MMClassification(一)
1、介绍
一句话总结:基于pytorch的强大模块化组件式的分类框架。
相关资料:中文文档 GitHub 课程学习
深入学习直接使用官方文档学习效果最好,本文记录学习过程知识以便快速回顾和查找。其中包含个人的学习总结,仅做参考。
2、项目结构
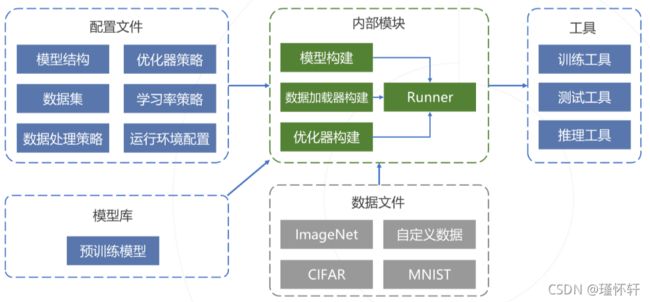
该项目结构图适用于openMMLab的其他框架。
主要工作是在配置文件模块:书写该配置文件中各个部分如图所示。
3、分类模型构成

上图展示图像分类的处理流程,下面逐一解释配置文件中参数含义:
3.1、模型结构配置
模型构建包括三部分:主干网络、颈部、分类头
model = dict( #定义模型
type = 'ImageClassifier', #定义模型类型
backbone = dict( #定义主干网络
type = 'ResNet', #主干网络采用ResNet模型
depth = 50, #深度为50,也就是ResNet50的模型
num_stages = 4, #使用全部4组卷积层
out_indices = (3, ), #输入最好一个卷积层的特征,3为下标
style = 'pytorch' #使用V1b结构变体
),
neck = dict(type='GlobalAveragePooling'), #颈部,使用全局平均池化
head = dict( #分类头
type='LinearClsHead', #使用单层线性分类头
num_classes=1000, #分类目标数1000
in_channels=2048, #线性层输入维度2048
loss=dict(type='CrossEntropyLoss', #是用交叉熵损失函数
loss_weight=1.0)
),
)3.2、数据集
该模块主要包含两个类:Dataset和DataLoader
data=dict( #描述数据集的字典
samples_per_gpu=32, #设置batchsize
workers_per_gpu=2, #设置数据加载进程数
train=dict( #定义训练数据子集
type='ImageNet', #设置数据集的类型为 ImageNet类型
data_prefix='data/imagenet/train', #指定数据文件的路径
pipeline=train_pipeline), #指定数据的处理流水线
val=dict(
), #验证集和测试集定义类似
test = dict(
),
)3.3、数据处理策略
该模块主要定义每一张图片读入内存后应该以什么样的步骤进行处理,可以想象成流水线。数据增强操作就是在此配置。
img_norm_cfg = dict( #此处是定义归一化的参数值,主要参考的是imagenet数据集的均值和标准差
mean=[123.675,116.28,103.53],std=[58.395,57.12,57.375],to_rgb=True
)
train_pipeline= [ #定义训练数据加载流水线
dict(type='LoadImageFromFile'), #从文件中读取图像
dict(type='RandomResizedCrop',size=224), #随机剪裁与缩放
dict(type='RandomFlip',flip_prob=0.5,direction='horizontal'),#概率为0.5的随机水平翻转
dict(type='Normalize',**img_norm_cfg), #像素值归一化
dict(type='ImageToTensor',keys=['img']), #将图像数据转为Tensor
dict(type='ToTensor',keys=['gt_label']), #将标签字段转为Tensor
dict(type='Collect',keys=['img','gt_label']) #整理数据字段输出给主干
]3.4、学习率、优化策略和运行环境配置
optimizer=dict( #定义优化器
type='SGD', #使用SGD优化器
lr=0.1, #初始学习率为0.1
momentum=0.9, #动量为0.9
weight_decay=0.0001 #权重衰减系数0.0001
)
lr_config=dict( #定义学习率策略
policy ='step', #使用步长下降策略
step=[30,60,90], #在指定周期阶段学习率下降十分之一
by_epoch=True, #阶段参考epoch数
warmup='Linear', #使用线性warmup策略
warmup_iters=5 #前5周期使用warmup策略
)
runner = dict( #运行环境配置(不全)
type='EpochBasedRunner', #基于epoch数的运行器
max_epochs=100 #最多训练100轮
)3.5、配置预训练模型
在官网文档中的模型库下载预训练模型,然后再配置文件中的load_from字段配置。