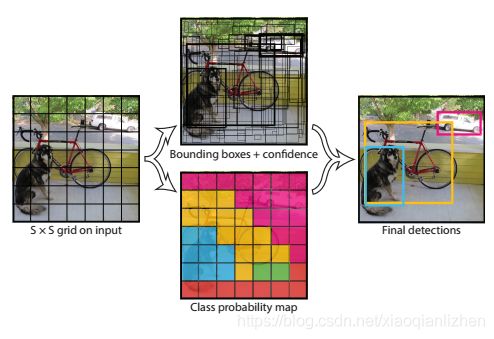
如上图图片被划分成S*S的网格,那么输出的张量个数为:S*S*(Box*5+Class),其中Box是框数,Box*5代表每个框需要预测5个张量,分别是框的坐标x,y和框的长宽w,h以及box置信度,Class是需要预测的总类别数。
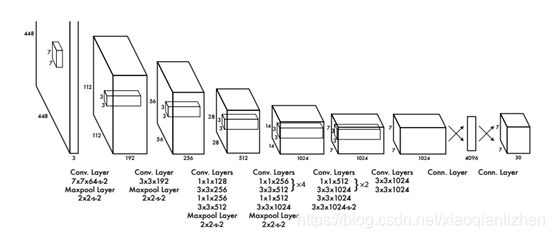
Yolo的网络结构共由24个卷积层和2个全连接层组成,交替进行1*1卷积以降低特征空间。在ImageNet分类任务上使图片分辨率为原先一般重新训练卷积层,再使用双倍分辨率图片做检测。
损失函数可以表示为:f=目标的定位预测误差+目标预测置信度误差+背景预测置信度误差+分类预测误差,具体公式如下。
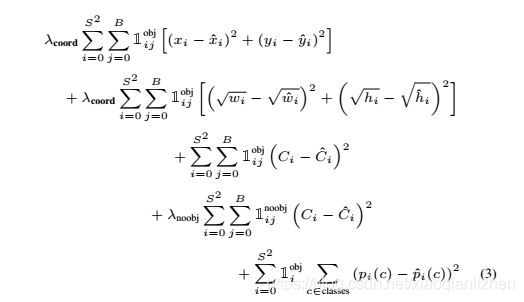
实验
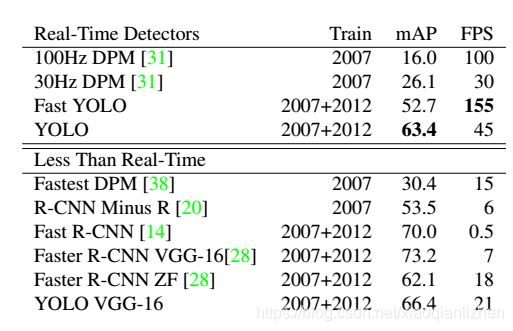
在PASCAL VOC检测上,比较快速检测模型的性能和速度,fast YOLO是速度最快的检测器,准确率是其他实时检测模型的两倍以上。而YOLO模型的准确率比fast YOLO模型高10mAP,但实时性不如fast YOLO。
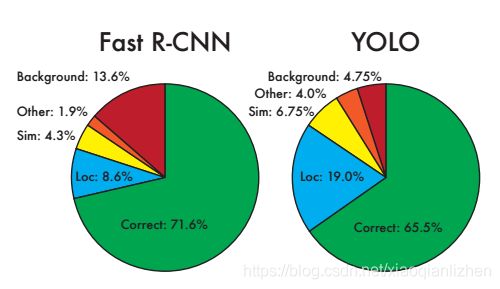
通过与fast R-CNN模型比较,可以知道yolo模型的定位能力要比fast R-CNN差,但是yolo模型对于背景误判成物体的错误率要比fast R-CNN低很多。

考虑yolo将背景误判为物体的概率低的特点,考虑联合yolo模型和fast R-CNN,使fast R-CNN模型预测的结果和yolo的结果对比,使准确率 单一fast R-CNN模型提高3.2%。
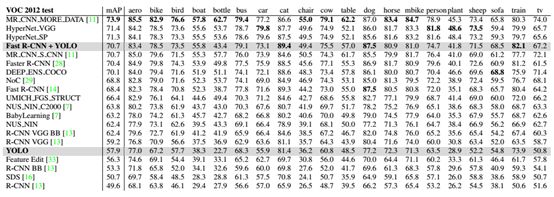
各种检测模型在PASCAL VOC 2012数据集上的性能比较。yolo和fast R-CNN的联合模型性能排第四,比fast R-CNN提高2.3%。并且yolo是个实时监测模型。而对于小目标场景较少的数据集中性能会提升不少。
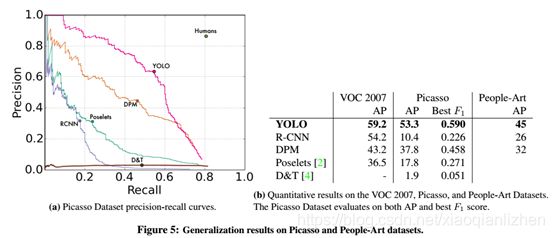
各个模型在Picasso数据集预测召回率曲线图,可以发现yolo模型的召回率是除了人工判别之外最高的。并且比较各个模型在不同数据集中的性能,发现yolo在Picasso数据集中性能最好。

实验Yolo模型在简单的艺术图像和自然景观图像,准确率非常高,但是会把在飞的人误判成飞机。
结论
Yolo模型结构简单并且可以直接用来训练,在艺术作品或没有小目标的检测任务中检测效果好。设计fast yolo模型,是目前实时性最好的模型。所以可以认为yolo模型适合应用于实时性要求高,进行粗鲁目标检测的任务中。
代码地址:https://github.com/pjreddie/darknet
测试步骤:
(1)git clone https://github.com/pjreddie/darknet
(2)cd darknet
(3)make
(4)wget https://pjreddie.com/media/files/yolov3.weights
(5)./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg or ./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
(6)wget https://pjreddie.com/media/files/yolov3-tiny.weights
(7)./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
重训练步骤:
(1)wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
(2)wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
(3)wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
(4)tar xf VOCtrainval_11-May-2012.tar
(5)tar xf VOCtrainval_06-Nov-2007.tar
(6)tar xf VOCtest_06-Nov-2007.tar
(7)wget https://pjreddie.com/media/files/voc_label.py
(8)python voc_label.py
(9)cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
(10)vim cfg/voc.data,修改如下内容
1 classes= 20
2 train =
3 valid =
4 names = data/voc.names
5 backup = backup
(11)wget https://pjreddie.com/media/files/darknet53.conv.74
(12)./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
我的实验结果:用于奶牛的检测和识别,为减少工作量只标注了其中6头奶牛。下图是检测识别效果图。
原图像:

预测结果:

视频演示效果: