k-means和k-medoids聚类算法matlab编程实现
k-means算法步骤:
步骤1:随机选择k个初始簇中心(聚类中心);
步骤2:对剩余的每个样本,分别计算其到k个簇中心的距离,并将其划分入距离它最近的簇中心所在的簇中,从而形成k个簇;
步骤3:重新计算每个簇的均值向量作为新的簇中心;
步骤4:如果簇中心没有任何改变,算法停止,否则回到步骤2。
k-means算法优点:
-
原理简单,易 于 实 现,收敛速度快。
-
算法高效:时间复杂度为Ο(tkn)
-
其中,n是样本数,k是簇的数目,t是算法迭代次数。k和t通常较小,所以k-均值算法被认为一个线性时间的算法,即时间复杂度近似为Ο(n) 。
-
算法的可解释度比较强。
-
主要需要调节的参数仅是簇数。
k-medoids算法步骤:
步骤1:随机选择k个样本作为初始的簇中心;
步骤2:对剩余的每个样本,将其划分入距离它最近的簇中心所在的簇中,从而形成k个簇;
步骤3:重新计算簇中心,即对于每个簇,找到该簇的一个样本点,称为medoid,使得该簇中所有其他点到该样本点的距离之和最小;
步骤4:如果簇中心没有任何改变,算法停止,否则回到步骤2。
实例:
完整代码如下:mo_2.m聚类分析算法实例(k-means和k-medois)matlab实现
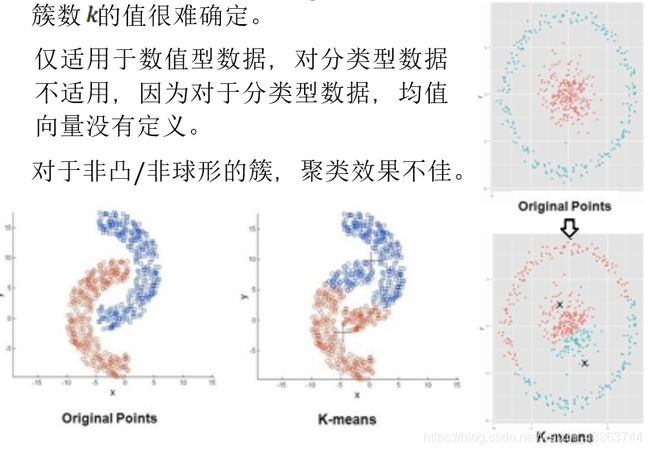
假设3个样本集合:set1,set2,set3,每个集合中包含1000个样本:
第一个集合所使用的正态分布参数:均值向量为[0 0],协方差矩阵为[0.5 0; 0 0.5];
第二个集合所使用的正态分布参数:均值向量为[2 3],协方差矩阵为[0.6 0.1; 0.1 0.6];
第三个集合所使用的正态分布参数:均值向量为[-2 3],协方差矩阵为[0.5 -0.1; -0.1 0.5];
使用scatter函数将这3个集合中的点显示在一幅图中:
mul = [0 0];
SIGMA = [0.5 0; 0 0.5];
set1 = mvnrnd(mul,SIGMA,1000);
scatter(set1(:,1),set1(:,2),'r+');
hold on;
mul = [2 3];
SIGMA = [ 0.6 0.1; 0.1 0.6];
set2 = mvnrnd(mul,SIGMA,1000);
scatter(set2(:,1),set2(:,2),'b*');
hold on;
mul = [-2 3];
SIGMA = [ 0.5 -0.1; -0.1 0.5];
set3 = mvnrnd(mul,SIGMA,1000);
scatter(set3(:,1),set3(:,2),'g.');
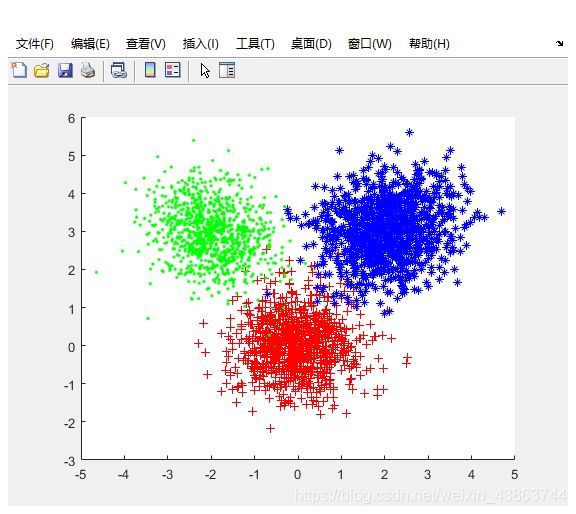
将上述3个样本集合并,放到样本集set中;然后编程实现k-means,此处并没有使用matlab自带的kmeans得到结果。
%%
figure;
set=[set1;set2;set3];
[u,re]=KMeans(set,3);
[m,n]=size(re);
for i=1:m
if re(i,3)==1
scatter(re(i,1),re(i,2),'ro');
elseif re(i,3)==2
scatter(re(i,1),re(i,2),'go');
else
scatter(re(i,1),re(i,2),'bo');
end
end
%% k-means
function [u,re]=KMeans(data,N)
[m,n]=size(data);
ma=zeros(n);
mi=zeros(n);
u=zeros(N,n);
for i=1:n
ma(i)=max(data(:,i));
mi(i)=min(data(:,i));
for j=1:N
u(j,i)=ma(i)+(mi(i)-ma(i))*rand();
end
end
while 1
pre_u=u;
for i=1:N
tmp{i}=[];
for j=1:m
tmp{i}=[tmp{i};data(j,:)-u(i,:)];
end
end
quan=zeros(m,N);
for i=1:m
c=[];
for j=1:N
c=[c norm(tmp{j}(i,:))];
end
[junk,index]=min(c);
quan(i,index)=norm(tmp{index}(i,:));
end
for i=1:N
for j=1:n
u(i,j)=sum(quan(:,i).*data(:,j))/sum(quan(:,i));
end
end
if norm(pre_u-u)<0.1
break;
end
end
re=[];
for i=1:m
tmp=[];
for j=1:N
tmp=[tmp,norm(data(i,:)-u(j,:))];
end
[junk,index]=min(tmp);
re=[re;data(i,:),index];
end
end
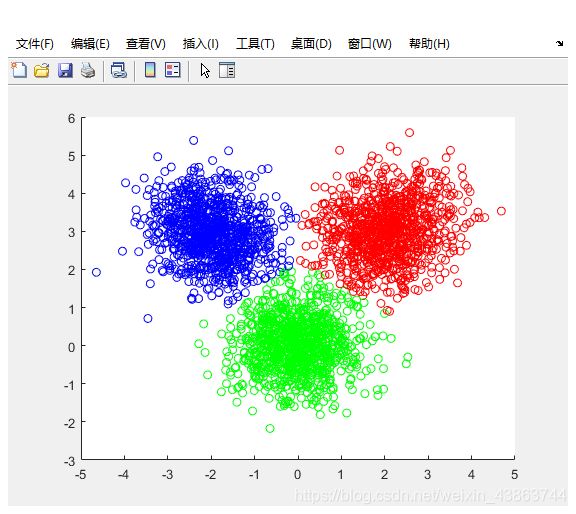
编程实现k-kmedoids,此处并没有使用matlab自带的kmedoids得到结果。
%% k-kmedoids
k=3;
[num,z]=size(set);
C_temp=zeros(k,2);
if ksqrt((set(i,1)-C_temp(j,1))*(set(i,1)-C_temp(j,1))+(set(i,2)-C_temp(j,2))*(set(i,2)-C_temp(j,2)))
minValue=sqrt((set(i,1)-C_temp(j,1))*(set(i,1)-C_temp(j,1))+(set(i,2)-C_temp(j,2))*(set(i,2)-C_temp(j,2)));
minNum=j;
end
end
cluster{minNum}=cat(1,cluster{minNum},set(i,:));
end
flag=1;
count=0;
while flag==1
randC=randperm(num-k);
randC=randC(1:1);
o_random=set(randC,:);
recordN=0;
for i=1:k
for j=1:size(cluster{i},1)
cc=cluster{i}(j,:);
cc=cc-o_random;
if cc==0
recordN=i;
break;
end
end
end
set(randC,:)=[];
o=cluster{recordN}(1,:);
o_rand_sum=0;
o_sum=0;
for i=1:length(set)
o_rand_sum=o_rand_sum+sqrt((set(i,1)-o_random(1,1))*(set(i,1)-o_random(1,1))+(set(i,2)-o_random(1,2))*(set(i,2)-o_random(1,2)));
o_sum=o_sum+sqrt((set(i,1)-o(1,1))*(set(i,1)-o(1,1))+(set(i,2)-o(1,2))*(set(i,2)-o(1,2)));
end
if o_rand_sumsqrt((set(i,1)-C_temp(j,1))*(set(i,1)-C_temp(j,1))+(set(i,2)-C_temp(j,2))*(set(i,2)-C_temp(j,2)))
minValue=sqrt((set(i,1)-C_temp(j,1))*(set(i,1)-C_temp(j,1))+(set(i,2)-C_temp(j,2))*(set(i,2)-C_temp(j,2)));
minNum=j;
end
end
cluster{minNum}=cat(1,cluster{minNum},set(i,:));
end
else
set=cat(1,set,o_random);
flag=0;
end
count=count+1;
end
for i=1:k
scatter(cluster{i}(:,1),cluster{i}(:,2),'filled');
hold on
end
end
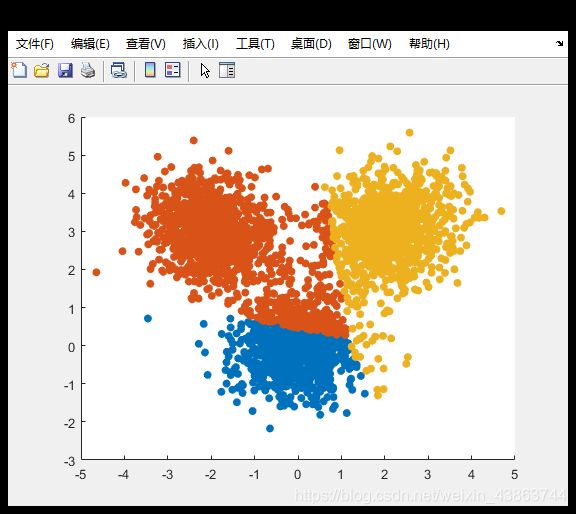
实例2:
set1 = mvnrnd([0 0],[0.1 0; 0 0.1],2000);
set2 = mvnrnd([1.5 1],[0.07 0; 0 1],2000);
set = [set1; set2];
用之前的k-means算法对样本集set 进行聚类
set1=mvnrnd([0 0],[0.1 0; 0 0.1],2000);
scatter(set1(:,1),set1(:,2),'r+');
axis equal;
hold on;
set2 = mvnrnd([1.5 1],[0.07 0; 0 1],2000);
scatter(set2(:,1),set2(:,2),'b*');
axis equal;
set = [set1; set2];
%%
figure;
hold on;
axis equal;
[u,re]=KMeans(set,2);
[m,n]=size(re);
for i=1:m
if re(i,3)==1
scatter(re(i,1),re(i,2),'ro');
elseif re(i,3)==2
scatter(re(i,1),re(i,2),'go');
end
end
%% k-means
function [u re]=KMeans(data,N)
[m n]=size(data);
ma=zeros(n);
mi=zeros(n);
u=zeros(N,n);
for i=1:n
ma(i)=max(data(:,i));
mi(i)=min(data(:,i));
for j=1:N
u(j,i)=ma(i)+(mi(i)-ma(i))*rand();
end
end
while 1
pre_u=u;
for i=1:N
tmp{i}=[];
for j=1:m
tmp{i}=[tmp{i};data(j,:)-u(i,:)];
end
end
quan=zeros(m,N);
for i=1:m
c=[];
for j=1:N
c=[c norm(tmp{j}(i,:))];
end
[junk index]=min(c);
quan(i,index)=norm(tmp{index}(i,:));
end
for i=1:N
for j=1:n
u(i,j)=sum(quan(:,i).*data(:,j))/sum(quan(:,i));
end
end
if norm(pre_u-u)<0.1
break;
end
end
re=[];
for i=1:m
tmp=[];
for j=1:N
tmp=[tmp norm(data(i,:)-u(j,:))];
end
[junk index]=min(tmp);
re=[re;data(i,:) index];
end
end
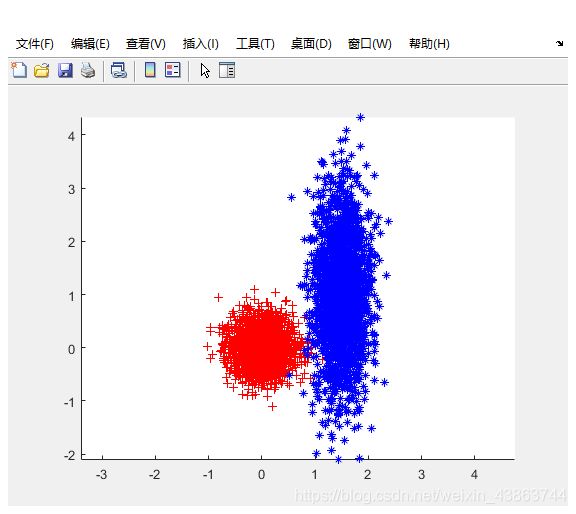
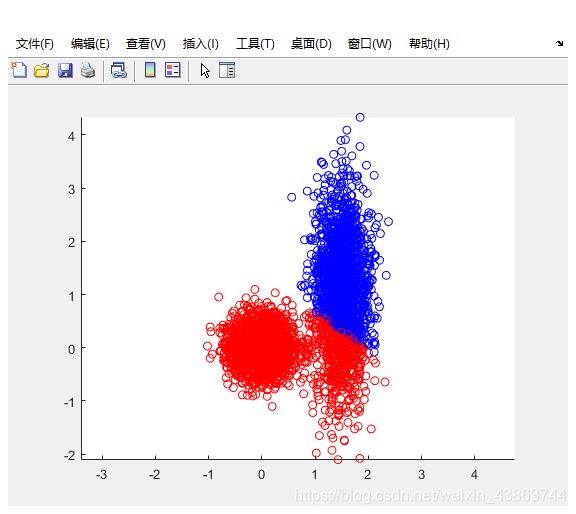
结果产生明显偏差,原因如下: