Android音频基础知识
鸟鸣清脆如玉,琴声婉转悠扬。。。声音对我们来说再也熟悉不过了,声音是由物体的振动产生的,并且以波的形式传播,我们把它叫做声波。
振动会发出声音,为什么我们听不到蝴蝶翅膀振动发出的声音,却能听到讨厌的蚊子声?为什么用力鼓掌比轻轻拍掌发出的声音大?这些问题要找到答案,就需要研究声音的特性。
1 声音的特性
1.1 音调(Pitch)
我们接触到的各种声音,有些听起来音调高,有些听起来音调低。声音为什么会有音调高低的不同?什么因素决定了音调的高低?
物体振动的快,发出的音调就高,振动的慢,发出的音调就低。可见发声体振动的快慢是一个很重要的物理量,他决定着音调的高低。物理学中用每秒内振动的次数——频率(Frequency)来描述物体振动的快慢。频率决定声音的音调,频率高则音调高,频率低则音调低。频率的单位为赫兹(Hertz),简称赫,符号Hz。如果一个物体一秒内振动100次,他的频率就是100Hz。
人能感受到的声音频率有一定的范围,多数人能够听到的频率范围大约20Hz到20000Hz。人们把高于20000Hz的声叫做超生波,把低于20Hz的叫做次声波。

1.2 响度(Loudness)
声音有音调的不同,也有强弱的不同,例如,用力击鼓比轻轻击鼓产生的声音大。物理学中,声音的强弱叫做响度。什么因素决定声音的响度呢?
物理学中用振幅(Amplitude)来描述物体振动的幅度。物体的振幅越大,产生声音的响度越大。
1.3 音色(Musical quality)
频率的高低决定了音调,振幅的大小影响声音的响度。但是不同物体发出的声音,即便音调和响度相同,我们还是能分辨出他们的不同。这表明在声音的特性中还有一个特性是很重要的,他就是音色。不同发声体的材料、结构不同,发出的声音的音色也就不同。体现在声波上,就是声波的形状不同。
人们在自然界中听到的绝大部分声音都具有非常复杂的波形,这些波形由基波和多种谐波构成。谐波的多少和强弱构成了不同的音色。各种发声物体在发出同一音调声音时,其基波成分相同。但由于谐波的多少不同,并且各谐波的幅度各异,因而产生了不同的音色。
音频的这三个属性,是所有音频处理的基础,所以在我们阅读源码的时候,要结合这些基础知识来看。
2 智能设备中音频
声音如此美妙~智能设备拥有音频,就像人类拥有听和说的能力,所以包括手机、平板、车载智能座舱,音频都是其中非常关键的子系统。
从整体上来讲,计算机的世界里音频的整体环节包括采集、传输、存储、播放四个环节。
借一张示意图看起来更加形象一些:
如果抽象一下看这个流程,大概如下:

3 音频的采集
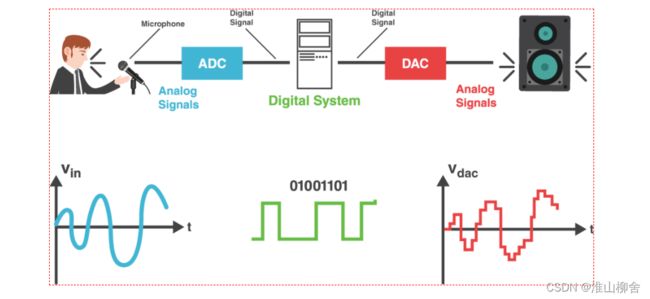
正如第二节所看到的,在现实生活中,我们听到的声音都是时间连续的,我们把这种信号叫模拟信号。模拟信号(连续信号)需要量化成数字信号(离散的、不连续的信号)以后才能在计算机中使用。所以数字音频系统需要将声波波形信号通过ADC转换成计算机支持的二进制,进而保存成音频文件,这一过程叫做音频采样(Audio Sampling)。
所以简单来讲,音频采集就是用采集设备(比如Microphone)捕获声音信息。然后将模拟信号通过模数转换器(ADC)处理成计算机能接受的二进制数据。同时根据需求进行必要的渲染处理,比如声学前处理,例如降噪、回声消除、混响处理、音效调整、过滤等等。
3.1 采集流程
3.1.1 模拟信号
模拟信号就是样本(Sample),比如一段连续的声音波形,这是我们进行采样的初始资料,现实生活中的声音表现为连续的、平滑的波形,其横坐标为时间轴,纵坐标表示声音的强弱。
3.1.2 采样
采样就是按照一定的时间间隔在连续的波上进行采样取值,如下图所示取了10个样。
采样通过采样器(Sampler)完成,采样器是将样本转换成终态信号的关键。它可以是一个子系统,也可以指一个操作过程,甚至是一个算法,取决于不同的信号处理场景。理想的采样器要求尽可能不产生信号失真。

3.1.3 量化
采样后的值还需要通过量化(Quantization),也就是将连续值近似为某个范围内有限多个离散值的处理过程。因为原始数据是模拟的连续信号,而数字信号则是离散的,它的表达范围是有限的,所以量化是必不可少的。
如上图所示,量化也就是给纵坐标定一个刻度,记录下每个采样的纵坐标的值。
3.1.4 编码
计算机的世界里,所有数值都是用二进制表示的,因而我们还需要把量化值进行二进制编码,将每个量化后的样本值转换成二进制编码,这一步通常与量化同时进行。
3.1.5 数字信号
将所有样本二进制编码连起来存储在计算机上,形成了最后的音频文件,这样就形成了声音的数字信号。
概括起来,音频的采集核心是把连续的模拟信号转换成离散的数字信号。整个流程如下图所示:

借用一张图,细化下这个流程就是:
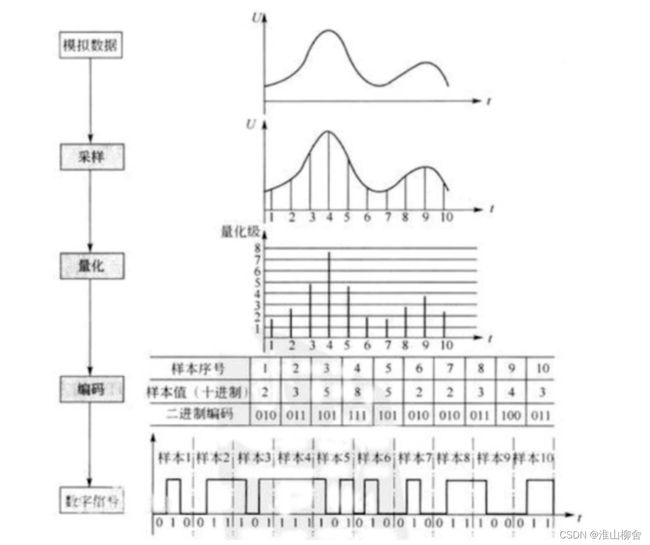
PCM(Pulse-code modulation)俗称脉冲编码调制,是将模拟信号数字化的一种经典方式,得到了非常广泛的应用。比如数字音频在计算机、DVD以及数字电话等系统中的标准格式采用的就是PCM。它的基本原理就是我们上面的几个流程,即对原始模拟信号进行抽样、量化和编码,从而产生PCM流。
3.2 音频采集中的概念
3.2.1 采样深度(Bit Depth)
一个采样用多少个bit存放,常用的是16bit(这就意味着上述的量化过程中,纵坐标的取值范围是0-65535,声音是没有负值的)。
采样深度具有比较重要的意义,因为我们知道量化是将连续值近似为某个范围内有限多个离散值的处理过程,那么这个范围的宽度以及可用离散值的数量会直接影响到音频采样的准确性。
3.2.2 采样率(Sampling Rate)
采样率就是采样频率(1秒采样次数),在将连续信号转化成离散信号时,就涉及到采样周期的选择。如果采样周期太长,虽然文件大小得到控制,但采样后得到的信息很可能无法准确表达原始信息;反之,如果采样的频率过快,则最终产生的数据量会大幅增加,这两种情况都是我们不愿意看到的,因而需要根据实际情况来选择合适的采样速率。
一般采样率有8kHz、16kHz、32kHz、44.1kHz、48kHz等,采样频率越高,声音的还原就越真实越自然,当然数据量就越大。由于人耳所能辨识的声音范围是20-20KHZ,所以人们一般都选用44.1KHZ(CD)、48KHZ或者96KHZ来做为采样速率;
我们大概算一下,如果按照44.1kHz的频率进行采样,对20HZ音频进行采样,一个正玄波采样2200次;对20000HZ音频进行采样,平均一个正玄波采样2.2次。
3.2.3 声道数(Channel)
一个声道(AudioChannel),简单来讲就代表了一种独立的音频信号。为了播放声音时能够还原真实的声场,在录制声音时在前后左右几个不同的方位同时获取声音,每个方位的声音就是一个声道。声道数是声音录制时的音源数量或回放时相应的扬声器数量,有单声道、双声道、多声道。
Monaural (单声道)
早期的音频录制是单声道的,它只记录一种音源,所以在处理上相对简单。播放时理论上也只要一个扬声器就可以了——即便有多个扬声器,它们的信号源也是一样的,起不到很好的效果
Stereophonic(立体声)
之所以称为立体声,是因为人们可以感受到声音所产生的空间感。大自然中的声音就是立体的,比如办公室里键盘敲击声,马路上汽车鸣笛,人们的说话声等等。那么这些声音为什么会产生立体感呢?
我们知道,当音源发声后(比如你右前方有人在讲话),音频信号将分别先后到达人类的双耳。在这个场景中,是先传递到右耳然后左耳,并且右边的声音比左边稍强。这种细微的差别通过大脑处理后,我们就可以判断出声源的方位了。
这个原理现在被应用到了多种场合。在音乐会的录制现场,如果我们只使用单声道采集,那么后期回放时所有的音乐器材都会从一个点出来;反之,如果能把现场各方位的声音单独记录下来,并在播放时模拟当时的场景,那么就可以营造出音乐会的逼真氛围。
Surround Sound(4.1环绕立体声)
随着技术的发展和人们认知的提高,单纯的双声道已不能满足需求了,于是更多的声道数逐渐成为主流,其中被广泛采用的就有四声道环绕立体声。
其中的“4”代表了四个音源,位置分别是前左(Front-Left)、前右(Front-Right)、后左(Rear-Left)、后右(Rear-Right)。而小数点后面的1,则代表了一个低音喇叭(Subwoofer),专门用于加强低频信号效果
Surround Sound(5.1环绕立体声)
相信大家都听过杜比数字技术,这是众多5.1环绕声中的典型代表。另外还有比如DTS、SDDS等都属于5.1技术。5.1相对于4.1多了一个声道,位置排列分别是前左、前右、中置(Center Channel)和两个Surround Channel,外加一个低音喇叭。
3.2.4 码率
也叫比特率,是指每秒传送的bit数。单位为 bps(Bit Per Second),比特率越高,每秒传送数据就越多,音质就越好。
3.2.5 音频帧(Frame)
帧(Frame)记录了一个声音单元,其长度为样本长度(采样位数)和通道数的乘积。
3.3 Nyquist–Shannon采样定律
在音频采用中, 都会用到Nyquist–Shannon采样定律,由Harry Nyquist和Claude Shannon总结出来的采样规律,为我们选择合适的采样频率提供了理论依据。这个规律又被称为“Nyquist sampling theorem”或者“The sampling theorem”,中文通常译为“奈奎斯特采样理论”。它的中心思想是:
“当对被采样的模拟信号进行还原时,其最高频率只有采样频率的一半”。
换句话说,如果我们要完整重构原始的模拟信号,则采样频率就必须是它的两倍以上。比如人的声音范围是20-20kHZ,那么选择的采样频率就应该在40kHZ左右,这也就是为什么人声的采样用44.1KHZ的比较多。数值太小则声音将产生失真现象,而数值太大也无法明显提升人耳所能感知的音质。
4 音频的传输
音频的传输通常指音频在网络上的传输,例如电话或者网络电话、目前流行视频会议都是非常常用的场景。由于人耳非常敏感,网络导致的延时、卡顿、回声都会严重影响客户体验,音频的网络传输需要重点解决这些问题。
音频网传输上通常跟视频一起,并被称为流媒体。流媒体包括广义和狭义的含义,在广义上的流媒体指的是音频和视频形式稳定和连续的系列的流动流的传输技术,方法和协议和重放的总称,即,流媒体技术;狭义上的流是相对于传统的下载——回放模式而言,是指从互联网上获取新的音频和视频等多媒体数据的方法,它可以支持多媒体数据流的实时播放的实时传输。
网络传输的大致步骤如下:
1、发起会话,通常使用Sip协议;
2、对采集到的音频进行压缩编码,可以采用硬件编码或者软件编码;
3、传输,例如RTP协议;
4、在接收端使用硬件或者软件解码,并进行回放;
5、结束会话,通过Sip协议结束会话。
如上所说,在流媒体的网络传输中,会用到RTSP实时流协议,以及RTP和RTCP协议,SIP会话协议等,下面也一同做个简单介绍。
RTP数据协议
实时传输协议是在因特网网络协议多媒体数据流进行处理,也能够使用流网络环境中的一个或许多来实现实媒体数据的传输-time。
RTP协议目的是提供实时数据端到端传输服务,因此,RTP的概念没有连接,它可以在非取向连接或面向连接的顶部建造传输协议底层;RTP不依赖于特定的网络地址格式,只需要对底层传输协议和链段的支撑框架就足够了;RTP本身不提供任何额外的可靠性机制,这些必须使传输协议或应用程序本身来保证。
RTCP控制协议
RTCP控制管理协议需要与RTP数据进行协议可以一起配合使用,当应用系统程序启动建设一个RTP会话时将同时需要占用两个端口,分别供RTP和RTCP使用。RTP本身并不能为按序传输数据包提供可靠的保证,也不提供流量控制和拥塞控制,这些都由RTCP来负责完成。RTP和RTCP通常将使用相同的分配机制,发送控制信息,以周期性地在会话中的所有成员,通过接收从中获取相关信息的会话参与者的应用程序数据,和网络状态,数据包丢失的概率反馈,因此能够控制服务或网络状态诊断的质量。
RTSP实时流协议
作为自己一个应用层协议,RTSP提供了一个企业可供扩展的框架,它的意义主要在于可以使得信息实时流媒体数据的受控和点播变得更加可能。总体而言,RTSP是用于控制具有实时特性的数据传输的流媒体该协议,但本身并不传输数据,但是必须依赖于由底层传输协议提供的某些服务。RTSP可以通过对流媒体发展提供一些诸如播放、暂停、快进等操作,它负责定义一个具体的控制系统消息、操作方式方法、状态码等,此外还描述了与RTP间的交互技术操作。
SIP协议
SIP是一个系统应用层的控制管理协议,可以直接用来进行建立、修改、和终止使用多媒体会话。SIP还可以邀请与会者参加已经存在的会议,例如多方会议。
音频编码
用于网络传输的音频编码主要有两个主要特点,第一是更关注语音压缩,毕竟,本次会议主要是听人说话;音乐可能不是很好的压缩;第二个是压缩比比较大,比较低的比特率,典型克。723支持5.9k/s这样的码率,而且语音音质还很不错。iso的音频数据可能更为人需要熟知企业一些,最流行的就是mp3,它的全称是mpeg-1 audio layer 3,意思是mpeg-1的音频进行第三层;另外,最新的音频算法可以被称为aac,它定义在mpeg-2或mpeg-4的音频以及部分。它们是由质量好,多通道,高精度采样,采样频率,尤其是乐比G系列好得多的压缩表征。
5 音频的存储
5.1音频的压缩
处理后的RAW音频数据已经可以存储到计算机设备中了。不过由于这时的音频数据体积相对庞大,不利于保存和传输,通常还会对其进行压缩处理。比如我们常见的mp3音乐,实际上就是对原始数据采用相应的压缩算法后得到的。压缩过程根据采样率、位深等因素的不同,最终得到的音频文件可能会有一定程度的失真,另外,音视频的编解码既可以由纯软件完成,也同样可以借助于专门的硬件芯片来完成。
前面小节我们分析了音频采样的基本过程,它将连续的声音波形转换成为若干范围内的离散数值,从而将音频数据用二进制的形式在计算机系统中表示。不过音频的处理并没有结束,我们通常还需要对上述过程产生的数据进行格式转化,然后才最终存储到设备中。
这里要特别注意文件格式(FileFormat)和文件编码器(Codec)的区别。编码器负责将原始数据进行一定的前期处理,比如压缩算法以减小体积,然后才以某种特定的文件格式进行保存。Codec和File Format不一定是一对一的关系,比如常见的AVI就支持多种音频和视频编码方式。本小节所讲述的以文件格式为主。比如上面提到过,模拟的音频信号转换为数字信号需要经过采样和量化,量化的过程被称之为编码,根据不同的量化策略,产生了许多不同的编码方式,常见的编码方式有:PCM 和 ADPCM,这些数据代表着无损的原始数字音频信号,添加一些文件头信息,就可以存储为WAV文件了,它是一种由微软和IBM联合开发的用于音频数字存储的标准,可以很容易地被解析和播放。
我们把数字音频格式分为以下几种:
不压缩的格式(UnCompressed Audio Format)
比如前面所提到的PCM数据,就是采样后得到的未经压缩的数据。PCM数据在Windows和Mac系统上通常分别以wav和aiff后缀进行存储。可想而知,这样的文件大小是比较可观的。
无损压缩格式(Lossless Compressed Audio Format)
这种压缩的前提是不破坏音频信息,也就是说后期可以完整还原出原始数据。同时它在一定程度上可以减小文件体积。比如FLAC、APE(Monkey’sAudio)、WV(WavPack)、m4a(Apple Lossless)等等。
有损压缩格式(Lossy Compressed Audio Format)
无损压缩技术能减小的文件体积相对有限,因而在满足一定音质要求的情况下,我们还可以进行有损压缩。其中最为人熟知的当然是mp3格式,另外还有iTunes上使用的AAC,这些格式通常可以指定压缩的比率——比率越大,文件体积越小,但效果也越差。
音频压缩的基本原理:
频谱掩蔽效应: 人耳所能察觉的声音信号的频率范围为20Hz~20KHz,在这个频率范围以外的音频信号属于冗余信号。
时域掩蔽效应: 当强音信号和弱音信号同时出现时,弱信号会听不到,因此,弱音信号也属于冗余信号。
5.2 音频编解码器
常见的音频压缩格式:
常见的音频编解码器包括OPUS、AAC、Vorbis、Speex、iLBC、AMR、G.711等。目前泛娱乐化直播系统采用rtmp协议,支持AAC和Speex。
性能上来看,OPUS > AAC > Vorbis,其它的逐渐被淘汰。
AAC编解码器介绍
AAC(Advanced Audio Coding)编解码器应用范围特别广,编解码的音频质量高保真,它出现的目的是取代mp3格式,因为mp3是有损压缩,对音频质量有一定损耗,而AAC对于原始数据的损耗就会小很多,而且压缩率很高。目前市面上90%以上的直播系统都是用的AAC(虽然OPUS性能最好,但是rtmp协议不支持OPUS)。
AAC常用规格
AAC目前常用的规格有 AAC LC、AAC HE V1、AAC HE V2。
AAC LC
AAC LC (Low Complexity) 是低复杂度,一般码率128kbt/s。
AAC HE V1
AAC HE V1是在AAC LC基础上加入了SBR(Spectral Band Replication)技术,也就是分频复用,加入这种技术后使码流变得更低,而且音质更好。比如按照44.1kHz采样率,20Hz频段一个正玄波采样2200个,这太浪费了,而在20000Hz频段一个正玄波采样2.2次,采样次数太少导致音质较差。采用SBR进行分频处理,在低频段降低采样率,在高频段提高采样率,这样既能降低码率又能提高音质。AAC HE V1一般码率为64kbt/s左右。
AAC HE V2
AAC HE V2在AAC HE V1的基础上又增加了PS(Parametric Stereo)技术。也就是将立体声双声道分别保存,一个声道的数据完整保存,另一个声道只存储一些差异性的参数信息,因为两个声道信息相关性非常强,可以通过那些差异性参数来还原这个声道的信息。AAC HE V1一般码率为32kbt/s左右。
6 音频的回放
6.1 音频回放流程
音频回放逻辑上可以认为是音频采集的逆过程,整个采集过程的一个逆序执行,只不过是最后对应的设备是声音输出设备;
所以回放实际流程是从本地存储取出音频相关文件,或者从网络端获取实时音频流后,进行相应的解码后,通过本地系统从声音输出设备中播放出来,基本的流程如下;
1、从网络端获取实时通讯音频流或者点播音频流,如果是本地的话,从本地存储设备中取出相关文件,并根据录制过程采用的编码方式进行相应的解码;
2、智能设备的音频系统为这一播放实例选定最终匹配的音频回放设备;
3、解码后的数据经过音频系统设计的路径传输;
4、音频数据信号通过数模转换器(DAC)变换成模拟信号;
5、模拟信号经过回放设备,还原出原始声音。
6.2 音频回放的概念
采集过程中所涉及到的概念在播放过程中都会涉及到,采样深度/采样率/声道等等,可以参照3.2节。
回放中和采集有些不同的是,回放要根据可以支持用户根据实际情况控制回放声音的大小。
6.3 音量控制
6.3.1 音量的概念
可能大家会说,音量还不简单吗。如果我们要深入研究音频系统,可能要深入了解一些。
音量又称音强、响度,是指人耳对所听到的声音大小强弱的主观感受,其客观评价尺度是声音的振幅大小。这种感受源自物体振动时所产生的压力,即声压。物体振动通过不同的介质,将其振动能量传导开去。人们为了对声音的感受量化成可以监测的指标,就把声压分成“级”——声压级,以便能客观的表示声音的强弱,其单位称为“分贝”(dB)。从一定的意义上讲,音量和响度几乎是同等意义的概念。
所以音量的表示实际上就是量化过程中每个采样数据的level值,只要适当的增大或者缩小采样的level就可以达到更改音量的目的。
但需要注意的是,并是不将level值*2就能得到两倍于原声音的音量。
因为如下两个原因:
数据溢出: 我们都知道每个采样数据的取值范围是有限制的,例如一个signed 8-bit样本,取值范围为-128~128,值为125时,放大两倍后的值为250,超过了可描述的范围,此时发生了数据溢出。这个时候就需要我们做策略性的裁剪处理,使放大后的值符合当前格式的取值区间。
对数描述: 平时表示声音强度我们都是用分贝(db)作单位的,声学领域中,分贝的定义是声源功率与基准声功率比值的对数乘以10的数值。根据人耳的心理声学模型,人耳对声音感知程度是对数关系,而不是线性关系。人类的听觉反应是基于声音的相对变化而非绝对的变化。对数标度正好能模仿人类耳朵对声音的反应。所以用分贝作单位描述声音强度更符合人类对声音强度的感知。前面我们直接将声音乘以某个值,也就是线性调节,调节音量时会感觉到刚开始音量变化很快,后面调的话好像都没啥变化,使用对数关系调节音量的话声音听起来就会均匀增大。
如下图所示,横轴表示音量调节滑块,纵坐标表示人耳感知到的音量,图中取了两块横轴变化相同的区域,音量滑块滑动变化一样,但是人耳感觉到的音量变化是不一样的,在左侧也就是较安静的地方,感觉到音量变化大,在右侧声音较大区域人耳感觉到的音量变化较小。
那音量怎么算合适的呢?不管是耳机发烧还是喇叭发烧,正确答案是一样的:最接近现场实际聆听的音量,是最合适的音量。也就是说,你听一张交响曲的CD,音量调到多大最合适?你就想象自己正坐在音乐厅里听一个乐队表演这首交响曲,假想不是在听CD,那么,如果你的音乐厅现场经验够丰富,你会知道,你坐在音乐厅中排位置,大致会是一个怎样的音量。就把HI-FI的音量调到这么大,最接近现场真实的响度,就是最合适的。用这个音量听,失真最小,再现音乐最逼真,最容易出好效果。
6.3.2 Weber–Fechner law
估计知道这个定律的人比较少,它是音频系统中计算声音大小的一个重要依据。从严格意义上讲,它并不只适用于声音感知,而是人体各种感观(听觉、视觉、触觉)与刺激物理量之间的一条综合规律。其中心思想用公式表达就是:
△I/I=C
其中△I表示差别阈值,I是原先的刺激量,而C则是常量。换句话说,就是能引起感观变化的刺激差别量与原先的刺激量比值是固定的。这样子说可能比较抽象,可以举一个价格差异感的例子,价格差异感是指当购买者在面对价格的调整、变化或者不同价格时的心理认知程度。如果消费者能够对价格的差异作出理性的判断,那么当绝对的价差—样时,就应该产生相同的行为。但是实践和实验的结果都表明,购买者对同样的价差的反应并不相同。下面是两个不同假设条件的实验:
实验A:假设你所光顾的文具店计算器的价格是20元,而有人告诉你其他商店的价格是15元。
实验B:假设你所光顾的文具店计算器的价格是120元,而有人告诉你其他商店的价格是115元。
那么,在哪种情况下你会改变到其他商店去购买?
实验的结果是,在A实验中大约68%的人会换一家商店去购买,B实验中大约29%人会愿意换一家商店去购买。这种实验的结果有什么特别的含义吗?只要我们仔细分析一下两组实验中的价差,就会发现两组实验的差价其实是一样的(都是5元),所以实验结果的不同寻常之处就在于,如果购物者都是理性经济人的话,为什么在相同的经济损益面前,其行为却有如此的不同呢?进一步分析,我们会发现,虽然两种实验中购物者实际节省的都是5元,但是在A中,5元相对于价格总额是一个不小的数字;而在B中,5元相对于价格微不足道。这就是营销学中著名的韦伯-费希纳定律定律:购买者对价格的感受与基础价格的水平有关,购买者对价格的感受更多地取决于相对价值,而非绝对价值。
这就是德国心理物理学家ErnstHeinrich Weber发现的规律,后来的学生GustavFechner把这一发现系统地用公式表达出来,就是上述公式所表达的韦伯定律。
后来,Fechner在此基础上又做了改进。他提出刺激量和感知是呈对数关系的,即当刺激强度以几何级数增长时,感知强度则以算术级数增加。这就是Weber–Fechner law,如下公式所示:
S = C log R
那么这对音频系统有什么指导意义呢?
我们知道,系统音量是可调的,比如分为0-20个等级。这些等级又分别对应不同的输出电平值,那么我们如何确定每一个等级下应该设置的具体电平值呢?你可能会想到平均分配。没错,这的确是一种方法,只不过按照这样的算法所输出的音频效果在用户听来并不是最佳的,因为声音的变化不连续。
一个更好的方案就是遵循Weber–Fechnerlaw,而采用对数的方法。在Android系统中,音量控制在Android系统的实现我们在后面的章节中会详细讲述。