OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields 论文精读
OpenPose:使用部分亲和场的实时多人 2D 姿势估计
摘要
实时多人2D姿势估计是使机器能够理解图像和视频中人的关键组成部分。在这项工作中,我们提出了一种实时方法来检测图像中多人的 2D 姿势。所提出的方法使用非参数表示,我们将其称为部分关联场 (PAF),以学习将身体部位与图像中的个体相关联。无论图像中有多少人,这种自下而上的系统都能实现高精度和实时性能。 在以前的工作中,PAF 和身体部位位置估计在训练阶段同时进行了改进。我们证明了是“PAF 的细化”而不是“PAF 和身体部位位置的细化”导致运行时性能和准确性的显着提高。我们还展示了第一个组合的身体和足部关键点检测器,基于我们公开发布的内部带注释的足部数据集。我们表明,与顺序运行它们相比,组合检测器不仅减少了推理时间,而且还单独保持了每个组件的准确性。这项工作最终以发布 OpenPose 为高潮,这是第一个用于多人 2D 姿势检测的开源实时系统,包括身体、足部、手部和面部关键点。
1、 介绍
在本文中,我们考虑了获得对图像和视频中人物的详细理解的核心组件:人体 2D 姿势估计(或定位解剖关键点或“部分”的问题)。人体估计主要集中在寻找个体的身体部位。推断图像中多人的姿势提出了一系列独特的挑战。首先,每张图像可能包含未知数量的人,这些人可以出现在任何位置或比例。其次,由于接触、咬合或肢体关节,人与人之间的互动会导致复杂的空间干扰,从而使部件的关联变得困难。 第三,运行时复杂性往往会随着图像中人数的增加而增加,这使得实时性能成为一项挑战。
一种常见的方法是使用人员检测器并为每个检测执行单人姿势估计。这些自上而下的方法直接利用现有技术进行单人姿势估计,但受到早期承诺的影响:如果行人检测器失败,就像人们靠近时容易发生的那样,就无法恢复。此外,它们的运行时间与图像中的人数成正比,对于每个人检测,都会运行一个单人姿势估计器。相比之下,自下而上的方法很有吸引力,因为它们为早期承诺提供了稳健性,并且有可能将运行时复杂性与图像中的人数分离。然而,自下而上的方法并不直接使用来自其他身体部位和其他人的全局上下文线索。最初的自下而上方法([1]、[2])并没有保持效率的提高,因为最终的解析需要昂贵的全局推理,每张图像需要几分钟。
在本文中,我们提出了一种有效的多人姿势估计方法,在多个公共基准上具有良好的表现。我们通过 Part Affinity Fields (PAFs) 呈现关联分数的第一个自下而上表示,这是一组 2D 矢量场,用于编码图像域上肢体的位置和方向。我们证明,同时推断这些自下而上的检测和关联表示编码了足够的全局上下文,以便贪婪解析以一小部分计算成本获得高质量的结果。
该手稿的早期版本出现在 [3] 中。这个版本做出了一些新的贡献。 首先,我们证明 PAF 细化对于最大限度地提高准确性至关重要,而身体部位预测细化并不那么重要。我们增加了网络深度,但删除了身体部位的细化阶段(第 3.1 和 3.2 节)。这个改进的网络分别将速度和准确度提高了大约 200% 和 7%(第 5.2 和 5.3 节)。其次,我们展示了一个带有15K人脚实例的带标注的脚数据集1,该数据集已公开发布(第 4.2 节),并且我们表明,可以训练具有身体和脚关键点的组合模型,保持纯身体模型的速度,同时保持其准确性(第5.5节)。第三,我们通过将其应用于车辆关键点估计任务(第 5.6 节)来证明我们方法的通用性。最后,这项工作记录了 OpenPose [4] 的发布。这个开源库是第一个用于多人 2D 姿势检测的实时系统,包括身体、脚、手和面部关键点(第 4 节)。我们还包括与 Mask R-CNN [5] 和 Alpha-Pose [6] 的运行时比较,展示了我们自下而上方法的计算优势(第 5.3 节)。

图1:上图:多人姿势估计。属于同一个人的身体部位是链接的,包括脚关键点(大脚趾、小脚趾和脚跟)。左下图:对应于连接右肘和手腕的肢体的零件关联字段(PAF)。颜色编码方向。右下图:每个PAF的每个像素中的2D向量对肢体的位置和方向进行编码。
2、相关工作
单人姿势估计
关节式人体姿态估计的传统方法是结合对身体部位的局部观察以及它们之间的空间依赖性进行推断。关节姿势的空间模型要么基于树结构图形模型[7]、[8]、[9]、[10]、[11]、[12]、[13],它们参数化编码之间的空间关系遵循运动链的相邻部分,或非树模型 [14]、[15]、[16]、[17]、[18],它们通过附加边缘来增强树结构以捕获遮挡、对称和远程关系。为了获得对身体部位的可靠局部观察,卷积神经网络 (CNN) 已被广泛使用,并显着提高了身体姿势估计的准确性[19]、[20]、[21]、[22]、[23]、[24]、[25]、[26]、[27]、[28]、[29]、[30]、[31]、[32]。汤普森等人[23]使用具有图形模型的深度架构,其参数是与网络共同学习的。菲斯特等人[33]进一步使用 CNN 通过设计具有大感受野的网络来隐式捕获全局空间依赖关系。Wei等人提出的卷积姿势机器架构[20]使用了基于顺序预测框架[34]的多阶段架构;迭代地结合全局上下文以细化零件置信度图并保留先前迭代的多模态不确定性。在每个阶段结束时都会执行中间监督,以解决训练期间梯度消失的问题[35]、[36]、[37]。纽厄尔等人[19] 还表明,中间监督在堆叠沙漏架构中是有益的。然而,所有这些方法都假设一个人,其中给出了感兴趣的人的位置和规模。
多人姿势估计
对于多人姿态估计,大多数方法 [5]、[6]、[38]、[39]、[40]、[41]、[42]、[43]、[44] 都使用自上向下该策略首先检测人,然后在每个检测到的区域上独立估计每个人的姿势。尽管这种策略使得为单人案例开发的技术直接适用,但它不仅在人员检测方面受到早期检测结果的影响,而且无法捕捉需要全局推理的不同人之间的空间依赖关系。一些方法已经开始考虑人际依赖。艾希纳等人[45]扩展了图形结构以考虑一组交互的人和深度排序,但仍然需要一个人检测器来初始化检测假设。皮舒林等人[1]提出了一种自下而上的方法,该方法联合标记部分检测候选对象并将它们与个人相关联,成对分数从检测到的部分的空间偏移量中回归。这种方法不依赖于行人检测,但是,在全连接图上解决所提出的整数线性规划是一个 NP-hard 问题,因此单个图像的平均处理时间约为数小时。 Insafutdinov 等人[2]建立在[1]的基础上,具有基于 ResNet [46] 和图像相关成对分数的更强大的部分检测器,并通过增量优化方法大大提高了运行时间,但该方法仍然需要每张图像几分钟,有一个限制 最多 150 个部分提案。[2]中使用的成对表示是每对身体部位之间的偏移向量,很难精确回归,因此需要单独的逻辑回归将成对特征转换为概率分数。
在早期的工作 [3]中,我们提出了部分亲和场 (PAF),这是一种由一组流场组成的表示,它编码可变数量的人的身体部位之间的非结构化成对关系。与[1]和[2]相比,我们可以有效地从 PAF 获得成对分数,而无需额外的训练步骤。这些分数足以让贪婪解析获得具有实时性能的高质量结果以进行多人估计。在这项工作的同时,Insafutdinov 等人进一步简化了他们的身体部位关系图,以便在单帧模型中进行更快的推理,并将关节式人体跟踪制定为部位建议的时空分组。最近,Newell等人[48]提出了关联嵌入,可以将其视为代表每个关键点组的标签。他们将具有相似标签的关键点分组到个人中。帕潘德里欧等人[49]提出检测单个关键点并预测它们的相对位移,允许贪婪解码过程将关键点分组到人物实例中。 科卡巴斯等人[50] 提出了一种姿态残差网络,它接收关键点和人物检测,然后将关键点分配给检测到的人物边界框。 聂等[51]提出使用从候选关键点到图像中人物质心的密集回归来划分所有关键点检测。
在这项工作中,我们对我们早期的工作进行了一些扩展[3]。我们证明了 PAF 细化对于高精度是关键且足够的,在增加网络深度的同时消除了身体部位置信度图细化。这导致更快和更准确的模型。 我们还展示了第一个组合的身体和足部关键点检测器,它是根据将公开发布的带注释的足部数据集创建的。我们证明,与独立运行它们相比,结合这两种检测方法不仅减少了推理时间,而且保持了它们各自的准确性。最后,我们介绍了 OpenPose,这是第一个用于实时身体、足部、手部和面部关键点检测的开源库。
3、方法

图2 整理流程 (a)我们的方法将整个图像作为输入,供CNN联合预测(b)人体部位检测的置信图和(c)零件关联的PAFs(d) 解析步骤执行一组二部匹配以关联身体部位候选(e)我们最终将它们组合成图像中所有人的全身姿势。
图 2 说明了我们方法的整体流程。 该系统将大小为 w × h 的彩色图像(图 2a)作为输入,并为图像中的每个人生成解剖关键点的 2D 位置(图 2e)。首先,前馈网络预测身体部位位置的一组 2D 置信图 S(图 2b)和部分亲和场(PAF)的一组 2D 矢量场 L,它们编码了各部分之间的关联程度(图 2c)。集合 S = (S1 ,S2 ,...,S J ) 有 J 个置信图,每个部分一个,其中 S j ∈ R w×h , j ∈ {1...J} 。 集合 L = (L 1 ,L 2 ,...,L C ) 有 C 个向量场,每个肢体一个,其中 L c ∈ R w×h×2 , c ∈ {1...C} 。 为了清楚起见,我们将部分对称为肢体,但有些对不是人体肢体(例如,面部)。Lc中的每个图像位置都编码一个二维向量(图 1)。最后,通过贪心推理(图 2d)解析置信图和 PAF,以输出图像中所有人的 2D 关键点。
3.1、网络架构
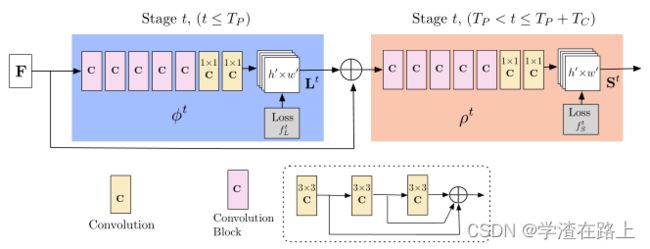
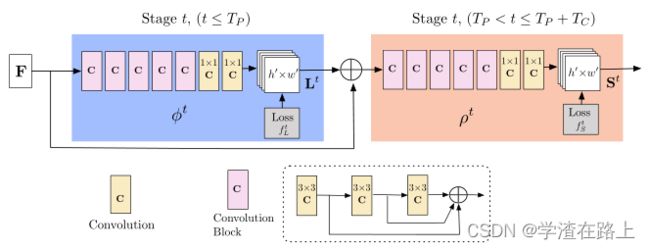
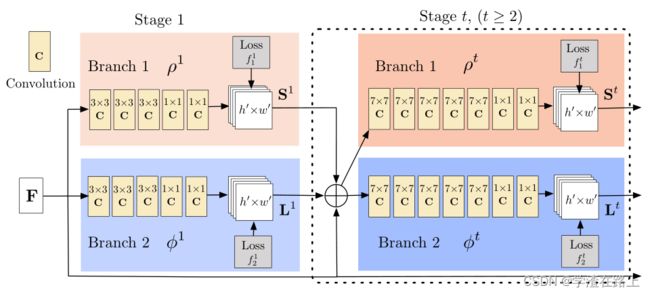
图3 多级CNN的架构。第一组阶段预测PAFs Lt,而最后一组预测置信图St。将每个阶段的预测及其相应的图像特征连接到每个后续阶段。原始方法[3]中的内核大小为7的卷积被替换为内核3的3层卷积,这些卷积在其末端串联
我们的架构,如图 3 所示,迭代地预测编码部分到部分关联的亲和场(以蓝色显示)和检测置信度图(以米色显示)。遵循[20]的迭代预测架构改进了连续阶段的预测,t∈{1,...,T} ,每个阶段都有中间监督。
网络深度相对于[3]有所增加。在最初的方法中,网络架构包括几个 7x7 卷积层。 在我们当前的模型中,通过将每个 7x7 卷积核替换为 3 个连续的 3x3 内核,在减少计算量的同时保留了感受野。前者的运算次数为 2×7^2 − 1 = 97 ,而后者只有 51 次。此外,按照类似于 DenseNet [52] 的方法,将 3 个卷积核中的每一个的输出连接起来。非线性层的数量增加了两倍,网络可以同时保留较低级别和较高级别的特征。第 5.2 节和第 5.3 节分别分析了准确性和运行时速度的改进。
3.2、同时检测和关联
图像由 CNN 分析(由 VGG-19 [53] 的前 10 层初始化并微调),生成一组特征图 F 输入到第一阶段。 在这个阶段,网络产生一组部分亲和场 (PAF) L 1 = φ 1 (F) ,其中 φ 1 指的是在阶段 1 进行推理的 CNN。在每个后续阶段,来自前一阶段的预测和 原始图像特征F被连接并用于产生精确的预测,
![]()
其中 φ t 是指用于在阶段 t 进行推理的 CNN,而 T P 是指总 PAF 阶段的数量。 在 T P 次迭代之后,对置信图检测重复该过程,从最新的 PAF 预测开始,
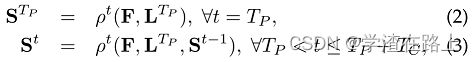
其中 ρ t 是指用于在阶段 t 进行推理的 CNN,而TC是指总置信度图阶段的数量。
这种方法不同于 [3],其中PAF和置信度图分支都在每个阶段进行了细化。因此,每个阶段的计算量减少了一半。我们在第 5.2 节中凭经验观察到,改进的亲和力场预测改善了置信度图结果,而相反的情况则不成立。直观地说,如果我们查看 PAF 通道输出,可以猜出身体部位的位置。但是,如果我们看到一堆没有其他信息的身体部位,我们就无法将它们解析为不同的人。

图4 右前臂各阶段的PAF。虽然在早期阶段左右身体部位和四肢之间存在混淆,但在后期阶段,通过全局推断,估计值会越来越精确。
图 4 显示了跨阶段的亲和力场的细化。 置信图结果是在最新和最精细的 PAF 预测之上预测的,导致置信图阶段之间几乎没有明显差异。为了引导网络迭代地预测第一个分支中身体部位的PAF和第二个分支中的置信度图,我们在每个阶段的末尾应用了一个损失函数。我们在估计的预测与真实地图和字段之间使用L2损失。 在这里,我们在空间上对损失函数进行加权,以解决一些数据集不能完全标记所有人的实际问题。具体来说,PAF分支在ti阶段的损失函数和置信度图分支在tk阶段的损失函数分别为:
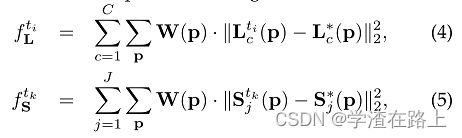
其中L*c是 groundtruth PAF,S*j是 groundtruth 部分置信度图,W 是当像素 p 处缺少注释时 W(p) = 0 的二进制掩码。 掩码用于避免在训练期间惩罚真正的正预测。 每个阶段的中间监督通过定期补充梯度来解决梯度消失问题[20]。总体目标是
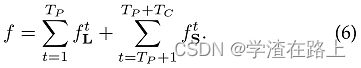
3.3、零件检测的置信度图
在方程式中评估 fS。(6)在训练期间,我们从带注释的 2D 关键点生成 groundtruth 置信度图 S*。每个置信度图都是对特定身体部位可以位于任何给定像素中的信念的 2D 表示。 理想情况下,如果图像中出现了一个人,如果对应部分可见,则每个置信度图中应该存在一个峰值;如果图像中有多个人,则每个人 k 的每个可见部分 j 应该有一个峰值对应
我们首先为每个人k生成个人置信图S*j,k。令xj,k∈R2为图像中人k的身体部位j的真实位置。S∗j,k中位置p∈R2处的值定义为,
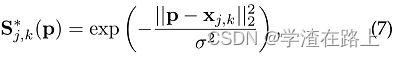
其中 σ 控制峰的扩散。网络预测的groundtruth置信度图是单个置信度图通过最大算子的聚合,
![]()
我们取置信度图的最大值而不是平均值,以便附近峰值的精度保持不同,如右图所示。 在测试时,我们预测置信度图,并通过执行非极大值抑制获得身体部位候选者。
3.4、部件关联的部件关联字段

图5 零件关联策略。(a)两种身体部位类型的身体部位检测候选(红点和蓝点)和所有连接候选(灰线)。(b)连接结果使用中点(黄色点)表示:也满足关联约束的正确连接(黑线)和错误连接(绿线)。(c)结果使用PAFs(黄色箭头)。通过编码肢体支撑上的位置和方向,PAF消除了错误关联
给定一组检测到的身体部位(如图 5a 中的红色和蓝色点所示),我们如何将它们组装成未知人数的全身姿势?我们需要对每对身体部位检测的关联进行置信度测量,即它们属于同一个人。 测量关联的一种可能方法是检测肢体上每对部件之间的附加中点,并检查其在候选部件检测之间的发生率,如图 5b 所示。 然而,当人们聚集在一起时——正如他们倾向于做的那样——这些中点可能会支持错误的关联(如图5b中的绿线所示)。这种错误关联的产生是由于表示中的两个限制:
(1)它只编码每个肢体的位置,而不是方向;(2)它将肢体的支撑区域减少到一个点。
部件关联字段 (PAF) 解决了这些限制。 它们保留了肢体支撑区域的位置和方向信息(如图 5c 所示)。 每个 PAF 是每个肢体的 2D 矢量场,如图 1d 所示。 对于属于特定肢体的区域中的每个像素,2D 矢量编码从肢体的一个部分指向另一部分的方向。 每种类型的肢体都有一个相应的 PAF,连接其两个相关的身体部位。
考虑下图中所示的单个肢体。令xj1,k和xj2,k为身体 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Gaussian 1 Gaussian 2 Max Average p S 0 0.2 0.4 0.6 0.8 1 Gaussian 1 Gaussian 2 Max Average Sppvv 的groundtruth位置?pxj2,1xj1,kxj2,k部分j1和j2来自图像中人k的肢体 c。如果点p位于肢体上,则L∗c,k(p)处的值是从j1指向j2的单位向量;对于所有其他点,向量为零值。
计算公式中的fL6在训练期间,我们将图像点p处的groundtruth PAF L ∗ c,k 定义为
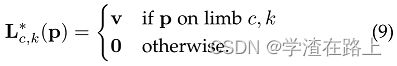
这里,v = (x j 2 ,k - x j 1 ,k )/||x j 2 ,k -x j 1 ,k || 2 是肢体方向上的单位向量。 肢体上的点集定义为线段距离阈值内的点,即那些点 p
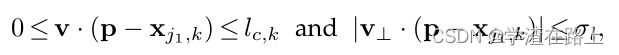
其中肢体宽度σl是以像素为单位的距离,肢体长度为lc,k=||x j2,k−xj1,k||2, v⊥是垂直于 v 的向量
groundtruth部分亲和力场平均图像中所有人的亲和力场,
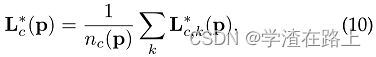
其中 n c (p) 是所有 k 个人在点 p 处的非零向量的数量。
在测试期间,我们通过沿着连接候选部件位置的线段计算相应 PAF 上的线积分来测量候选部件检测之间的关联。 换句话说,我们测量预测的 PAF 与通过连接检测到的身体部位形成的候选肢体的对齐情况。具体来说,对于两个候选部位位置 d j 1 和 d j 2 ,我们沿线段对预测的部位亲和场 L c 进行采样,以测量它们关联的置信度
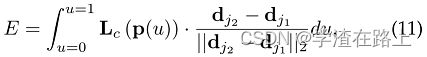
其中 p(u) 对两个身体部位 d j 1 和 d j 2 的位置进行插值,
![]()
在实践中,我们通过对 u 的均匀间隔值进行采样和求和来近似积分
3.5 使用 PAF 的多人解析
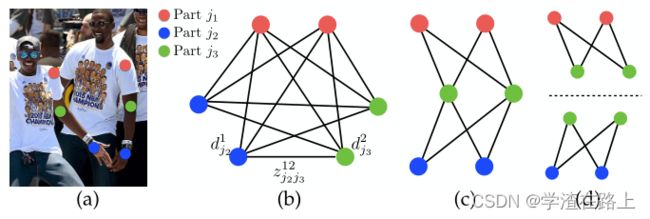
图6 图形匹配。(a)带有零件检测的原始图像。(b)K部图。(c)树状结构。(d)一组二部图。
我们对检测置信度图执行非极大值抑制以获得一组离散的零件候选位置。 对于每个部分,由于图像中有多个人或误报,我们可能有多个候选者(图 6b)。这些候选部件定义了大量可能的肢体。我们使用等式中定义的 PAF 上的线积分计算对每个候选肢体进行评分。寻找最优解析的问题对应于一个已知为 NP-Hard [54] 的 K 维匹配问题(图 6c)。在本文中,我们提出了一种贪婪的算法,它始终如一地产生高质量的匹配。我们推测原因是由于 PAF 网络的大感受野,成对关联分数隐含地编码了全局上下文。
形式上,我们首先获得一组多人的身体部位检测候选 DJ,其中 DJ={dmj : for j ∈ {1...J},m ∈ {1...N j }} ,其中Nj是身体部位 j 的候选者数量,dmj∈R2是身体部位 j 的第m个检测候选者的位置。这些候选部位检测仍然需要与同一个人的其他部位相关联——换句话说,我们需要找到实际上是连接肢体的部位检测对。我们定义一个变量zmnj1j2∈{0,1}来表示两个检测候选dmj1和dnj2 是否连接,目标是找到所有可能连接集合的最优分配,Z={zmnj1j2:对于j1,j2∈{1...J},m∈{1...Nj1},n∈ {1...Nj2}}
如果我们考虑第c个肢体的一对部分j1和j2(例如,颈部和右臀部),则找到最佳关联会减少到最大权重二分图匹配问题[54]。这种情况如图5b所示。在这个图匹配问题中,图的节点是身体部位检测候选Dj1和Dj2,边都是检测候选对之间的可能连接。此外,每条边都由等式加权。11—部分亲和力聚合。二分图中的匹配是选择的边的子集,其选择方式是没有两条边共享一个节点。我们的目标是为所选边缘找到最大权重的匹配,
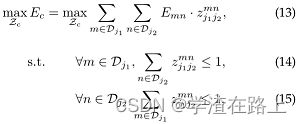
其中Ec是肢体类型c匹配的总权重,Zc是肢体类型c的Z子集,Emn是等式中定义的部分dmj1和dnj2之间的部分亲和性。11. 方程14 和15强制没有两条边共享一个节点,即没有两个相同类型的肢体(例如左前臂)共享一个部分。我们可以使用匈牙利算法[55]来获得最优匹配。
在寻找多人的全身姿势时,确定 Z 是一个 K 维匹配问题。 这个问题是 NP-Hard [54] 并且存在许多松弛。 在这项工作中,我们为优化添加了两个放松,专门针对我们的领域。 首先,我们选择最少数量的边来获得人体姿态的生成树骨架,而不是使用完整的图,如图 6c 所示。 其次,我们进一步将匹配问题分解为一组二分匹配子问题,并独立确定相邻树节点中的匹配,如图6d所示。我们在第5.1节中展示了详细的比较结果,这表明最小贪心推理以一小部分计算成本很好地逼近了全局解决方案。原因是相邻树节点之间的关系由PAF显式建模,但在内部,非相邻树节点之间的关系由CNN隐式建模。这个属性的出现是因为CNN训练有一个大的感受野,并且来自非相邻树节点的 PAF 也会影响预测的 PAF。
有了这两个松弛,优化被简单地分解为
![]()
因此,我们使用 Eqns 独立获得每种肢体类型的肢体连接候选者。13-15. 对于所有肢体连接候选,我们可以将共享相同部位检测候选的连接组装成多人的全身姿势。我们对树结构的优化方案比对全连接图[1]、[2]的优化要快几个数量级。

图7 冗余PAF连接的重要性。(a)由于颈鼻连接错误,两个不同的人被错误地合并。(b)右耳肩连接的可信度更高,避免了错误的鼻颈连接
我们当前的模型还包含冗余的PAF连接(例如,耳朵和肩膀之间、手腕和肩膀之间等)。这种冗余特别提高了拥挤图像的准确性,如图7所示。为了处理这些冗余连接,我们稍微修改了多人解析算法。虽然最初的方法是从根组件开始的,但我们的算法通过它们的 PAF 分数对所有可能的成对连接进行排序。 如果一个连接试图连接已经分配给不同人的2个身体部位,算法会以更高的置信度识别出这将与 PAF 连接相矛盾,并且随后会忽略当前连接。
4、OPENPOSE
越来越多的计算机视觉和机器学习应用需要2D人体姿态估计作为其系统的输入 [56]、[57]、[58]、[59]、[60]、[61]、[62]。为了帮助研究社区推进他们的工作,我们公开发布了OpenPose[4],这是第一个在单张图像上联合检测人体、足部、手部和面部关键点(总共 135 个关键点)的实时多人系统。有关整个系统的示例,请参见图 8。

图8 OpenPose的输出,实时检测身体、脚、手和面部关键点。OpenPose对遮挡具有鲁棒性,包括在人机交互期间
4.1、系统
可用的2D身体姿态估计库,例如Mask R-CNN[5]或Alpha-Pose[6],要求用户实现大部分管道、他们自己的帧读取器(例如,视频、图像或相机流),用于可视化结果的显示、使用结果生成输出文件(例如,JSON 或 XML 文件)等。此外,现有的面部和身体关键点检测器没有组合在一起,需要针对每个目的使用不同的库。 OpenPose 克服了所有这些问题。 它可以在不同的平台上运行,包括Ubuntu、Windows、Mac OSX 和嵌入式系统(例如,Nvidia Tegra TX2)。它还提供对不同硬件的支持,例如 CUDA GPU、OpenCL GPU和CPUonly设备。用户可以在图像、视频、网络摄像头和 IP 摄像头流之间选择输入。 他还可以选择是显示结果还是将它们保存在磁盘上,启用或禁用每个检测器(身体、脚、脸和手),启用像素坐标归一化,控制使用多少GPU,跳过帧以加快处理速度,等等
OpenPose由三个不同的模块组成:(a)身体+足部检测,(b)手部检测[63],和(c)面部检测。核心块是组合的身体+足部关键点检测器(第4.2节)。它也可以使用在 COCO和MPII数据集上训练的原始纯身体模型[3]。基于身体检测器的输出,可以从一些身体部位位置(特别是耳朵、眼睛、鼻子和颈部)粗略估计面部边界框建议。类似地,手部边界框建议是使用手臂关键点生成的。该方法继承了第 1 节中讨论的自上而下方法的问题。手部关键点检测器算法在[63]中进行了更详细的解释,而面部关键点检测器的训练方式与手部关键点检测器的训练方式相同。该库还包括3D关键点姿态检测,通过对多个同步摄像机视图的结果执行3D三角测量和非线性Levenberg-Marquardt细化[64]。
OpenPose的推理时间优于所有最先进的方法,同时保留了高质量的结果。它能够在配备Nvidia GTX 1080 Ti的机器上以大约22 FPS的速度运行,同时保持高精度(第5.3节)。OpenPose已经被研究界用于许多视觉和机器人主题,例如人员重新识别[56]、基于GAN的人脸视频重定向[57]和身体[58]、人机交互[59]、3D姿态估计[60]和3D人体网格模型生成[61]。此外,OpenCV库[65]在其深度神经网络(DNN)模块中包含了OpenPose和我们基于PAF的网络架构。
4.2、扩展足部关键点检测
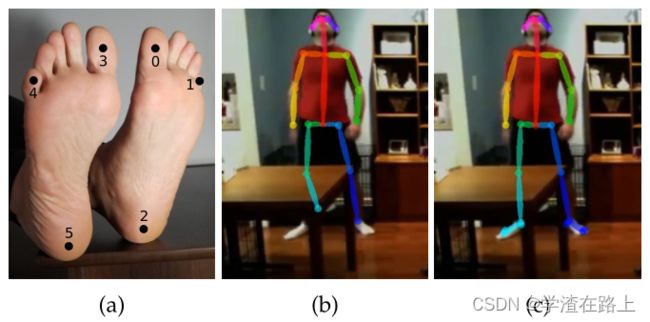
图9 脚部关键点分析。(a)脚关键点注释,由大脚趾、小脚趾和脚跟组成。(b)未正确估计右脚踝的纯身体模型示例。(c)类似于身体+脚模型示例,脚信息有助于预测右脚踝位置
现有的人体姿势数据集([66]、[67])包含有限的身体部位类型。MPII数据集[66]注释了脚踝、膝盖、臀部、肩膀、肘部、手腕、颈部、躯干和头顶,而COCO [67]还包括一些面部关键点。对于这两个数据集,足部注释仅限于脚踝位置。然而,图形应用程序,如头像重定向或3D人体形状重建([61],[68])需要足部关键点,如大脚趾和脚跟。在没有足部信息的情况下,这些方法会遇到诸如糖果包装效果、地板穿透和足部滑冰等问题。为了解决这些问题,COCO数据集中的一小部分脚实例使用Clickworker平台 [69] 进行标记。它分为来自 COCO 训练集的14K注释和来自验证集的545个注释。总共标记了6个脚关键点(见图 9a)。我们考虑足部关键点的3D坐标而不是表面位置。例如,对于确切的脚趾位置,我们标记了指甲和皮肤连接之间的区域,并且还通过标记脚趾的中心而不是表面来考虑深度。

图10 3个数据集的关键点注释配置
使用我们的数据集,我们训练了足部关键点检测算法。可以通过使用身体关键点检测器生成足部边界框建议,然后在其上训练足部检测器来构建一个幼稚的足部关键点检测器。然而,这种方法存在第 1 节中所述的自上而下的问题。相反,训练先前描述的用于身体估计的相同架构来预测身体和脚的位置。图10显示了三个数据集(COCO、MPII和COCO+foot)的关键点分布。身体+足部模型还在臀部之间加入了一个插值点,即使在上部躯干被遮挡或超出图像的情况下,也可以连接双腿。我们发现足部关键点检测隐含地帮助网络更准确地预测一些身体关键点的证据,特别是腿部关键点,例如脚踝位置。图9b显示了仅身体网络无法预测脚踝位置的示例。通过在训练期间包括足部关键点,同时保持相同的身体注释,该算法可以正确预测图 9c 中的脚踝位置。我们在 5.5 节中定量分析了精度差异。
论文地址
2017:https://arxiv.org/pdf/1611.08050.pdf
2019:https://arxiv.org/abs/1812.08008
代码地址
GitHub - CMU-Perceptual-Computing-Lab/openpose: OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation
论文整体的思路
1、图像进入之后,首先进行了一顿卷积,就是上图中的F,论文中的描述是:VGG-19的前10层初始化并微调
2、一顿卷积计算了PAFs,就是点与点的相互关系,这个过程中计算了损失
3、 将1出来的结果和2出来的结果进行了一个拼接
4、最后一顿卷积计算了各个关节的置信度,并计算了损失
理论介绍
AI识别人的五重境界
AI识别人可以分成五个层次,依次为:
1.有没有人?->object detection (YOLO SSD Faster-RCNN)
2.人在哪里?->object localization & semantic segmentation (Mask-RCNN)
3.这个人是谁?->face identification 人脸识别
4.这个人此刻处于什么状态? pose estimation
5.这个人在当前一段时间里在做什么?->Sequence action recognition 一小段视频的行为识别
姿态检测的挑战
每张图片中包含的人的数量是未知的。
人与人之间的相互作用是非常复杂的,比如接触、遮挡等,这使得联合各个肢体,即确定一个人有哪些部分变得困难。
图像中人越多,计算复杂度越大(计算量与人的数量正相关),这使得real time变得困难。
多人姿态估计
多人姿态估计分为Bottom-Up方法和top-down方法两个方向 1、自下而上(Bottom-Up)方法:先检测图像中人体关键点,然后将图像中多人的人体关键点分别分配到不同的人体实例上。 2、自上而下(Top-Down方法):在图像上首先运行一个人体检测器,找到所有的人体实例,对每个人体再使用关键点检测,这个做法是将人体检测和关键点检测分离开
贪心算法
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
NP-problem
(nondeterministic polynomial time) NP是指非确定性多项式(non-deterministic polynomial,缩写NP)。所谓的非确定性是指,可用一定数量的运算去解决多项式时间内可解决的问题。
PAFs
Part Affinity Fields,啥是PAFs??
 如图4所示,实际上就是两个关节之间的连接所产生的heatmap
如图4所示,实际上就是两个关节之间的连接所产生的heatmap
匈牙利算法
个人对这个算法的理解呢,举个简单的例子
在多目标跟踪deepsort中,就使用了这个算法,比如说第一帧图像检测出了5个目标,第二帧图像检测出了6个目标,目标跟踪需要尽可能将前后两帧中的目标匹配到一起,匈牙利算法就是将前一帧5个目标和后一帧6个目标匹配到一起的算法,他计算了个损失,损失最低的匹配方案是最合理的匹配方案,匈牙利算法就是这么个多目标相互匹配求最优解的这么个算法
Hungarian Algorithm(匈牙利算法)_星R尘的博客-CSDN博客_hungarian算法
版本说明
openpose其实有两篇论文,是一个团队写的,发表时间分别是2017年和2019年,
2017年的网络结构是:
2019年的网络
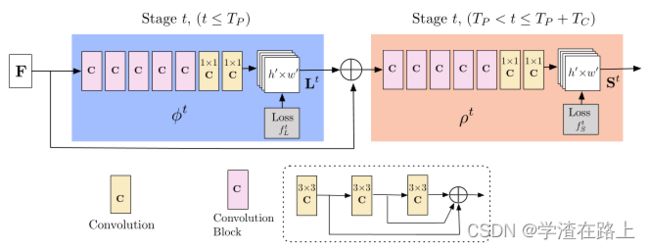
在2019版本论文中,也明确提到,新论文中将每个 7x7 卷积核替换为 3 个连续的 3x3 内核,此外还借鉴了DenseNet网络结构,如第二张图中的虚线部分
参考链接
OpenPose 2019版总结_西西弗Sisyphus的博客-CSDN博客_openpose应用现状
如何评价卡内基梅隆大学的开源项目 OpenPose? - 知乎
[多图/秒懂]白话OpenPose,最受欢迎的姿态估计网络 - 知乎
【AI识人】OpenPose:实时多人2D姿态估计 | 附视频测试及源码链接 - 知乎
代码编译讲解
OpenPose的编译和PyOpenPose的基本使用:
OpenPose的编译和PyOpenPose的基本使用_哔哩哔哩_bilibili