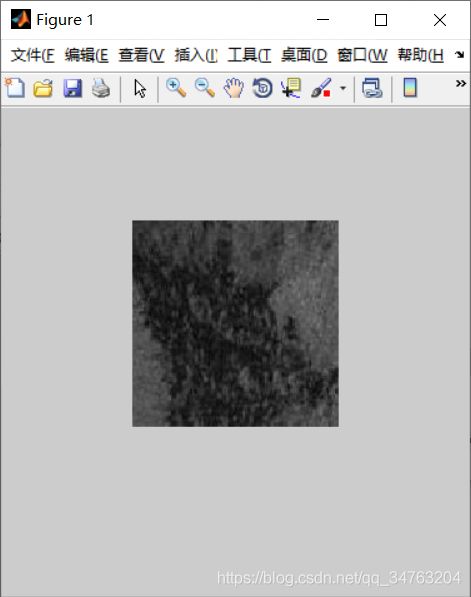
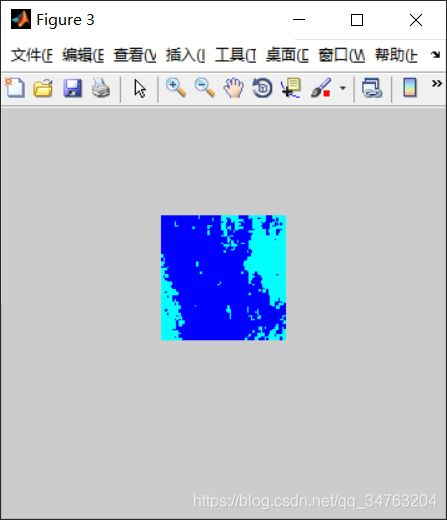
【图像分割】基于谱聚类算法实现图像分割matlab源码
一. 前言
本来想写关于聚类系列算法的介绍,但是聚类系列的其它几个算法原理比较简单,网上有大量的教程可以查阅。这里主要是介绍一下谱聚类算法,做一个学习笔记,同时也希望对想要了解该算法的朋友有一个帮助。关于聚类的其他系列算法,这里推荐一个写的很不错的博客。
谱聚类在最近几年变得受欢迎起来,主要原因就是它实现简单,聚类效果经常优于传统的聚类算法(如K-Means算法)。刚开始学习谱聚类的时候,给人的感觉就是这个算法看上去很难,但是当真正的深入了解这个算法的时候,其实它的原理并不难,但是理解该算法还是需要一定的数学基础的。如果掌握了谱聚类算法,会对矩阵分析,图论和降维中的主成分分析等有更加深入的理解。
本文首先会简单介绍一下谱聚类的简单过程,然后再一步步的分解这些过程中的细节以及再这些过程中谱聚类是如何实现的,接着总结一下谱聚类的几个算法,再接着介绍谱聚类算法是如何用图论知识来描述,最后对本文做一个总结。下面我们就来介绍一下谱聚类的基本原理。
二. 谱聚类的基本原理介绍
2.1 谱和谱聚类
2.1.1 谱
方阵作为线性算子,它的所有特征值的全体统称为方阵的谱。方阵的谱半径为最大的特征值。矩阵A的谱半径是矩阵 的最大特征值。
的最大特征值。
2.1.2 谱聚类
谱聚类是一种基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量进行聚类,从而达到对样本数据聚类的母的。谱聚类可以理解为将高维空间的数据映射到低维,然后在低维空间用其它聚类算法(如KMeans)进行聚类。
2.2 谱聚类算法简单描述
输入:n个样本点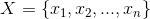 和聚类簇的数目k;
和聚类簇的数目k;
输出:聚类簇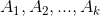
(1)使用下面公式计算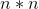 的相似度矩阵W;
的相似度矩阵W;
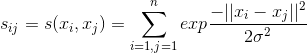
W为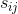 组成的相似度矩阵。
组成的相似度矩阵。
(2)使用下面公式计算度矩阵D;
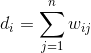 ,即相似度矩阵W的每一行元素之和
,即相似度矩阵W的每一行元素之和
D为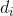 组成的对角矩阵。
组成的对角矩阵。
(3)计算拉普拉斯矩阵 ;
;
(4)计算L的特征值,将特征值从小到大排序,取前k个特征值,并计算前k个特征值的特征向量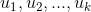 ;
;
(5)将上面的k个列向量组成矩阵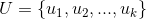 ,
,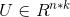 ;
;
(6)令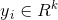 是
是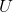 的第
的第 行的向量,其中
行的向量,其中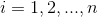 ;
;
(7)使用k-means算法将新样本点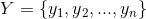 聚类成簇
聚类成簇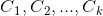 ;
;
(8)输出簇,其中,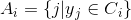 .
.
上面就是未标准化的谱聚类算法的描述。也就是先根据样本点计算相似度矩阵,然后计算度矩阵和拉普拉斯矩阵,接着计算拉普拉斯矩阵前k个特征值对应的特征向量,最后将这k个特征值对应的特征向量组成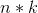 的矩阵U,U的每一行成为一个新生成的样本点,对这些新生成的样本点进行k-means聚类,聚成k类,最后输出聚类的结果。这就是谱聚类算法的基本思想。相比较PCA降维中取前k大的特征值对应的特征向量,这里取得是前k小的特征值对应的特征向量。但是上述的谱聚类算法并不是最优的,接下来我们一步一步的分解上面的步骤,总结一下在此基础上进行优化的谱聚类的版本。
的矩阵U,U的每一行成为一个新生成的样本点,对这些新生成的样本点进行k-means聚类,聚成k类,最后输出聚类的结果。这就是谱聚类算法的基本思想。相比较PCA降维中取前k大的特征值对应的特征向量,这里取得是前k小的特征值对应的特征向量。但是上述的谱聚类算法并不是最优的,接下来我们一步一步的分解上面的步骤,总结一下在此基础上进行优化的谱聚类的版本。
2.3 谱聚类算法中的重要属性
2.3.1 相似度矩阵介绍
相似度矩阵就是样本点中的任意两个点之间的距离度量,在聚类算法中可以表示为距离近的点它们之间的相似度比较高,而距离较远的点它们的相似度比较低,甚至可以忽略。这里用三种方式表示相似度矩阵:一是 -近邻法(-neighborhood graph),二是k近邻法(k-nearest nerghbor graph),三是全连接法(fully connected graph)。下面我们来介绍这三种方法。
-近邻法(-neighborhood graph),二是k近邻法(k-nearest nerghbor graph),三是全连接法(fully connected graph)。下面我们来介绍这三种方法。
(1)-neighborhood graph:
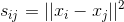 ,表示样本点中任意两点之间的欧式距离
,表示样本点中任意两点之间的欧式距离
用此方法构造的相似度矩阵表示如下:
![]()
该相似度矩阵由于距离近的点的距离表示为,距离远的点距离表示为0,矩阵种没有携带关于数据集的太多的信息,所以该方法一般很少使用,在sklearn中也没有使用该方法。
(2)k-nearest nerghbor graph:
由于每个样本点的k个近邻可能不是完全相同的,所以用此方法构造的相似度矩阵并不是对称的。因此,这里使用两种方式表示对称的knn相似度矩阵,第一种方式是如果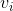 在
在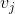 的k个领域中或者在的k个领域中,则
的k个领域中或者在的k个领域中,则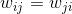 为与之间的距离,否则为
为与之间的距离,否则为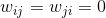 ;第二种方式是如果在的k个领域中并且在的k个领域中,则为与之间的距离,否则为。很显然第二种方式比第一种方式生成的相似度矩阵要稀疏。这两种方式用公式表达如下:
;第二种方式是如果在的k个领域中并且在的k个领域中,则为与之间的距离,否则为。很显然第二种方式比第一种方式生成的相似度矩阵要稀疏。这两种方式用公式表达如下:
第一种方式:
第二种方式:
(3)fully connected graph:
该方法就是在算法描述中的高斯相似度方法,公式如下:
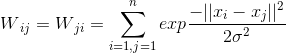
该方法也是最常用的方法,在sklearn中默认的也是该方法,表示任意两个样本点都有相似度,但是距离较远的样本点之间相似度较低,甚至可以忽略。这里面的参数 控制着样本点的邻域宽度,即越大表示样本点与距离较远的样本点的相似度越大,反之亦然。
控制着样本点的邻域宽度,即越大表示样本点与距离较远的样本点的相似度越大,反之亦然。
2.3.2 拉普拉斯矩阵介绍
对于谱聚类来说最重要的工具就是拉普拉斯矩阵了,下面我们来介绍拉普拉斯矩阵的三种表示方法。
(1)未标准化的拉普拉斯矩阵:
未标准化的拉普拉斯矩阵定义如下:
其中W是上节所说的相似度矩阵,D是度矩阵,在算法描述中有介绍。很显然,W与D都是对称矩阵。
未标准化的拉普拉斯矩阵L满足下面几个性质:
(a)对任意一个向量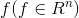 都有:
都有:
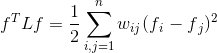
证明如下:
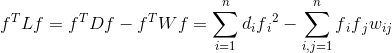
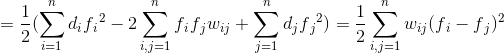
(b)L是对称的和半正定的,证明如下:
因为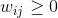 ,所以
,所以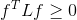 ,所以为半正定矩阵。由于W和D都是对称矩阵,所以L为对称矩阵。
,所以为半正定矩阵。由于W和D都是对称矩阵,所以L为对称矩阵。
(c)L最小的特征值为0,且特征值0所对应的特征向量为全1向量,证明如下:
令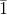 表示
表示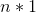 的全1向量,则
的全1向量,则
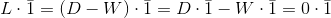
由D和W的定义可以得出上式。
(d)L有n个非负的实数特征值: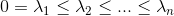
(2)标准化拉普拉斯矩阵
标准化拉普拉斯矩阵有两种表示方法,一是基于随机游走(Random Walk)的标准化拉普拉斯矩阵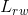 和对称标准化拉普拉斯矩阵
和对称标准化拉普拉斯矩阵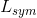 ,定义如下:
,定义如下:
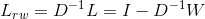
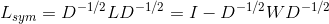
标准化的拉普拉斯矩阵满足如下性质:
(a)对任意一个向量都有:
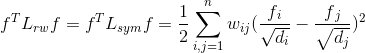
(b)当且仅当 是的特征值,对应的特征向量为
是的特征值,对应的特征向量为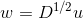 时,则是特征值,对应的特征向量为u;
时,则是特征值,对应的特征向量为u;
(c)当且仅当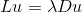 时,是的特征值,对应的特征向量为u;
时,是的特征值,对应的特征向量为u;
(d)0是的特征值,对应的特征向量为,为的全1向量;0也是的特征值,对应的特征向量为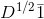 ;
;
(e)和是半正定矩阵并且有非负实数特征值: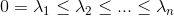 .
.
关于各个版本的谱聚类算法的不同之处,就是在于相似度矩阵的计算方式不同和拉普拉斯矩阵的表示方法不同,其它步骤基本相同。下面就来介绍关于谱聚类的两个比较流行的标准化算法。
2.4 标准化谱聚类算法介绍
2.4.1 随机游走拉普拉斯矩阵的谱聚类算法描述
输入:n个样本点和聚类簇的数目k;
输出:聚类簇
(1)计算的相似度矩阵W;
(2)计算度矩阵D;
(3)计算拉普拉斯矩阵 ;
;
(4)计算的特征值,将特征值从小到大排序,取前k个特征值,并计算前k个特征值的特征向量;
(5)将上面的k个列向量组成矩阵,;
(6)令是的第行的向量,其中;
(7)使用k-means算法将新样本点聚类成簇;
(8)输出簇,其中,.
2.4.2 对称拉普拉斯矩阵的谱聚类算法描述
输入:n个样本点和聚类簇的数目k;
输出:聚类簇
(1)计算的相似度矩阵W;
(2)计算度矩阵D;
(3)计算拉普拉斯矩阵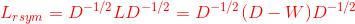 ;
;
(4)计算的特征值,将特征值从小到大排序,取前k个特征值,并计算前k个特征值的特征向量;
(5)将上面的k个列向量组成矩阵,;
(6)令是的第行的向量,其中;
(7)对于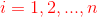 ,将
,将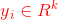 依次单位化,使得
依次单位化,使得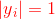 ;
;
(8)使用k-means算法将新样本点聚类成簇;
(9)输出簇,其中,.
上面两个标准化拉普拉斯算法加上未标准化拉普拉斯算法这三个算法中,主要用到的技巧是将原始样本点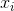 转化为新的样本点
转化为新的样本点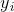 ,然后再对新样本点使用其它的聚类算法进行聚类,在这里最后一步用到的聚类算法不一定非要是KMeans算法,也可以是其它的聚类算法,具体根据实际情况而定。在sklearn中默认是使用KMeans算法,但是由于KMeans聚类对初始聚类中心的选择比较敏感,从而导致KMeans算法不稳定,进而导致谱聚类算法不稳定,所以在sklearn中有另外一个可选项是'discretize',该算法对初始聚类中心的选择不敏感。
,然后再对新样本点使用其它的聚类算法进行聚类,在这里最后一步用到的聚类算法不一定非要是KMeans算法,也可以是其它的聚类算法,具体根据实际情况而定。在sklearn中默认是使用KMeans算法,但是由于KMeans聚类对初始聚类中心的选择比较敏感,从而导致KMeans算法不稳定,进而导致谱聚类算法不稳定,所以在sklearn中有另外一个可选项是'discretize',该算法对初始聚类中心的选择不敏感。
三. 用切图的观点来解释谱聚类
聚类算法给我们的直观上的感觉就是根据样本点的相似性将他们划分成不同的组,使得在相同组内的数据点是相似的,不同组之间的数据点是不相似的。对于给定的样本点计算相似度,形成相似度图,因而谱聚类的问题可以被重新描述如下:我们想要找到图形的一个分区,使得不同分区之间的边具有非常低的权重(这意味着不同分区中的点彼此不相似)并且分区内的边具有高权重(这意味着其中的点彼此相似)。在这个小节我们将讨论如何推导谱聚类为近似的图分区的问题。
3.1 最小切(mincut)
对于无向图G,我们的目标是将图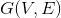 切成互相没有连接的子图,每个子图点的集合为,其中
切成互相没有连接的子图,每个子图点的集合为,其中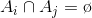 且
且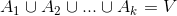 。
。
对于任意两个子图点的集合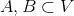 ,
,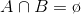 ,我们定义A和B之间的权重切图为:
,我们定义A和B之间的权重切图为:
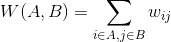
对于k个子图集合,我们定义切图cut为:
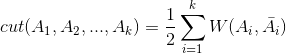
其中, 为A的补集。
为A的补集。
我们可以想到的切图方法就是最小化上式,也就是使各个组之间的权重尽可能的小,但是在许多情况下mincut只是简单的将图中的一个定点与其余的顶点分开,在并不是我们想要的结果,合理的切分结果应该是组内的样本点尽可能的多。所以mincut在实际中并不常用。下面我们介绍另外两个切图方式RatioCut和Ncut。
3.2 RatioCut切图
在RatioCut切图中,不仅要考虑使不同组之间的权重最小化,也考虑了使每个组中的样本点尽量多。
定义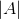 为子集A中的顶点个数,RatioCut的表达式如下:
为子集A中的顶点个数,RatioCut的表达式如下:
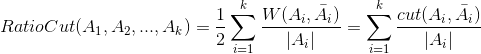
将图中顶点V分成k个分区,我们定义指示向量为: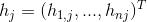 ,其中:
,其中:
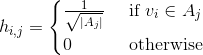
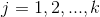
我们令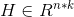 为包含k个指示向量作为列向量的矩阵,注意到H的列向量彼此正交,即
为包含k个指示向量作为列向量的矩阵,注意到H的列向量彼此正交,即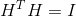 ,然后我们计算下式:
,然后我们计算下式:
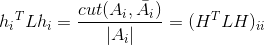 ,证明如下:
,证明如下:
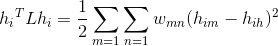
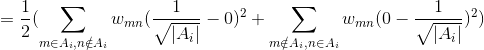
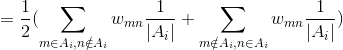
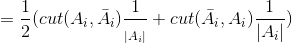
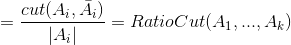
结合上面可以得到:
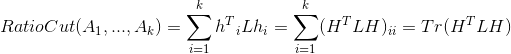
其中Tr(A)表示矩阵A的迹,也就是矩阵A的对角线之和。
所以我们此时的目标函数成为:
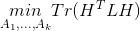 ,约束条件为:
,约束条件为:
注意到我们H矩阵里面的每一个指示向量都是n维的,向量中每个变量的取值为0或者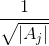 ,就有
,就有 种取值,有k个子图的话就有k个指示向量,共有
种取值,有k个子图的话就有k个指示向量,共有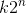 种H,因此找到满足上面优化目标的H是一个NP难的问题。那么是不是就没有办法了呢?
种H,因此找到满足上面优化目标的H是一个NP难的问题。那么是不是就没有办法了呢?
注意观察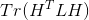 中每一个优化子目标
中每一个优化子目标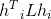 ,其中
,其中 是单位正交基,
是单位正交基,  为对称矩阵。在PCA中,我们的目标是找到协方差矩阵(对应此处的拉普拉斯矩阵L)的最大的特征值,而在我们的谱聚类中,我们的目标是找到目标的最小的特征值,得到对应的特征向量,此时对应二分切图效果最佳。也就是说,我们这里要用到维度规约的思想来近似去解决这个NP难的问题。
为对称矩阵。在PCA中,我们的目标是找到协方差矩阵(对应此处的拉普拉斯矩阵L)的最大的特征值,而在我们的谱聚类中,我们的目标是找到目标的最小的特征值,得到对应的特征向量,此时对应二分切图效果最佳。也就是说,我们这里要用到维度规约的思想来近似去解决这个NP难的问题。
对于,我们的目标是找到最小的L的特征值,而对于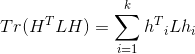 ,则我们的目标就是找到k个最小的特征值,一般来说,k远远小于n,也就是说,此时我们进行了维度规约,将维度从n降到了k,从而近似可以解决这个NP难的问题。
,则我们的目标就是找到k个最小的特征值,一般来说,k远远小于n,也就是说,此时我们进行了维度规约,将维度从n降到了k,从而近似可以解决这个NP难的问题。
通过找到L的最小的k个特征值,可以得到对应的k个特征向量,这k个特征向量组成一个nxk维度的矩阵,即为我们的H。一般需要对H矩阵按行做标准化,即
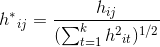
由于我们在使用维度规约的时候损失了少量信息,导致得到的优化后的指示向量h对应的H现在不能完全指示各样本的归属,因此一般在得到nxk维度的矩阵H后还需要对每一行进行一次传统的聚类,比如使用K-Means聚类。
3.3 Ncut切图
Ncut在最小化损失函数之外,还考虑了子图之间的权重大小。Ncut切图与Ratiocut类似,只是把RatioCut分母中的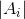 替换成了
替换成了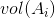 ,其中:
,其中:
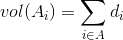
由于子图样本的个数多并不一定权重就大,我们切图时基于权重也更合我们的目标,因此一般来说Ncut切图优于RatioCut切图。所以Ncut的目标函数如下:
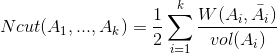 ,证明同上
,证明同上
在Ncut中使用子图权重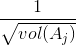 来表示指示向量h,定义如下:
来表示指示向量h,定义如下:
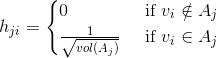
我们的优化目标函数是:
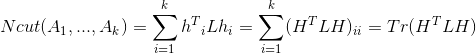
但是此时我们的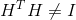 ,而是
,而是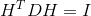 。推导如下:
。推导如下:
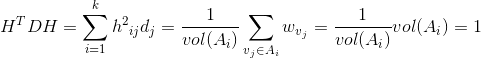
也就是说,此时我们的优化目标最终为:
约束条件:
令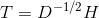 ,则问题变成如下形式:
,则问题变成如下形式:
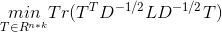 约束条件为:
约束条件为: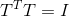
可以发现这个式子和RatioCut基本一致,只是中间的L变成了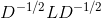 。这样我们就可以继续按照RatioCut的思想,求出的最小的前k个特征值,然后求出对应的特征向量,并标准化,得到最后的特征矩阵
。这样我们就可以继续按照RatioCut的思想,求出的最小的前k个特征值,然后求出对应的特征向量,并标准化,得到最后的特征矩阵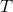 ,最后对进行一次传统的聚类(比如K-Means)即可。
,最后对进行一次传统的聚类(比如K-Means)即可。
一般来说,相当于对拉普拉斯矩阵做了一次标准化,即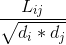 ,所以Ncut会产生标准化的谱聚类,而RatioCut会产生未标准化的谱聚类。
,所以Ncut会产生标准化的谱聚类,而RatioCut会产生未标准化的谱聚类。
四. 谱聚类算法的优缺点
4.1 优点
(1)当聚类的类别个数较小的时候,谱聚类的效果会很好,但是当聚类的类别个数较大的时候,则不建议使用谱聚类;
(2)谱聚类算法使用了降维的技术,所以更加适用于高维数据的聚类;
(3)谱聚类只需要数据之间的相似度矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法(比如K-Means)很难做到
(4)谱聚类算法建立在谱图理论基础上,与传统的聚类算法相比,它具有能在任意形状的样本空间上聚类且收敛于全局最优解
4.2 缺点
(1)谱聚类对相似度图的改变和聚类参数的选择非常的敏感;
(2)谱聚类适用于均衡分类问题,即各簇之间点的个数相差不大,对于簇之间点个数相差悬殊的聚类问题,谱聚类则不适用;
close all
clear all
clc;
%读入一副图像
% global slide_window interpixel_distance qutity_level k
tic
%读图
I=imread('oil3-01.jpg');
% I=rgb2gray(I);
figure,imshow(I);
I1=double(I);
% I1=rgb2gray(I1);
L=harrl(I1);
LL=harrll(L);
matrix=LL;
II=mat2gray(matrix);
figure,imshow(II);
II=matrix(:);
m=size(II,1);
%聚类数
k=2;
Delta=0.0012;
d=zeros(m,m);
W=zeros(m,m);%尺度系数
for i=1:m
for j=1:m
d(i,j)=abs(II(i)-II(j))^2;
W(i,j)=exp(-d(i,j)/2*Delta^2);
end
end % W=affiliate(ent,Delta);
Y=cut(W);
Y=Y(:,2);
% matrix=mat2gray(Y);
% MATRIX=reshape(matrix,[60,60]);
% figure,imshow(MATRIX);
% imwrite(MATRIX,'featureIMAGE');
Y=Y./sum(Y);
%Y=Y';
% plot(m,n)
%T=0.5*(max(Y)+min(Y));
%while true
% g=Y>=T;
% Tn=0.5*(mean(Y(g)+mean(Y(~g))));
% done=abs(T-Tn)<0.1;
% T=Tn;
% end
% figure,imshow(image);
label_matrix1=k_meanclusterings(Y,k);
label_matrix2=reshape(label_matrix1,64,64);
label_map=label2rgb(label_matrix2);
figure,imshow(label_map);
imwrite(label_map,'oil3-02.jpg');
toc
% im_matric=label_matrix;
% im_matric1=reshape(im_matric,[m,n]);
%label_map=mat2gray(im_matric1);
%figure,imshow(label_map);