NLP——8.基于统计的翻译系统
基于统计的机器翻译:mosesdecoder作为比对翻译效果的baseline,如果不如这个的效果,就说明测试系统效果不算好。
首先看看一共需要以下三个模型:

语言模型:用来评估这句话的通畅程度。
1、需要从大量的语料中学习出在新的句子知道对应的英语翻译是什么。
2、翻译模型:实质是基于短语的(不是基于单词的翻译)
3、平行语料:只要中英文两个文件中行是相同的,那他们就是相互对应的中英文
4、在大量的平行语料中学习出该怎样去完成。可能会对词进行一些表示,例如word2vec等将文字表示为计算机能读懂的向量。然后做后续的映射。
5、基于统计的机器翻译就是做大量运算之后得到一个统计表:中文对应英文某表达的概率(可能有很多对应,但是每种对应方式会有不同大小的概率值)
6、对于数字、日期、时间、网址等这类不需要翻译(翻译前后都是一模一样的数字),无需为他们在统计表中记录下来,因此可以提前将所有苏子都转化为$number标记好,然后在训练时就直接原封不动的保留下来即可,不必放入统计表中计算映射关系。
这类均可以通过自行定义泛化名进行原文替换。同时,泛化可以很好地解决数据稀疏的问题(因为所给的这些量只会有很少的次数对应,有可能所有个文档中就出现一次)
因此,可以对所有你认为有必要且能规整为一个固定模式的量都进行这样的泛化处理。
7、提前将训练数据做好分词(可以利用jieba等)对整个文件做好分词。如果不做这些预处理,会有很多冗余的信息量,会浪费很多内存。
1.双语数据预处理
目标:了解和学习开发汉英双语数据预处理模块。
双语数据预处理是统计机器翻译系统构建的第一步,为词对齐处理提供分词后的 双语数据。预处理的工作本质上就是双语数据的分词处理,与传统分词不同的一 点在于需要对一些特定类型词汇进行泛化处理,如数字词汇“123.45”泛化为 “$number”来代替原文。本讲中以汉英双语数据为处理内容。
中文分词预处理
采用传统基于词典的正向最大匹配法来完成中文分词。基本流程如图所示:
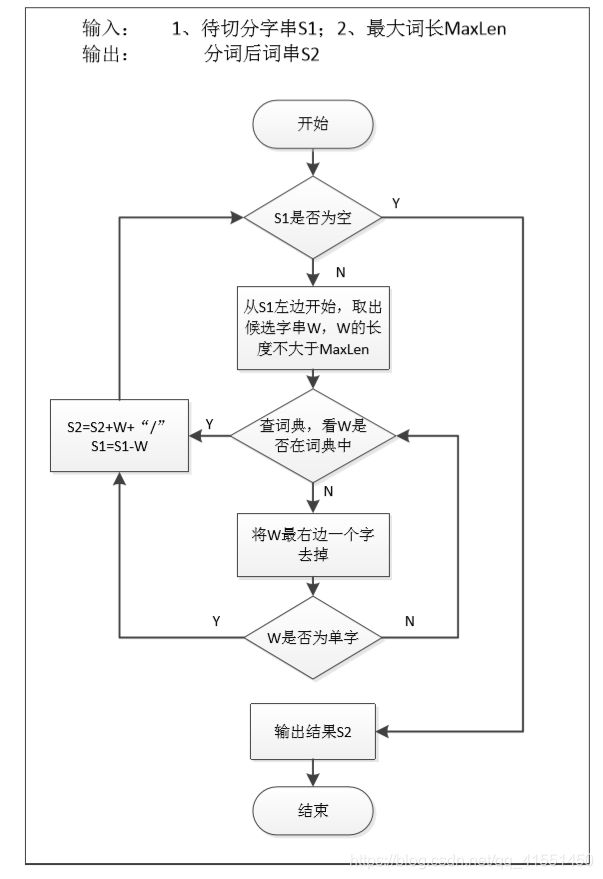
由于数字、日期、时间、网址等不可枚举,无法通过词典简单查找来分词。 可以采用正则表达式或者自动机进行自动识别,并给予特殊名字进行泛化。例如:
数字类型 $number 如:123
日期类型 $date 如:1993 年 12 月 3 日
时间类型 $time 如:3:10
网址等类型 $literal 如:http://www.niutrans.com
实际上大家可以总结更多类型,并自行定义泛化名字进行替换原文。泛化的 目的是为了有效解决数据稀疏问题。
需要注意一点的是,建议不要对组织机构名进行捆绑为一个词汇。例如将“东 北大学信息学院”最好分成两个词“东北大学”“信息学院”。这样做的好处是为 了有助于后面规则抽取模块抽取出更多翻译规则。
英文分词处理
相对于中文分词处理来说,英文分词主要处理三个问题:
- 将所有大写字母改为小写字母;
- 将英文句尾结束符与句尾最后一个单词用空格分开;
- 同样将数字、日期、时间、网址等不可枚举的类型进行识别,然后分 别采用特殊名字进行泛化处理。
例如双语句对:
中文:4 月 14 日我买了 10 本书。
英文:I bought 10 books on April 14.
预处理结果:
中文:$date 我 买 了 $number 本 书 。
英文:i bought $number books on $date
其它说明:
1) 中文的全角字符可以考虑改写为半角字符来处理;
2) 同一类型的泛化名字在中英文中最好一样,如中文/英文数字=>$number;
3) 也可以采用 CRF 或者语言模型来实现高性能中文分词;
4) 注意区分英文的句尾符号“.”和“Mr. Smith”的“.”;
5) 双语句对的泛化结果需要检查一致性,例如中文句子中包含 $number,正 常情况下,英文句子中也应该包含 $number 等;
6) 目前有很多开源的分词工具可以被使用,如 NiuTrans 提供的双语数据预 处理工具从 http://www.nlplab.com/NiuPlan/NiuTrans.YourData.html 下载。
2.词对齐
IBM的思路:EM算法。
由于语序问题肯定不能一个个词直接翻译。因此需要找到内在的词对齐的方式。
在IBM出现之前,采用过很多句法上的努力。例如利用语法syntax分析(现在已经不怎么用)。因为当句子很长的、表达方式越来越多元化的时候,如果想要通过直接归纳出来一个固定模式的方法效果并不好。
IBM提出直接用统计的方法来实现,直接找到词与词之间的对应关系。因此,当你送入大量语料库的时候,机器进行观察,很多句话里,都有中文中出现某词的时候英语中一定会出现另外一个词。
采用共现(共同出现)来分析:






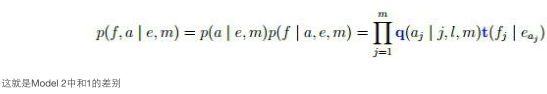

![]()


目标:学会使用词对齐工具 GIZA++并自行开发词对齐对称化程序。
词对齐是统计机器翻译系统构建的第二步,经过第一步双语数据预处理后, 得到分词后的双语数据。而词对齐的任务就是要得到中英文词语的对应关系。
GIZA++的使用
GIZA++是 GIZA(SMT 工具包 EGYPT 的一个组成部分)的扩展,扩展部分 主要由 Franz Josef Och 开发。GIZA++主要算法是 IBM model、HMM 等。
- GIZA++运行环境:Linux,并预装软件 gcc、g++。
- GIZA++下载地址: http://code.google.com/p/giza-pp/downloads/detail?name=giza-pp-v1.0.7.tar.gz
- 编译:
a) 首先进入到 GIZA++根目录
b) 解压包,指令:tar zxvf giza-pp-v1.0.7.tar.gz
c) 进入到解压后的目录,指令:cd giza-pp
d) 编译,指令:make - GIZA++运行:
a) 新建目录 Alignment,并将编译后的 GIZA+±v2 目录下的“GIZA++”、 “snt2cooc.out”、“plan2snt.out”文件和 mkcls-v2 目录下的“mkcls”文件,拷贝到 Alignment 目录下,同时将预处理后的文件 c.txt 和 e.txt 作为 GIZA++工具的 输入文件放到其中。
b) 在终端依次运行以下命令,获得下一步需要的文件:c2e.A3.final 和 e2c.A3.final。
$> ./plain2snt.out e.txt c.txt
$> ./snt2cooc.out c.vcb e.vcb c_e.snt> cooc.ce
$> ./snt2cooc.out e.vcb c.vcb e_c.snt > cooc.ec
$> ./mkcls -m2 -c80 -n10 -pe.txt -Ve.vcb.classes opt
$> ./mkcls -m2 -c80 -n10 -pc.txt -Vc.vcb.classes opt
$> ./GIZA++ -S c.vcb –T e.vcb –C c_e.snt -CoocurrenceFile cooc.ce -O c2e
$> ./GIZA++ -S e.vcb –T c.vcb –C e_c.snt -CoocurrenceFile cooc.ec -O e2c
词对齐对称化
由于 GIZA++程序中,原语=>目标语和目标语=>原语的对齐过程是彼此独立 的,因此会产生两个对齐文件,词对齐对称化的任务就是通过一定的算法合并这 两个对齐文件。
1、输入:GIZA++运行目录中的 c2e.A3.final 文件和 e2c.A3.final 文件,格式如下:
- c2e.A3.final 文件的一个句对:
# Sentence pair (1) source length 5 target length 7 alignment score : 3.53407e-09
the weather is very good today .
NULL ({ 1 3 6 }) 今天 ({ }) 天气 ({ 2 }) 真 ({ 4 }) 好 ({ 5 }) . ({ 7 })
- e2c.A3.final 文件的一个句对
# Sentence pair (1) source length 7 target length 5 alignment score : 5.24219e-08
今天 天气 真 好 .
NULL ({ }) the ({ 2 }) weather ({ 2 }) is ({ }) very ({ 3 }) good ({ 4 }) today ({ 1 }) . ({ 5 })
其中,第三行大括号里面的数字,代表该大括号前面的词语对应的目标语的词的 位置。
- 如:“天气 ({ 2 })”中的“2”表示对应的英语中的“weather”。 “weather ({ 2 })”中的“2”表示对应的汉语中的“天气”。
- 因此,“天气”和“weather”构成了一个双向对齐“天气”“weather”。 “today ({ 1 })”中的“1”表示对应的汉语中的“今天”。 而“今天”后的({})为空,并未与“today”对应。
- 因此,“today”和“今天”就构成了一个单向对齐“today”=>“今天”。
- 另外,“NULL ({ 1 3 6 })”表示英文中“the”“ is”“ today”对空,即形成空 对齐“the”=>“NULL”,“ is”=>“NULL”,“today”=>“NULL”。
2、输出:将两个输入文件通过算法合并为对齐文件,文件中每一行格式如下:
0-5 1-0 1-1 2-3 3-4 4-6
其中, 0-5表示经过算法合并后,中文中第0个词“今天”与英文中第5个词“today” 对齐。
3、词对齐对称化算法:
算法流程如下:
Matrix[src_len][trg_len];
neighboring =(上,下,左,右,左上,左下,右上,右下);
寻找对齐节点,将双向对齐节点加入 Alignment
- 循环直到没有新节点出现
- 遍历Alignment,查看该节点的 neighboring
若某一 neighboring 单向对齐,且该点的原语或目标语未双向对齐
则加入该节点到 Alignment- 遍历 Matrix
- 如果存在某节点单向对齐,且该点的原语或目标语未双向对齐 则加入该节点到Alignment
该算法与 Philipp Koehn 的 GROW-DIAG-FINAL 算法类似。
算法说明:
以上面的句对作为示例:
中文到英文:
# Sentence pair (1) source length 5 target length 7 alignment score : 3.53407e-09
the weather is very good today .
NULL ({ 1 3 6 }) 今天 ({ }) 天气 ({ 2 }) 真 ({ 4 }) 好 ({ 5 }) . ({ 7 })
英文到中文:
# Sentence pair (1) source length 7 target length 5 alignment score : 5.24219e-08
今天 天气 真 好 .
NULL ({ }) the ({ 2 }) weather ({ 2 }) is ({ }) very ({ 3 }) good ({ 4 }) today ({ 1 }) . ({ 5 })
-
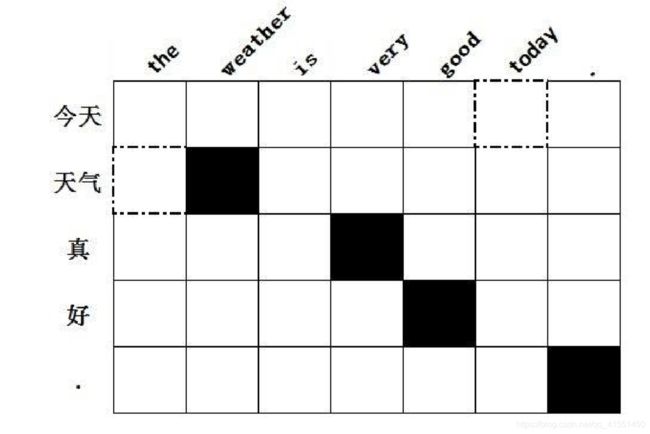
首先,找到对齐的词语对,将所有双向对齐加入 Alignment。如图(矩阵中 实心方格表示双向对齐,虚线空心方格表示单向对齐):
-
遍历 Alignment,对其邻居进行检测,如果邻居中存在单向对齐的点,并且 该点的两个词中存在一个没有与任何词双向对齐,则将该点加入 Alignment。 循环这个操作直到没有新节点加入。如上图中,当遍历到“weather-天气”时, 发现该点左边存在单向对齐点“the-天气”,且“the”尚未与任何词双向对 齐,则将该点加入 Alignment。

-
最后遍历矩阵中所有节点,如果存在单向对齐的点,并且该点的两个词中存在一个没有与任何词双向对齐,则将该点也加入 Alignment。如图,当遍历 到“today-今天”时,发现该点是一个单向对齐点,并且“today”尚未与任何 词双向对齐,则将该点加入 Alignment。

-
最后获得最终的对齐信息输出到文件,如上图所示,得到的对称化的词对齐 信息为:
0-5 1-0 1-1 2-3 3-4 4-6
所有的ML算法中采用的训练数据都是平行语料,都是不跨行的。
3.短语翻译表构造 --短语抽取
目标:深刻理解基于短语统计机器翻译系统中短语(指代短语对 )抽取的基本算法,可自行开发短语抽取模块。
短语抽取是统计机器翻译系统构建的第三步,经过第二步词对齐后,获得双语平行句对间的词对齐信息。短语抽取是短语翻译表构造的第一步(短语翻译表构造的第二步为短语翻译表概率估计 ),短语抽取的任务是从含有词对齐信息的双语平行句对中学习解码器在翻译过程中使用的翻译短语。
示例短语
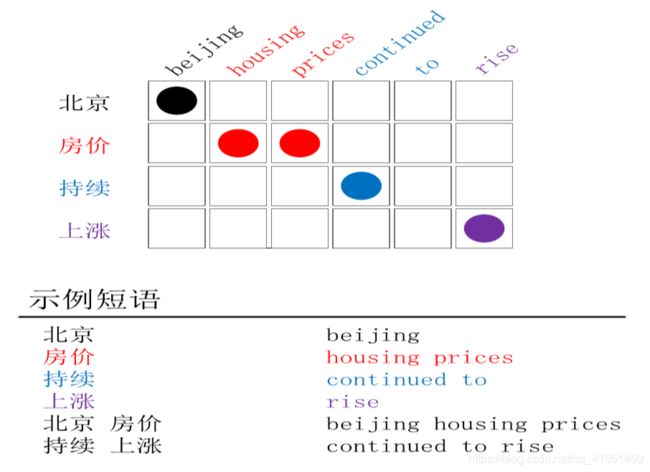
短语抽取的本质是从含有词对齐信息的平行句对中抽取基于短语的统计机器翻译系统中使用的翻译短语。图 1 中展示了从含有词对齐信息的双语平行句对(图 1 中上方图所示)中抽取的短语对(图1 中下方的“示例短语”所示)。从图 1 中可以看出,在给定词对齐信息的双语平行句对中,理想情况下是可以抽取与词对齐保持一致的短语对,如“示例短语”中所示的短语对。
一致性短语
使用含有词对齐信息的双语平行句对进行短语抽取时,抽取出的短语对需要与词对齐保持一致。
下面给出一致性的定义。

短语抽取算法
在定义“一致性短语”后,本节给出在含有词对齐信息的双语平行数据中抽取所有满足“一致性” 定义短语对的算法。
算法 1 的核心思想:长度从 1 到 I 遍历目标语端词串并且在源语端找到与之匹配的最小词串。如果目标语端词串中所有词汇在词对齐中对应的项都在与之匹配的源语词串范围内,并且源语端词串中所有词汇在词对齐中所对应的项都在目标语词串范围内时,同时源语、目标语词串不能只包含对空词汇,此时找到的源语端、目标语端词串便与词对齐保持一致,称双语端词串对为短语对。
算法 1 详细解释如下:

- 算法第 1 行与第 2 行在目标语端进行二重循
环,目的是遍历目标语端所有可能出现的短
语;算法第 2 行设臵当前目标语端词串的起
始位置。 - 算法第 3 行设置当前目标语端词串的结束位置。
- 算法第 4 行设置当前源语端词串的起始位置与结束位置。起始位臵设置为源语句子长度的最大值,结束位置设置为 0。该设置可快速判断是否可找到与词对齐保持一致的短语。
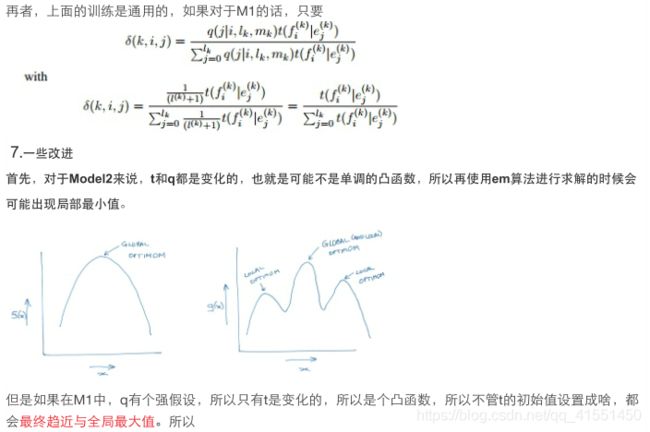
- 算法第 5-10 行确保目标语端词串 e i 1 i 2 e^{\over{i_2}} _{i_1} ei1i2 中的所有词汇在词对齐中对应的词汇在源语端词串 f f 1 f 2 f^{\over{f_2}} _{f_1} ff1f2范围内。
- 算法第 11 行使用 e x t r a c t ( j 1 , j 2 , i 1 , i 2 ) extract (j_1,j_2,i_1,i_2) extract(j1,j2,i1,i2)函数对找到的可能短语对进行验证和扩展,确保找到短语对与词对齐保持一致。
算法 2 中 extract 函数是算法 1 中第 11 行使用的对找到的短语进行验证和扩展的函数。在与词对齐保持一致的短语对的扩展过程中,主要是短语对中源语端与目标语端边缘对空词汇的扩展。根据一致性的定义,边缘对空词汇不会影响短语一致性的性质,同时,抽取更多边缘对空扩展对空短语可获得更多上下文信息、可适当缓解词对齐不精确带来的问题。
算法 2 详细解释如下:

- 算法第 1-3 行保证找到的源语端词串中至少
有一个词汇在词对齐中对应的项在目标语词
串 e i 1 i 2 e^{\over{i_2}} _{i_1} ei1i2 内。 - 算法第 4-8 行确保源语端词串 f j 1 j 2 f^{\over{j_2}} _{j_1} fj1j2 中的所有词 汇在词对齐中对应的词汇在目标语端词串 e i 1 i 2 e^{\over{i_2}} _{i_1} ei1i2 范围内,即找到与词对齐一致的短语对。
- 算法第 9 行初始化短语对集合为空。
- 算法第 10-18 行扩展与词对齐保持一致的短
语对,如果找到的短语对的源语端或目标语
端的边界词汇对空,则扩展该短语对,将新
短语对加入到短语对集合 E 中。 - 算法第 19 行返回短语对集合 E。
短语抽取流程
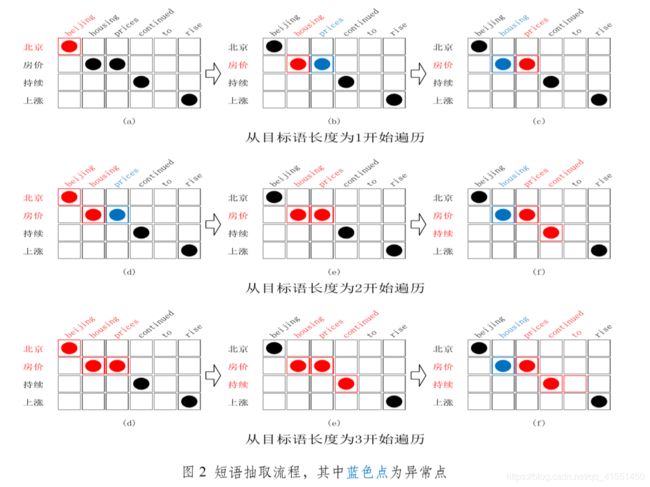
图 2 展示应用短语抽取算法 1、2 抽取短语对的基本流程。其中“从目标语长度 n 开始循环”为算法 1 的第 1 行;每组三个图如“(a),(b)和©”为算法 1 中第 2 行至第 12 行。图(2)中(a)图展示抽取的一个与词对齐保持一致的短语对“北京,beijing”; (b)图展示一个非法的短语对“房价,housing”,其中目标语端词汇“prices”为异常点。
满足一致性的短语
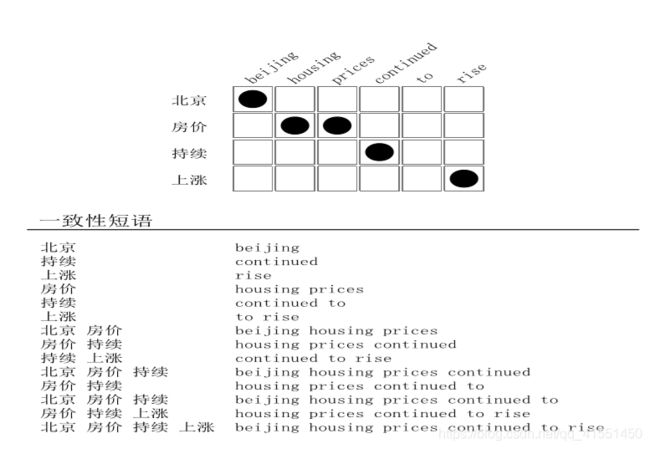
- 图 3 双语数据与词对齐信息中抽取满足一致性定义的所有短语对,以算法 1 实际短语抽取顺序排序
图 3 中所示“一致性短语”为根据上文“一致性”定义及“算法 1、2”从示例含有词对齐信息
的双语平行句对中抽取的所有与词对齐保持一致的短语对。
参考资源
- NiuTrans 源码:http://www.nlplab.com/NiuPlan/NiuTrans.ch.html 下载 NiuTrans 源码包, NiuTrans 源码包目录/NiuTrans/src/NiuTrans.PhraseExtractor/ 下,phrasetable_extractor.cpp 与 phrasetable_extractor.h 两文件实现短语抽取功能。
- Philipp Koehn. 2010. Statistical Machine Translation. Cambridge, UK: Cambridge University Press.
- Tong Xiao, Jingbo Zhu, Hao Zhang and Qiang Li. 2012. NiuTrans: An Open Source Toolkit for Phrase-based and Syntax-based Machine Translation. In Proc. of ACL 2012, page 19-24.
4.短语翻译表构造 –概率估计
目标:深刻理解基于短语统计机器翻译系统中短语翻译表概率估计的基本步骤,可自行开发概率估计模块。
短语翻译表概率估计是统计机器翻译系统构建的第四步,经过第三步短语抽取后,获得基于短语系统使用的翻译短语对,概率估计的作用是对翻译短语对的正确性进行合理的评估。
示例短语对集合
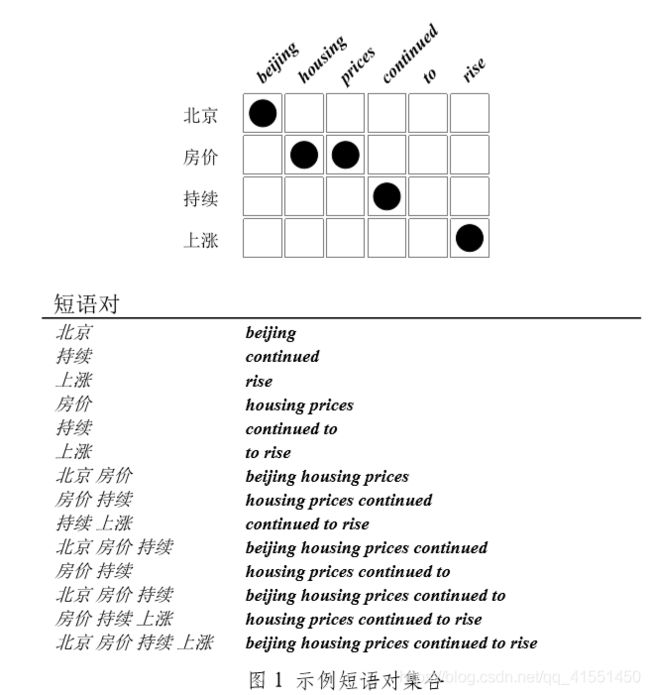
概率估计主要进行四个分数的计算,即双向(正向:“源语言->目标语言”方向;反向:“目标语言->源语言”方向 )短语翻译概率、双向词汇化权重。首先,在图 1 上方给定的含有词对齐的句对中,通过上一讲中的短语对抽取算法抽取出 14 条与词对齐保持一致的短语对,短语概率估计是在图 1 结果的基础上进行的(在进行概率估计时,短语对集合需要保留词对齐信息 )。
双向短语翻译概率
“源语言->目标语言”短语翻译概率
P r ( e ‾ ∣ f ‾ ) = c o u n t ( f ‾ , e ‾ ) ∑ e i ‾ c o u n t ( f ‾ , e i ‾ ) Pr( \overline e|\overline f )=\frac {count( \overline f,\overline e )}{\sum_{\overline {e_i}}count( \overline f,\overline {e_i} )} Pr(e∣f)=∑eicount(f,ei)count(f,e)
在公式(1)中,短语翻译概率使用极大似然估计(maximum likelihood estimation)进行计算。其中 c o u n t ( f ‾ , e ‾ ) count( \overline f,\overline e) count(f,e)表示源言语与目标语言短语对 ( f ‾ , e ‾ ) (\overline f,\overline e ) (f,e)在大规模双语平行句对中出现的频次, ∑ e i ‾ c o u n t ( f ‾ , e i ‾ ) \sum_{\overline {e_i}}count( \overline f,\overline {e_i} ) ∑eicount(f,ei)表示以 f ‾ \overline f f 作为源语言端短语的短语对在大规模双语平行句对中出现的频次。
“目标语言->源语言”短语翻译概率
P r ( f ‾ ∣ e ‾ ) = c o u n t ( e ‾ , f ‾ ) ∑ f i ‾ c o u n t ( e ‾ , f i ‾ ) Pr( \overline f|\overline e )=\frac {count( \overline e,\overline f )}{\sum_{\overline {f_i}}count( \overline e,\overline {f_i} )} Pr(f∣e)=∑ficount(e,fi)count(e,f)
反向的短语翻译概率与正向短语翻译概率计算方式相同,在公式(2)中, c o u n t ( e ‾ , f ‾ ) count( \overline e,\overline f) count(e,f) 表示目标语言与源语言短语对 ( e ‾ , f ‾ ) ( \overline e,\overline f) (e,f)在大规模双语平行句对中出现的频次, ∑ f i ‾ c o u n t ( e ‾ , f i ‾ ) \sum_{\overline {f_i}}count( \overline e,\overline {f_i} ) ∑ficount(e,fi)表示以 e ‾ \overline e e作为目标语言端短语的短语对在大规模双语平行句对中出现的频次。
当使用的含有词对齐信息的双语平行句对的规模比较大时,抽取出来的短语对集合文件是非常大的,文件大小甚至会达到几个 GB 或几十 GB。所以,在使用公式(1)、公式(2)计算短语翻译概率时,需要对文件进行外部排序,以避免文件内容全部加载至内存中。以公式(1)为例,如果对抽取出来的短语对集合文件按照源语言端短语进行排序,这样具有相同源语短语的短语对在文件中将是依次出现
的,此时仅需要同时读入有限的短语对至内存中便可进行条件概率分布分数的计算。
在基于短语的统计机器翻译系统中,经常仅仅使用双向的短语翻译概率。在这种情况下,数据的稀疏性或不可靠的数据源可能会产生一些问题。如果短语 e ‾ \overline e e和 f ‾ \overline f f 都只出现一次,那么短语翻译概率 P r ( e ‾ ∣ f ‾ ) = P r ( f ‾ ∣ e ‾ ) = 1 Pr(\overline e|\overline f)=Pr(\overline f|\overline e)=1 Pr(e∣f)=Pr(f∣e)=1,这通常过高的估计了这种短语对的可靠性。为了判断不经常出现的短语对是否可靠,通常做法是将短语对分解成词的翻译,这样就可以检查短语对的匹配程度,这种方法称为词汇化加权,该方法是一种基本的平滑方法。
双向词汇化翻译概率
“源语言->目标语言”词汇化加权
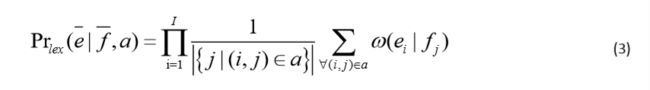
词汇化加权(lexical weighting)特征是将源语言端和目标语言端短语分解成词汇,进而检查词汇间的匹配程度。即源语言端短语 f ‾ \overline f f 中词汇 f 1 . . . f J f_1...f_J f1...fJ与目标语言端短语e中词汇 e ! . . . e I e_!...e_I e!...eI的匹配程度。其中 ω ( e i ∣ f j ) \omega(e_i|f_j) ω(ei∣fj)计算公式如公式(4)所示,该公式可以从含有词对齐的大规模平行句对中进行估计。在公式(4)中, c o u n t ( f ‾ j , e ‾ i ) count (\overline f_j, \overline e_i) count(fj,ei) 表示的是词对 ( f j , e i ) (f_j ,e_i ) (fj,ei)在大规模双语平行句对中出现的频次, ∑ e i c o u n t ( f j , e i ) \sum_{{e_i}}count( f_j, {e_i} ) ∑eicount(fj,ei)表示以 f j f_j fj 为源语言端词汇的词对在大规模语料中出现的频次。
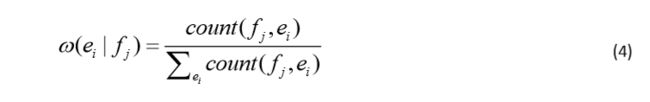
以图 1 中短语对“北京 房价 持续 上涨,beijing housing prices continued to rise”为例,公式(3)的具体计算方式如下所示:

公式(3)是一个二重循环问题,在外层循环中,从目标语言端第一个词汇遍历至最后一个词汇,将概率值进行连乘;在内层循环中,当前目标语言端词汇为 e i e_i ei ,计算不同 f j f_j fj 翻译为 e i e_i ei 的概率和的均值。
“目标语言->源语言”词汇化加权
“目标语言->源语言”方向词汇化加权与公式(3)相似,具体如公式所示。
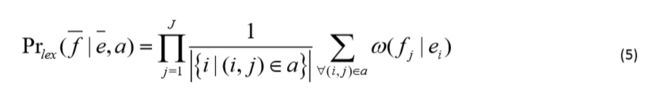
在公式(5)中, ω ( f i ∣ e j ) \omega(f_i|e_j) ω(fi∣ej)计算如公式(6)所示。其中公式(6)说明与公式(4)类似。
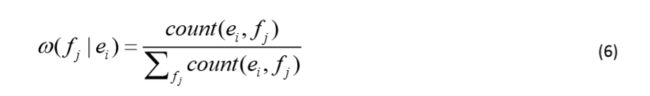
以图 1 中短语对“北京 房价 持续 上涨,beijing housing prices continued to rise”为例,公式(5)的
具体计算方式如下所示:

此处具体计算方式的解释与上文相似,在此不再赘述。至此,短语翻译表中最常使用的 4 个特征介绍完毕。
- 注:附件“phrase.translation.table ” 为在实际的汉英短语翻译系统中使用的短语翻译表中的一部分。该短语翻译表共分为五个域,第一个域为“源语言”端短语;第二个域为“目标语言”端短语;第三个域为分数域,其中前四个分数为本文讲的双向短语翻译概率和双向词汇化权重,这四个分数在概率值基础上通过取 log 获得;第 4 个域为短语对出现的频次;最后一个域为词对齐信息。
参考资源
- NiuTrans 源码:http://www.nlplab.com/NiuPlan/NiuTrans.ch.html 下载 NiuTrans 源码包, NiuTrans 源码包目录/NiuTrans/src/NiuTrans.PhraseExtractor/下,ruletable_scorer.cpp 与 ruletable_scorer.h 两 文件实现短语翻译表概率估计功能。
- Philipp Koehn. 2010. Statistical Machine Translation. Cambridge, UK: Cambridge University Press.
- Tong Xiao, Jingbo Zhu, Hao Zhang and Qiang Li. 2012. NiuTrans: An Open Source Toolkit for Phrase-based and Syntax-based Machine Translation. In Proc. of ACL 2012, page 19-24.
5.Decoding


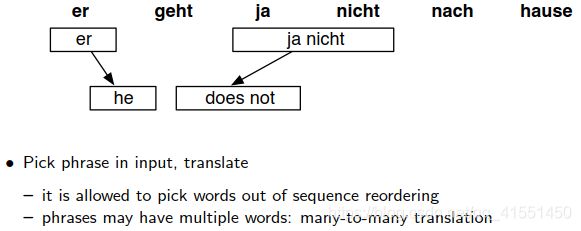

两两组合看有多少种对齐方式列举成一棵树。
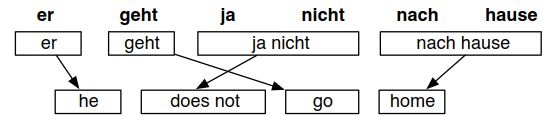
然后从头开始组成一句话。但是如果想要穷尽所有情况是一个NP难问题,没有办法实现,因此只能采取最优路径搜索。
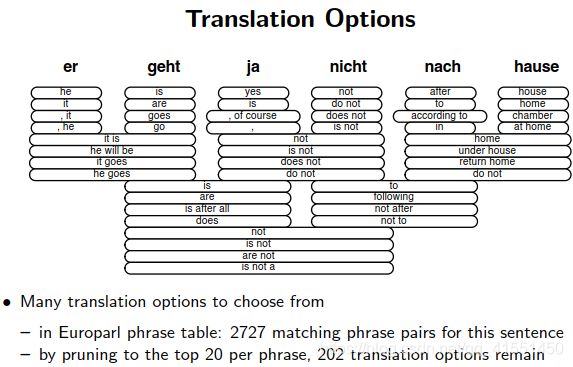
例如,下面提到的beam search算法可以很优秀地进行路径查找。此方法在谷歌NN翻译的解码阶段也有采用。
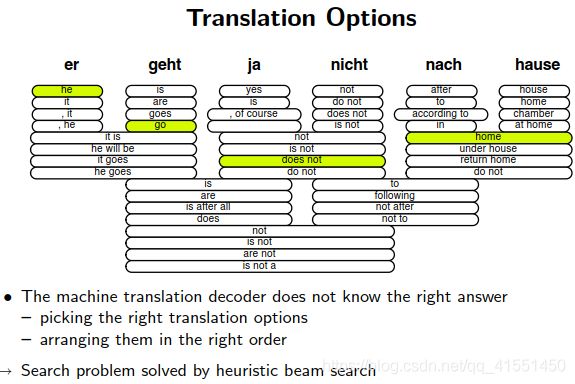
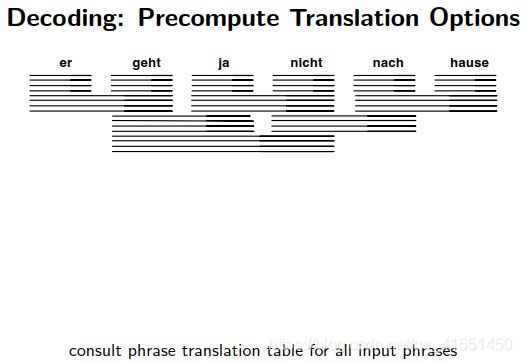

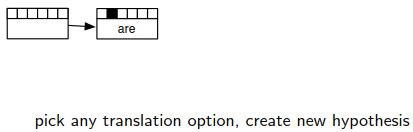
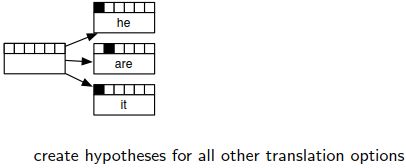
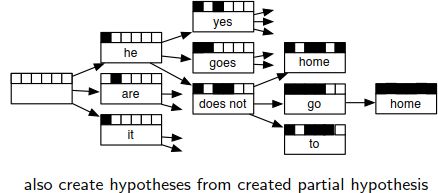
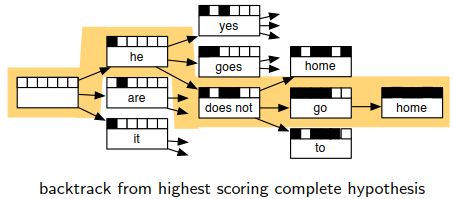
Find Best Path:找最优路径。从而解码才是可控的。
没有办法穷尽所有的路径,利用beam search来减少算法的复杂度。每次之后保留下来较优的候选,然后在节点处展开。
beam search会限定一定的宽度,超过候选概率,概率较低的就从路径树上直接删去。然后实现给定参数的剪枝模型。


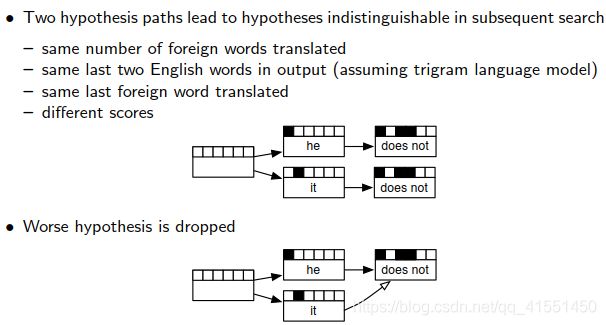

 剪枝就是之前的Recombination步骤,将类似的合并取一个较优的出来。较差的drop
剪枝就是之前的Recombination步骤,将类似的合并取一个较优的出来。较差的drop
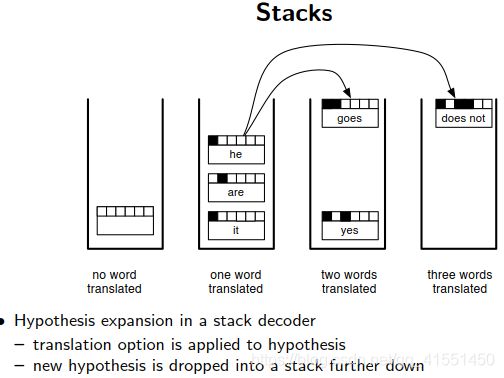
每次选一定个数的候选,每次放一定个数的候选到堆栈当中。
按照概率进行剪枝选择最好的项。
然后将组合出来的句子计算概率。
通过此算法可以找到一条或者多条较优的路径。然后就可以开始进行下一讲的评估了。



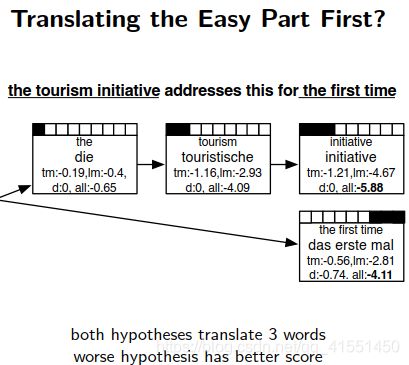
预估未来的代价:

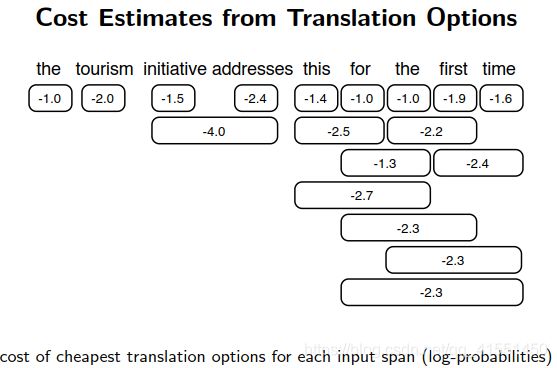
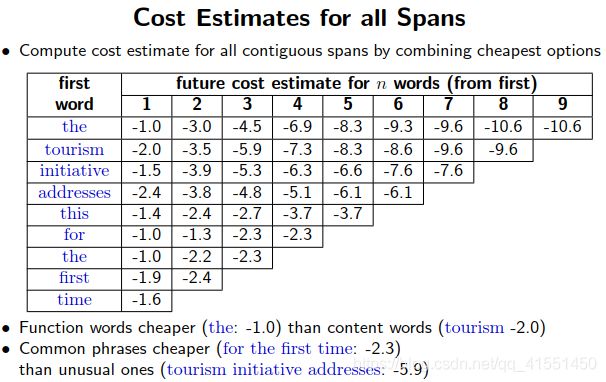


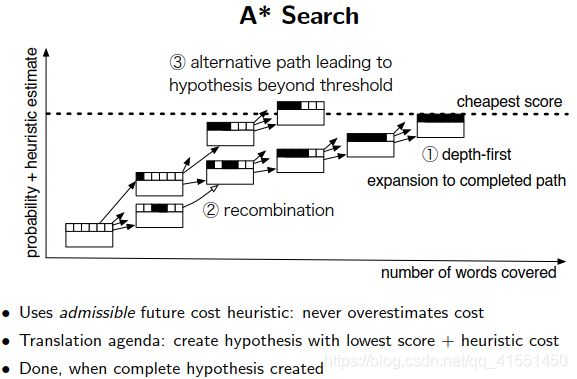


6.Evaluation
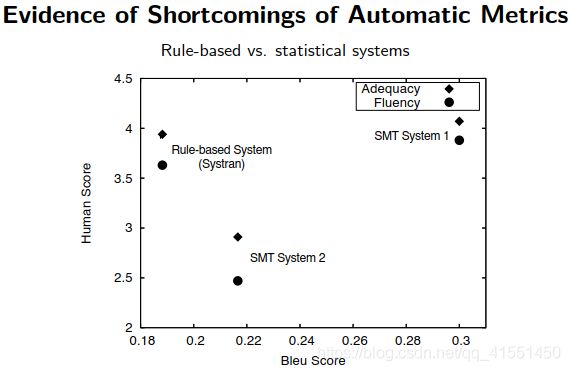
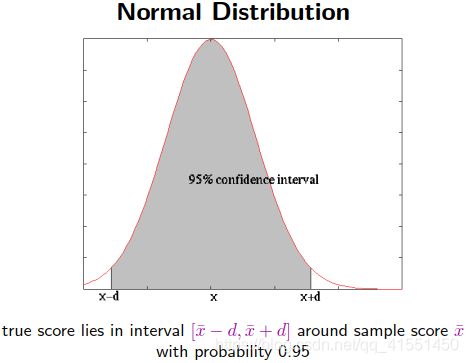
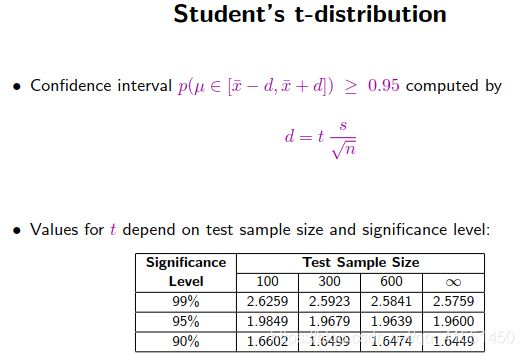
翻译其实是没有一个标准答案的,只能最终提供一个参考答案。所以评估结果是依据参考答案得出来的



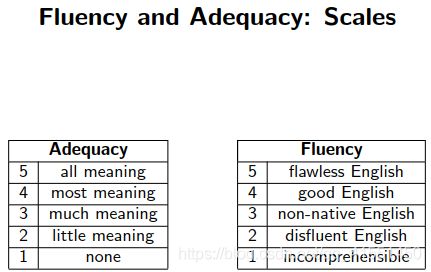
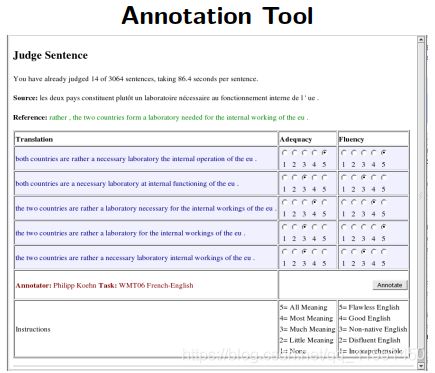
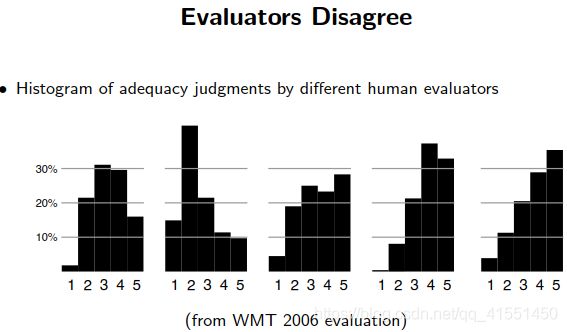

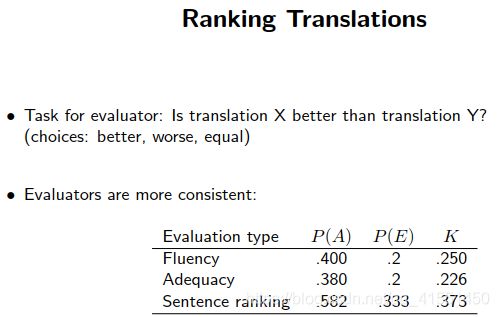




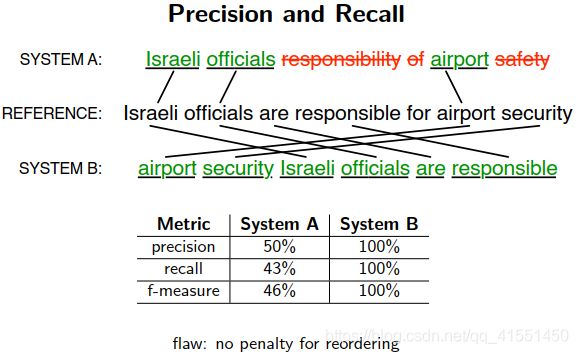

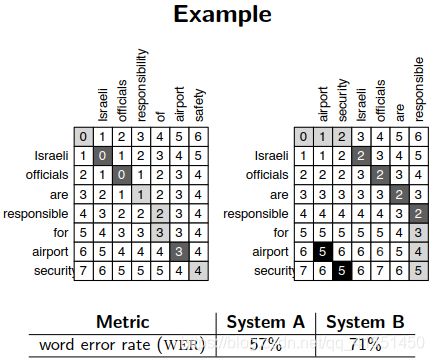
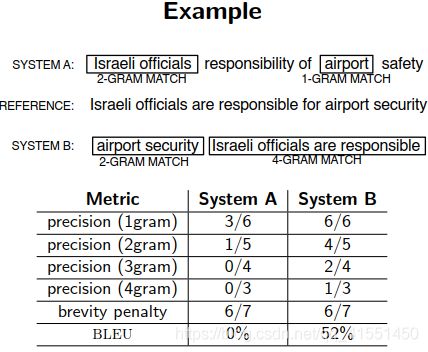
常用的评估:BLEU:
判断翻译结果中,所有的N元祖,和标准答案N元祖之间的重合度
通常计算精确度是计算1~4元的
添加一个惩罚项penalty,当输出长度比参考的长度长的时候系数取1;当输出比参考短的时候,取他俩长度的比值。
(惩罚项的意义就在于,如果翻译得到的输出比原句子短,越短说明翻译准确率越低,因此乘上相应的比例来衰减最终的BLEU得分)




















7.Niutrans
Niutrans:基于短语的统计翻译系统
- Data preparation数据准备阶段
a) Training data 训练数据 LM-training-set和 LM-training-set
b) Tuning data 调参参数(相当于超参数:来调整权重参数)
c) Test data 测试效果的(类似交叉验证)
d) Evaluation data 评估
注意:
1)、LM:语言模型language model无需对齐
2)、在TM训练数据模型中,需要对齐
- Training Translation Model
输入的数据有该模型的数据有:
Chinese.txt
english.txt
Alignment.txt 对齐文本:根据一致性原则来生成
输出得到的数据为:
reordering.table:排序表,从一种语言到另外一种语言之间偏移了多少的概率
phrase.translation.table:短语到短语之间转换的概率表
处理过程:利用GIZA,先扫描输入数据中所有的单词,然后用滑动窗口扫描得出短语之间的对照关系,并利用短语一致性的原则来筛选得出最后的结果。
- Training n-gram language model语言模型
最终建立成一个字典树,可以自行加载你想要的。
- Generating Configuration File
由于底层是用C++写的,所以运算速率还可以。
实际上生成一个配置文件,从而便于搭建出一个服务sever。
- Table Filtering(Optional)
如果在五千万平行语料中生成了一个模型,但这个模型在线上加载时将非常消耗内存。
如果是对一些子领域进行处理的时候,例如只想要实现对医学领域文本的处理,那就可以只选取加载和医学领域相关的短语,其余的就不加载了。
因此就是做一下过滤,只抽取出你想要的短语。
- Weight Tuning
可以理解为和机器学习中超参数的选择类似。
- Decoding Test Sentences
解码只找最优的一条路径:1best.out
如果想要解码得到两条最优路径:2best.out
- Recasing(Suppose that the target language is English)
将英文的首字母全部大写,即还原成英语句子的样子。
- Detokenizer
修改完善一些标点符号
- Evaluation评估
转化格式,用一个xml格式的进行评估,比对标准的和你自己生成的xml文件。得到评估结果。