BEV常见的开源算法 | BEV空间的生成(BEVFormer/PersFormer等)
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【3D目标检测】技术交流群
后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述!

BEV感知系列分享是整数智能推出的一个全新分享系列,在这个系列中,我们将介绍BEV感知相关的算法和数据集等内容。
BEV常见的开源算法系列
BEV空间的生成
BEV下的多模态融合
BEV下的时序融合
在本系列中,我们将介绍截至目前为止发布的优秀BEV算法。我们将该系列分为BEV空间的生成、BEV下的多模态融合算法、BEV下的时序融合算法。
本篇将从BEV空间的生成算法开始,介绍BEV算法的发展历史,并且重点介绍基于Transformer的BEV空间生成算法。这些算法开创性地使用Transformer更高效,更精确地生成BEV空间。
BEV算法的发展历史
在 BEV空间中,传统的 BEV变换算法通常是在图像空间中进行特征提取,并产生分割结果,再利用逆透视变换(IPM)将其转化为 BEV空间。
IPM的功能是消除视觉上的影响,比如,在自动/辅助驾驶中,因为在前视的照相机拍摄的图像中,原本平行的物体会因为透视的原因而发生交叉。
IPM是把影像与 BEV空间连接起来的一种简便、直接的方式,要得到一幅影像的 IPM,就必须了解摄像机的内参(焦距、光心)和外参(俯仰角、偏航角和地面高度)。在这个过程中,摄像机必须保持俯仰角,但这种约束太严格,难以在实际应用中得到满足。同时,由于参数的变化,会引起系统对物体的感知能力的变化,从而降低视觉质量,造成平行车道之间的夹角。
为减小俯仰角对视觉的影响,在改进后的算法中,采用了摄像机的实时位姿,并将俯仰校正添加到相邻的帧中,这样可以获得较好的逆变换效果,但由于实时位姿难以精确地获得,因而无法获得最理想的结果。
这两年BEV相关算法的发展让深度学习应用于BEV空间转换的方式逐渐成为主流。与以往的算法相比,利用神经网络进行二维 BEV空间变换可以获得更好的视觉效果。
该方法主要流程是:首先利用主干网对各个摄像机进行特征提取,再利用 Transformer等将多摄像机数据从图像空间转化为 BEV空间。在 BEV空间中,由于利用同一坐标系统,可以很方便地将 Lidar、 Radar等传感器数据与其他传感器数据进行融合,还可以进行时序融合形成4D空间,这也是当下BEV技术的大趋势。
基于Transformer的PV2BEV算法
01 BEVFormer
【论文地址】
https://arxiv.org/abs/2203.17270
【简介】
BEVFormer可以有效地聚合来自多视角摄像机的时空特征和历史BEV特征。由BEVFormer生成的BEV特征可以同时支持多种三维感知任务,如三维物体检测和地图分割,这对自动驾驶系统是很有价值的。
【算法结构】

BEVFormer网络结构
BEVFormer网络结构如上图所示,它有6个编码器层,除BEV查询,空间交叉注意和时间自我注意三种定制设计外,每个编码层都遵循Transformer的常规结构。
BEV Queries
作者预先设定了一组网络形状的可学习的参数![]() 作为BEVFormer的queries。其中H和W是BEV平面的空间尺寸。具体来说,查询
作为BEVFormer的queries。其中H和W是BEV平面的空间尺寸。具体来说,查询![]() 在
在![]() 处,Q负责BEV平面中相应的网络单元区域。每个BEV平面中的网络单元对应于s米的真实大小。BEV特征的中心在默认情况下对应于ego car的位置。按照常见的做法,数据输入BEVFormer之前,向BEV queries Q添加了可学习的位置编码。
处,Q负责BEV平面中相应的网络单元区域。每个BEV平面中的网络单元对应于s米的真实大小。BEV特征的中心在默认情况下对应于ego car的位置。按照常见的做法,数据输入BEVFormer之前,向BEV queries Q添加了可学习的位置编码。
Spatial Cross-Attention
作者设计了一种空间交叉注意力机制,使BEV queries从多相机特征中通过注意力机制提取所需的空间特征。由于本方法使用多尺度的图像特征和高分辨率的BEV特征,直接使用最朴素的global attention会带来无法负担的计算代价。因此作者使用了一种基于deformable attention的稀疏注意力机制使每个BEV query和部分图像区域进行交互。具体而言,对于每一个位于(x, y)位置的BEV特征,我们可以计算其对应现实世界的坐标x', y'。然后作者将BEV query进行lift操作,获取在z轴上的多个3D points。有了3D points,就能够通过相机内外参获取3D points在view平面上的投影点。受到相机参数的限制,每个BEV query一般只会在1-2个view上有有效的投影点。基于Deformable Attention,我们以这些投影点作为参考点,在周围进行特征采样,BEV query使用加权的采样特征进行更新,从而完成了spatial空间的特征聚合。
Temporal Self-Attention
除了空间信息之外,时序信息对于视觉系统了解周围环境来说也是至关重要的。例如,在没有时间线索的情况下,推断运动物体的速度或者从静态图像中检测高度遮挡的物体是很有挑战性的。作者设计了Temporal Self-Attention通过结合BEV的历史特征表示当前的环境。
作者将BEV特征视为类似能够传递序列信息的memory,每一时刻生成的BEV特征都从上一时刻的BEV特征获取了所需的时序信息,这样保证能够动态获取所需的时序特征,而非像堆叠不同时刻BEV特征那样只能获取定长的时序信息。
【实验结果】
在3D目标检测任务上,BEVFormer在验证集上比以前最好的方法DETR3D高出9.2分(51.7% NDS vs. 42.5% NDS)。在测试集上,BEVFormer在没有附加条件的情况下取得了56.9%的NDS,比DETR3D(47.9%的NDS)高9.0个百分点。该方法甚至可以达到与一些基于LiDAR的基线相当的性能,如SSN(56.9% NDS)和PointPainting(58.1% NDS)。

 在nuScenes验证集上3D检测结果
在nuScenes验证集上3D检测结果
【标注demo视频】
02 PersFormer
【论文地址】
https://arxiv.org/abs/1912.04838
【简介】
作者提出一种端到端单目3D车道检测器,它具有基于变压器的空间特征转换模块。该模型以相机参数为参考,关注相关的前视局部区域生成BEV特征。PersFormer采用统一的2D/3D锚点设计和辅助任务同时检测2D/3D车道,增强了特征一致性,共享了多任务学习的好处。
【算法结构】
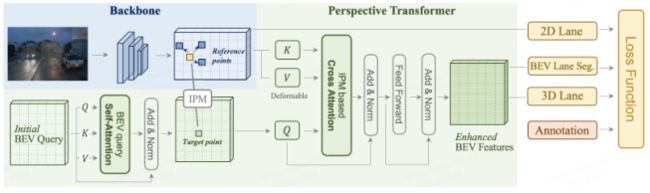
PersFormer网络结构
PersFormer整体结构如上图所示,由主干、透视变压器和车道检测头三部分组成。
主干以调整后的图像为输入,生成多尺度的前视图特征,其中采用流行的ResNet变体。
透视转换器以摄像机的前视图特征为输入,借助摄像机的内外参数生成BEV特征。作者不是简单地从正面视图向BEV投影一对一的特征对应,而是引入Transformer来关注局部上下文并聚合周围的特征,从而在BEV中形成一个健壮的表示。
车道检测头负责预测2D/3D坐标以及车道类型。
【实验结果】
 PersFormer超过之前的SOTA算法在整个验证集和每个场景集上获得了最高的F-Score
PersFormer超过之前的SOTA算法在整个验证集和每个场景集上获得了最高的F-Score
【标注demo视频】
03 CoBEVT
【论文地址】
https://arxiv.org/abs/2207.02202
【简介】
作者提出了第一个通用的多智能体多摄像机感知框架CoBEVT,假设所有智能体获取的信息是准确的,传输的信息是同步的,利用多个智能体之间的共享信息来获得整体的BEV分割图,协同生成BEV地图预测。为了在底层Transformer架构中有效地融合来自多视图和多代理数据的相机特征,作者设计了一个融合轴向注意(FAX)模块,它可以跨视图和代理捕获稀疏的局部和全局空间交互。
【算法结构】

CoBEVT的整体架构包括:
融合轴向注意(FAX):它作为SinBEVT和FuseBEVT的核心组件,用于高效地获得场景中的局部和全局属性
SinBEVT:用于BEV特征计算
FuseBEVT:用于多智能体特征压缩和共享
【实验结果】

基于OPV2V摄像机的地图语义分割

基于OPV2V激光雷达的3D目标检测
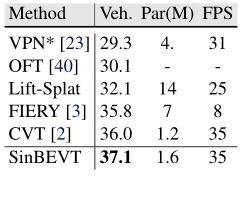
nuScene上的地图语义分割
往期回顾
首篇!无相机参数BEV感知!(北航、地平线)

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
