用python实现各种文件类型转换
一、word转pdf
先安装win32库:pip install pywin32
from win32com.client import gencache
from win32com.client import constants, gencache
def createPdf(wordPath, pdfPath):
"""
word转pdf
:param wordPath: word文件路径
:param pdfPath: 生成pdf文件路径
"""
word = gencache.EnsureDispatch('Word.Application')
doc = word.Documents.Open(wordPath, ReadOnly=1)
doc.ExportAsFixedFormat(pdfPath,
constants.wdExportFormatPDF,
Item=constants.wdExportDocumentWithMarkup,
CreateBookmarks=constants.wdExportCreateHeadingBookmarks)
word.Quit(constants.wdDoNotSaveChanges)
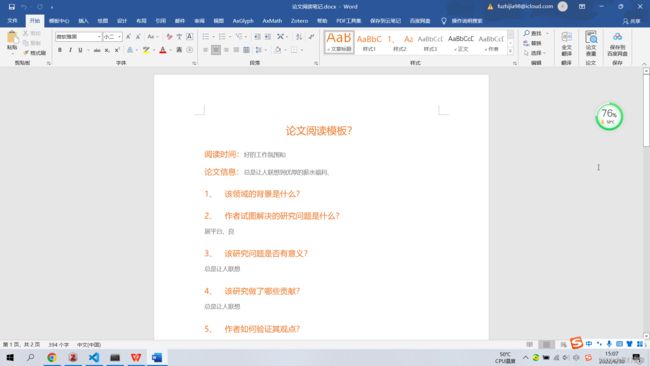
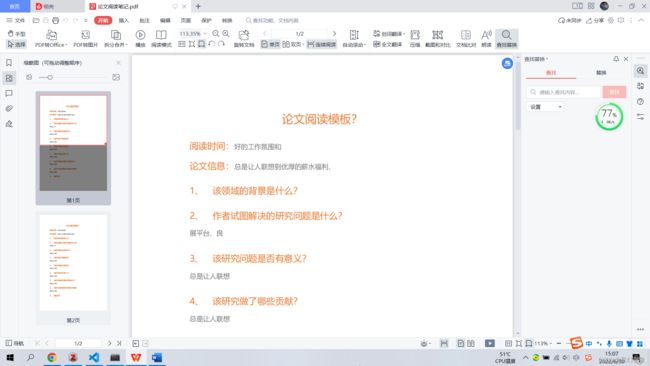
createPdf('D:\桌面\论文阅读笔记.docx','D:\桌面\论文阅读笔记.pdf')
运行结果:
二、excel转pdf
# Import Module
from win32com import client
# Open Microsoft Excel
excel = client.Dispatch("Excel.Application")
# Read Excel File
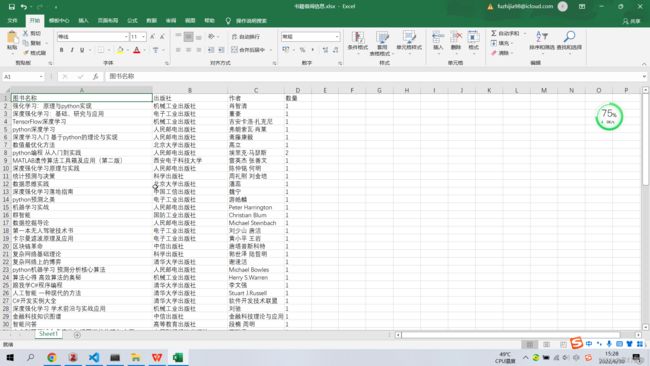
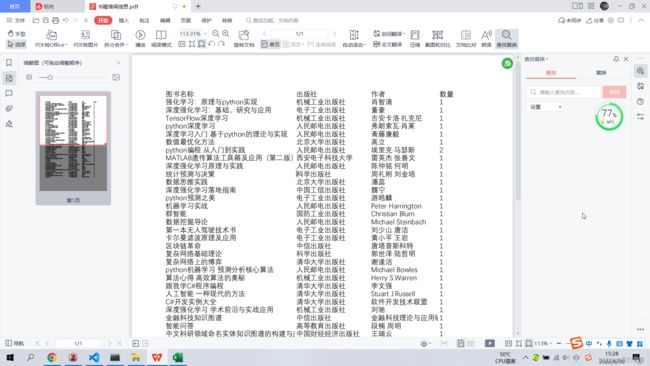
sheets = excel.Workbooks.Open('F:\书籍借阅信息.xlsx')
work_sheets = sheets.Worksheets[0]
# Convert into PDF File
work_sheets.ExportAsFixedFormat(0, 'F:\书籍借阅信息.pdf')
# 关闭服务
excel.Quit()
运行结果:
三、ppt转pdf
# 1). 导入需要的模块(打开应用程序的模块)
import win32com.client
import os
def ppt2pdf(filename, output_filename):
"""
PPT文件导出为pdf格式
:param filename: PPT文件的名称
:param output_filename: 导出的pdf文件的名称
:return:
"""
# 2). 打开PPT程序
ppt_app = win32com.client.Dispatch('PowerPoint.Application')
# ppt_app.Visible = True # 程序操作应用程序的过程是否可视化
# 3). 通过PPT的应用程序打开指定的PPT文件
# filename = "C:/Users/Administrator/Desktop/PPT办公自动化/ppt/PPT素材1.pptx"
# output_filename = "C:/Users/Administrator/Desktop/PPT办公自动化/ppt/PPT素材1.pdf"
ppt = ppt_app.Presentations.Open(filename)
# 4). 打开的PPT另存为pdf文件。17数字是ppt转图片,32数字是ppt转pdf。
ppt.SaveAs(output_filename, 32)
print("导出成pdf格式成功!!!")
# 退出PPT程序
ppt_app.Quit()
# 要处理的目录名称
dirname = 'D:\桌面\智能算法设计与实现'
# 列出指定目录的内容
filenames = os.listdir(dirname)
# for循环依次访问指定目录的所有文件名
for filename in filenames:
# 判断文件的类型,对所有的ppt文件进行处理(ppt文件以ppt或者pptx结尾的)
if filename.endswith('ppt') or filename.endswith('pptx'):
# print(filename) # PPT素材1.pptx -> PPT素材1.pdf
# 将filename以.进行分割,返回2个信息,文件的名称和文件的后缀名
base, ext = filename.split('.') # base=PPT素材1 ext=pdf
new_name = base + '.pdf' # PPT素材1.pdf
# ppt文件的完整位置: C:/Users/Administrator/Desktop/PPT办公自动化/ppt/PPT素材1.pptx
filename = dirname + '/' + filename
# pdf文件的完整位置: C:/Users/Administrator/Desktop/PPT办公自动化/ppt/PPT素材1.pdf
output_filename = dirname + '/' + new_name
# 将ppt转成pdf文件
ppt2pdf(filename, output_filename)
运行结果:

四、图片转pdf
from PIL import Image
import os
# 防止字符串乱码
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
def pic2pdf(img_path, pdf_path):
file_list = os.listdir(img_path)
for x in file_list:
if "jpg" in x or 'png' in x or 'jpeg' in x:
pdf_name = x.split('.')[0]
im1 = Image.open(os.path.join(img_path, x))
im1.save(pdf_path + pdf_name + '.pdf', "PDF", resolution=100.0)
if __name__ == '__main__':
# 待转换图像路径
img_path = r"D:\桌面\\"
# 转换后的pdf存放路径
pdf_path = r'D:\桌面\\'
pic2pdf(img_path=img_path, pdf_path=pdf_path)
五、pdf转word
先安装:pip install pdf2docx
from pdf2docx import Converter
pdf_file = r'D:\桌面\论文阅读笔记.pdf'
docx_file = r'D:\桌面\论文阅读笔记.docx'
cv = Converter(pdf_file)
cv.convert(docx_file, start=0, end=None)
cv.close()
六、pdf转图片
先安装:pip install pdf2image
from pdf2image import convert_from_path
pages = convert_from_path('D:\桌面\论文阅读笔记.pdf', 500)
# 保存
for page in pages:
page.save('D:\桌面\论文阅读笔记.jpg', 'JPEG')
七、csv转excel
import pandas as pd
data = pd.read_csv('F:/train.csv',index_col=0)
data.to_excel('F:/train.xlsx',encoding='utf-8')
八、excel转csv
import pandas as pd
data = pd.read_excel('F:/train.xlsx',index_col=0)
data.to_csv('F:/train.csv',encoding='utf-8')