【Hadoop学习项目】1. WordCount + Combine 详解每行代码
0. 项目结构

数据处理过程图

1. WordCountDriver
package hadoop_test.word_count_demo_01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import hadoop_test.Utils_hadoop;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 客户端以root身份对HDFS上进行读写操作
//System.setProperty("HADOOP_USER_NAME", "root");
// 配置Job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 配置Driver类,方便hadoop从jar文件中找到
job.setJarByClass(WordCountDriver.class);
// 设置mapper类、Combiner类、Reducer类
job.setMapperClass(wordMapper.class);
job.setCombinerClass(WordCountCombine.class);
job.setReducerClass(wordReducer.class);
// 配置mapper类输出(可以不写)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 最终输出的key-value类型(必须写)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 配置输入文件路径
FileInputFormat.setInputPaths(job, new Path("/hadoop_test/word_count/article.txt"));
// 配置输出文件
if( Utils_hadoop.testExist(conf,"/hadoop_test/word_count/word_count_result")){
Utils_hadoop.rmDir(conf,"/hadoop_test/word_count/word_count_result");
}
FileOutputFormat.setOutputPath(job, new Path("/hadoop_test/word_count/word_count_result"));
// 将运行进度信息及时输出
job.waitForCompletion(true);
// 将运行进度信息及时输出并判定程序是否正常退出
//boolean result = job.waitForCompletion(true);
//System.exit(result ? 0 : 1);
}
}
详细解析
(1)System.setProperty
// 客户端以root身份对HDFS上进行读写操作
System.setProperty("HADOOP_USER_NAME", "root");
解析: 在默认情况下,HDFS客户端API会采用Windows默认用户访问虚拟机上的HDFS。而HDFS在默认情况下,仅有root用户具有读写权限,其他用户仅有读权限,因此会报权限异常错误。因此,在访问HDFS时,需要配置用户。
Hadoop启动过程中的问题集
(2) Configuration、job.getInstance
// 配置Job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf); //实例化Job传入参数
解析: 运行MapReduce程序前都要初始化Configuration,该类主要是读取MapReduce系统配置信息,这些信息包括hdfs还有MapReduce,也就是安装hadoop时候的配置文件例如:core-site.xml、hdfs-site.xml和mapred-site.xml等等文件里的信息。
Configuration是hadoop中五大组件的公用类,所以放在了core下,org.apache.hadoop.conf.Configruration。这个类是作业的配置信息类,任何作业的配置信息必须通过Configuration传递,因为通过Configuration可以实现在多个mapper和多个reducer任务之间共享信息。Configuration实现了Iterable和Writable两个接口,其中实现Iterable是为了迭代,迭代出Configuration对象加载到内存中的所有name-value键值对。实现Writable是为了实现hadoop框架要求的序列化,可以将内存中的name-value序列化到硬盘。
hadoop中Configuration类剖析、Hadoop环境编程-Configuration类的使用、hadoop系列之Configuration类解析
(3)job.setJarByClass
// 配置Driver类,方便hadoop从jar文件中找到
job.setJarByClass(WordCountDriver.class);
解析: 设置job方法入口的驱动类(Driver),指定本程序的jar包所在的本地路径。使用反射机制,加载程序。
(4)setMapper、Combiner、Reducer
//设置mapper类、Combiner类、Reducer类
job.setMapperClass(wordMapper.class);
job.setCombinerClass(WordCountCombine.class);
job.setReducerClass(wordReducer.class);
解析: 设置Job在Map、Combin和Reduce阶段的使用类。
(5)setMapOutputKey、Value
// 配置mapper类输出(可以不写)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
解析: 配置Mapper输出的类型(可写可不写)
(6)setOutputKey、Value
// 最终输出的key-value类型(必须写)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
解析: 最终输出的Key、Value类型,必须写。
Text:Hadoop中的Text类为了与外界更好的交互,采用的是utf-8的编码,而java的char,String,StringBuffer则默认使用的是utf-16编码;两者在使用和访问的时候其实是有一些差别。Text是正对UTF-8序列的Writable类。一般可以认为是对String的Writable,即Text是对String的封装。
数据类型:string和text之间的区别是什么?
hadoop中Text类 与 java中String类的区别
LongWritable.class:LongWritable 是 Hadoop 对 Long 的进一步封装,使其可以进行序列化。
hadoop中Writable类和WritableComparable类、序列化和反序列化
(7)FileInputFormat
// 配置输入文件路径
FileInputFormat.setInputPaths(job, new Path("/hadoop_test/word_count/article.txt"));
解析: 输入文件在HDFS上的路径,将文件传给Job。
在读取文件时候,默认先读单个大文件所在的路径(一次性读清该文件下所有文件),后读小文件所在路径。
FileInputFormat 继承于 InputFormat

在FileInputFormat中有一个实现类TextInputFormat
在这个实现类中 RecordReader 方法可以实现文件按行读取
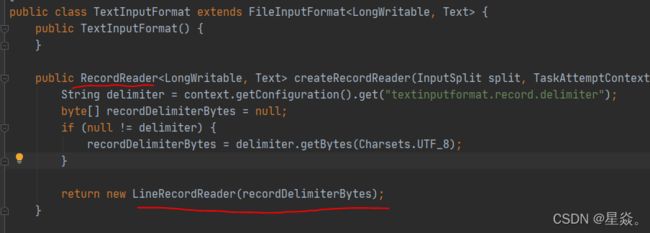
文件上传后,每个Block对应一个split,实现从split中按行读取内容。
FileInputFormat.setInputPaths多路径读取规则
(8)FileOutputFormat
// 配置输出文件及其路径
if( Utils_hadoop.testExist(conf,"/hadoop_test/word_count/word_count_result")){
Utils_hadoop.rmDir(conf,"/hadoop_test/word_count/word_count_result");
}
FileOutputFormat.setOutputPath(job, new Path("/hadoop_test/word_count/word_count_result"));
解析:
Utils_hadoop.testExist(conf, dir):Utils_hadoop中方法,测试文件路径是否存在
public static boolean testExist(Configuration conf, String path) throws IOException {
FileSystem fs = FileSystem.get(conf);
return fs.exists(new Path(path));
}
Utils_hadoop.rmDir(conf, dir):Utils_hadoop中方法,若存在则删除目录
public static boolean rmDir(Configuration conf, String remoteDir) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path dirPath = new Path(remoteDir);
/* 第二个参数表示是否递归删除所有文件 */
boolean result = fs.delete(dirPath, true);
fs.close();
return result;
}
FileOutputFormat.setOutputPath(job, new Path(dir)):设置Job输出目录
(9)job.waitForCompletion
// 将运行进度信息及时输出并判定程序是否正常退出
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
解析:将运行进度等信息及时输出给用户,用Syetem.exit(result ? 0 : 1)判定是否正常退出。
true表示将运行进度等信息及时输出给用户,false的话只是等待作业结束。
MapReduce代码中,Job.waitForCompletion方法及System.exit方法
2. WordCountMapper
package hadoop_test.word_count_demo_01;
import com.google.inject.internal.util.$AbstractMapEntry;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//mapper进程,每一个split(block)会启动该类,
public class wordMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
// map方法,对一个block里面的数据 按行进行读取、处理
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// LongWritable key: 指的是偏移量。
// Text value: 每一行的内容
// Context context:上下文
// value = he love bigData
// 1.每行读取文字,变成java的string
String line = value.toString();
System.out.println(line);
// data =[he,love,bigData]
// 2.按指定分隔符切分每个单词,切分为字符串数组
String[] data = line.split(" ");
System.out.println(line);
// String ts= data[3];
// 3.遍历字符串数组,然后一步一步输出,格式为:(word,1)
for (String word: data) {
// if(Integer.parseInt(ts)>30 || Integer.parseInt(ts) <39){
//
// }
// new Text(word),new LongWritable(1),, (chess,1)
// word,1
System.out.println("word:"+word+": value:"+1);
context.write(new Text(word),new LongWritable(1));
}
}
}
详细解析
一个Block对应一个split,一个split由一个map处理,map从split中按行读取数据进行处理。
(1)Mapper
//mapper进程,每一个split(block)会启动该类
public class wordMapper extends Mapper
解析:
<每行行首的偏移量,每一行的内容>。
拓展:
第一个输入为LongWritable时表示该行在文件中的位置,输入为IntWritable时表示行号。
hadoop中Writable类和WritableComparable类、序列化和反序列化
(2)map(LongWritable key, Text value, Context context)
// map方法,对一个block里面的数据 按行进行读取、处理
protected void map(LongWritable key, Text value, Context context)
解析: 这里的key, value就是读取的数据,context为上下文,用于暂时存储job的配置信息、状态和 map() 处理后的结果等。
Hadoop中Context类的作用和Mapper<LongWritable, Text, Text, LongWritable>.Context context是怎么回事【笔记自用】
(3)value.toString
// 1.每行读取文字,变成java的string
String line = value.toString();
System.out.println(line);
解析: 将value转化为String类型,读取每行数据并打印输出
(4)line.split(" ")
// 2.按指定分隔符切分每个单词,切分为字符串数组
String[] data = line.split(" ");
System.out.println(line);
解析:按空格切分数据为字符串数组,将其打印输出。
// 3.遍历字符串数组,然后一步一步输出,格式为:(word,1)
for (String word: data) {
System.out.println("word:"+word+": value:"+1);
context.write(new Text(word),new LongWritable(1));
}
解析: 从字符串数组中读取每个字符,输出目标格式(word, 1),意思为word出现一次。然后,通过上下文context把map处理结果输出给后续的类来处理,格式为之前定义的
3. WordCountReduce
package hadoop_test.word_count_demo_01;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class wordReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
// key:单词, values:一个List列表形式的迭代器,记录每个map中单词出现的次数
// love,[5,9,8]
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
// 统计单词数量的总和
long count = 0;
for (LongWritable v: values) {
count += v.get();
}
// 输出最终统计结果,key:单词,value:单词在文章中出现的次数
context.write(new Text(key),new LongWritable(count));
}
}
详细解析
(1)wordReducer extends Reducer
// reducer进程,处理每个map
public class wordReducer extends Reducer
解析:
获取map函数的中间结果,按照key是否相同作一组去调用reduce方法。将中间结果中的Value按Key划分组,而组按照Key排序,从而形成了
(2)reduce(Text key, Iterable< LongWritable > values, Context context)
// 对map进行reduce
protected void reduce(Text key, Iterable values, Context context)
解析: 三个参数对应KeyIn, ValueIn,Contex。
Iterable:在Reduce阶段中,Hadoop的迭代器(Iterable values)中使用了对象重用,即迭代时value始终指向一个内存地址(引用值始终不变)改变的是引用指向的内存地址中的数据。
调用next()方法后,会从ReduceContex中获取新的key-value判断下一个key和上一个key是否相同,然后决定hashNext方法是否结束,同时对key和value进行了一次重新赋值。
hadoop迭代器原理(通俗易懂)
初学hadoop程序之---------------Iterable迭代器
示例:
若Map端输出为以下内容
<hello, 1>
<hello, 2>
<hello, 1>
<hello, 3>
reduce()方法中Text key的值便为hello,Iterable < IntWritable > values的值为[1, 2, 1, 3]。
(3)LongWritable v: values
// 统计每个单词出现的数量
long count = 0;
for (LongWritable v: values) {
count += v.get();
}
解析:从values中获取单词出现的数量,相加求和。
(4)context.write(KeyOut, ValueOut)
context.write(new Text(key),new LongWritable(count));
解析: 输出最终结果数据
4. WordCountCombine
package hadoop_test.word_count_demo_01;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
// Reducer详细解析
combiner继承于Reducer,相当于是在shuffle阶段经过sort后对其进行的局部reduce,代码逻辑与上述Reducer相同。主要区别在于输入数据的来源和输出数据的目标去向。
通过Iterable<>迭代器,将相同的key所拥有的值放到迭代器里。然后,使用for循环将值和累加进行数据合并。
Mapper类、Reducer类源码解析
hadoop2.6.5 Mapper类、Reducer类源码解析
参考资料
Hadoop学习笔记(六)实战wordcount
hadoop入门经典:wordcount代码详解
mapreduce实例代码详解(一行一行的注释)
Hadoop之图解MapReduce与WordCount示例分析