【Keras】注意力机制(Attention)
Keras注意力机制
- 注意力机制
- 导入安装包
- 加载并划分数据集
- 数据处理
- 构建模型
- main函数
注意力机制
从大量输入信息里面选择小部分的有用信息来重点处理,并忽略其他信息,这种能力就叫做注意力(Attention)。分为 聚焦式注意力和基于显著性的注意力:
- 聚焦式注意力(Focus Attention):自上而下的、有意识的注意力。指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力。
- 基于显著性的注意力(Saliency-Based Attention):自下而上的、无意识的。不需要主动干预,和任务无关,由外界刺激驱动的注意。举例:赢者通吃(最大汇聚)或者门控机制。
导入安装包
from tensorflow.keras.models import *
from tensorflow.keras.layers import Input, Dense, Multiply
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
加载并划分数据集
使用手写数字数据
#划分数据集
(x_train,y_train),(x_test,y_test) = mnist.load_data()
x_train.shape
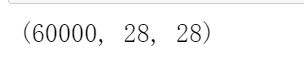
将数据维度由(60000,28,28)转为(60000,28*28),即(60000,784)
x_train = x_train.reshape(60000,784)
x_test = x_test.reshape(10000,784)
数据处理
数据类型转换:
x_train和x_test里的数据都是int整数,要把它们转换成float32浮点数
数据归一化处理:
要把x_train和x_test里的整数变成0-1之间的浮点数,就要除以255。因为色彩的数值是0-255,所以要变成0-1之间的浮点数,只要简单的除以255
one-hot处理:
y值0-9数字变成onehot模式,以后就可以把分类数据变成这种形式
#设置数据类型为float32
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 数据值映射在[0,1]之间
x_train = x_train/255
x_test = x_test/255
#数据标签one-hot处理
y_train = keras.utils.to_categorical(y_train,10)
y_test = keras.utils.to_categorical(y_test,10)
print(y_train[1])
构建模型
def build_model():
inputs = Input(shape=(input_dim,)) #输入层
# ATTENTION PART STARTS HERE 注意力层
attention_probs = Dense(input_dim, activation='softmax', name='attention_vec')(inputs)
attention_mul = Multiply()([inputs, attention_probs])
# ATTENTION PART FINISHES HERE
attention_mul = Dense(64)(attention_mul) #原始的全连接
output = Dense(10, activation='relu')(attention_mul) #输出层
model = Model(inputs=[inputs], outputs=output)
return model
可以看到注意力层就两行代码,分别是一个Dense(全连接)层和一个Multiply操作,注意Multiply是对应元素相乘。
main函数
if __name__ == '__main__':
m = build_model() #构造模型
m.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
m.summary()
m.fit(x_train,y_train,epochs=20, batch_size=128)
m.evaluate(x_test, y_test,batch_size=128)


写文不容易,请给个赞吧!