AutoEncoder是什么?
AutoEncoder (AE) 自编码器
1 概述
- AE是一种无监督学习模型,不需要带标签的数据
- AE包含两部分,Encoder编码器 和 Decoder解码器;模型架构如下图所示:
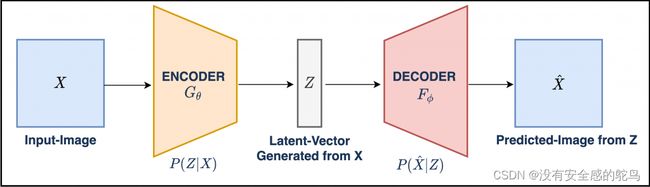
- 如上图所示:输入X经过编码器,生成潜在向量Z;Z经过解码器,生成x_hat; 模型的误差为输入X和输出X_hat的误差(通常被称为重构误差),通过误差的反向传播,梯度优化,最终得到训练好的自编码器。
2 AutoEncoder的特点
- 这里可能就有一个问题,就是我辛辛苦苦从X->Z,为什么还要从Z->X_hat,还要让X与X_hat尽可能接近,这不是白忙活一阵么?
- AE希望通过编码器得到 输入 X 的主要信息 Z,以达到 【数据降维】 的目的
- 那么如何知道编码后的数据是否保留了较完整的信息呢?如果 Z 能够较容易地通过解码恢复成原始数据(即X_hat 与 X 尽可能地接近),那么就认为Z 较好地保留了 输入X的信息,我们就得到了一个能够实现 【特征提取】 功能的编码器
- AE与CNN、RNN的区别?
- 与其说AE是一种新的模型,不如说AE是一种框架
- Encoder和Decoder可以是神经网络的一层或好几层;神经网络的每一层都是是一个权重矩阵;其中Encoder和Decoder可以是全连接层(Dense),卷积层(CNN),循环神经网络层(RNN),也可以是他们的组合
3 AutoEncoder的几种实现
- 1、2 的编码器和解码器不同;3为具体应用(心电图异常检测);4为变分自编码器(VAE),编码器解码器用的是卷积神经网络
- 文中代码均为节选片段,为了方便理解模型架构;完整代码可评论留下邮箱发。
3.1 基础自编码器【Encoder & Decoder都是全连接层】
- 最普通的AutoEncoder的Encoder和Decoder都是全连接层(Dense)
- 以MNIST数据集为例,MNIST是大型手写数字数据库,包含60,000训练集以及10,000测试集,每个数据是大小为(28, 28)的图片;构造基础AutoEncoder
#1 基本AE
# 具有两个Dense层的AE,encoder将图像压缩为64维潜在向量,decoder从潜在空间重建原始图像
latent_dim = 64 # 潜在向量大小
class Autoencoder(Model):
def __init__(self, latent_dim):
super(Autoencoder, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential([
layers.Flatten(), # 将(28,28)展平为(784,)
layers.Dense(latent_dim, activation='relu'), # 全连接层,输出为(64,)激活函数为ReLU
])
self.decoder = tf.keras.Sequential([
layers.Dense(784,activation='sigmoid'), # 全连接层,输出为(784,),激活函数为Sigmoid
layers.Reshape((28,28)) # 将(784,)转换为(28,28),实现重构
])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
# 模型训练
autoencoder = Autoencoder(latent_dim)
autoencoder.compile(optimizer='adam', loss=losses.MeanSquaredError()) # 重构误差 均方误差
autoencoder.fit(x_train, x_train, # 输入 和 真实值是一样的,都是X,要计算预测值X_hat 和 X的误差
epochs=10,
shuffle=True,
validation_data=(x_test, x_test))
3.2 降噪自编码器【Encoder & Decoder都是卷积神经网络】
- 为了缓解基础自编码器容易过拟合的问题;能够训练出能自动去噪声的自编码器
- 输入是加了噪声的数据X_noisy,真实值为没加噪声的原始数据X,Loss为AE预测数据X_pred和真实值X的重构误差;这里的Encoder和Decoder 都是卷积神经网络;依旧是以MNIST数据集为例
#2 图像去噪
# 向图像添加随机噪声
noise_factor = 0.2
x_train_noisy = x_train + noise_factor * tf.random.normal(shape=x_train.shape)
x_test_noisy = x_test + noise_factor * tf.random.normal(shape=x_test.shape)
# 卷积自动编码器
class Denoise(Model):
def __init__(self):
super(Denoise, self).__init__()
self.encoder = tf.keras.Sequential([
layers.Input(shape=(28,28,1)),
layers.Conv2D(16,(3,3), activation='relu', padding='same', strides=2), # 输出通道数为16,卷积核大小为(3,3)
layers.Conv2D(8,(3,3), activation='relu', padding='same', strides=2) # 激活函数、填充、步长
])
self.decoder = tf.keras.Sequential([
layers.Conv2DTranspose(8, kernel_size=3, strides=2 , activation='relu', padding='same'), # 相当于卷积的逆操作
layers.Conv2DTranspose(16, kernel_size=3, strides=2, activation='relu', padding='same'),
layers.Conv2D(1, kernel_size=(3,3), activation='sigmoid', padding='same')
])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
# 降噪AE-Conv
autoencoder1 = Denoise()
autoencoder1.compile(optimizer='adam', loss=losses.MeanSquaredError())
autoencoder1.fit(x_train_noisy, x_train, # 输入为带噪声的X_noisy,真实值为X
epochs=10,
shuffle=True,
validation_data=(x_test_noisy, x_test))
3.3 心电图异常检测【Encoder & Decoder都是全连接层】
- 异常检测的原理:以正常数据作为训练集,训练得到一个能辨识、重构 正常心电图 的自编码器【即输入正常的心电图,能输出正常的心电图,输出接近输出】,默认异常心电图 与 正常心电图之间存在不同。故当输入异常心电图时,模型的输出 和 真实值会有较大的误差,因为模型是基于正常数据训练的。
history = autoencoder2.fit(normal_train_data, normal_train_data, # 以正常数据作为训练集
epochs=20,
batch_size=512,
validation_data=(test_data, test_data),
shuffle=True)
# 如果重构误差高于训练集的一个标准偏差,则将该示例分类为异常。
# 训练集的重构误差
reconstructions = autoencoder2.predict(normal_train_data)
train_loss = tf.keras.losses.mae(reconstructions, normal_train_data) # 所有的重构误差
# 选择一个比平均值高一个标准差的,作为阈值
threshold = np.mean(train_loss) + np.std(train_loss)
# 如果重构误差大于阈值,则将ECG分类为异常
def predict(model, data, threshold):
reconstructions = model(data)
loss = tf.keras.losses.mae(reconstructions, data)
return tf.math.less(loss, threshold) # 比较大小
preds = predict(autoencoder2, test_data, threshold) # 结果,正常or异常
3.4 变分自编码器VAE【Encoder & Decoder都是卷积神经网络】->CVAE
- VAE是一种生成模型,也是在AutoEncoder这个框架之下,但是涉及生成模型相关公式推导,较为复杂,后续更新……
4 引用
https://blog.csdn.net/qq_39521554/article/details/80697882
https://roguesir.blog.csdn.net/article/details/77469665?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-77469665-blog-80697882.pc_relevant_antiscanv2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-77469665-blog-80697882.pc_relevant_antiscanv2&utm_relevant_index=2
https://zhuanlan.zhihu.com/p/58111908
https://zhuanlan.zhihu.com/p/34238979
https://zhuanlan.zhihu.com/p/68903857
https://zhuanlan.zhihu.com/p/133207206