JointDNN: An Effificient Training and Inference Engine for Intelligent Mobile Cloud Computing Servic
题目:JointDNN: An Effificient Training and Inference Engine for Intelligent Mobile Cloud Computing Services
JointDNN:一个高效的智能移动云计算服务的训练和推理引擎
作者:Amir Erfan Eshratifar , Mohammad Saeed Abrishami, and Massoud Pedram
摘要:Deep learning models are being deployed in many mobile intelligent applications. End-side services, such as intelligent personal assistants, autonomous cars, and smart home services often employ either simple local models on the mobile or complex remote models on the cloud. However, recent studies have shown that partitioning the DNN computations between the mobile and cloud can increase the latency and energy effificiencies. In this paper, we propose an effificient, adaptive, and practical engine, JointDNN, for collaborative computation between a mobile device and cloud for DNNs in both inference and training phase. JointDNN not only provides an energy and performance effificient method of querying DNNs for the mobile side but also benefifits the cloud server by reducing the amount of its workload and communications compared to the cloud-only approach. Given the DNN architecture, we investigate the effificiency of processing some layers on the mobile device and some layers on the cloud server. We provide optimization formulations at layer granularity for forward- and backward-propagations in DNNs, which can adapt to mobile battery limitations and cloud server load constraints and quality of service. JointDNN achieves up to 18 and 32 times reductions on the latency and mobile energy consumption of querying DNNs compared to the status-quo approaches, respectively.
深度学习模型被放置在许多移动智能应用上。终端服务,比如说智能个人助理、自动驾驶汽车和智能家居服务经常采用移动设备上简单的本地模型或者云上复杂的远程模型。然而,最近的研究显示在移动设备和云之间切分DNN计算能够降低延迟,提高效率。在这篇文章里,我们提出一个有效的,自适应的且实用的引擎:JointDNN,用于推理和训练阶段的DNN的移动设备和云之间的协作计算。JointDNN不仅能够为在移动端查询DNN提供一个能量和性能都高效的方法,而且与仅云计算方法相比,通过减少工作量和通信量使云服务器受益。鉴于DNN结构,我们调查了处理移动设备某些层和云上服务器某些层的效率。我们为 DNN 中的前向和后向传播提供层粒度的优化公式,可以适应手机电池限制和云服务器负载限制和服务质量。与现存的方法相比,JointDNN 查询 DNN 的延迟和移动能耗分别降低了 18 倍和 32 倍。
关键词:深度神经网络;智能服务器;移动计算;云卸载
一、介绍
DNN architectures are promising solutions in achieving remarkable results in a wide range of machine learning applications, including, but not limited to computer vision, speech recognition, language modeling, and autonomous cars. Currently, there is a major growing trend in introducing more advanced DNN architectures and employing them in end-user applications. The considerable improvements in DNNs are usually achieved by increasing computational complexity which requires more resources for both training and inference [1]. Recent research directions to make this progress sustainable are: development of Graphical Processing Units (GPUs) as the vital hardware component of both servers and mobile devices [2], design of effificient algorithms for large-scale distributed training [3] and effificient inference [4], compression and approximation of models [5], and most recently introducing collaborative computation of cloud and fog as known as dew computing [6].
DNN架构在广泛的机器学习应用领域中取得显著成果的有前途的解决方案,包括但不限于计算机视觉,语音识别,语言建模恶化自动驾驶汽车。目前,引入更先进的 DNN 架构并将其用于最终用户应用程序的趋势越来越大。DNN 的显着改进通常是通过增加计算复杂度来实现的,这需要更多资源用于训练和推理[1]。使这一进展可持续的最新研究方向是: 开发图形处理单元 (GPU) 作为服务器和移动设备的重要硬件组件[2]。为大规模分布式训练设计高效算法[3]和高效推理算法[4],压缩和近似模型[5],并且最近引入了云计算和雾计算的协作计算,露计算[6]。
Deployment of cloud servers for computation and storage is becoming extensively favorable due to technical advancements and improved accessibility. Scalability, low cost, and satisfactory Quality of Service (QoS) made offlfloading to cloud a typical choice for computing-intensive tasks. On theother side, mobile-device are being equipped with more powerful general-purpose CPUs and GPUs. Very recently there is a new trend in hardware companies to design dedicated chips to better tackle machine-learning tasks. For example, Apple’s A11 Bionic chip [7] used in iPhone X uses a neural engine in its GPU to speed up the DNN queries of applications such as face identifification and facial motion capture [8].
由于技术的进步和可达性的提升,为计算和存储配置云服务器变得广受好评。可扩展性,低花费和令人满意的服务质量(Qos)使卸载到云端成为计算复杂性任务的重要选择。另一方面,移动设备配备更强大的通用 CPU 和 GPU。最近,硬件公司出现了一种新趋势,即设计专用芯片以更好地处理机器学习任务。举个例子,iPhone X 中使用的苹果 A11 仿生芯片 [7] 在其 GPU 中使用神经引擎来加速应用程序的 DNN 查询,例如面部识别和面部动作捕捉 [8]。
In the status-quo approaches, there are two methods for DNN inference: mobile-only and cloud-only. In simple models, a mobile device is suffificient for performing all the computations. In the case of complex models, the raw input data (image, video stream, voice, etc.) is uploaded to and then the required computations are performed on the cloud server. The results of the task are later downloaded to the device. The effects of raw input and feature compression are studied in [9] and [10].
在现有的方法中,有两种DNN推理方法:仅移动设备和仅云。在简单模型中,移动设备足以执行所有计算。在复杂模型的情况下,原始输入数据(图像、视频流、语音等)被上传到云端,然后在云服务器上执行所需的计算。任务的结果稍后会下载到设备。在[9]和[10]中研究了原始输入和特征压缩的影响。
Despite the recent improvements of the mobile devices mentioned earlier, the computational power of mobile devices is still signifificantly weaker than the cloud ones. Therefore, the mobile-only approach can cause large inference latency and failure in meeting QoS. Moreover, embedded devices undergo major energy consumption constraints due to battery limits. On the other hand, cloud-only suffers communication overhead for uploading the raw data and downloading the outputs. Moreover, slowdowns caused by service congestion, subscription costs, and network dependency should be considered as downsides of this approach [11].
尽管前面提到的移动设备最近有所改进,但移动设备的计算能力仍然明显弱于云计算。因此,仅移动设备方法会导致较大的推理延迟和无法满足 QoS。此外,由于电池限制,嵌入式设备经历了重大的能源消耗限制。另一方面,仅云会因上传原始数据和下载输出而遭受通信开销。此外,由服务拥塞、订阅成本和网络依赖性引起的减速也是仅云这种方法的缺点[11]。
The superiority and persistent improvement of DNNs depend heavily on providing a huge amount of training data. Typically, this data is collected from different resources and later fed into a network for training. The fifinal model can then be delivered to different devices for inference functions. However, there is a trend of applications requiring adaptive learning in online environments, such as self-driving cars and security drones [12], [13]. Model parameters in these smart devices are constantly being changed based on their continuous interaction with their environment. The complexity of these architectures with an increasing number of parameters and current cloud-only methods for DNN training implies a constant communication cost and the burden of increased energy consumption for mobile devices. The main difference of collaborative training and cloud-only training is that the data transferred in the cloud-only approach is the input data and model parameters but in the collaborative approach, it is layer(s)’s output and a portion of model parameters. Therefore, the amount of data communicated can be potentially decreased [14].
DNN 的优越性和持续改进在很大程度上取决于提供大量的训练数据。通常,这些数据是从不同资源收集的,然后输入到网络中进行训练。然后可以将最终模型传送到不同的设备以进行推理功能。然而,在线环境中存在需要自适应学习的应用程序的趋势,例如自动驾驶汽车和安全无人机[12],[13]。这些智能设备中的模型参数会根据它们与环境的持续交互而不断变化。这些架构的复杂性以及越来越多的参数和当前用于 DNN 训练的仅云方法意味着持续的通信成本和移动设备能耗增加的负担。协同训练和纯云训练的主要区别在于纯云方法中传输的数据是输入数据和模型参数,而在协同方法中,它是层的输出和模型参数的一部分。因此,通信的数据量可能会减少 [14]。
Automatic partitioning of computationally extensive tasks over the cloud for optimization of performance and energy consumption has been already well-studied [15]. Most recently, scalable distributed hierarchy structures between the end-user device, edge, and cloud have been suggested [16] which are specialized for DNN applications. However, exploiting the layer granularity of DNN architectures for runtime partitioning has not been studied thoroughly yet.
已经对云上计算量大的任务的自动分区以优化性能和能耗进行了充分研究 [15]。最近,已经提出了终端用户设备、边缘和云之间的可扩展分布式层次结构 [16],它们专门用于 DNN 应用程序。然而,尚未彻底研究利用 DNN 架构的层粒度进行运行时分区。
In this work, we are investigating the inference and training of DNNs in a joint platform of mobile and cloud as an alternative to the current single-platform methods as illustrated in Fig. 1. Considering DNN architectures as an ordered sequence of layers, and the possibility of computation of every layer either on mobile or cloud, we can model the DNN structure as a Directed Acyclic Graph (DAG). The parameters of our real-time adaptive model are dependent on the following factors: mobile/cloud hardware and software resources, battery capacity, network specififications, and QoS. Based on this modeling, we show that the problem of fifinding the optimal computation schedule for different scenarios, i.e., best performance or energy consumption, can be reduced to the polynomial-time shortest path problem.
在这项工作中,我们正在研究移动设备和云联合平台中 DNN 的推理和训练,作为当前单平台方法的替代方案,如图 1 所示。将 DNN 架构视为层的有序序列,以及在移动或云上计算每一层的可能性。我们可以将 DNN 结构建模为有向无环图 (DAG)。我们的实时自适应模型的参数取决于以下因素:移动设备/云的硬件和软件资源,电池容量,网络规格和Qos。基于此建模,我们表明寻找不同场景的最佳计算调度的问题,即最佳性能或能耗,可以简化为多项式时间最短路径问题。
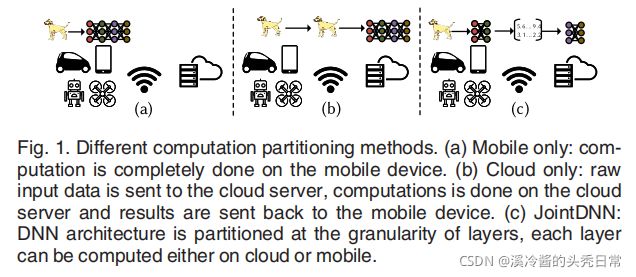
To present realistic results, we made experiments with fair representative hardware of mobile device and cloud. To model the communication costs between platforms, we used various mobile network technologies and the most recent reports on their specififications in the U.S.
为了呈现真实的结果,我们对移动设备和云的具有代表性的硬件进行了实验。为了模拟平台之间的通信成本,我们使用了各种移动网络技术以及有关它们在美国的规格的最新报告。
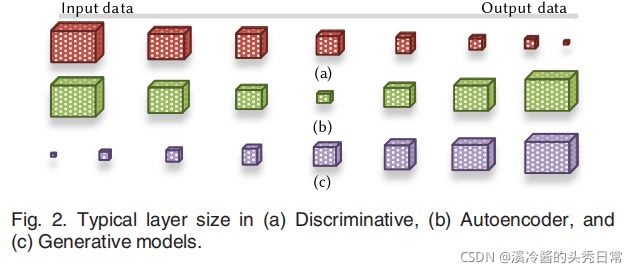
DNN architectures can be categorized based on functionality. These differences enforce specifific type and order of layers in architecture, directly affecting the partitioning result in the collaborative method. For discriminative models, used in recognition applications, the layer size gradually decreases going from input toward output as shown in Fig. 2. This sequence suggests the computation of the fifirst few layers on the mobile device to avoid excessive communication cost of uploading large raw input data. On the other hand, the growth of the layer output size from input to output in generative models which are used for synthesizing new data, implies the possibility of uploading a small input vector to the cloud and later downloading one of the last layers and performing the rest of computations on the mobile device for better effificiency. Interesting mobile applications like image-to-image translation are implemented with autoencoder architectures whose middle layers sizes are smaller compared to their input and output. Consequently, to avoid huge communication costs, we expect the fifirst and last layers to be computed on the mobile device in our collaborative approach. We examined eight well-known DNN benchmarks selected from these categories to illustrate their differences in the collaborative computation approach.
DNN 架构可以根据功能进行分类。这些差异在架构中强制执行特定类型和层级的顺序,直接影响协作方法中的分区结果。对于识别应用中使用的判别模型,层大小从输入到输出逐渐减小,如图 2 所示。此序列建议在移动设备上计算前几层,以避免上传大量原始输入数据的过多通信成本。另一方面,在用于合成新数据的生成模型中,从输入到输出的层输出大小的增长意味着可以将一个小的输入向量上传到云端,然后下载最后一层并执行移动设备上的其余计算以提高效率。有趣的移动应用程序,如图像到图像的转换,是通过自编码器架构实现的,其中间层的尺寸与其输入和输出相比更小。因此,为了避免巨大的通信成本,我们希望在我们的协作方法中在移动设备上计算第一层和最后一层。我们检查了从这些类别中选出的八个著名的 DNN 基准,以说明它们在协作计算方法中的差异。
As we will see in Section 4, the communication between the mobile and cloud is the main bottleneck for both performance and energy in the collaborative approach. We investigated the specifific characteristics of CNN layer outputs and introduced a loss-less compression approach to reduce the communication costs while preserving the model accuracy.
正如我们将在第 4 节中看到的,移动和云之间的通信是协作方法中性能和能量的主要瓶颈。我们研究了 CNN 层输出的具体特性,并引入了一种无损压缩方法来降低通信成本,同时保持模型的准确性。
State-of-the-art work for collaborative computation of DNNs [14] only considers one offlfloading point, assigning computation of its previous layers and next layers on the mobile and cloud platforms, respectively. We show that this approach is non-generic and fails to be optimal, and introduced a new method granting the possibility of computation on either platform for each layer independent of other layers. Our evaluations show that JointDNN signifificantly improves the latency and energy up to 3x and 7x respectively compared to the status-quo single platform approaches without any compression. The main contributions of this paper can be listed as:
DNN 协同计算的最新工作 [14] 仅考虑一个卸载点,分别在移动和云平台上分配其前一层和下一层的计算。我们表明这种方法是非通用的并且不是最优的,并引入了一种新方法,允许在任一平台上为独立于其他层的每一层进行计算。我们的评估表明,与没有任何压缩的现状单一平台方法相比,JointDNN 显着地将延迟和能量分别提高了 3 倍和 7 倍。本文的主要贡献可以列举如下:
1.Introducing a new approach for the collaborative computation of DNNs between the mobile and cloud
1. 引入一种新的移动和云端 DNN 协同计算方法
2.Formulating the problem of optimal computation scheduling of DNNs at layer granularity in the mobile cloud computing environment as the shortest path problem and integer linear programming (ILP)
2.将移动云计算环境中层粒度DNN的最优计算调度问题表述为最短路径问题和整数线性规划(ILP)
3.Examining the effect of compression on the outputs of DNN layers to improve communication costs
3. 检查压缩对 DNN 层输出的影响以提高通信成本
4.Demonstrating the signifificant improvements in performance, mobile energy consumption, and cloud workload achieved by using JointDNN
4. 展示使用 JointDNN 在性能、移动能耗和云工作负载方面取得的显着改善
二、问题定义和建模
In this section, we explain the general architecture of DNN layers and our profifiling method. Moreover, we elaborate on how cost optimization can be reduced to the shortest path problem by introducing the JointDNN graph model. Finally, we show how the constrained problem is formulated by setting up ILP.
在这个章节,我们解释了通常的DNN层结构和我们的划分方法。与此同时,我们详细说明了如何通过引入 JointDNN 图模型将成本优化精简到最短路径问题。最后,我们展示了怎样通过设置ILP来制定约束问题。
2.1 能量和延迟分析
There are three methods in measuring the latency and energy consumption of each layer in neural networks [17]:
在测量每层神经网络延迟和能耗的问题上,这里有三个方法:
Statistical Modeling. In this method, a regression model over the confifigurable parameters of operators (e.g., fifilter size in the convolution) can be used to estimate the associated latency and energy. This method is prone to large errors because of the inter-layer optimizations performed by DNN software packages. Therefore, it is necessary to consider the execution of several consecutive operators grouped during profifiling. Many of these software packages are proprietary, making access to inter-layer optimization techniques impossible.
统计建模。在这个方法中,使用运算符的可配置参数(eg.卷积中的过滤器大小)的回归模型,可以用来估计相关的延迟和能量。由于 DNN 软件包执行的层间优化,这种方法容易出现大错误。因此,有必要去考虑在分析期间对几个连续运算符的执行。许多这些软件包都是专有的,因此无法使用层间优化技术。
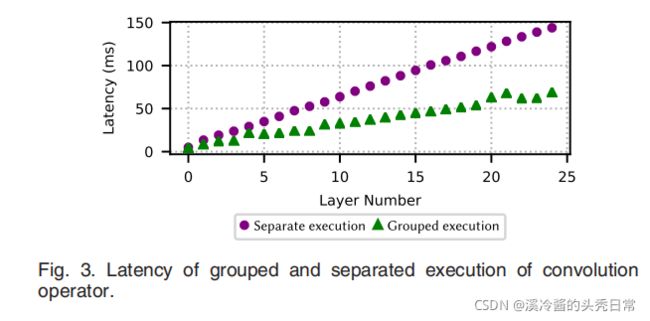
In order to illustrate this issue, we designed two experiments with 25 consecutive convolutions on NVIDIA Pascal GPU using cuDNN library [18]. In the fifirst experiment, we measure the latency of each convolution operator separately and set the total latency as the sum of them. In the second experiment, we execute the grouped convolutions in a single kernel together and measure the total latency. All parameters are located on the GPU’s memory in both experiments, avoiding any data transfer from the main memory to make sure results are exactly representing the actual computation latency.
为了说明这个问题,我们使用 cuDNN 库 [18] 在 NVIDIA Pascal GPU 上设计了两个具有 25 个连续卷积的实验。在第一次实验中,我们分别测量了每个卷积算子的延迟,并将总延迟设置为它们的总和。在第二个实验中,我们一起在单个内核中执行分组卷积并测量总延迟。在两个实验中,所有参数都位于 GPU 的内存中,避免从主内存传输任何数据,以确保结果准确代表实际计算延迟。
As we see in Fig. 3, there is a large error gap between separated and grouped execution experiments which grows as the number of convolutions is increased. This observation confifirms that we need to profifile grouped operators to have more accurate estimations. Considering the various consecutive combination of operators and different input sizes, this method requires a very large number of measurements, not to mention the need for a complex regression model.
如图3所示,分离的和分组的执行实验之间存在很大的误差差距,随着卷积数量的增加而增长。这一观察证实我们需要对分组的运营商进行概要分析以获得更准确的估计。考虑到算子的各种连续组合和不同的输入大小,这种方法需要非常大量的测量,更不用说需要复杂的回归模型了。
Analytical Modeling. To derive analytical formulations for estimating the latency and energy consumption, it is required to obtain the exact hardware and software specififications. However, the state-of-the-art in latency modeling of DNNs [19] fails to estimate layer-level delay withinan acceptable error bound, for instance, underestimating the latency of a fully connected layer with 4,096 neurons by around 900 percent. Industrial developers do not reveal the detailed hardware architecture specififications and the proprietary parallel computing architectures such as CUDA, therefore, the analytical approach could be quite challenging [20].
验证了每层的延迟 /能耗分开计算再加和是不正确的,存在较大的误差。
分析建模。为了推导出用于估计延迟和能耗的分析公式,需要获得准确的硬件和软件规格。然而,DNN [19] 延迟建模的最新技术未能在可接受的误差范围内估计层级延迟,例如,将具有 4,096 个神经元的完全连接层的延迟低估了约 900%。 工业开发人员没有透露详细的硬件架构规格和专有的并行计算架构,例如 CUDA,因此,分析方法可能非常具有挑战性 [20]。
Application-Specifific Profifiling. In this method, the DNN architecture of the application being used is profifiled in run-time. The number of applications in a mobile device using neural networks is generally limited. In conclusion, this method is more feasible, promising higher accuracy estimations. We have chosen this method for the estimation of energies and latencies in the experiments of this paper.
特定应用程序的分析。在这个方法中,正在使用的应用程序的 DNN 架构在运行时进行分析。使用神经网络的移动设备中的应用程序数量通常是有限的。总之,这种方法更可行,有望实现更高的准确度估计。在本文的实验中,我们选择了这种方法来估计能量和延迟。
2.2 JointDNN 图模型
First, we assume that a DNN is presented by a sequence of distinct layers with a linear topology as depicted in Fig. 4. Layers are executed sequentially, with output data generated by one layer feeds into the input of the next one. We denote the input and output data sizes of kth layer as  and
and  , respectively. Denoting the latency (energy) of layer k as
, respectively. Denoting the latency (energy) of layer k as  , where k=1,2,··· ,n,the total latency (energy) of querying the DNN is
, where k=1,2,··· ,n,the total latency (energy) of querying the DNN is ![]() .
.
首先,我们假设 DNN 由一系列具有线性拓扑的不同层呈现,如图 4 所示。每层依次执行,一层生成的输出数据是下一层的输入数据。我们将第k层的输入和输出数据大小分别记作和 。将第k层的延迟(能量)记作 ,k=1,2,···,n ,查询DNN总延迟(能量)是![]() 。
。

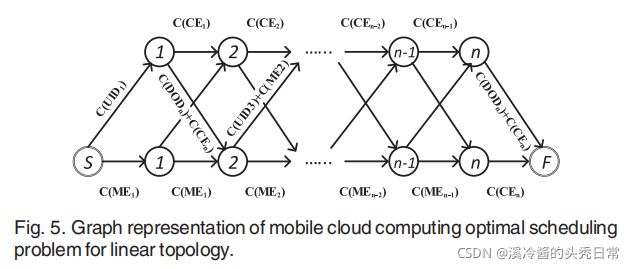
The mobile cloud computing optimal scheduling problem can be reduced to the shortest path problem, from node S to F, in the graph of Fig. 5. Mobile Execution cost of the kth layer (![]() ) is the cost of executing the kth layer in the mobile while the cloud server is idle. Cloud Execution cost of the kth layer (
) is the cost of executing the kth layer in the mobile while the cloud server is idle. Cloud Execution cost of the kth layer (![]() ) is the executing cost of the kth layer in the cloud server while the mobile is idle. Uploading the Input Data cost of the kth layer is the cost of uploading output data of the (k-1)th layer to the cloud server(
) is the executing cost of the kth layer in the cloud server while the mobile is idle. Uploading the Input Data cost of the kth layer is the cost of uploading output data of the (k-1)th layer to the cloud server( ![]() ). Downloading the Input Data cost of the kth layer is the cost of downloading output data of the (k-1)th layer to the mobile (
). Downloading the Input Data cost of the kth layer is the cost of downloading output data of the (k-1)th layer to the mobile (![]() ). The costs can refer to either latency or energy. However, as we showed in Section 2.1, the assumption of linear topology in DNNs is not true and we need to consider all the consecutive grouping of the layers in the network. This fact suggests the replacement of linear topology by a tournament graph as depicted in Fig. 6. We defifine the parameters of this new graph, JointDNN graph model, in Table 1.
). The costs can refer to either latency or energy. However, as we showed in Section 2.1, the assumption of linear topology in DNNs is not true and we need to consider all the consecutive grouping of the layers in the network. This fact suggests the replacement of linear topology by a tournament graph as depicted in Fig. 6. We defifine the parameters of this new graph, JointDNN graph model, in Table 1.
移动云计算最优调度问题可以简化为最短路径问题,从节点S到F,如图5所示。移动设备执行第k层的成本(![]() )相当于当云层闲置时候的移动设备执行第k层的成本。 云执行第k层的成本(
)相当于当云层闲置时候的移动设备执行第k层的成本。 云执行第k层的成本(![]() )相当于当移动设备闲置时候的云执行第k层的成本。上传第k层的输入数据的成本相当于将第(k-1)层的输出数据上传到云端的成本(
)相当于当移动设备闲置时候的云执行第k层的成本。上传第k层的输入数据的成本相当于将第(k-1)层的输出数据上传到云端的成本(![]() )。下载第k层的输入数据的成本相当于将第(k-1)层的输出数据下载到移动端的成本(
)。下载第k层的输入数据的成本相当于将第(k-1)层的输出数据下载到移动端的成本(![]() )。这个成本既可以代表延迟也可以代表能耗。然而,如我们在2.1节所看到的,DNN 中线性拓扑的假设是不正确的,我们需要考虑网络中所有层的连续分组。这一事实表明,用图 6 中描绘的图可以用于代替线性拓扑。我们在表 1 中定义了这个新图(JointDNN 图模型)的参数。
)。这个成本既可以代表延迟也可以代表能耗。然而,如我们在2.1节所看到的,DNN 中线性拓扑的假设是不正确的,我们需要考虑网络中所有层的连续分组。这一事实表明,用图 6 中描绘的图可以用于代替线性拓扑。我们在表 1 中定义了这个新图(JointDNN 图模型)的参数。


In this graph, node ![]() represents that the layers
represents that the layers  to
to  are computed on the cloud server, while node
are computed on the cloud server, while node ![]() represents that the layers to are computed on the mobile device. An edge between two adjacent nodes in JointDNN graph model is associated with four possible cases:
represents that the layers to are computed on the mobile device. An edge between two adjacent nodes in JointDNN graph model is associated with four possible cases:
在这个图中,![]() 表示在云服务器上计算的层,而
表示在云服务器上计算的层,而![]() 表示在移动设备上计算的层。在JointDNN图模型中,两个相邻节点之间的边有四种可能的情况:
表示在移动设备上计算的层。在JointDNN图模型中,两个相邻节点之间的边有四种可能的情况:
1) A transition from the mobile to the mobile, which only includes the mobile computation cost (![]() )
)
1) 从移动设备到移动设备的传输,只包括移动计算成本 ![]()
2) A transition from the cloud to the cloud, which only includes the cloud computation cost (![]() )
)
2)从云到云的传输,这只包括云计算成本 ![]()
3) A transition from the mobile to the cloud, which includes the mobile computation cost and uploading cost ofthe inputs of the next node (![]() )
)
3)从移动到云的传输,包括移动计算成本和下一个节点输入的上传成本![]()
4) A transition from the cloud to the mobile, which includes the cloud computation cost and downloading cost of the inputs of the next node (![]() ).
).
从云到移动的转换,包括云计算成本和下一个节点输入的下载成本 ![]()
Under this formulation, we can transform the computation scheduling problem to finding the shortest path from S to F. Residual networks are a class of powerful and easy-totrain architectures of DNNs [21]. In residual networks, as depicted in Fig. 7a, the output of one layer is fed into another layer with a distance of at least two. Thus, we need to keep track of the source layer (node 2 in Fig. 7) to know that this layer is computed on the mobile or the cloud. Our standard graph model has a memory of one which is the very previous layer. We provide a method to transform the computation graph of this type of network to our standard model, JointDNN graph.
在此公式下,我们可以将计算调度问题转化为寻找从S到F的最短路径。残差网络是DNNs[21]中一类功能强大且易于训练的结构。在残差网络中,如图7a所示,一层的输出馈入另一层,其距离至少为两层。因此,我们需要跟踪源层(图7中的节点2),以了解该层是在移动端或云上计算的。我们的标准图模型的内存是前一层。我们提供了一种将这类网络的计算图转换为我们的标准模型JointDNN图的方法。

In this regard, we add two additional chains of size  ,where k is the number of nodes in the residual block(3 in Fig. 7). One chain represents the case of computing layer 2 on the mobile and the other one represents the case of computing layer 2 on the cloud. In Fig. 7, we have only shown the weights that need to be modified, where D2 and U2 are the cost of downloading and uploading the output oflayer 2, respectively.
,where k is the number of nodes in the residual block(3 in Fig. 7). One chain represents the case of computing layer 2 on the mobile and the other one represents the case of computing layer 2 on the cloud. In Fig. 7, we have only shown the weights that need to be modified, where D2 and U2 are the cost of downloading and uploading the output oflayer 2, respectively.
在这方面,我们增加了两个额外的大小为 k-1 的链,其中 k 为残块中的节点数(图7中为3)。一条链表示移动端上的计算层情况,另一条链表示云上的计算层情况。在图7中,我们只显示了需要修改的权值,其中D2和U2分别是下载和上传第2层输出的成本。
By solving the shortest path problem in the JointDNN graph model, we can obtain the optimal scheduling of inference in DNNs. The online training consists of one inference and one back-propagation step. The total number of layers is noted by N consistently throughout this paper so there are 2N layers for modeling training, where the second N layers are the mirrored version of the first N layers, and their associated operations are the gradients of the error function concerning the DNN’s weights. The main difference between the mobile cloud computing graph of inference and online training is the need for updating the model by downloading the new weights from the cloud. We assume that the cloud server performs the whole back-propagation step separately, even if it is scheduled to be done on the mobile, therefore, there is no need for the mobile device to upload the weights that are updated by itself to save mobile energy consumption. The modification in the JointDNN graph model is adding the costs of downloading weights of the layers that are updated in the cloud to ![]() . The shortest path problem can be solved in polynomial time efficiently.
. The shortest path problem can be solved in polynomial time efficiently.
通过求解JointDNN图模型中的最短路径问题,可以得到dnn中推理的最优调度。在线训练由一个推理步骤和一个反向传播步骤组成。层的总数在本文中一直由N表示,因此有2N层用于建模训练,其中第二层N层是第二层N层的镜像版本,它们的相关操作是关于DNN权重的误差函数的梯度。移动云计算图的推理和在线训练的主要区别是需要从云下载新的权重来更新模型。我们假设云服务器单独执行整个反向传播步骤,即使计划在移动设备上执行,那么移动设备就不需要上传自己更新的权值来节省移动能耗。JointDNN图模型中的修改是添加在云中更新的层的下载权值的成本![]() 。最短路径问题可以在多项式时间内有效地求解。
。最短路径问题可以在多项式时间内有效地求解。
However, the problem of the shortest path subjected to constraints is NP-Complete [22]. For instance, assuming our standard graph is constructed for energy and we need to find the shortest path subject to the constraint of the total latency of that path is less than a time deadline (QoS). However, there is an approximation solution to this problem, “LARAC” algorithm [23], the nature of our application does not require to solve this optimization problem frequently, therefore, we aim to obtain the optimal solution. We can constitute a small look-up table of optimization results for a different set of parameters (e.g., network bandwidth, cloud server load, etc.). We provide the ILP formulations of DNN partitioning in the following sections.
然而,受约束的最短路径问题是NP-Complete[22]。例如,假设我们的标准图是为能量构建的,我们需要找到一条最短路径,该路径的总延迟小于一个时间截止日期(QoS)。但是,这个问题有一个近似解,“LARAC”算法[23],我们的应用的性质不需要经常解决这个优化问题,因此,我们的目标是获得最优解。我们可以为一组不同的参数(如网络带宽、云服务器负载等)组成一个优化结果的小查询表。我们在接下来的章节中提供了DNN划分的ILP公式。
2.3 ILP设置
2.3.1 用于推理的性能高效计算卸载ILP设置
We formulated the scheduling of inference in DNNs as an ILP with tractable number of variables. In our method, first we profile the delay and energy consumption of consecutive
layers of size ![]() . Thus, we will have number of different profiling values for delay and energy. Considering layer i to layer j to be computed either on the mobile device or cloud server, we assign two binary variables
. Thus, we will have number of different profiling values for delay and energy. Considering layer i to layer j to be computed either on the mobile device or cloud server, we assign two binary variables ![]() and
and ![]() , respectively. Download and upload communication delays needs to be added to the execution time, when switching from/to cloud to/from mobile, respectively.
, respectively. Download and upload communication delays needs to be added to the execution time, when switching from/to cloud to/from mobile, respectively.
我们将DNN中的推理调度制定为具有可处理的变量数量的ILP。在我们的方法中,首先我们描绘了连续层的延迟和能量消耗的大小 ![]() .因此,我们将有许多不同的延迟和能量分析值。考虑到每一层都是在移动设备或云服务器上计算的,我们分配两个二进制变量分别为
.因此,我们将有许多不同的延迟和能量分析值。考虑到每一层都是在移动设备或云服务器上计算的,我们分配两个二进制变量分别为![]() 和
和 ![]() 。下载和上传通信延迟需要分别添加到执行时间中
。下载和上传通信延迟需要分别添加到执行时间中
![]()

![]() and
and ![]() represent the execution time of the ith layer to the jth layer on the mobile and cloud, respectively.
represent the execution time of the ith layer to the jth layer on the mobile and cloud, respectively.![]() and
and ![]() represent the latency of downloading and uploading the output of the ith layer, respectively. Considering each set of the consecutive layers, whenever
represent the latency of downloading and uploading the output of the ith layer, respectively. Considering each set of the consecutive layers, whenever ![]() and one of
and one of ![]() are equal to one, the output of the jth layer is uploaded to the cloud. The same argument applies to downloading. We also note that the last two terms in Eq. (3) represent the condition by which the last layer is computed on the cloud and we need to download the output to the mobile device, and the first layer is computed on the cloud and we need to upload the input to the cloud, respectively. To support for residual architectures, we need to add a pair of download and upload terms similar to the first two terms in Eq. (3) for the starting and ending layers of each residual block. In order to guarantee that all layers are computed exactly once, we need to add the following set of constraints:
are equal to one, the output of the jth layer is uploaded to the cloud. The same argument applies to downloading. We also note that the last two terms in Eq. (3) represent the condition by which the last layer is computed on the cloud and we need to download the output to the mobile device, and the first layer is computed on the cloud and we need to upload the input to the cloud, respectively. To support for residual architectures, we need to add a pair of download and upload terms similar to the first two terms in Eq. (3) for the starting and ending layers of each residual block. In order to guarantee that all layers are computed exactly once, we need to add the following set of constraints:
![]() 和
和 ![]() 分别表示第i层到第j层在移动和云上的执行时间。
分别表示第i层到第j层在移动和云上的执行时间。![]() 和
和![]() 分别表示下载第i层输出和上传第i层输出的延时。考虑每一组连续层,当
分别表示下载第i层输出和上传第i层输出的延时。考虑每一组连续层,当![]() 和
和 ![]() 之一等于1时,将第j层的输出上传到云端。同样的方法也适用于下载。我们还注意到Eq.(3)的最后两项分别表示最后一层在云端计算需要将输出下载到移动设备上,第一层在云端计算需要上传输入到云端的情况。为了支持残差架构,我们需要为每个残差块的起始层和结束层添加一对类似于Eq.(3)中前两个项的下载和上传项。为了保证所有层都精确计算一次,我们需要添加以下约束:
之一等于1时,将第j层的输出上传到云端。同样的方法也适用于下载。我们还注意到Eq.(3)的最后两项分别表示最后一层在云端计算需要将输出下载到移动设备上,第一层在云端计算需要上传输入到云端的情况。为了支持残差架构,我们需要为每个残差块的起始层和结束层添加一对类似于Eq.(3)中前两个项的下载和上传项。为了保证所有层都精确计算一次,我们需要添加以下约束:
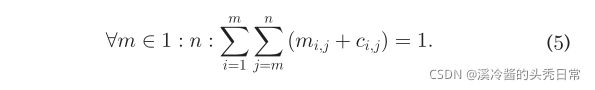
Because of the non-linearity of multiplication, an additional step is needed to transform Eq. (3) to the standard form of ILP. We define two sets of new variables with the following constraints:
由于乘法的非线性,需要一个额外的步骤将Eq.(3)转换为ILP的标准形式。我们定义了两组具有以下约束条件的新变量:
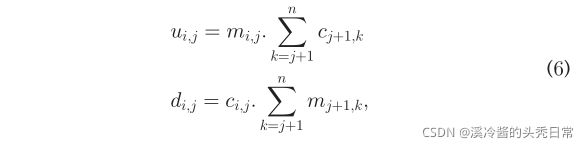

The first two constraints ensure that ![]() will be zero if either
will be zero if either ![]() or
or  are zero. The third inequality guarantees that
are zero. The third inequality guarantees that ![]() will take value one if both binary variables,
will take value one if both binary variables,![]() and are set to one. The same reasoning works for
and are set to one. The same reasoning works for ![]() . In summary, the total number of variables in our ILP formulation will be
. In summary, the total number of variables in our ILP formulation will be ![]() , where N is total number of layers in the network.
, where N is total number of layers in the network.
前两个约束确保如果![]() 和中有一个为0,第三个不等式保证
和中有一个为0,第三个不等式保证![]() 的值为0。第三个等式保证如果两个二元变量
的值为0。第三个等式保证如果两个二元变量![]() 和 都被设置为1,那么
和 都被设置为1,那么![]() 的值为1。同样的推理也适用于
的值为1。同样的推理也适用于![]() 。总之,我们的ILP公式中的变量总数为
。总之,我们的ILP公式中的变量总数为![]() ,其中是N网络中层的总数。
,其中是N网络中层的总数。
2.3.2 用于推理的能源高效计算卸载ILP设置
Because of the nature of the application, we only care about the energy consumption on the mobile side. We formulate ILP as follows:
由于应用程序的性质,我们只关心移动端的能耗。我们制定的ILP如下:

![]() and
and  represent the amount of energy required to compute the ith layer to the jth layer on the mobile and cloud, respectively.
represent the amount of energy required to compute the ith layer to the jth layer on the mobile and cloud, respectively. ![]() and
and ![]() represent the energy required to download and upload the output of ith layer, respectively. Similar to performance efficient ILP constraints, each layer should be executed exactly once
represent the energy required to download and upload the output of ith layer, respectively. Similar to performance efficient ILP constraints, each layer should be executed exactly once
![]() 和表示在移动和云上分别计算第i层到第j层所需的能量。
和表示在移动和云上分别计算第i层到第j层所需的能量。![]() 和
和![]() 分别表示下载第i层输出和上传第i层输出所需的能量。与性能高效的ILP约束类似,每一层都应该只执行一次
分别表示下载第i层输出和上传第i层输出所需的能量。与性能高效的ILP约束类似,每一层都应该只执行一次
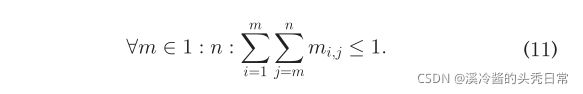
The ILP problem can be solved for different set of parameters (e.g., different uplink and download speeds), and then the scheduling results can be stored as a look-up table in the mobile device. Moreover because the number of variables in this setup is tractable solving ILP is quick. For instance, solving ILP for AlexNet takes around 0.045 seconds on Intel (R) Core(TM) i7-3770 CPU with MATLAB’s intlinprog() function using primal simplex algorithm.
可以针对不同的参数集(如不同的上行和下载速度)解决ILP问题,然后将调度结果以查表的形式存储在移动设备中。此外,由于在这个设置中变量的数量是可处理的,求解ILP是快速的。例如,在Intel (R) Core(TM) i7-3770 CPU上用MATLAB的intlinprog()函数,使用原始单纯形算法解决AlexNet的ILP大约需要0.045秒。
2.3.3 用于训练的性能高效计算卸载ILP设置
The ILP formulation of online training phase is very similar to that of inference. In online training we have 2N layers instead of N obtained by mirroring the DNN, where the second N layers are backward propagation. Moreover, we need to download the weights that are updated in the cloud to the mobile. We assume that the cloud server always has the most updated version of the weights and does not require the mobile device to upload the updated weights. The following terms need to be added for the ILP setup of training
在线培训阶段的ILP制定与推理阶段非常相似。在在线培训中,我们有2N层,而不是通过镜像DNN获得的N层,其中第2N层是反向传播的。此外,我们需要将在云中更新的权重下载到移动端。我们假设云服务器总是拥有权值的最新版本,不需要移动设备上传更新的权值。培训的ILP设置需要添加以下条款:

2.3.4 用于训练的能源高效计算卸载ILP设置


2.3.5 场景
There can be different optimization scenarios defined for ILP as listed below:
可以为ILP定义不同的优化场景,如下所示:
1)Performance efficient computation:In this case, it is sufficient to solve the ILP formulation for performance efficient computation offloading.
1)性能高效的计算:在这种情况下,求解ILP公式就足以实现性能高效的计算卸载。
2)Energy efficient computation:In this case, it is sufficient to solve the ILP formulation for energy efficient computation offloading.
2)节能计算:在这种情况下,解决节能计算卸载的ILP公式就足够了。
3)Battery budget limitation:In this case, based on the available battery, the operating system can decide to dedicate a specific amount of energy consumption to each application. By adding the following constraint to the performance efficient ILP formulation, our framework would adapt to battery limitations.
3)电池预算限制:在这种情况下,基于可用的电池,操作系统可以决定为每个应用程序指定特定数量的能源消耗。通过在高性能ILP配方中添加以下约束,我们的框架将适应电池的限制。
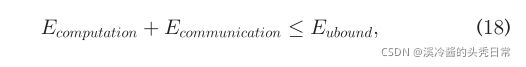
4)Cloud limited resources:In the presence of cloud server congestion or limitations on user’s subscription, we can apply execution time constraints to each application to alleviate the server load
4)云资源有限:在云服务器拥塞或用户订阅受限的情况下,我们可以对每个应用程序应用执行时间约束,以减轻服务器负载

5)QoS:In this scenario, we minimize the required energy consumption while meeting a specified deadline
5)QoS:在这个场景中,我们在满足指定期限的同时最小化所需的能量消耗

This constraint could be applied to both energy and performance efficient ILP formulations.
这一约束条件适用于能源和性能高效的ILP方案。
三、评估
3.1 深度结构基准
Since the architecture of neural networks depends on the type of application, we have chosen three common application types of DNNs as shown in Table 2:
由于神经网络的架构取决于应用类型,我们选择了三种常见的dnn应用类型,如表2所示:
Discriminative neural networks are a class of models in machine learning for modeling the conditional probability distribution  . This class generally is used in classification and regression tasks. AlexNet [24], OverFeat [25], VGG16 [26], Deep Speech [27], ResNet [21], and NiN [28] are well-known discriminative models we use as benchmarks in this experiment. Except for Deep Speech, used for speech recognition, all other benchmarks are used in image classification tasks.
. This class generally is used in classification and regression tasks. AlexNet [24], OverFeat [25], VGG16 [26], Deep Speech [27], ResNet [21], and NiN [28] are well-known discriminative models we use as benchmarks in this experiment. Except for Deep Speech, used for speech recognition, all other benchmarks are used in image classification tasks.
判别神经网络是机器学习中一类用于条件概率建模的模型。这个类通常用于分类和回归任务。AlexNet [24], OverFeat [25], VGG16 [26], Deep Speech [27], ResNet[21]和NiN[28]是我们在实验中使用的著名的判别模型作为基准。除了用于语音识别的深度语音,所有其他基准都用于图像分类任务。
Generative neural networks model the joint probability distribution 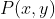 , allowing generation of new samples. These networks have applications in Computer Vision [29] and Robotics [30], which can be deployed on a mobile device. Chair [31] is a generative model we use as a benchmark in this work
, allowing generation of new samples. These networks have applications in Computer Vision [29] and Robotics [30], which can be deployed on a mobile device. Chair [31] is a generative model we use as a benchmark in this work
生成神经网络模型 的联合概率分布,允许生成新样本。这些网络在计算机视觉[29]和机器人[30]中有应用,它们可以部署在移动设备上。[31]chair是一个生成模型,我们在这个工作中使用作为基准
Autoencoders are another class of neural networks used to learn a representation for a data set. Their applications are image reconstruction, image to image translation, and denoising to name a few. Mobile robots can be equipped with autoencoders to be used in their computer vision tasks. We use Pix2Pix [32], as a benchmark from this class.
自动编码器是另一类用于学习数据集表示的神经网络。它们的应用包括图像重建、图像到图像的转换和去噪等等。移动机器人可以配备用于计算机视觉任务的自动编码器。我们使用Pix2Pix[32]作为这个类的基准。
3.2 移动设备和服务器设置
We used the Jetson TX2 module developed by NVIDIA [33], a fair representation of mobile computation power as our mobile device. This module enables efficient implementation of DNN applications used in products such as robots,drones, and smart cameras. It is equipped with NVIDIA Pascal GPU with 256 CUDA cores and a shared 8 GB 128 bit LPDDR4 memory between GPU and CPU. To measure the power consumption of the mobile platform, we used INA226 power sensor [34].
NVIDIA Tesla K40C [35] with 12 GB memory serves as our server GPU. The computation capability of this device is more than one order of magnitude compared to our mobile device.
NVIDIA Tesla K40C[35]的内存为12GB作为我们的服务器GPU。这个设备的计算能力比我们的移动设备多一个数量级。
3.3 通信参数
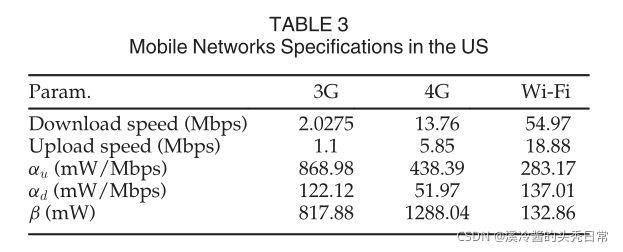
To model the communication between platforms, we used the average download and upload speed of mobile Internet [36], [37] for different networks (3G, 4G and Wi-Fi) as shown in Table 3.
为了建模平台间的通信,我们使用不同网络(3G、4G和Wi-Fi)的移动互联网[36]、[37]的平均下载和上传速度,如表3所示。
The communication power for download (![]() ) and upload (
) and upload (![]() ) is dependent on the network throughput (
) is dependent on the network throughput ( ![]() 和
和 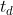 ). Comprehensive examinations in [38] indicates that uplink and downlink power can be modeled with linear equations (Eq. (21)) fairly accurate with less than 6 percent error rate. Table 3 shows the parameter values of this equation for different networks
). Comprehensive examinations in [38] indicates that uplink and downlink power can be modeled with linear equations (Eq. (21)) fairly accurate with less than 6 percent error rate. Table 3 shows the parameter values of this equation for different networks
下载(Pd)和上传(Pu)的通信功率取决于网络吞吐量(![]() 和)。[38]的综合检验表明,上行和下行功率可以用线性方程(Eq.(21))模拟,相当准确,错误率低于6%。表3给出了不同网络下该方程的参数值。
和)。[38]的综合检验表明,上行和下行功率可以用线性方程(Eq.(21))模拟,相当准确,错误率低于6%。表3给出了不同网络下该方程的参数值。

四、结果
The latency and energy improvements of inference and online training with our engine for 8 different benchmarks are shown in Figs. 8 and 9, respectively. We considered the best case of mobile-only and cloud-only as our baseline. JointDNN can achieve up to 66 and 86 percent improvements in latency and energy consumption, respectively during inference. Communication cost increases linearly with batch size while this is not the case for computation cost and it grows with a much lower rate, as depicted in Fig. 10b. Therefore, a key observation is that as we increase the batch size, the mobile-only approach becomes more preferable.
图8和图9分别显示了我们的引擎对8个不同基准的推理和在线训练的延迟和能量改进。我们以只适用于移动设备和云计算的最佳案例为基准。在推理过程中,JointDNN可以实现66%的延迟和86%的能量消耗改善。通信成本随批量大小线性增加,而计算成本则不是这样,它以更低的速率增长,如图10b所示。因此,一个关键的观察结果是,随着批量大小的增加,只使用移动设备的方法变得更可取。

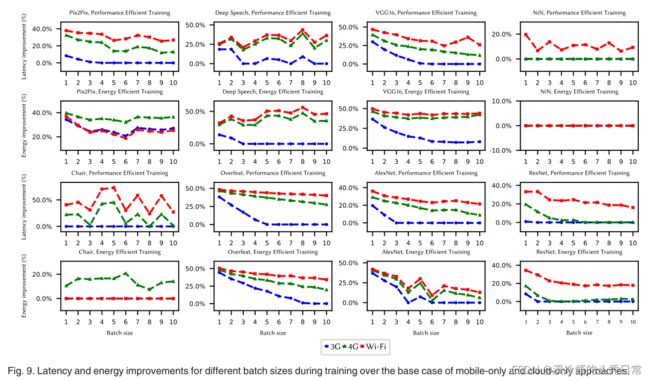

During online training, the huge communication overhead of transmitting the updated weights will be added to the total cost. Therefore, to avoid downloading this large data, only a few back-propagation steps are computed in the cloud server. We performed a simulation by varying the percentage of updated weight. As the percentage of updated weights increases, the latency and energy consumption becomes constant which is shown in Fig. 10. This is the result of the fact that all the backpropagations will be performed on the mobile device and weights are not transferred from the cloud to the mobile. JointDNN can achieve improvements up to 73 percent in latency and 56 percent in energy consumption during inference.
在线训练过程中,传输更新权值的巨大通信开销将增加到总成本中。因此,为了避免下载这些庞大的数据,只需要在云服务器中计算少量的反向传播步骤。我们通过改变更新权重的百分比来进行模拟。随着权值更新百分比的增加,延迟和能量消耗趋于恒定,如图10所示。这是由于所有的反向传播都将在移动设备上执行,并且权重没有从云转移到移动设备。在推理过程中,JointDNN可以实现73%的延迟和56%的能量消耗的改善。
Different patterns of scheduling are demonstrated in Fig. 11. They represent the optimal solution in the Wi-Fi network while optimizing for latency while mobile/cloud is allowed to use up to half of their computing resources. They show how the computations in DNN is divided between the mobile and the cloud. As can be seen, discriminative models (e.g., AlexNet), inference follows a mobilecloud pattern and training follows a mobile-cloud-mobile pattern. The intuition is that the last layers are computationally intensive (fully connected layers) but with small data sizes, which require a low communication cost, therefore, the last layers tend to be computed on the cloud. For generative models (e.g., Chair), the execution schedule of inference is the opposite of discriminative networks, in which the last layers are generally huge and in the optimal solution they are computed on the mobile. The reason behind not having any improvement over the base case of mobile-only is that the amount of transferred data is large. Besides, cloud-only becomes the best solution when the amount of transferred data is small (e.g., generative models). Lastly, for autoencoders, where both the input and output data sizes are large, the first and last layers are computed on the mobile.
不同的调度模式如图11所示。它们代表了Wi-Fi网络中的最佳解决方案,同时优化了延迟,而移动/云允许使用多达一半的计算资源。它们展示了DNN的计算是如何在移动和云之间进行划分的。可以看出,判别模型(如AlexNet),推理遵循移动云模式,训练遵循移动云-移动模式。直观的感觉是,最后一层是计算密集型的(全连接层),但数据量小,需要低通信成本,因此,最后一层往往在云上计算。对于生成模型(例如,Chair),推理的执行时间表与判别网络相反,在中,最后一层通常是巨大的,在最优的解决方案中,它们是在移动端计算的。没有对mobile-only的基本情况进行任何改进的原因是传输的数据量很大。此外,当传输的数据量很小时(例如生成模型),云计算成为最佳解决方案。最后,对于自动编码器,当输入和输出的数据大小都很大时,第一层和最后一层在移动端上计算。

JointDNN pushes some parts of the computations toward the mobile device. As a result, this will lead to less workload on the cloud server. As we see in Table 4, we can reduce the cloud server’s workload up to 84 and 53 percent on average, which enables the cloud provider to provide service to more users, while obtaining higher performance and lower energy consumption compared to single-platform approaches.
JointDNN将部分计算推向移动设备。因此,这将减少云服务器上的工作负载。如表4所示,我们可以将云服务器的工作负载平均减少84%和53%,这使得云提供商能够向更多用户提供服务,同时与单一平台方法相比,可以获得更高的性能和更低的能耗。

4.1 通信优势
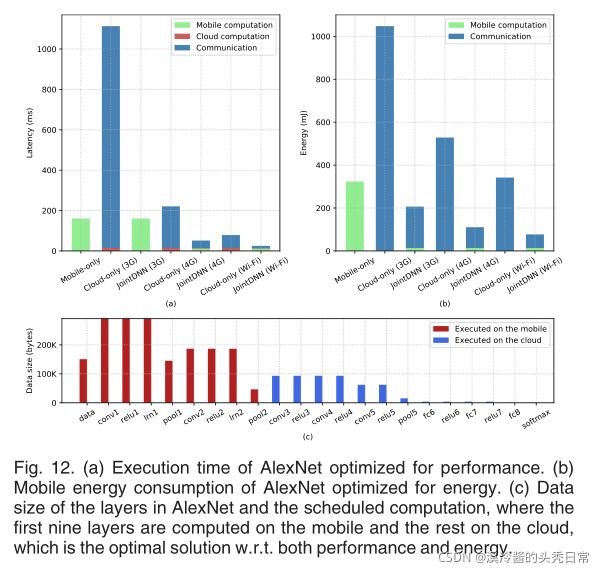
Execution time and energy breakdown for AlexNet, which is noted as a representative for the state-of-the-art architectures deployed in cloud servers, is depicted in Fig. 12. The cloud-only approach is dominated by the communication costs. As demonstrated in Fig. 12, 99, 93 and 81 percent of the total execution time are used for communication in case of 3G, 4G, and Wi-Fi, respectively. This relative portion also applies to energy consumption. Comparing the latency and energy of the communication to those of mobile-only approach, we notice that the mobile-only approach for AlexNet is better than the cloud-only approach in all the mobile networks. We apply loss-less compression methods to reduce the overheads of communication, which will be covered in the next section.
图12描述了AlexNet的执行时间和能量分解,它被认为是云服务器中部署的最先进架构的代表。只使用云计算的方法主要是由通信成本决定的。如图12所示,在3G、4G和Wi-Fi的情况下,通信时间分别占总执行时间的99%、93%和81%。这一相对部分也适用于能源消耗。将通信的延迟和能量与仅移动方式进行比较,我们注意到,在所有移动网络中,AlexNet的仅移动方式比仅云方式更好。我们使用无损压缩方法来减少通信开销,这将在下一节中讨论。
4.2 层压缩
The preliminary results of our experiments show that more than 75 percent of the total energy and delay cost in DNNs are caused by communication in the collaborative approach. This cost is directly proportional to the size of the layer being downloaded to or uploaded from the mobile device. Because of the complex feature extraction process of DNNs, the size of some of the intermediate layers are even larger than the network’s input data. For example, this ratio can go as high as10X in VGG16. To address this bottleneck, we investigated the compression of the feature data before any communication. This process can be applied to different DNN architecture types; however, we only considered CNNs due to their specific characteristics explained later in detail.
我们实验的初步结果表明,在协作方式下,dnn中超过75%的总能量和延迟成本是由通信引起的。这一成本直接与从移动设备上下载或上传的层的大小成比例。由于dnn的特征提取过程复杂,一些中间层的大小甚至比网络的输入数据还要大。例如,这个比率可以高达10X 在VGG16。为了解决这个瓶颈,我们在任何通信之前研究了特征数据的压缩。该过程可应用于不同的DNN体系结构类型;然而,由于cnn的具体特点,我们只考虑了cnn。
CNN architectures are mostly used for image and video recognition applications. Because of the spatially local preservation characteristics ofconvlayers, we can assume that the outputs of the first convolution layers are following the same structure as the input image, as shown in Fig. 13. Moreover, a big ratio of layer outputs is expected to be zero due to the presence of the ReLU layer. Our observations shows that the ratio of neurons equal to zero(ZR)varies from 50 to 90 percent afterreluin CNNs. These two characteristics, layers being similar to the input image, and a large proportion of their data being a single value, suggest that we can employ existing image compression techniques to their output.
CNN架构主要用于图像和视频识别应用。由于卷积层的空间局部保存特性,我们可以假设第一卷积层的输出与输入图像遵循相同的结构,如图13所示。此外,由于ReLU层的存在,预计层输出的很大比例将为零。我们的观察表明,零神经元(ZR)的比例在50%到90%之间变化。这两个特征,层与输入图像相似,而且它们的数据的很大一部分是单一值,表明我们可以使用现有的图像压缩技术来输出它们。

There are two general categories of compression techniques, lossy and loss-less [40]. In loss-less techniques, the exact original information is reconstructed. On the contrary, lossy techniques use approximations and the original data cannot be reconstructed. In our experiments, we examined the impact of compression of layer outputs using PNG, a loss-less technique, based on the encoding of frequent sequences in an image.
有两大类压缩技术,有损压缩和无损压缩。在无损技术中,精确的原始信息被重建。相反,有损技术使用近似,原始数据不能重建。在我们的实验中,我们检查了使用PNG压缩层输出的影响,PNG是一种无损技术,基于图像中频繁序列的编码。
Even though the data type of DNN parameters in typical implementations is 32-bits floating-points, most image formats are based on 3-bytes RGB color triples. Therefore, to compress the layer in the same way as 2D pictures, the floating-point data should be quantized into 8-bits fixedpoint. Recent studies show representing the parameters of DNNs with only 4-bits affects the accuracy, not more than 1 percent [5]. In this work, we implemented our architectures with an 8-bits fixed-point and presented our baseline without any compression and quantization. The layers of CNN contain numerous channels of 2D matrices, each similar to an image. A simple method is to compress each channel separately. In addition to extra overhead of file header for each channel, this method will not take the best of the frequent sequence decoding of PNG. One alternative is locating different channels side by side, referred to as tiling, to form a large 2D matrix representing one layer as shown in Fig. 13. It should be noted that 1D fully connected layers are very small and we did not apply compression on them.
尽管DNN参数在典型实现中的数据类型是32位浮点,但大多数图像格式都是基于3字节的RGB颜色三元组。因此,要像2D图片一样压缩层,需要将浮点数据量化为8位的定点。最近的研究表明,仅用4位表示dnn的参数会影响精度,不超过1%[5]。在这项工作中,我们实现了我们的架构与8位定点,并提出了我们的基线没有任何压缩和量化。CNN的层包含许多二维矩阵的通道,每个通道类似于一张图像。一个简单的方法是分别压缩每个通道。除了每个通道的文件头的额外开销外,这种方法不会利用PNG的频繁序列译码的最佳效果。一种替代方法是将不同的通道并排放置,称为平铺,形成一个大的二维矩阵,表示一个层,如图13所示。需要注意的是,一维全连通层非常小,我们没有对它们进行压缩。
The Compression Ratio(CR)is defined as the ratio of the size of the layer (8-bit) to the size of the compressed 2D matrix in PNG. Looking at the results of compression for two different CNN architectures in Fig. 14, we can observe a high correlation between the ratio of pixels being zero(ZR)and CR. PNG can compress the layer data up to 5.8X and 3.5X by average, therefore the communication costs can be reduced drastically. By replacing the compressed layer’s output and adding the cost of the compression process itself, which is negligible compared to DNN operators, in JointDNN formulations, we achieve an extra 4.9X and 4.6X improvements in energy and latency on average, respectively.
压缩比(CR)定义为层(8位)的大小与PNG格式的压缩2D矩阵的大小之比。在图14中,我们可以看到两个不同的CNN架构的压缩结果,我们可以看到像素为0 (ZR)和CR之间有很高的相关性,PNG可以将层数据压缩到5.8X 和 3.5X 因此,平均而言,通信成本可以大大降低。通过替换压缩层的输出,加上压缩过程本身的成本(与DNN运算符相比可以忽略不计),在JointDNN方法中,我们实现了额外的4.9X 和 4.6X能量和延迟的平均改进。

五、相关工作和比较
General Task Offloading Frameworks.There are existing prior arts focusing on offloading computation from the mobile to the cloud[15], [41], [42], [43], [44], [45], [46]. However, all these frameworks share a limiting feature that makes them impractical for computation partitioning of the DNN applications.
通用任务卸载框架。现有的现有技术专注于将计算从移动转移到云端[15],[41],[42],[43],[44],[45],[46]。然而,所有这些框架都有一个限制特性,这使得它们无法实现DNN应用程序的计算划分。
These frameworks are programmer annotations dependent as they make decisions about pre-specified functions, whereas JointDNN makes scheduling decisions based on the model topology and mobile network specifications in run-time. Offloading in function level, cannot lead to efficient partition decisions due to layers of a given type within one architecture can have significantly different computation and data characteristics. For instance, a specific convolution layer structure can be computed on mobile or cloud in different models in the optimal solution
这些框架依赖于程序员的注释,因为它们对预先指定的函数做出决策,而JointDNN在运行时根据模型拓扑和移动网络规范做出调度决策。功能层的卸载,不能导致有效的分区决策,因为一个体系结构中给定类型的层可能具有显著不同的计算和数据特征。例如,特定的卷积层结构可以在移动或云上以不同的模型计算最优解。
Neurosurgeon [14] is the only prior art exploring a similar computation offloading idea in DNNs between the mobile device and the cloud server at layer granularity. Neurosurgeon assumes that there is only one data transfer point and the execution schedule of the efficient solution starts with mobile and then switches to the cloud, which performs the whole rest of the computations. Our results show this is not true especially for online training, where the optimal schedule of execution often follows the mobilecloud-mobile pattern. Moreover, generative and autoencoder models follow a multi-transfer points pattern. Also, the execution schedule can start with the cloud especially in case of generative models where the input data size is large. Furthermore, inter-layer optimizations performed by DNN libraries are not considered in Neurosurgeon. Moreover, Neurosurgeon only schedules for optimal latency and energy, while JointDNN adapts to different scenarios including battery limitation, cloud server congestion, and QoS. Lastly,Neurosurgeon only targets simple CNN and ANN models, while JointDNN utilizes a graph-based approach to handle more complex DNN architectures like ResNet and RNNs.
神经外科医生[14]是唯一的现有技术,探索在移动设备和云服务器之间的dnn中以层粒度进行类似的计算卸载。神经外科医生假设只有一个数据传输点,高效解决方案的执行计划从移动开始,然后切换到云,由云执行其余所有的计算。我们的结果表明,这并不正确,特别是对于在线培训,其中的最佳执行计划通常遵循移动云-移动模式。此外,生成式和自动编码器模型遵循多转移点模式。此外,执行计划可以从云开始,特别是在输入数据量很大的生成模型中。此外,神经外科医生不考虑DNN库进行的层间优化。此外,Neurosurgeon只安排最优的延迟和能量,而JointDNN适应不同的场景,包括电池限制、云服务器拥塞和QoS。最后,Neurosurgeon只针对简单的CNN和ANN模型,而JointDNN采用基于图的方法处理更复杂的DNN架构,如 ResNet 和 RNNs 。
六、结论和未来工作
In this paper, we demonstrated that the status-quo approaches, cloud-only or mobile-only, are not optimal with regard to latency and energy. We reduced the problem of partitioning the computations in a DNN to shortest path problem in a graph. Adding constraints to the shortest path problem makes it NP-Complete, therefore, we also provided ILP formulations to cover different possible scenarios of limitations of mobile battery, cloud congestion, and QoS. The output data size in discriminative models is typically smaller than other layers in the network, therefore, last layers are expected to be computed on the cloud, while first layers are expected to be computed on the mobile. Reverse reasoning works for Generative models. Autoencoders have large input and output data sizes, which implies that the first and last layers are expected to be computed on the mobile. With these insights, the execution schedule of DNNs can possibly have various patterns depending on the model architecture in model cloud computing. JointDNN formulations are designed for feed-forward networks and its extension to recurrent neural networks will be studied as a future work.
在本文中,我们证明了现状的方法,仅云或仅移动,在延迟和能量方面不是最优的。我们将DNN中的计算划分问题简化为图中的最短路径问题。为最短路径问题添加约束成NP-Complete,因此,我们还提供了ILP公式,以覆盖移动电池、云拥塞和QoS的不同可能的限制场景。区别模型中的输出数据大小通常小于网络中的其他层,因此,最后一层预计在云上计算,而第一层预计在移动设备上计算。逆向推理适用于生成模型。自动编码器有大的输入和输出数据大小,这意味着第一层和最后一层预计是在移动设备上计算的。有了这些见解,dnn的执行计划可能会根据模型云计算中的模型架构有不同的模式。JointDNN公式是为前馈网络设计的,将其推广到递归神经网络将是未来的工作。