Multi-task Pre-training Language Model for Semantic Network Completion
多任务预训练语言模型用于语义网络补全
Da Li ∗ , Sen Yang †‡ , Kele Xu §¶ , Ming Yi ∗ , Yukai He ∗ , and Huaimin Wang §¶ ∗ Tencent, Beijing 100084, China † Beijing Institute of Microbiology and Epidemiology, Beijing, 100071, China ‡ State Key Laboratory of Pathogen and Biosecurity, Beijing, 100071, China § National University of Defense Technology, Changsha, 410073, China ¶ National Key Lab of Parallel and Distributed Processing, Changsha, 410073, China
摘要-语义网络,如知识图谱,可以利用图结构表示知识。
虽然知识图谱在自然语言处理中显示出很好的应用价值,但它存在不完全性。本文的重点是通过预测实体之间的链接来完成知识图谱,这是一项基本但关键的任务。语义匹配是一种潜在的链接预测解决方案,因为它可以处理看不见的实体,而基于平移距离的方法难以处理看不见的实体。然而,为了获得具有竞争力的表现,作为基于翻译距离的方法,基于语义匹配的方法需要用于训练目的的大规模数据集,而这些数据集在实际环境中通常不可用。因此,我们采用语言模型,引入了一种新的知识图谱架构LP-BERT,它包括两个主要阶段:多任务预训练和知识图谱微调。在预训练阶段,通过预测实体或关系,执行三项任务来驱动模型从三元组中学习关系信息。而在微调阶段,受对比学习的启发,我们设计了一批三式负抽样,在保持训练时间几乎不变的情况下,大大增加了负抽样的比例。此外,我们提出了一种新的数据增强方法,利用三元组的逆关系来提高模型的表现和鲁棒性。为了证明我们提出的框架的有效性,我们在三个广泛使用的知识图谱数据集WN18RR、FB15k-237和UMLS上进行了大量实验。实验结果证明了我们方法的优越性,我们的方法在WN18RR和FB15k-237数据集上取得了最新的结果。值得注意的是Hits@10在WN18RR数据集上,指标比之前的最新结果提高了5%,而在UMLS数据集上则达到了100%。
索引项-知识图谱、链接预测、语义匹配、翻译距离、多任务学习。
一、 引言
知识图谱(KG)的应用似乎在工业和学术领域都很明显【1】,包括问答、推荐系统、自然语言处理【2】等。这些明显的应用反过来又吸引了人们对构建大规模KG的极大兴趣。尽管已经做出了可持续的努力,但以前的许多知识图谱都存在不完整性[3],因为很难一次性存储所有这些事实。为了解决这个不完整性问题,人们探索了许多链接预测方法,目的是发现实体之间的未注关系,以完成知识图谱,这是一个具有挑战性但至关重要的问题,因为它有可能促进下游应用。
KG的链接预测也称为KG完成。
以前的链接预测方法可以分为两大类:基于平移距离的方法和基于语义匹配的方法。基于平移距离的模型通常将实体和关系嵌入到向量空间中,并利用评分函数来测量它们之间的距离。虽然实体关系的距离表示可能非常多样化,但很难预测训练阶段未出现的实体信息。作为一种很有前途的替代方法,基于语义匹配的方法利用实体和关系的语义信息,能够根据文本描述嵌入那些看不见的实体。此外,由于模型的高度复杂结构和缓慢的训练速度,出于训练的目的,负采样的比例要低得多,这导致实体库中负样本实体信息的学习不足,严重限制了模型的表现。
为了解决上述问题,特别是为了缓解翻译距离模型中看不见节点的预测表现不佳和文本匹配模型的训练不足的问题,本文提出了一种新的知识图谱预训练框架,即LP-BERT。具体而言,LP-BERT采用语义匹配表示法,它利用多任务预训练策略,包括用于上下文学习的掩码式语言模型任务(MLM),用于实体语义学习的掩码式实体模型任务(MEM),以及用于关系语义学习的mask关系模型任务(MRM)。通过预训练任务,LP-BERT可以学习结构化知识图谱的关系信息和非结构化语义知识。此外,为了解决低负抽样率导致的训练不足的问题,我们在对比学习的启发下,提出了一种在批次中进行负抽样的方法,在保证训练时间不变的情况下,显著增加了负抽样的比例。同时,我们提出了一种基于三元组逆关系的数据增强方法,以增加样本多样性,从而进一步提高表现。
为了证明所提解决方案的鲁棒性的有效性,我们综合评估了LP-BERT在WN18RR、FB15k-237和UMLS数据集上的表现。
在没有任何干扰的情况下,LP-BERT优于一组有竞争力的方法[5]、[6]、[7]、[8]、[9],并在WN18RR和UMLS数据集上取得了最先进的结果。这个Hits@10在WN18RR数据集上,指标比之前的最新结果提高了5%,而在UMLS数据集上则达到了100%。
其余文件的结构如下。第二节讨论了拟议方法与先前工作之间的关系。在第三节中,我们提供了我们的方法的细节,而第四节描述了全面的实验结果。第五部分是本文的结论。
二、相关工作
A、 知识图谱嵌入
KG嵌入是一个研究得很好的主题,综合调查可在【4】、【10】中找到。传统的方法只能利用三元组中观察到的结构信息来完成知识图谱。例如,TransE【11】和TransH【12】是两个具有代表性的作品,它们通过计算实体之间的距离来迭代更新实体的向量表示。卷积神经网络(CNN)在知识图谱嵌入方面也取得了令人满意的表现【13】、【14】、【15】。此外,还引入了不同类型的外部信息,如实体类型、逻辑规则和文本描述,以增强结果【4】。对于文本描述,[16]首先通过平均名称中包含的单词嵌入来表示实体,其中单词嵌入是从外部语料库学习的。
[4] 通过对齐维基百科定位点和实体名称,将实体和单词嵌入到相同的向量空间中。CNN还被用来对实体描述中的单词序列进行编码【17】。[18] 提出了语义空间投影(SSP),通过描述事实三元组和文本描述之间的强相关性,将主题和知识图谱嵌入到一起。
尽管这些模型的表现令人满意,但他们只学会了实体和关系的相同文本表示,而实体/关系描述中的单词在不同的三元组中可能具有不同的含义或重要性权重。为了解决这些问题,[19]提出了一种文本增强的KG嵌入模型TEKE,该模型可以将不同的嵌入分配给不同的三元组关系,并使用实体标记文本语料库中实体和单词的共现。[20] 使用长-短期记忆(LSTM)编码器和注意力机制构建给定不同关系的上下文文本表示。[21]提出了一种精确的文本增强KG嵌入方法,该方法利用了三重特定关系提及和关系提及与实体描述之间的相互注意机制。
虽然这些方法可以处理不同三元组的实体和关系的语义变化,但由于它们只使用实体描述、关系提及和单词与实体的共现,无法充分利用大规模自由文本数据中的句法和语义信息。
KG-BERT【22】、MLM【23】、StAR【9】等作品引入了一种预训练范式。如上所述,由于模型的高度复杂性和训练速度慢,负抽样的比例远远低于之前的工作,这导致实体库中的负样本实体信息学习不足。
与上述方法相比,我们的方法引入了对比学习策略。在训练过程中,采用了一种新的负抽样方法,使得负抽样的比例可以成倍增加,从而缓解了学习不足的问题。
此外,我们还优化了预训练策略,使模型不仅可以学习上下文知识,还可以学习左实体、关系和右实体的元素信息,这大大提高了模型的表现。
B、 链路预测
链接预测是KG嵌入中一个活跃的研究领域,近年来受到了广泛的关注。KBGAT[24]是一种新的基于注意力的特征嵌入,旨在捕获任何给定实体邻域中的实体和关系特征。AutoSF[25]致力于通过AutoML技术为不同的KG自动设计SFs。
CompGCN【26】旨在构建一种新的图卷积框架,将节点和关系共同嵌入到关系图中,该框架利用知识图谱嵌入技术中的各种实体-关系组合操作,并随关系数的增加而扩展。Meta-KGR【27】是一种基于元的多跳推理方法,采用元学习从高频关系中学习有效的元参数,可以快速适应少镜头关系。ComplEx-N3-RP【28】通过简单地将关系预测纳入常用的1vsAll目标,为多关系图表示学习设计了一个新的自我监督训练目标,该目标不仅包含用于预测给定三元组的主体和对象的术语,还包含用于预测关系类型的术语。AttH【29】是一类同时捕获层次和逻辑模式的双曲KG嵌入模型,它将双曲反射和旋转与对模型复杂关系模式的注意力相结合。
RotatE【30】将每个关系定义为复杂向量空间中从源实体到目标实体的旋转,能够模型并推断各种关系模式,包括对称/反对称、反转和合成。
HAKE[8]将TransE和RotatE组合为层次结构不同层次的模型实体,同时区分同一层次的实体。GAAT【31】集成了衰减的注意力机制,并为关系路径分配了不同的权重,以从邻域获取信息。StAR【9】将一个三元组分成两个不对称部分,就像在基于翻译距离的图嵌入方法中一样,并通过暹罗风格的文本编码器将这两个部分编码为上下文表示。然而,文本模型的预训练阶段只能学习文本的上下文知识,而忽略了图形结构。
C、 预训练语言模型
预训练语言模型方法可分为两类:基于特征的方法和基于微调的方法【32】、【33】。传统的单词嵌入方法,如Word2Vec[34]和Glove[35],旨在使用基于特征的方法来学习上下文语义信息,并以特征向量的形式表达单词。ELMo[36]将传统的单词嵌入扩展到上下文感知的单词嵌入,从而可以正确处理多义现象。
与基于特征的方法不同,BERT[37]中使用的基于传销的预训练方法开辟了基于transformer结构的语言模型的预训练范式。RoBERTa(RoBERTa)[38]仔细衡量了关键超参数和训练数据大小的影响,并进一步增强了效果。SpanBERT【39】通过掩码连续随机跨度而非随机tokens扩展了BERT,并训练跨度边界表示,以预测掩码式跨度的整个内容,而不依赖其中的单个token表示。麦克伯特[40]在几个方面对RoBERTa进行了改进,尤其是采用传销作为更正(Mac)的掩码策略。
最近,也在KG的背景下探索了预训练的语言模型。[41]学习知识图谱中随机游走生成的实体关系链(句子)上的上下文嵌入,并将其初始化为知识图谱嵌入模型,如TransE[11]。
ERNIE(ERNIE)[42]利用知识图谱,可以利用外部知识增强语言表示,以训练增强的语言表示模型。COMET[43]使用GPT在知识库中生成一个给定的关系类型的首短语和尾短语标记,这并不完全适合比较两个实体与已知关系的模式。KG-BERT[22]使用MLM方法对三重数据进行预训练,以学习知识图谱场景的语料库信息。
与这些研究不同的是,我们使用了基于MLM、Mask实体模型(MEM)和Mask关系模型(MRM)的多任务预训练策略,这样模型不仅可以学习上下文语料库信息,还可以在语义层面学习三元组的关联信息。
三、 方法论
A、 任务制定
知识图谱G可以表示为一组三元组
![]()
,其中N是三元组的数目ing,E hand E t表示头部实体和尾部实体,并且从E h toe t存在一条具有属性的有向边(即。
关系)R。所有实体和关系通常都是包含几个tokens的短文本。每个实体也有其描述,即详细描述实体的文本。我们分别使用D手D t来表示E手E t的描述。
链接预测的任务是预测两个实体之间是否存在特定的关系,即给定E手E t(及其描述D手D t),预测{E h,R,E t}是否成立。
B、 总体框架
图1显示了我们提出的LP-BERT的总体框架。它显示了两个链接预测过程:多任务预训练和知识微调。在预训练阶段,除了流行的Mask语言模型任务(MLM)[37],我们还提出了两个新的预训练任务:Mask实体模型任务(MEM)和Mask关系模型任务(MRM)。同时利用这三个预训练任务,LP-BERT可以学习语料库的上下文信息和头-尾三元组的语义信息。在微调阶段,受对比学习的启发,我们设计了一批三风格的负抽样,在保持训练时间几乎不变的情况下,显著增加了负抽样的比例。
此外,我们还提出了一种基于三元组逆关系的数据增强方法,以提高样本的多样性。
图1:。总体框架概述。LP-BERT包括两个阶段:预训练和微调。在预训练阶段,除了Mask语言模型任务(MLM)外,我们还提出了两个新的预训练任务,即Mask实体模型任务(MEM)和Mask关系模型任务(MRM)。三项任务采用多任务方式并行训练的。在微调阶段,我们在一批数据中设计了三种类型的负采样,可以显著增加负采样的比例,同时保持训练时间几乎不变。
C、 多任务预训练
我们建议用三个任务对LP-BERT模型进行预训练。虽然它们需要不同的掩码策略,但它们也共享相同的输入,将实体、关系以及实体描述连接成一个三元组作为一个整体序列:这里的
![]()
,符号“‖”表示句子连接,“[CLS]”和“[SEP]”是BERT[37]中的两个保留tokens,表示序列的开始和分离。下面几节介绍了三个预训练任务的更多细节。
1) Mask实体建模(MEM):在Mask实体建模任务中,输入的实体序列是掩码式的,模型需要基于另一个实体和关系恢复掩码式实体。相应的实体描述也被掩码式,以避免信息泄漏。由于每个三元组包含两个实体,MEM可以mask头部实体或尾部实体,但不能同时mask两者。
以尾部实体上的MEM为例,输入如下:
![]()
在这里,我们使用“[MASK]”来表示那些被掩码式的tokens。
由于尾部实体是掩码式的,其描述将替换为保留的token“[填充]”,以避免模型仅从其描述推断实体。请注意,“[MASK]”和“[PAD]”都可以包含多个tokens,因为它们与尾部实体和尾部描述共享相同的长度。预测的目标是恢复尾部实体,而不包括其描述。类似地,对于头部实体的预测,LP-BERT只是屏蔽头部实体并预测相应的tokens。在预训练过程中,头部和尾部实体以相同的概率随机屏蔽。
为了预测实体中的tokens,在LP-BERT编码器的顶部构建了一个结合多层感知器和批次范数层的分类器,以输出预测结果的概率矩阵:
![]()
,其中“◦ ” 表示函数组成。每个token都有一个单词词汇量的概率向量,但预测结果不涉及损失计算,但掩码式实体的tokens除外。
2) Mask关系建模(MRM):Mask关系建模任务(MRM)采用了与MEM类似的样本构建策略(如算法1所示)。
MRM没有掩码三元组中两个实体中的一个,而是用“[MASK]”替换关系中的tokens,同时保留头部和尾部实体和描述。然后,MRM驱动模型预测两个实体之间的对应关系。掩码式样本可以表示如下:
![]()
3)Mask语言建模(MLM):为了与MEM和MRM共存,与BERT对序列中的所有tokens进行[37]随机掩码预测不同,拟议的MLM方法仅对样本的特定文本范围进行局部随机掩码。随机掩码策略如下:•对于MEM中的头部实体预测任务,仅在E t和D t的token序列中使用随机mask;•对于MEM中的尾部实体预测任务,随机mask仅在E-hand D D h的token序列中对于MRM任务,仅在E h、D h、E t和D t的token序列中使用随机mask。
通过这种方式,传销驱动模型学习语料库的上下文信息。更重要的是,尽管MRM和MEM是独家的,但它们都与传销兼容。因此,在小批量的预训练过程中,传销与MEM或MRM一起进行。同时,对MEM和MRM任务的文本特征进行掩码相当于进行类似于drop的正则化,可以提高MEM和MRM的表现,如实验所示。
算法1显示了关于预训练LP-BERT的构造样本的更多细节。具体而言,第20-25行和第26-31行显示了使用传销的MEM程序(分别针对头部实体和尾部实体),第32-36行显示了使用传销的MRM程序。算法1的第1-15行详细显示了掩码tokens的策略,即MLM。
4) 预训练损失设计:由于在MEM和MRM任务中构建样本的策略是互斥的,对于由同一输入模型训练的的三个样本,头部实体和尾部实体的预测不能同时预测。为了确保模型的泛化能力,我们使用Mask项模型(MIM)任务作为MEM和MRM任务的统一表达式,并定义损失函数如下:
![]()
,其中L是最终损失,y′和y分别是预测目标和金标签,α是均匀分布在区间[0,1]中的随机数。L MIM的详细信息如下所示:
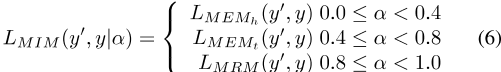
。
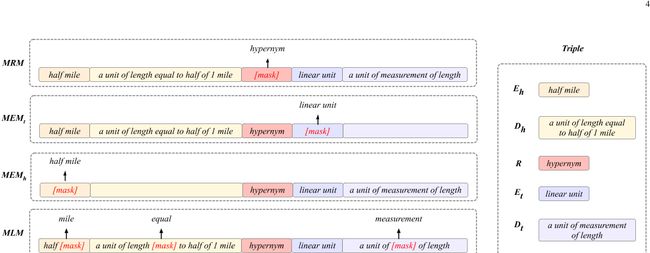
图2:。演示预训练任务的实例。实体、关系和实体描述被连接为一个完整的序列。对于传销,随机tokens被掩码式;对于MEM,头部实体或尾部都是掩码式的,所以我们用下标“h”或“t”来限定MEM;而对于MRM,这种关系是掩码式的。值得注意的是,这些预训练任务可以在预训练过程中使用多任务学习范式进行组合。

D、 知识图谱微调
1) 知识表示:微调阶段的样本构建方法不同于预训练阶段的样本构建方法。受星号[9]的启发,对于每一个三元组,我们将手部R文本串联起来。然后,预训练的LP-BERT模型使用暹罗语的结构[44]分别编码E h‖R和E t。模型的微调目标是使正样本的两种表示更接近,负样本的两种表示更进一步。这里,正样本表示(eh,R,et)存在于知识库中,而负样本则不存在。
由于三元组(E h,R,E t)被拆分为E h‖R和E t,知识图谱只能提供正样本。
因此,为了在微调过程中进行二元分类,我们提出了一种简单而有效的方法来生成负样本。如图3所示,对于尺寸为n的小批次,通过交错![]() 和
和![]() ,我们将
,我们将![]() 作为负样本。因此,对于小批量,LP-BERT对于n 2样本距离仅向前两次,这大大增加了负采样的比例,并减少了训练时间。算法2显示了构造精细调谐的负样本的详细过程。
作为负样本。因此,对于小批量,LP-BERT对于n 2样本距离仅向前两次,这大大增加了负采样的比例,并减少了训练时间。算法2显示了构造精细调谐的负样本的详细过程。
2) 三重扩充:上述基于对的知识图谱表示方法有局限性,因为它不能在头部实体预测任务中直接表示(E h,RE t)对。具体而言,对于负样本的构建,我们只能对E t进行负采样,而不能对E h进行负采样,这限制了负样本的多样性,尤其是当数据集中存在mo关系时。因此,我们提出了一种双关系数据增强方法。
对于每个关系R,我们定义了相应的反向关系R rev。对于(?,R,E R)形式的头部实体预测样本,我们将其改写为(E R,R rev,?)形式增强数据。这样,我们可以使用![]() 的向量表示来代替
的向量表示来代替![]() ,从而提高采样的多样性和模型的鲁棒性。
,从而提高采样的多样性和模型的鲁棒性。
此外,我们使用fp16和fp32的混合精度策略来减少梯度计算的GPU内存使用量,以改进n的大小并提高负采样率。
3) 微调损耗设计:我们设计了两种距离计算方法来联合计算损耗函数
![]()
,其中V E h R和V E t分别是E h R和E t的编码向量。
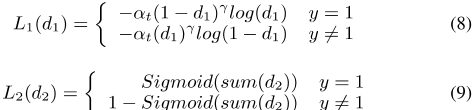
。
其中,
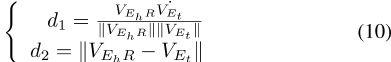
,其中α用于调整正和负样本的权重,γ用于调整难以区分的样本的权重。使用两种不同的维度距离计算方法计算多任务学习向量对之间的距离关系。
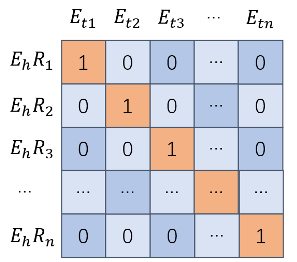
图3:。批量大小为n的标签矩阵。对于第i个(1)中的E h R i和E ti≤ 我≤ n)批次元素,只能生成1个正样本,n− 1负样品。因此,该批次有n 2个样本,包括n个正样本和n个(n− 1) 负样本。

四、 实验
在这一部分中,我们首先详细介绍了实验装置。
然后,我们在多个广泛使用的数据集(包括WN18RR[13]FB15k-237[45]和UMLS[13]基准数据集)上证明了所提出的模型的有效性。其次,进行了消融研究,我们将其与标准模型区分开来,并保持其他结构不变,目的是证明每项改进的贡献。最后,我们对不可见实体的预测表现进行了广泛的分析,并提供了一个案例研究来证明所提出的LP-BERT的有效性。
A、 实验设置和数据集
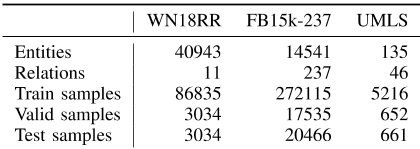
我们在WN18RR【13】、FB15k-237【45】和UMLS【13】数据集上评估了提出的模型。对于WN18RR,数据集采用WordNet,用于链接预测任务【46】,它由英语短语和相应的语义关系组成。FB15k-237【45】是Freebase【47】的一个子集,它由真实世界的命名实体及其关系组成。WN18RR和FB15k-237都是从WN18和FB15k[11]中分别更新而来的,通过消除反向关系和数据泄漏,这是最流行的基准之一。UMLS【13】是一个包含医学语义实体及其关系的小KG。数据集的汇总统计数据如表一所示。
为了便于训练,我们使用PyTorch 1框架在带有64GB RAM的Intel Xeon处理器和Nvidia P40 GPU的工作站上实现LP-BERT。AdamW优化器用于5%的预热步骤。对于LP-BERT中的超参数,我们将epochs设置为50,批大小设置为32,学习率=10− 4 / 5 × 10 − 5分别用于线性和注意力部分初始化。提前停止的epoch数设置为3。在知识图谱微调阶段,我们根据开发数据集上的最佳点击数@10,将WN18RR上的批大小设置为64,FB15k-237上的批大小设置为120,UMLS上的批大小设置为128。学习速率设置为10− 3 / 5 × 10 − 5分别用于LB-BERT初始化的线性部分和注意力部分。WN18RR和FB15k-237上的训练epochs数为7,而UMLS数据集的训练次数为30,α=0。WN18RR和UMLS上为8,α=0。FB15k-237上为5,式8中γ=2。
在推理阶段,知识图谱中的所有其他实体都被视为错误的候选实体,这可能会损坏其头部或尾部实体。训练的的模型旨在使用“过滤”设置来纠正腐败者的三重排名。评估指标有两个方面:(1)Hits@N表示正确候选项中前N个测试实例的比率;(2) 平均排名(MR)和平均互惠排名(MRR)反映了绝对排名。
表一所用数据集的汇总统计数据,包括WN18RR、FB15 K-237和UMLS。
B、 结果
我们使用所提出的方法和竞争方法(包括基于相对距离的方法和基于语义匹配的方法)对链接预测任务进行基准测试。对于平移距离模型,我们在实验中测试了18种广泛使用的解决方案,包括TransE【11】、DistMult【48】、ComplEx【49】、R-GCN【15】、Conv【13】、KBAT【24】、QuatE【50】、RotatE【30】、TuckER【51】、AttH【29】、DensE【53】、Rot Pro【5】、Quatte【6】、Lin-eaRE【7】、CapsE【54】、RESCAL-DURA【55】和HAKE【8】。正如所料,由于训练的困难,以前只有少数尝试使用基于语义匹配的方法。这里,KG-BERT[22]和StAR[9]用于定量比较。
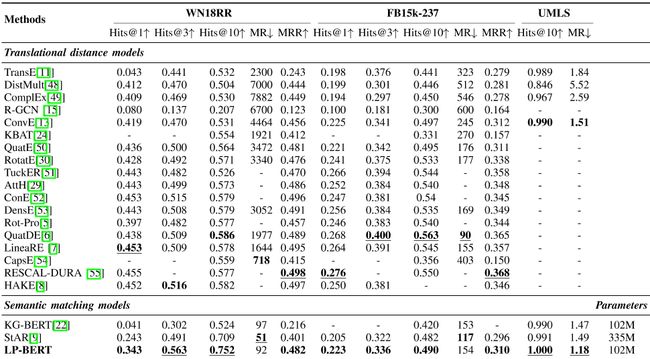
详细结果见表二。从表中可以看出,LB-BERT能够在所有三个广泛使用的数据集(包括WN18RR、FB15k-237和UMLS数据集)上实现最先进或具有竞争力的表现。
在以下方面的改进尤其显著Hits@10和Hits@3由于多任务预训练文本编码方法具有优异的泛化表现,这将在下一节中进一步分析。此外,LP-BERT在以下方面大大优于所有其他方法Hits@3, Hits@10在WN18RR和Hits@10在UMLS上。虽然它在FB15k-237数据集和Hits@1与平移距离模型相比,WN18RR数据集的MRR通过引入结构化知识,仍然显著优于其他语义匹配模型,如KG-BERT和StAR。特别是,LB-BERT在所有三个数据集上的性能都优于StAR[9],StAR是以前最先进的模型,只有三分之一的参数。
对于WN18RR数据集Hits@1从0.243增加到0.343,Hits@3从0.491增加到0.563。
实验结果表明,语义匹配模型在topK召回评估方法中表现良好,但在topK召回评估方法中,语义匹配模型的性能较差Hits@1结果明显低于平移距离模型。这是因为语义匹配模型的特征是基于文本的,这导致文本中相似实体的向量表示比较接近,难以区分。虽然平移距离模型在Hits@1,他们无法理解文本语义。对于训练集中没有看到的新实体,翻译距离模型的预测结果是随机的,而语义匹配模型是可靠的,这就是为什么Hits@3和Hits@10LP-BERT可以远远超过平移距离模型,实现最先进的表现。
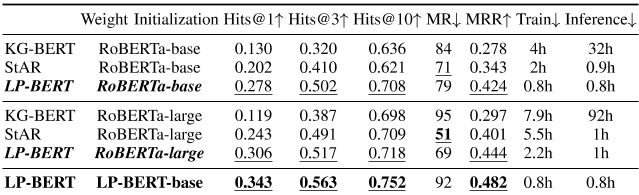
与KG-BERT和StAR相似,我们的模型依赖BERT,我们在WN18RR上详细比较了LP-BERT和KG-BERT和StAR,包括不同的初始化方式。
如表III所示,LP-BERT在表现方面始终优于大多数指标。基于RoBERTa base的LB-BERT模型的评估效果已经超过了基于RoBERTa large的KG-BERT和StAR的评估效果。就经验效率而言,由于模型参数数量较少,以及在训练过程中基于批次的负抽样策略,我们的模型在训练和推理阶段都比KG-BERT和StAR更快。
表II WN18RR、FB15 K-237和UMLS数据集的实验结果。粗体数字表示每种类型的最佳效果,而下划线数字则表示最先进的表演。我们可以看到,LP-BERT在WN18RR和UMLS数据集的多个评估结果中达到了最先进的性能,并且在FB15 K-237数据集上优于其他语义匹配模型。↑ 意味着更高的值提供更好的性能,而↓ 意味着值越低,性能越好。
C、 消融研究
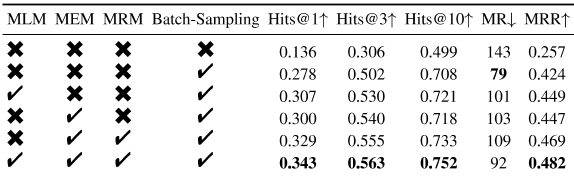
在这一部分中,我们将每个模块与标准模型分开,并保持其他结构不变,目的是证明每个改进的贡献。消融实验是在WN18RR数据集上进行的,我们发现这三个数据集的表现相似。表四显示了结果。在添加基于批次的三重式负采样策略并结合焦点损失后,适当的负采样率显著改善了模型的评估效果,如第二行所示。原始的预训练权重(BERT或RoBERTa预训练权重)不熟悉链接预测任务的语料库信息。在加入基于传销的预训策略后,提高了评估效果。然而,基于传销策略的预训练方法并没有充分挖掘三胞胎之间的关系信息,而将传销、记忆和MRM相结合的多任务预训练策略使得模型的评估结果最优。
D、 未见过的实体
为了验证LP-BERT对不可见实体的预测表现,我们重新拆分了数据集。具体来说,我们随机选择10%的实体三元组分别作为验证集和测试集,以确保训练集、验证集和测试集在任何实体上都不重叠。然后,我们重新训练和评估LP-BERT以及其他基线,其结果如表V所示。
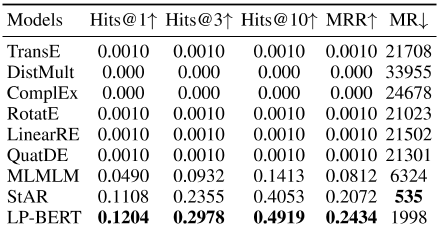
从表中可以看出,所有模型在五个指标中都经历了显著的表现下降。特别是,基于距离的方法在处理未见过的实体方面较差。如上所述,此类方法仅对实体之间的关系和距离进行编码,而不包括语义信息,因此无法对训练集中未看到的实体进行编码。相比之下,基于预训练的模式,包括 MLMLM, StAR和我们的LP-BERT,已经显示出他们应对未见过实体的能力。
此外,我们的LP-BERT在几乎所有指标上都超过了MLM和StAR,证明了它在处理未见过的实体方面的优势。特别是,LP-BERT以6-9分的成绩超过了之前最先进的StARHits@3和Hits@10.然而,LP-BERT在平均秩度量上的得分不如其他度量,表明LP-BERT在那些失败实体上的表现更差。
表III与KG-BERT和star在WN18RR数据集上的定量比较。“T RAIN”表示每个训练时段的时间,“I INFERENCE”表示测试集上的总推理时间。使用T ESLA P40收集数值,无混合精度。
表IV WN18RR数据集上LP-BERT的BLATION研究。
表五LP-BERT在无形实体上的表现。
E、 案例研究
为了进一步证明LP-BERT的表现,对WN18RR数据集进行了额外的案例研究,结果的可视化显示在表VI中。在表中,每一行表示从测试集中随机选择的真实样本。第一列是三元组,格式为(左实体、关系、)← 右侧实体。预测模型使用左实体和关系来预测右实体。从第二列到第四列,我们展示了使用不同预训练方法获得的预测概率最高的前5名实体。实体使用预测概率排序,正确答案使用粗体突出显示。第2列给出了我们提出的LP-BERT的预训练策略的预测结果。
第3列提供了仅使用基于传销的预训练获得的结果,而最后一列显示了未经预训练获得的结果。
对于不同的方法,表中给出了正确预测结果的顺序(每个元素中的数字)。
对于LP-BERT,正确预测结果的阶数为[1,2,1,2,2],而基于传销的预训练的阶数为[3,3,5,3,3],没有预训练的阶数为[6,21,12,6,4]。结果表明,与基于传销的无需预训练的模型相比,LP-BERT可以提供优异的表现。需要注意的是,所有呈现的结果都是典型的,并不是精心挑选的,目的是避免误报所提议方法的实际表现。
五、 结论和未来工作
本文主要研究自然语言处理领域中的一项基本而又关键的任务,即语义网络的构建。更具体地说,我们设法预测这种联系。
知识图谱语义网络中的实体之间。我们采用语言模型并引入LP-BERT,它包含多任务预训练和知识图谱微调阶段。在预训练阶段,我们提出了两个新的预训练任务MEM和MRM,以鼓励模型学习上下文知识和知识图谱的结构信息。在微调阶段,我们设计了一个批量三重式负采样,在保持训练时间几乎不变的情况下,大大增加了负采样的比例。
在三个数据集上的大量实验结果证明了我们提出的LP-BERT的效率和有效性。在未来的工作中,我们将探索更多不同的预训练任务,并增加模型参数大小,以使LP-BERT能够存储更大的图知识。
表六使用WN18RR数据集的案例研究。第一列是三元组,格式为(左实体、关系、)← 右侧实体。从第二列到第四列,我们展示了预测概率最高的前5名实体,这些实体来自不同的预训练方法(包括基于LP-BERT的拟议预训练、基于传销的预训练和无预训练)。使用预测概率对实体进行排序。正确答案用粗体突出显示。每个元素中的数字是正确预测结果的顺序

六、 致谢
这项工作得到了国家重点研究开发项目(2021ZD0112901)的部分支持。
参考文献
[1] S. M. Kazemi and D. Poole, “Simple embedding for link prediction in knowledge graphs,” Advances in neural information processing systems , vol. 31, 2018.
[2] M. Sundermeyer, H. Ney, and R. Schlüter, “From feedforward to recurrent lstm neural networks for language modeling,” IEEE/ACM Transactions on Audio, Speech, and Language Processing , vol. 23, no. 3, pp. 517–529, 2015.
[3] A. Rossi, D. Barbosa, D. Firmani, A. Matinata, and P. Merialdo, “Knowl- edge graph embedding for link prediction: A comparative analysis,” ACM Transactions on Knowledge Discovery from Data , vol. 15, no. 2, pp. 1–49, 2021.
[4] Q. Wang, Z. Mao, B. Wang, and L. Guo, “Knowledge graph embed- ding: A survey of approaches and applications,” IEEE Transactions on Knowledge and Data Engineering , 2017.
[5] T. Song, J. Luo, and L. Huang, “Rot-pro: Modeling transitivity by projection in knowledge graph embedding,” International Conference on Neural Information Processing Systems , vol. 34, 2021.
[6] H. Gao, K. Yang, Y. Yang, R. Y. Zakari, J. W. Owusu, and K. Qin, “Quatde: Dynamic quaternion embedding for knowledge graph comple- tion,” arXiv preprint arXiv:2105.09002 , 2021.
[7] Y. Peng and J. Zhang, “Lineare: Simple but powerful knowledge graph embedding for link prediction,” in ICDM . IEEE, 2020, pp. 422–431. [8] Z. Zhang, J. Cai, Y. Zhang, and J. Wang, “Learning hierarchy-aware knowledge graph embeddings for link prediction,” in Proceedings of the AAAI Conference on Artificial Intelligence , 2020.
[9] B. Wang, T. Shen, G. Long, T. Zhou, Y. Wang, and Y. Chang, “Structure- augmented text representation learning for efficient knowledge graph completion,” in International World Wide Web Conference , 2021, pp. 1737–1748.
[10] P. Goyal and E. Ferrara, “Graph embedding techniques, applications, and performance: A survey,” Knowledge-Based Systems , vol. 151, pp. 78–94, 2018.
[11] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” international Conference on Neural Information Processing Systems , 2013.
[12] Z. Wang, J. Zhang, J. Feng, and Z. Chen, “Knowledge graph embedding by translating on hyperplanes,” in Proceedings of the AAAI Conference on Artificial Intelligence , 2014.
[13] T. Dettmers, P. Minervini, P. Stenetorp, and S. Riedel, “Convolutional 2d knowledge graph embeddings,” in Proceedings of the AAAI Conference on Artificial Intelligence , 2018.
[14] D. Q. Nguyen, D. Q. Nguyen, T. D. Nguyen, and D. Phung, “A con- volutional neural network-based model for knowledge base completion and its application to search personalization,” Semantic Web , vol. 10, no. 5, pp. 947–960, 2019.
[15] M. Schlichtkrull, T. N. Kipf, P. Bloem, R. Van Den Berg, I. Titov, and M. Welling, “Modeling relational data with graph convolutional networks,” in ESWC . Springer, 2018, pp. 593–607.
[16] R. Socher, D. Chen, C. D. Manning, and A. Ng, “Reasoning with neural tensor networks for knowledge base completion,” Advances in neural information processing systems , vol. 26, 2013.
[17] F. Zhang, N. J. Yuan, D. Lian, X. Xie, and W.-Y. Ma, “Collaborative knowledge base embedding for recommender systems,” in Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining , 2016, pp. 353–362.
[18] H. Xiao, M. Huang, L. Meng, and X. Zhu, “Ssp: semantic space projection for knowledge graph embedding with text descriptions,” in Thirty-First AAAI conference on artificial intelligence , 2017.
[19] Z. Wang, J. Li, Z. Liu, and J. Tang, “Text-enhanced representation learning for knowledge graph,” in Proceedings of International Joint Conference on Artificial Intelligent (IJCAI) , 2016, pp. 4–17.
[20] J. Xu, K. Chen, X. Qiu, and X. Huang, “Knowledge graph representation with jointly structural and textual encoding,” arXiv preprint arXiv:1611.08661 , 2016.
[21] B. An, B. Chen, X. Han, and L. Sun, “Accurate text-enhanced knowledge graph representation learning,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , 2018, pp. 745–755.
[22] L. Yao, C. Mao, and Y. Luo, “Kg-bert: Bert for knowledge graph completion,” arXiv:1909.03193 , 2019.
[23] L. Clouatre, P. Trempe, A. Zouaq, and S. Chandar, “Mlmlm: Link
prediction with mean likelihood masked language model,” arXiv preprint arXiv:2009.07058 , 2020.
[24] D. Nathani, J. Chauhan, C. Sharma, and M. Kaul, “Learning attention- based embeddings for relation prediction in knowledge graphs,” arXiv preprint arXiv:1906.01195 , 2019.
[25] Y. Zhang, Q. Yao, W. Dai, and L. Chen, “Autosf: Searching scoring functions for knowledge graph embedding,” in International Conference on Data Engineering . IEEE, 2020.
[26] S. Vashishth, S. Sanyal, V. Nitin, and P. Talukdar, “Composition- based multi-relational graph convolutional networks,” in International Conference on Learning Representations , 2019.
[27] X. Lv, Y. Gu, X. Han, L. Hou, J. Li, and Z. Liu, “Adapting meta knowledge graph information for multi-hop reasoning over few-shot relations,” in Conference on Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing , 2019, pp. 3376–3381.
[28] Y. Chen, P. Minervini, S. Riedel, and P. Stenetorp, “Relation prediction as an auxiliary training objective for improving multi-relational graph representations,” in AKBC , 2021.
[29] I. Chami, A. Wolf, D.-C. Juan, F. Sala, S. Ravi, and C. Ré, “Low- dimensional hyperbolic knowledge graph embeddings,” in Annual meeting of the Association for Computational Linguistics , 2020.
[30] Z. Sun, Z.-H. Deng, J.-Y. Nie, and J. Tang, “Rotate: Knowledge graph embedding by relational rotation in complex space,” in International Conference on Learning Representations , 2018.
[31] R. Wang, B. Li, S. Hu, W. Du, and M. Zhang, “Knowledge graph embedding via graph attenuated attention networks,” IEEE Access , vol. 8, pp. 5212–5224, 2019.
[32] Y. Cui, W. Che, T. Liu, B. Qin, and Z. Yang, “Pre-training with whole word masking for chinese bert,” IEEE/ACM Transactions on Audio, Speech, and Language Processing , vol. 29, pp. 3504–3514, 2021.
[33] J. Qiang, Y. Li, Y. Zhu, Y. Yuan, Y. Shi, and X. Wu, “Lsbert: Lexical simplification based on bert,” IEEE/ACM Transactions on Audio, Speech, and Language Processing , vol. 29, pp. 3064–3076, 2021.
[34] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their composi- tionality,” Advances in neural information processing systems , vol. 26, 2013.
[35] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) , 2014, pp. 1532–1543.
[36] J. Sarzynska-Wawer, A. Wawer, A. Pawlak, J. Szymanowska, I. Stefa- niak, M. Jarkiewicz, and L. Okruszek, “Detecting formal thought disorder by deep contextualized word representations,” Psychiatry Research , vol. 304, p. 114135, 2021.
[37] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805 , 2018.
[38] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” International Conference on Learning representations , 2020.
[39] M. Joshi, D. Chen, Y. Liu, D. S. Weld, L. Zettlemoyer, and O. Levy, “Spanbert: Improving pre-training by representing and predicting spans,” Transactions of the Association for Computational Linguistics , vol. 8, pp. 64–77, 2020.
[40] Y. Cui, W. Che, T. Liu, B. Qin, S. Wang, and G. Hu, “Revisiting pre- trained models for chinese natural language processing,” in Conference on Empirical Methods in Natural Language Processing , 2020.
[41] H. Wang, V. Kulkarni, and W. Y. Wang, “Dolores: deep contextualized knowledge graph embeddings,” arXiv preprint arXiv:1811.00147 , 2018.
[42] Z. Zhang, X. Han, Z. Liu, X. Jiang, M. Sun, and Q. Liu, “Ernie: enhanced language representation with informative entities,” arXiv preprint arXiv:1905.07129 , 2019.
[43] A. Bosselut, H. Rashkin, M. Sap, C. Malaviya, A. Celikyilmaz, and Y. Choi, “Comet: Commonsense transformers for automatic knowledge graph construction,” arXiv preprint arXiv:1906.05317 , 2019.
[44] J. Mueller and A. Thyagarajan, “Siamese recurrent architectures for learning sentence similarity,” in Proceedings of the AAAI Conference on Artificial Intelligence , 2016.
[45] K. Toutanova, D. Chen, P. Pantel, H. Poon, P. Choudhury, and M. Ga- mon, “Representing text for joint embedding of text and knowledge bases,” in Conference on Empirical Methods in Natural Language Processing , 2015, pp. 1499–1509.
[46] G. A. Miller, WordNet: An electronic lexical database . MIT press, 1998.
[47] K. Bollacker, C. Evans, P. Paritosh, T. Sturge, and J. Taylor, “Freebase: a collaboratively created graph database for structuring human knowl- edge,” in International Conference on Management of Data , 2008, pp. 1247–1250.
[48] B. Yang, W.-t. Yih, X. He, J. Gao, and L. Deng, “Embedding entities and relations for learning and inference in knowledge bases,” arXiv preprint arXiv:1412.6575 , 2014.
[49] T. Trouillon, J. Welbl, S. Riedel, Ã. Gaussier, and G. Bouchard, “Com- plex embeddings for simple link prediction.(2016),” in International Conference on Machine Learning , 2016.
[50] S. Zhang, Y. Tay, L. Yao, and Q. Liu, “Quaternion knowledge graph em- beddings,” International Conference on Neural Information Processing Systems , 2019.
[51] I. Balažević, C. Allen, and T. Hospedales, “Tucker: Tensor factorization for knowledge graph completion,” in Conference on Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing , 2019, pp. 5185–5194.
[52] Y. Bai, Z. Ying, H. Ren, and J. Leskovec, “Modeling heterogeneous hierarchies with relation-specific hyperbolic cones,” in International Conference on Neural Information Processing Systems , 2021.
[53] H. Lu and H. Hu, “Dense: An enhanced non-abelian group representation for knowledge graph embedding,” arXiv preprint arXiv:2008.04548 , 2020.
[54] T. Vu, T. D. Nguyen, D. Q. Nguyen, D. Phung et al. , “A capsule network- based embedding model for knowledge graph completion and search personalization,” in Conference of the North American Chapter of the Association for Computational Linguistics , 2019, pp. 2180–2189.
[55] Z. Zhang, J. Cai, and J. Wang, “Duality-induced regularizer for tensor factorization based knowledge graph completion,” International conference on Neural Information Processing Systems , vol. 33, 2020.