机器学习中的数学原理——梯度下降法(最速下降法)
好久没更新了,确实是有点懒了,主要是这两天返乡在隔离(借口)。这个专栏主要是用来分享一下我在机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言!这一篇就更新一下《白话机器学习中的数学——梯度下降法》!
目录
一、什么是梯度下降法
二、算法分析
三、总结
一、什么是梯度下降法
梯度下降法(英语:Gradient descent)是一个一阶最优化算法,通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。
二、算法分析
在上一篇最小二乘法里面还记得我们的误差公式E(θ)吗?那时候我们说要使E(θ)尽可能小,即修改参数 θ,使这个值变得越来越小。
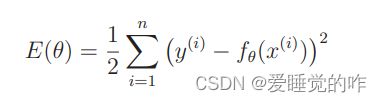
但是一边修改 θ 的值,一边 计算 E(θ) 并与之前的值相比较的做法实在是太麻烦了。所以我们使用微分的思想来求θ 的值。微分是计算变化的快慢程度时使用的方法。
首先我们看表达式为 g(x) = (x-1)^2,g(x) = (x-1)^2 的二次函数图像如下所示

它的最小值是 g(x) = 0,出现在x = 1 时。这个二次函数的增减表为:

在 x < 1 时,g(x) 的图形 向右下方延伸,反之当 x > 1 时,g(x) 的图形向右上方延伸,换句话说就是从左下方开始延伸的。 x = 3 这一点,为了使 g(x)的值变小,我们需要向左移动x,也就是必须减小 x。如果是在另一侧的 x = −1 这一点,为了使 g(x) 的值变小,我们 需要向右移动 x,也就是必须增加 x。


所以只要向与导数的符号相反的方向移动 x,g(x) 就会自然而然地沿着最小值的方向前进了。也就是自动更新参数。
上面所说的就是最速下降法或者说是梯度下降法,用数学语言表达就是:

像A := B 这种写法,它的意思是通过 B 来定义 A。上面的意思就是将后面的值来定义前面的值,从而达到更新参数的目的,即用上一个 x 来定义新的 x。
η是称为学习率的正的常数,读作“伊塔”。根据学习率的大小, 到达最小值的更新次数也会发生变化。换种说法就是收敛速度会 不同。有时候甚至会出现完全无法收敛,一直发散的情况。


那我们回过头来看一下目标函数 E(θ)。我们再看一下目标函数的表达式:
fθ(x)拥有 θ0 和 θ1 两个参数。 也就是说这个目标函数是拥有 θ0 和 θ1 的双变量函数,所以不能用 普通的微分,而要用偏微分。如此一来,更新表达式就是这样的:

这里的E是没有 θ0,是因为θ0 在 fθ(x)里面,所以这里可以使用复合函数的微分:


是不是特别熟悉,这是 我们大一高数上面的阶梯微分。先从 u 对 v 微分的地方开始计 算:

下面就是 v 对 θ0 进行微分:

合在一起,记得v 替换回fθ(x):

同样我们也可以得到 对θ1进行微分:



所以参数 θ0 和 θ1 的更新表达式就是这样的:

只要根据这个表达式来更新 θ0和 θ1,就可以找到正确的一次函数 fθ(x)了!
三、总结
梯度下降是通过迭代搜索一个函数极小值的优化算法。使用梯度下降,寻找一个函数的局部极小值的过程起始于一个随机点,并向该函数在当前点梯度(或近似梯度)的反方向移动。在线性和对数几率回归中,梯度下降可以用于搜索最优参数。至于SVM和神经网络,我们之后才考虑。