读论文:Self-Attention ConvLSTM for Spatiotemporal Prediction
标题: 用于时空预测的自注意卷积
作者: Zhihui Lin, Maomao Li, Zhuobin Zheng, Yangyang Cheng, Chun Yuan.
文章目录
- ==Abstract==
- ==Introduction==
-
- 一、介绍
- ==综述==
-
- 二、相关工作
- 三、方法
-
- 3.1 基本模型
- 3.2 Self-Attention记忆模块
- 3.3 自注意卷积LSTM
- 四、实验
-
- 4.1 实现
- 4.2 数据集
- 4.3 消融实验
- 4.4 定量与定性比较
- 4.5 关注可视化
- ==总结==
- ==未来展望==
Abstract
由于复杂的动态运动和外观变化,时空预测具有挑战性。而且现有的一些方法通过卷积的方式只能低效地捕获局部的空间依赖关系。为了提取具有全局和局部依赖性的空间特征,文本提出了自注意机制,这是一种新的自我注意记忆(SAM)方法来记忆具有长期空间和时间依赖性的特征。基于自注意,SAM就可以通过聚合输入本身和记忆特征的所有位置的特征来产生特征,也就可以提取具有长时间时空相关性的特征,再以此构造一个用于时空预测的自注意ConvLSTM (SA-ConvLSTM)。与之前的先进方法相比,SA-ConvLSTM在两个数据集上都以更少的参数和更高的时间效率获得了最先进的结果。
Introduction
一、介绍
时空预测学习已经成为计算机视觉和人工智能广泛领域的一个重要的基础研究问题,并有越来越多地研究团体中开始关注它。尽管ConvLSTM可以捕获长短期建模之外的空间依赖性,但是效果并不好。而Self-attention模块就可以获得单层的全局空间上下文,并且效率更高。此外,研究人员认为当前时间步的特征可以从聚合过去的相关特征中获益——>SAM:用于ConvLSTM的自我注意记忆模块,它利用自我注意的特征聚合机制,通过计算成对的相似度得分,将当前和记忆的特征融合在一起。
将SAM嵌入到ConvLSTM中,构建自我注意ConvLSTM,简称SA-ConvLSTM。消融实验证明了自我注意和附加记忆对不同类型数据的有效性,而且它在所有数据集上以更少的参数和更高的效率获得了最好的结果;
- 贡献:
- 提出了SAConvLSTM来进行时空预测,它可以成功地捕获远程空间依赖性;
- 设计了一个基于记忆的自我注意模块(SAM)来记忆预测过程中的全局时空依赖性;
- 评估了SA-ConvLSTM的表现:与目前最先进的模型MIM相比(在MovingMNIST和KTH上的多帧预测和TexiBJ对交通流的预测),它以更少的参数和更高的效率在所有数据集上取得了最好的结果;它们很容易遭受梯度消失的问题
综述
二、相关工作
- 基于ConvRNN的时空预测:自从ConvLSTM提出以后产生了许多变种,例如PredRNN,PredRNN++和MIM。但是它们很容易遭受梯度消失的问题,而且其记忆单元往往集中在局部空间依赖性上。本文提出了一种自注意记忆单元,既能通过高速公路中的自适应更新获得长期的时间依赖性,又能通过自注意有效提取全局的空间依赖性;
- Self-Attention模块:近些年自注意力机制因其良好的效果也被广泛应用。而本文就是在自注意力机制的基础上提出了SAM用于解决上面提出的长期空间依赖问题;
三、方法
3.1 基本模型
基本模型是Self-attention和ConvLSTM的简单组合;也就是说,基本模型是由两部分直接级联建立的,其表述如下:

其中SA表示自我注意模块。X^ 和H^ 是通过自我注意模块聚合的特性。具体而言,在每个时间步中,注意位置模块通过所有位置特征的加权和有选择地聚合每个位置的输入特征
作为对照,下面是ConvLSTM的公式:
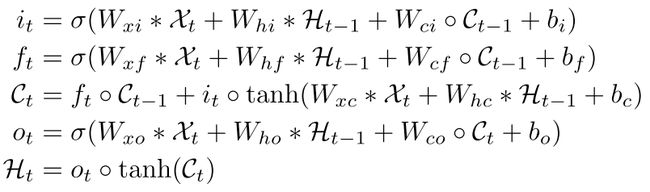
可以看到,两个的主要区别在于自我主义模块以及其对应的参数;
- 自注意机制:下图显示了标准的自我注意模块的管道:
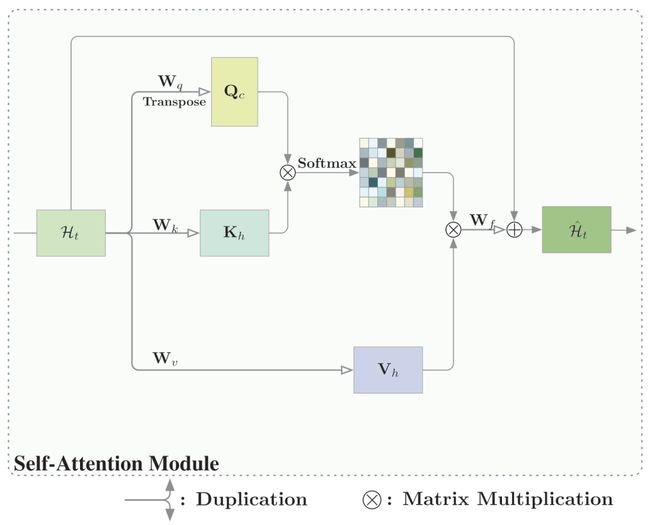
Ht为时间步t时ConvLSTM中的隐藏状态,Qh为查询,Kh为键值,Vh为基于特征上的1 × 1卷积的值,wd为输出。将原始特征映射Ht作为查询映射到不同的特征空间:Qh=WqHt∈RC×N;键:Kh = WkHt∈RC×N,值:Vh = WvHt∈RC×N,其中{Wq,Wk, Wv}是一个1 × 1卷积的权值集;C和C^ 为通道数,其中N = H × W;
对于所提出的SAM,通过对Ht和另一个特征Zm施加自注意来获得聚合特征Zh,其中Zm通过对Km的查询和访问Vm来计算。这里,Km和Vm都是内存Mt−1的映射。Zh和Zm通过1 × 1卷积融合为Z。然后用Z和原始输入Ht用门控机制更新内存。最终的输出是输出门值和更新后的内存Mt之间的点积。
每对点的相似度分数通过矩阵乘法计算为:

然后对相似度分数进行归一化处理后再计算第i个位置的聚合特征:

其中WvHt,j∈RC×1是值Vh的第j列。该输出是通过一个快捷连接来获得的:Ht = Wf Z+Ht;
在这里,残差机制稳定了模型训练,并确保模块可以灵活地嵌入到其他深度模型中。
3.2 Self-Attention记忆模块
自我注意记忆结构如下图所示:

自我注意记忆块接收两个输入,当前时间步长的输入特征Ht和最后一步的记忆Mt−1。
整个管道可分为三个部分:1.获取全局上下文信息的特征聚合、2.内存更新和3.输出;
- 功能聚合:在每一个时间步上,聚合特征Z是Zh和Zm的融合,其中Zh就是之前提到的self-attention的输出、Zm通过在最后一个时间步Mt−1上查询内存来聚合。具体的操作步骤与self-attention类似,最终通过将和的通道拼接得到最后的聚合特征;

- 内存更新:作者采用门控机制来动态地更新记忆单元,聚合特征和原始输入用于生成输入门和聚合特征;
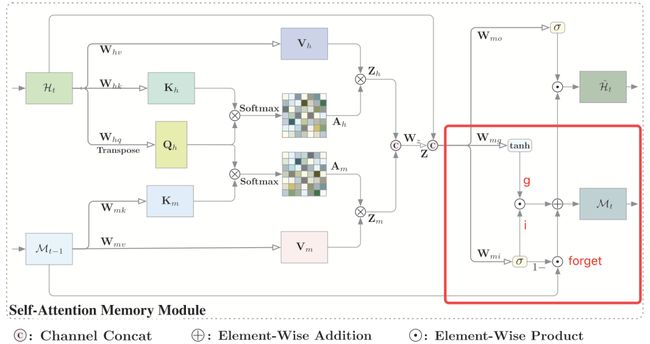
计算公式如下:

聚合的特征Z和原始的输入Ht被用来产生输入门i’t和融合特征g’t,将遗忘门替换为1-i’t来减少参数。为了进一步减少参数和计算量作者使用深度可分离卷积来代替标准的卷积操作;
- 输出:

自注意记忆模块的输出是将特征H^ t是输出门o’t和更新后的内存Mt 聚合后的产物,可表述为:

3.3 自注意卷积LSTM
将自我注意记忆模块嵌入到ConvLSTM中,构建SA-ConvLSTM,如下图所示:

SAM就是之前讲的那个
如果我们去掉SAM模块,SAConvLSTM将退化为标准的ConvLSTM。
此外,它可以灵活地嵌入到其他模型中;
四、实验
本文对三个常用的数据集进行了时空预测:用于多帧预测的MovingMNIST和KTH数据集,以及用于交通流预测的TexiBJ数据集。作者为了验证设计模型的有效性做了许多消融实验,并在第一层和最后一层的注意映射可视化;
4.1 实现
为了与以前的工作进行公平的比较,本文应用了几乎相同的实验设置、抽样策略以及其他的各种模型设置;
4.2 数据集
- MovingMNIST是一个常用的数据集,描述了两个可能重叠的数字以恒定的速度移动,并在图像边缘反弹。图像大小为64×64×1,每个序列包含20帧,10个输入,10个预测;
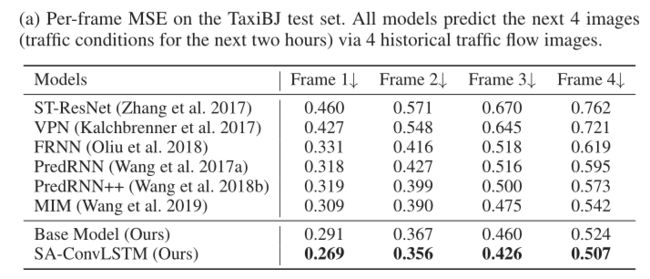
- TaxiBJ从混乱的现实环境中采集,包含连续从北京出租车GPS监视器上采集的交通流图像。其中的每一帧都是一个32 × 32 × 2的图像网格。两个通道表示此时进出同一区域的交通流量(我们使用4个已知帧来预测接下来的4帧(未来两个小时的交通状况));
- KTH包含6类人类行为由25人在4种不同的场景中完成。文章遵循了之前作品中的设置来构建训练和测试集。图像大小从320 × 240调整为128 × 128。训练时使用10帧来预测接下来的10帧,推理时使用20帧;
4.3 消融实验
本文对MovingMNIST和TexiBJ进行了消融研究,以评估不同类型数据的模型:
MovingMNIST中的运动变化是平稳的,需要对局部动态进行精确建模。而TexiBJ则采用像素值的演化来表示交通流的变化;
因此,TexiBJ比MovingMNIST具有更多的远程空间依赖性;
实验结果如下表所示:

本文用SSIM、MSE、MAE等方法来衡量预测质量。ConvLSTM是基线模型,评估了四个变量,包括第3节中的基础模型。带额外内存的ConvLSTM和SA-ConvLSTM(图1中带或不带Zm);
SSIM:结构相似性,值越大,表示图像失真越小;MSE:均方根误差;MAE:平均绝对误差,MAE越小表示模型越好
在MovingMNIST和TexiBJ上,自注意分别相对降低了9.0%和22.2%的MSE。对于额外的内存M,相对减少了12.2%和18.2%——>额外的内存对动态平滑的数据更有效,而自注意更适合于流量或网络流预测,因为它可以提取长期的空间依赖性;
SA-ConvLSTM (w/o Zm)在MovingMNIST和TexiBJ上的MSE分别降低了13.1%和22.6%;
而SA-ConvLSTM结合了两者的优点,在这两类数据上MSE分别降低了32.2%和26.0%;
可以看出,SA-ConvLSTM取得了较好的结果。
4.4 定量与定性比较
- 在MovingMNIST上,不同模型之间的定量比较详见下表,其中报告了平均结果:

采用PredRNN、PredRNN++ 、MIM 等模型进行比较,其中MIM实现了近年来最先进的方法。所有模型都是基于之前的10帧来预测接下来的10帧。并且遵循PredRNN、PredRNN++和MIM的实验设置和超参数进行比较
与各种传统的模型相比,SA-ConvLSTM模型在参数更少,结构更加简洁的同时还有着相似甚至更优的得分。模型规模较小的原因是在提出的自我注意记忆中采用了深度可分离卷积,减少了可训练参数;
每个模型的定性比较如下图所示:

其中FRNN和ConvLSTM产生的结果最模糊。PredRNN、PredRNN++和MIM的结果仍然很模糊,无法区分数字“4”和“7”。我们的基础模型实现了精确但不是很精确的预测。SA-ConvLSTM在准确性和图像质量方面实现了最好的预测
- TaxiBJ:每个模型通过4个已知帧来预测接下来的4帧(未来2小时的交通状况)。我们采用框架的MSE作为度量。定量比较和可视化对比如下表/图所示:

预测和事实之间的绝对差异被展示出来。颜色越亮,绝对误差越高。提出的SA-ConvLSTM比MIM降低了平均MSE误差约9.3%
- KTH:本文用最后10帧来预测接下来的20帧。SA-ConvLSTM在KTH数据集上表现出了它的高效率和灵活性。比较结果如下所示:

PSNR是峰值信噪比,是一种评价图像的客观标准,它具有局限性,一般是用于最大值信号和背景噪音之间的一个工程项目,越大越好
KTH上的预测样本如图5所示:

ConvLSTM很难做出高质量的预测,与PredRNN相比,SA-ConvLSTM可以提供更多的纹理信息,例如图5中的黑色裤子和白色外套。相比之下,SAConvLSTM不仅可以保留更多的纹理信息,而且可以提高预测精度
4.5 关注可视化
从MovingMNIST的测试集中随机选择了一些例子,通过查询一个特定的点“+”,将注意映射可视化在图6中:
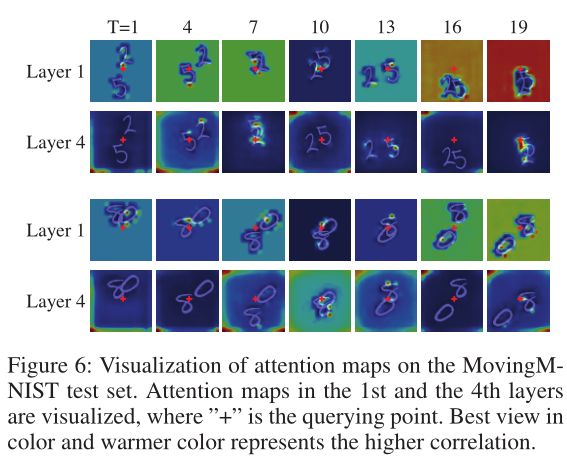
第1层和第4层的注意映射被可视化,其中“+”为查询点。颜色上最好的视角和较暖的颜色代表较高的相关性。
颜色较暖的区域与查询点的关系更密切。当“+”在数字上时,注意力集中在前景上,如第二行“T=13”、“T=19”和第三行“T=10”所示。相反,当查询点在后台时,大部分权重都集中在后台,如第二行“T=1”和第四行“T=16”所示。底层(layer 1)特征是平移不变的,这样背景特征基本相同,layer 1可以统一出席背景像素。相比之下,第4层的特征具有更多的语义信息。
总结
本文提出了SA-ConvLSTM用于时空预测,由于对当前时间步长的预测可以从过去的相关特征中获益,文章构建了一个自注意记忆模块,以捕获空间和时间维度上的长期依赖性。在三种不同的数据集上进行的消融实验证明了自注意和附加记忆M对不同类型数据的有效性;
未来展望
虽然取得了很好的效果,但是论文中也提到对于注意力的计算复杂度是很高的,所以本篇论文中实验采用的图像的尺寸比较小,可以忽略注意力的计算,对于大范围的数据来说这点可能也会成为一个限制因素;