[数据分析笔记] 用户消费行为分析
文章目录
-
- 0.导入数据
- 1.进行用户消费趋势分析(按月)
- 2.用户个体消费
- 3.用户消费行为
- 4.复购率和回购率分析
0.导入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
columns = ['user_id', 'order_dt', 'order_products', 'order_amount']
df = pd.read_table('CDNOW_master.txt', names=columns, sep='\s+')
- user_id: 用户ID
- order_dt: 购买日期
- order_products: 购买产品数
- order_amount: 购买金额
df.head()
![[数据分析笔记] 用户消费行为分析_第1张图片](http://img.e-com-net.com/image/info8/765bbeddd22f47968a1317707b7d4fe0.jpg)
df.info()
![[数据分析笔记] 用户消费行为分析_第2张图片](http://img.e-com-net.com/image/info8/e84214ba25c84369b09fe032658606f2.jpg)
df.describe()
![[数据分析笔记] 用户消费行为分析_第3张图片](http://img.e-com-net.com/image/info8/c8abfe95f77b45cfa53d9c72981ef0d8.jpg)
- 大部分订单只消费了少量商品(平均2.4),有一定极值干扰
- 用户的消费金额比较稳定,平均消费35元,中位数在26元,有一定极值干扰
df['order_dt'] = pd.to_datetime(df.order_dt, format="%Y%m%d") # 解析日期
df['month'] = df.order_dt.values.astype('datetime64[M]') # 生成month变量
df.head()
![[数据分析笔记] 用户消费行为分析_第4张图片](http://img.e-com-net.com/image/info8/1997e8e2dcd546859652a373f3220a7d.jpg)
1.进行用户消费趋势分析(按月)
- 每月的消费总金额
- 每月的消费次数
- 每月的产品购买量
- 每月的消费人数
grouped_month = df.groupby('month') # 按月聚合
order_month_amount = grouped_month.order_amount.sum() # 加总每月消费额
order_month_amount.head()
![[数据分析笔记] 用户消费行为分析_第5张图片](http://img.e-com-net.com/image/info8/679f99b339d8481abc4d024b18a351c4.jpg)
# 每月总金额折线图
order_month_amount.plot()
![[数据分析笔记] 用户消费行为分析_第6张图片](http://img.e-com-net.com/image/info8/36c7c47e847b47d0a196431f097554b2.jpg)
由上图可知,消费金额在前三个月达到最高峰,后续消费额较为稳定,有轻微下降趋势
# 每月消费订单数
grouped_month.user_id.count().plot()
![[数据分析笔记] 用户消费行为分析_第7张图片](http://img.e-com-net.com/image/info8/f0e22dd107ac49ad8a44280d1da3ad04.jpg)
前三个月消费订单数在10000笔左右,后续月份的平均消费人数在2500人左右
# 每月消费商品总数
grouped_month.order_products.sum().plot()
![[数据分析笔记] 用户消费行为分析_第8张图片](http://img.e-com-net.com/image/info8/4f1a9a0e2db54a8ba0f29d74acb29acd.jpg)
# 每月消费人数
# user_id 作为输入,去重
df.groupby('month').user_id.apply(lambda x:len(x.drop_duplicates())).plot()
![[数据分析笔记] 用户消费行为分析_第9张图片](http://img.e-com-net.com/image/info8/7d88a8600465489fb03a72c9c0fcd789.jpg)
# 另一种方法去重
(df.groupby(['month', 'user_id']).count().reset_index()).groupby('month').user_id.count().plot()
![[数据分析笔记] 用户消费行为分析_第10张图片](http://img.e-com-net.com/image/info8/893ccdf88a934a2e9c847fd1e8421c03.jpg)
- 每月消费人数低于每月消费次数,但差异不大
- 前三个月每月的消费人数在8000-10000之间,后续月份,平均消费人数在2000人不到
# 使用数据透视表
df.pivot_table(index = 'month',
values = ['order_products', 'order_amount', 'user_id'],
aggfunc = {'order_products': 'sum',
'order_amount': 'sum',
'user_id': 'count'}).head()
![[数据分析笔记] 用户消费行为分析_第11张图片](http://img.e-com-net.com/image/info8/7cfc4c32844e4e34885cb9ac1e8a0a17.jpg)
2.用户个体消费
- 用户消费金额、消费次数的描述统计
- 用户消费金额和消费的散点图
- 用户消费金额的分布图
- 用户消费次数的分布图
- 用户累计消费金额占比(百分之多少的用户占了百分之多少的消费额)
grouped_user = df.groupby('user_id')
grouped_user.sum().describe()
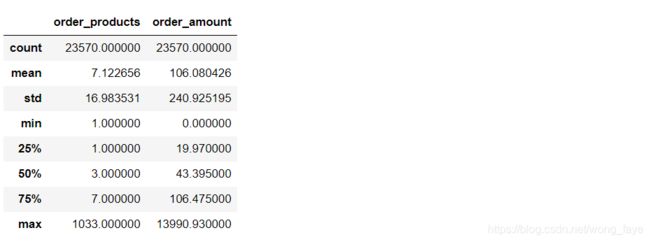
- 用户平均购买了7张CD,但是中位值只有3,说明小部分用户购买了大量的CD
- 用户平均消费106元,中位值有43,有极值干扰
grouped_user.sum().plot.scatter(x='order_amount', y='order_products')
![[数据分析笔记] 用户消费行为分析_第12张图片](http://img.e-com-net.com/image/info8/eab5888612e94d30a80ceceeb81b3bd6.jpg)
# order_amount < 4000的数据
grouped_user.sum().query('order_amount < 4000').plot.scatter(x='order_amount', y='order_products')
![[数据分析笔记] 用户消费行为分析_第13张图片](http://img.e-com-net.com/image/info8/6a7008c3409d482ab4bb25b092ae8bf7.jpg)
# 消费金额分布
grouped_user.sum().order_amount.plot.hist(bins=20)
![[数据分析笔记] 用户消费行为分析_第14张图片](http://img.e-com-net.com/image/info8/eec33c41c15c484da0a98376af02f0db.jpg)
从直方图可知,用户消费金额,绝大部分呈现集中趋势,小部分异常值干扰了判断,可以使用过滤操作排除异常
# 购买产品数
grouped_user.sum().query('order_products < 100').order_products.hist(bins=20)
![[数据分析笔记] 用户消费行为分析_第15张图片](http://img.e-com-net.com/image/info8/7583a688485c4107a46ab42877b133f8.jpg)
使用切比雪夫定理过滤异常值
user_cumsum = grouped_user.sum().sort_values('order_amount').apply(lambda x:x.cumsum() / x.sum())
user_cumsum.head()
![[数据分析笔记] 用户消费行为分析_第16张图片](http://img.e-com-net.com/image/info8/29ccf67a6aa34eb4b40ac97aebd50b0a.jpg)
user_cumsum.tail()
![[数据分析笔记] 用户消费行为分析_第17张图片](http://img.e-com-net.com/image/info8/b694e9394858421d9d5dbbf16af8472e.jpg)
user_cumsum.reset_index().order_amount.plot()
![[数据分析笔记] 用户消费行为分析_第18张图片](http://img.e-com-net.com/image/info8/fcebde60f44847aeb69faed6a4423c24.jpg)
按用户消费金额进行升序排列,由图可知50%的用户仅贡献了15%的消费额度
3.用户消费行为
- 用户第一次消费(首购)
- 用户最后一次消费
- 新老客消费比
- 多少用户仅消费了一次
- 每月新客占比
- 用户分层
- RFM
- 新、老、活跃、回流、流失
- 用户购买周期(按订单)
- 用户消费周期描述
- 用户消费周期分布
- 用户生命周期(按第一次和最后一次消费)
- 用户生命周期描述
- 用户生命周期分布
grouped_user.min().order_dt.value_counts().plot()
![[数据分析笔记] 用户消费行为分析_第19张图片](http://img.e-com-net.com/image/info8/cf851ff8de154ccc85c98e9ac9370bdf.jpg)
- 用户第一次购买分布集中在前三个月
- 其中,在2月11日至2月25日有一次剧烈的波动
grouped_user.max().order_dt.value_counts().plot()
![[数据分析笔记] 用户消费行为分析_第20张图片](http://img.e-com-net.com/image/info8/197acc8c7a4747aaaaed5d1009a367c4.jpg)
- 用户最后一次购买的分布比第一次广
- 大部分最后一次购买集中在前三个月,说明有很多用户购买了一次之后就不再进行购买
- 随着时间的递增,最后一次购买数也在递增,消费呈现流失上升的状况
user_life = grouped_user.order_dt.agg(['min', 'max'])
user_life.head()
![[数据分析笔记] 用户消费行为分析_第21张图片](http://img.e-com-net.com/image/info8/066a2ea98357495ca551b1fb70581f21.jpg)
(user_life['min'] == user_life['max']).value_counts()

有一半用户只消费了一次
rfm = df.pivot_table(index = 'user_id',
values = ['order_products', 'order_amount', 'order_dt'],
aggfunc = {'order_dt': 'max',
'order_amount': 'sum',
'order_products': 'sum'})
rfm.head()
![[数据分析笔记] 用户消费行为分析_第22张图片](http://img.e-com-net.com/image/info8/c9f6ec3546f24cf7aa11220647bd0a59.jpg)
# 距今天数 转换时间格式 把单位消除
rfm['R'] = -(rfm.order_dt - rfm.order_dt.max()) / np.timedelta64(1, 'D')
# 重命名
rfm.rename(columns= {'order_products': 'F', 'order_amount': 'M'}, inplace=True)
rfm.head()
![[数据分析笔记] 用户消费行为分析_第23张图片](http://img.e-com-net.com/image/info8/b518fc1b0e9e4424885a195610eb7d0e.jpg)
rfm[['R', 'F', 'M']].apply(lambda x:x-x.mean()).head() # 负号表示小于平均值
![[数据分析笔记] 用户消费行为分析_第24张图片](http://img.e-com-net.com/image/info8/f8ded9e2567c4ce6bb97330d4f1c9d54.jpg)
def rfm_func(x):
level = x.apply(lambda x:'1' if x>=0 else '0') # x大于0表示高于平均值,否则低于平均值
label = level.R + level.F + level.M
d = {
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要发展客户',
'001':'重要挽留客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般发展客户',
'000':'一般挽留客户'
}
result = d[label]
return result
rfm['label'] = rfm[['R', 'F', 'M']].apply(lambda x:x-x.mean()).apply(rfm_func, axis=1)
rfm.head()
![[数据分析笔记] 用户消费行为分析_第25张图片](http://img.e-com-net.com/image/info8/6c9da694c5cc47de9296ea8eb7701846.jpg)
rfm.groupby('label').sum()
![[数据分析笔记] 用户消费行为分析_第26张图片](http://img.e-com-net.com/image/info8/208b27a7a13c4f8d862fcb59a86a5c55.jpg)
rfm.loc[rfm.label == '重要价值客户', 'color'] = 'coral'
rfm.loc[~(rfm.label == '重要价值客户'), 'color'] = 'c' # 除了重要价值客户之外的客户
rfm.plot.scatter('F', 'R', c=rfm.color)
![[数据分析笔记] 用户消费行为分析_第27张图片](http://img.e-com-net.com/image/info8/8ea9e91cf2194db5b7e987fa3c9575aa.jpg)
rfm.head()
![[数据分析笔记] 用户消费行为分析_第28张图片](http://img.e-com-net.com/image/info8/579889f706b34994ab19140fa1890135.jpg)
从RFM分层可知,大部分用户为重要保持客户,但是这是由于极值的影响,所以RFM的划分标准
- 尽量用小部分的用户覆盖大部分的额度
- 不要为了数据好看划分等级
pivoted_counts = df.pivot_table(index = 'user_id',
columns = 'month',
values = 'order_dt',
aggfunc = 'count').fillna(0)
pivoted_counts.head()
![[数据分析笔记] 用户消费行为分析_第29张图片](http://img.e-com-net.com/image/info8/42f9757c019345cbbc7d0df6c725c2ec.jpg)
df_purchase = pivoted_counts.applymap(lambda x: 1 if x > 0 else 0)
df_purchase.tail()
![[数据分析笔记] 用户消费行为分析_第30张图片](http://img.e-com-net.com/image/info8/7a5d630ca8914bdd868a505c24731a46.jpg)
def active_status(data):
status = []
for i in range(18):
# 若本月没有消费
if data[i] == 0:
if len(status) > 0: # 如果有记录
if status[i-1] == 'unreg': # 如果前一个月未注册
status.append('unreg') # 那么就为未注册
else:
status.append('unactive') # 否则就为不活跃
else: # 如果没有记录就为未注册
status.append('unreg')
# 若本月消费
else:
if len(status) == 0: # 如果记录为空,那么就为本月第一次消费
status.append('new') # 该用户为新用户
else: # 如果记录不为空
if status[i-1] == 'unactive': # 如果前一个月不活跃
status.append('return') # 该用户为回流用户
elif status[i-1] == 'unreg': # 如果未注册
status.append('new') # 该用户为新用户
else:
status.append('active') # 否则该用户为活跃用户
return pd.Series(status)
若本月没有消费
- 若之前未注册,则依旧为未注册
- 若之前有消费,则为流失/不活跃
- 其他情况,为未注册
若本月有消费
- 若是第一次消费,则为新用户
- 若之前有过消费,上个月为不活跃,则为回流
- 若上个月为未注册,则为新用户
- 除此之外,为活跃
print(df_purchase.columns)
![[数据分析笔记] 用户消费行为分析_第31张图片](http://img.e-com-net.com/image/info8/f6b99aaf316e4b9bb94d5ad5d5dc5efe.jpg)
purchase_stats = df_purchase.apply(active_status, axis=1)
purchase_stats.columns = df_purchase.columns
purchase_stats.head()
![[数据分析笔记] 用户消费行为分析_第32张图片](http://img.e-com-net.com/image/info8/4e0ad39339734a8a8c727f363f02b759.jpg)
purchase_stats.tail()
![[数据分析笔记] 用户消费行为分析_第33张图片](http://img.e-com-net.com/image/info8/89f7d323c28f4280861093e486fe0fe7.jpg)
purchase_stats_ct = purchase_stats.replace('unreg', np.NaN).apply(lambda x:pd.value_counts(x))
purchase_stats_ct.head()
![[数据分析笔记] 用户消费行为分析_第34张图片](http://img.e-com-net.com/image/info8/10f52a92e47743ca8dc95211d5d785b2.jpg)
purchase_stats_ct.fillna(0).T.head()
![[数据分析笔记] 用户消费行为分析_第35张图片](http://img.e-com-net.com/image/info8/2e1de1eea16540a7af473264b27a6206.jpg)
purchase_stats_ct.fillna(0).T.apply(lambda x:x/x.sum(), axis=1)
![[数据分析笔记] 用户消费行为分析_第36张图片](http://img.e-com-net.com/image/info8/c3859380869649f5891b14e084b0af23.jpg)
purchase_stats_ct.fillna(0).T.plot.area()
![[数据分析笔记] 用户消费行为分析_第37张图片](http://img.e-com-net.com/image/info8/adbbb5b8fc4e440b8071a78efb15ae5c.jpg)
order_diff = grouped_user.apply(lambda x:x.order_dt - x.order_dt.shift())
order_diff.head(10)
![[数据分析笔记] 用户消费行为分析_第38张图片](http://img.e-com-net.com/image/info8/54d0bdb668234e658b505b7dc96cf41b.jpg)
df.order_dt.head(10)
![[数据分析笔记] 用户消费行为分析_第39张图片](http://img.e-com-net.com/image/info8/b225a66d755c43fdae0753217ed031fc.jpg)
df.order_dt.shift().head(10) # 把所有数据往下移动一位
![[数据分析笔记] 用户消费行为分析_第40张图片](http://img.e-com-net.com/image/info8/b622d8237d0f46099e44abcd7bb86de8.jpg)
order_diff.describe()
![[数据分析笔记] 用户消费行为分析_第41张图片](http://img.e-com-net.com/image/info8/3dcff5196a604a559d11b94387330a5b.jpg)
(order_diff / np.timedelta64(1, 'D')).hist(bins=20)
![[数据分析笔记] 用户消费行为分析_第42张图片](http://img.e-com-net.com/image/info8/fb7dcd03f14f4f9297b102875ff5b6a7.jpg)
- 订单周期呈指数分布
- 用户的平均购买周期是68天
- 绝大部分用户的购买周期都低于100天
(user_life['max'] - user_life['min']).describe()
![[数据分析笔记] 用户消费行为分析_第43张图片](http://img.e-com-net.com/image/info8/d88bca7cd8b94261ab782a378fb308e7.jpg)
((user_life['max'] - user_life['min']) / np.timedelta64(1, 'D')).hist(bins= 40)
![[数据分析笔记] 用户消费行为分析_第44张图片](http://img.e-com-net.com/image/info8/dc5734fd8efe4d34ba32ee68da9d1163.jpg)
用户的生命周期受只购买一次的用户影响比较厉害
u_1 = ((user_life['max'] - user_life['min']).reset_index()[0] / np.timedelta64(1, 'D'))
u_1[u_1 > 0].hist(bins = 40)
![[数据分析笔记] 用户消费行为分析_第45张图片](http://img.e-com-net.com/image/info8/260678a2170e4b8094934091e06e2540.jpg)
4.复购率和回购率分析
- 复购率
- 自然月内,购买多次的用户占比
- 回购率
- 曾经购买过的用户在某一时期内的再次购买的占比
pivoted_counts.head()
![[数据分析笔记] 用户消费行为分析_第46张图片](http://img.e-com-net.com/image/info8/7ba1b94356d94729b4e8abd9831a4431.jpg)
# 大于1 -> 1
# 等于1 -> 0
# 等于0 -> NaN
purchase_r = pivoted_counts.applymap(lambda x: 1 if x > 1 else np.NaN if x == 0 else 0)
purchase_r.head()
![[数据分析笔记] 用户消费行为分析_第47张图片](http://img.e-com-net.com/image/info8/91d48c1daead464185fd5abf8c975e17.jpg)
(purchase_r.sum() / purchase_r.count()).plot(figsize=(10, 4))
![[数据分析笔记] 用户消费行为分析_第48张图片](http://img.e-com-net.com/image/info8/e3e2f63e7c7240a2859cf0bb3faa480a.jpg)
复购率稳定在20%左右,前三个月因为有大量新用户涌入,而这批用户只购买了一次,所以导致复购率降低
df_purchase.head()
![[数据分析笔记] 用户消费行为分析_第49张图片](http://img.e-com-net.com/image/info8/cdb04aedee2245a99eb0a925e2e65b46.jpg)
# 1 -> 当月消费过,次月依旧消费
# 0 -> 当月消费过,次月没有消费
# NaN -> 当月没有消费
def purchase_back(data):
status = []
for i in range(17):
if data[i] == 1:
if data[i+1] == 1:
status.append(1)
if data[i+1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series(status)
purchase_b = df_purchase.apply(purchase_back, axis=1)
purchase_b.head(5)
![[数据分析笔记] 用户消费行为分析_第50张图片](http://img.e-com-net.com/image/info8/85c8a2abfc3940c5aeb2728c8509574a.jpg)
(purchase_b.sum() / purchase_b.count()).plot(figsize=(10, 4))
![[数据分析笔记] 用户消费行为分析_第51张图片](http://img.e-com-net.com/image/info8/d5d4da36467843449c3b313ea3c331a9.jpg)