Tensorflow2自定义网络 2. Pointer-Generator Seq2Seq复制机制神经网络大致介绍和框架实现
网络大致介绍
为了提升神经机器翻译质量,论文Get To The Point: Summarization with Pointer-Generator Networks 两个角度出发:
- 减少网络翻译出现重复语句的情况
- 尽可能从输入获取单词表外的单词,强化语义转换的同时,减少OOV的情况。
基于此,提出了Coverage mechanism和Pointer-generator。
Coverage mechanism
Coverage vector计算来源于译码器0~t-1的注意力权重,用于Bahdanau Attention权重计算的一个部分。(个人猜想:压缩经常注意的权重)。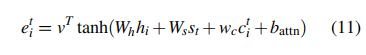
![]()
Pointer-generator
编码器注意力权重分配机制,便于输出的时候分辨单词表依赖程度和输入序列依赖程度,这样可以通过扩增单词表找到输出单词,做梯度下降。![]()
![]()
代码框架
Tensorflow2 实现,并且,这只是框架,没有完整的训练过程,pointer加入较困难,近期如果实现有机会更新 (看运气)
import tensorflow as tf
from tensorflow.keras import *
class GRUBiEncoder(layers.Layer):
def __init__(self, hid_dim, layer_num, dropout=0.1):
super(GRUBiEncoder, self).__init__()
self.hid_dim = hid_dim
self.layer_num = layer_num
self.gru_layers = [
layers.Bidirectional(layers.GRU(hid_dim, return_sequences=True, return_state=True, dropout=dropout)) for _
in range(self.layer_num)]
def call(self, inputs, mask=None, training=None, *args, **kwargs):
# inputs: [batch, seq, embed_dim]
# mask: [batch, seq]
# training: bool
x = inputs
forward_states = []
backward_states = []
for i in range(self.layer_num):
x, forward_s, backward_s = self.gru_layers[i](x,
initial_state=[tf.zeros((tf.shape(x)[0], self.hid_dim))] * 2,
training=training, mask=mask)
forward_states.append(forward_s)
backward_states.append(backward_s)
# x: [b, seq, hid*2]
# states: layer_num * [batch, hid]
return x, tf.convert_to_tensor(forward_states), tf.convert_to_tensor(backward_states)
class BahdanauaAttention(layers.Layer):
def __init__(self, hid_dim, coverage=False):
super(BahdanauaAttention, self).__init__()
self.hid_dim = hid_dim
self.coverage = coverage
self.W_h = layers.Dense(hid_dim, use_bias=False)
self.W_s = layers.Dense(hid_dim)
if coverage:
self.W_c = layers.Dense(1, use_bias=False)
self.V = layers.Dense(1, use_bias=False)
def call(self, key, query, mask=None, cover_vec=None):
# key: [b, 1, hid]
# query: [b, seq, hid]
# mask: [b, seq] 0: pad
# cover_vec: [b, seq, 1] sum of all previous decoder timestep
# [b, seq, hid]
x = self.W_h(query) + self.W_s(key)
if self.coverage:
x += self.W_c(cover_vec)
# [b, seq, 1]
x = self.V(tf.nn.tanh(x))
if mask is not None:
# [b, seq, 1]
pad_place = (1. - tf.cast(tf.expand_dims(mask, -1), dtype=x.dtype))
x += pad_place * -1e10
# [b, seq, 1]
context_weight = tf.nn.softmax(x, axis=-2)
# [b, 1, hid]
context_vector = tf.reduce_sum(context_weight * query, axis=-2, keepdims=True)
# calc next coverage_vector
if cover_vec is None:
cover_vec = context_weight
else:
cover_vec += context_weight
# [b, 1, hid], [b, seq, 1] [b, seq, 1]
return context_vector, context_weight, cover_vec
def initial_coverage_vector(batch_size, encode_length):
return tf.zeros((batch_size, encode_length, 1), tf.float32)
class GRUDecoder(layers.Layer):
def __init__(self, hid_dim, layer_num, dropout=0.1, coverage=False):
super(GRUDecoder, self).__init__()
self.hid_dim = hid_dim
self.layer_num = layer_num
self.coverage = coverage
self.attention = BahdanauaAttention(hid_dim, coverage)
self.gru_layers = [layers.GRU(self.hid_dim, dropout=dropout, return_state=True, return_sequences=True) for _ in
range(layer_num)]
self.fc = layers.Dense(hid_dim)
def call(self, decode_input, encode_sequence, encode_mask, previous_state, coverage_vector=None, training=None):
# decode_input: [b, 1, hid]
# encode_sequence: [b, seq, hid]
# encode_mask: [b, seq] 0: pad
# previous_state: [b, hid] from Bi-encode states concatenation or previous
# coverage_vector: [b, seq, 1]
x = decode_input
decode_state_list = []
for i in range(self.layer_num):
x, state = self.gru_layers[i](x, initial_state=previous_state[i], training=training)
decode_state_list.append(state)
# [b, 1, hid], [b, seq, 1] [b, seq, 1]
context_vec, context_weight, next_coverage_vector = self.attention(x, encode_sequence, encode_mask,
coverage_vector)
# [b, 1, 2 * hid]
x = tf.concat([x, context_vec], axis=-1)
# [b, 1, hid]
x = self.fc(x)
# x: [b, 1, hid]
# decode_state_list: layer * [b, hid]
# context_vector: [b, 1, hid] for pointer-generator
# context_weight: [b, seq, 1]
# coverage_vector: [b, seq, 1]
if self.coverage:
return x, decode_state_list, context_vec, context_weight, next_coverage_vector
return x, decode_state_list, context_vec, context_weight
class PointerGenerator(layers.Layer):
def __init__(self):
super(PointerGenerator, self).__init__()
self.W_h = layers.Dense(1, use_bias=False)
self.W_s = layers.Dense(1, use_bias=False)
self.W_x = layers.Dense(1)
def call(self, context_vector, decoder_state, decoder_input):
# [b, 1, hid] [b, 1, hid] [b, 1, embed] => [b, 1]
return tf.nn.sigmoid(
tf.squeeze(self.W_h(context_vector) + self.W_s(decoder_state) + self.W_x(decoder_input), axis=-1))
def mytest_gruseq2seq():
decoder_hid = 64
encoder_hid = 32
vocab_dim = 64
vocab_size = 2000
layer = 3
batch = 20
seq = 30
loss_lambda = 1
embedding = layers.Embedding(vocab_size, vocab_dim)
fc_out = layers.Dense(vocab_size, use_bias=False)
encoder = GRUBiEncoder(encoder_hid, layer)
ln1 = layers.LayerNormalization(trainable=True)
ln2 = layers.LayerNormalization(trainable=True)
decoder = GRUDecoder(decoder_hid, layer, coverage=True)
pointer = PointerGenerator()
optimizer = optimizers.Adam(0.03)
x = tf.random.uniform((batch, seq), 0, vocab_size, tf.int32)
y = tf.random.uniform((batch, seq), 0, vocab_size, tf.int32)
x_mask = tf.random.uniform((batch, seq), 0, 2, tf.int32)
for step in range(50):
with tf.GradientTape() as tape:
embed_x = embedding(x)
embed_y = embedding(y)
sequence, forward_state, backward_state = encoder(embed_x, training=True)
forward_state = ln1(forward_state, training=True)
backward_state = ln2(backward_state, training=True)
state = tf.concat([forward_state, backward_state], axis=-1)
coverage_vec = initial_coverage_vector(batch, seq)
logits_list = []
coverage_penalty = []
for i in range(seq - 1):
# Note: this coverage has been add context_weight
out, state, context_vector, context_weight, next_coverage = decoder(embed_y[:, i:i + 1],
sequence,
x_mask,
state,
coverage_vec, training=True)
# ====== test coverage_vec and next_coverage======
mask = coverage_vec + context_weight != next_coverage
if True in mask.numpy():
print(tf.boolean_mask(next_coverage, mask))
print(tf.boolean_mask(coverage_vec + context_weight, mask))
# ====== end test ======
# s_t = state[-1]
p_gen = pointer(context_vector, out, embed_y[:, i:i + 1])
# one by one
logits = fc_out(out)
logits_list.append(logits)
coverage_penalty.append(
tf.reduce_min(tf.concat([context_weight, coverage_vec], axis=-1), axis=-1)) # [b, seq]
coverage_vec = next_coverage
# [b, seq-1, class]
logits_list = tf.concat(logits_list, axis=-2)
# [b, seq-1]
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y[:, 1:], logits=logits_list)
loss = tf.reduce_mean(loss) + loss_lambda * tf.reduce_mean(coverage_penalty)
print('step loss:', step, loss.numpy())
variables = embedding.trainable_variables + fc_out.trainable_variables + encoder.trainable_variables + decoder.trainable_variables + ln1.trainable_variables + ln2.trainable_variables + pointer.trainable_variables
grads = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(grads, variables))
# mytest_gruseq2seq()
再说一次,mytest中的网络没有加入pointer,只有coverage
存在疑问留言即可。也欢迎学习NLP相关的朋友,推荐一些不错的论文,我有时间也会尝试复现。