强化学习 第 1 章 绪论
1.1 强化学习概述
强化学习(reinforcement learning, RL) 讨论的问题是智能体(agent)怎么在复杂、不确定的环境(environment)里面去最大化它能获得的奖励。如图 1.1 所示,强化学习由两部分组成:智能体和环境。在强化学习过程中,智能体与环境一直在交互。智能体在环境里面获取某个状态后,它会利用该状态输出一个动作(action),这个动作也称为决策(decision)。然后这个动作会在环境之中被执行,环境会根据智能体采取的动作,输出下一个状态以及当前这个动作带来的奖励。智能体的目的就是尽可能多地从环境中获取奖励
我们可以总结出强化学习的一些特征。
(1)强化学习会试错探索,它通过探索环境来获取对环境的理解。
(2)强化学习智能体会从环境里面获得延迟的奖励。
(3)在强化学习的训练过程中,时间非常重要。因为我们得到的是有时间关联的数据(sequential data),而不是独立同分布的数据。在机器学习中,如果观测数据有非常强的关联,会使得训练非常不稳定。这也是为什么在监督学习中,我们希望数据尽量满足独立同分布,这样就可以消除数据之间的相关性。
(4)智能体的动作会影响它随后得到的数据,这一点是非常重要的。
例子:
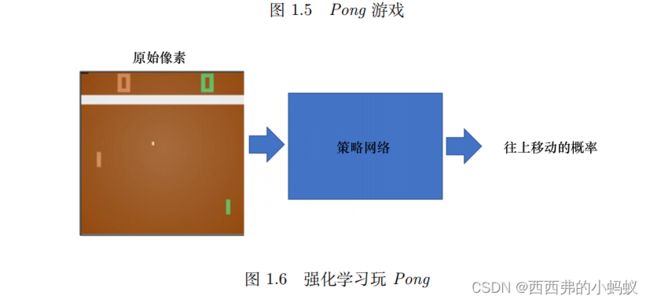
我们将当前的智能体与环境交互,会得到一系列观测。每一个观测可看成一个轨迹(trajectory)。轨迹就是当前帧以及它采取的策略,即状态和动作的序列:
![]()
1.2 强化学习和深度强化学习区别
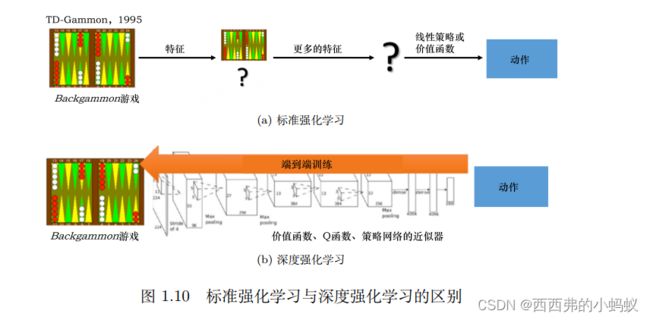
深度强化学习 = 深度学习 + 强化学习。
标准强化学习:其实就是设计特征,然后训练价值函数的过程。标准强化学习先设计很多特征,这些特征可以描述现在整个状态。得到这些特征后,我们就可以通过训练一个分类网络或者分别训练一个价值估计函数来采取动作
深度强化学习:我们不需要设计特征,直接输入状态就可以输出动作。我们可以用一个神经网络来拟合价值函数或策略网络,省去特征工程(featureengineering)的过程
1.4强化学习智能体的组成成分和类型
策略(policy)。智能体会用策略来选取下一步的动作。
价值函数
价值函数的值是对未来奖励的预测,我们用它来评估状态的好坏。价值函数里面有一个折扣因子(discount factor),我们希望在尽可能短的时间里面得到尽可能多的奖励

模型

1.5 强化学习智能体的类型
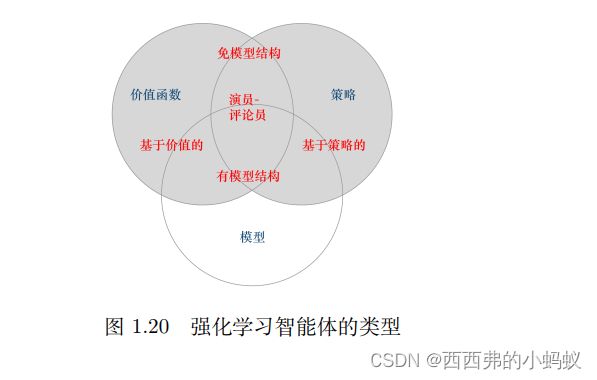
基于价值的智能体与基于策略的智能体根据智能体学习的事物不同,我们可以把智能体进行归类。 基于价值的智能体(value-based agent)显式地学习价值函数,隐式地学习它的策略。策略是其从学到的价值函数里面推算出来的。 基于策略的智能体(policy-based agent) 直接学习策略,我们给它一个状态,它就会输出对应动作的概率。基于策略的智能体并没有学习价值函数。把基于价值的智能体和基于策略的智能体结合起来就有了演员-评论员智能体(actor-critic agent)。这一类智能体把策略和价值函数都学习了,然后通过两者的交互得到最佳的动作
总结:存在基于价值和基于策略的智能体
我们来看一个走迷宫的例子。要求智能体从起点(start)开始,然后到达终点(goal)
的位置。每走一步,我们就会得到 -1 的奖励
如果换成基于价值的强化学习(value-based RL)方法,利用价值函数作为导向,我们就会得到另外一种表征,每一个状态会返回一个价值。
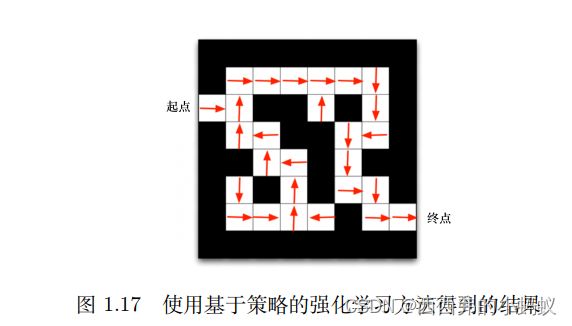
基于策略的强化学习(policy-based RL)方法,当学习好了这个环境后,在每一个状态,我们都会得到一个最佳的动作

注意补充:
对于一个状态转移概率已知的马尔可夫决策过程,我们可以使用动态规划算法来求解。从决策方
式来看,强化学习又可以划分为基于策略的方法和基于价值的方法。决策方式是智能体在给定状态下从动作集合中选择一个动作的依据,它是静态的,不随状态变化而变化。在基于策略的强化学习方法中,智能体会制定一套动作策略(确定在给定状态下需要采取何种动作),并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。而在基于价值的强化学习方法中,智能体不需要制定显式的策略,它维护一个价值表格或价值函数,并通过这个价值表格或价值函数来选取价值最大的动作。基于价值迭代的方法只能应用在不连续的、离散的环境下(如围棋或某些游戏领域),对于动作集合规模庞大、动作连续的场景(如机器人控制领域),其很难学习到较好的结果(此时基于策略迭代的方法能够根据设定的策略来选择连续的动作)。基于价值的强化学习算法有 Q 学习(Q-learning)、 Sarsa等,而基于策略的强化学习算法有策略梯度算法等。此外,演员-评论员算法同时使用策略和价值评估来做出决策。其中,智能体会根据策略做出动作,而价值函数会对做出的动作给出价值,这样可以在原有的策略梯度算法的基础上加速学习过程,取得更好的效果
马尔可夫决策过程来定义强化学习任务,并将其表示为四元组 < S, A, P, R >,即状态集
合、动作集合、状态转移函数和奖励函数。如果这个四元组中所有元素均已知,且状态集合和动作集合在有限步数内是有限集,则智能体可以对真实环境进行建模,构建一个虚拟世界来模拟真实环境中的状态和交互反应。具体来说,当智能体知道状态转移函数 P(st+1|st, at) 和奖励函数 R(st, at) 后,它就能知道在某一状态下执行某一动作后能带来的奖励和环境的下一状态,
1.6 探索和利用
在强化学习里面,探索和利用是两个很核心的问题。探索即我们去探索环境,通过尝试不同的动作来得到最佳的策略(带来最大奖励的策略)。利用是指我们直接采取已知的可以带来很好奖励的动作
最大化单步奖励需考虑两个方面:一是需知道每个动作带来的奖励,二是要执行奖励最大的动作
单步强化学习任务对应于一个理论模型,即 K-臂赌博机(K-armed bandit) 。
K-臂赌博机也被称为多臂赌博机(multi-armed bandit)。赌徒的目标是通过一定的策略最大化自己的奖励,即获得最多的硬币。
1)若仅为获知每个摇臂的期望奖励,则可采用仅探索(exploration-only)法:将所有的尝试机会平均分配给每个摇臂(即轮流按下每个摇臂),最后以每个摇臂各自的平均吐币概率作为其奖励期望的近似估计。
2)若仅为执行奖励最大的动作,则可采用仅利用(exploitation-only)法:按下目前最优的(即到目前为止平均奖励最大的)摇臂,若有多个摇臂同为最优,则从中随机选取一个
