神经网络学习笔记7——目标检测,语义分割和实例分割中的FCN
系列文章目录
RCNN系列参考视频
FCN参考视频
文章目录
- 系列文章目录
- 目标检测(Object Detection)
- 语义分割(Semantic segmentation)
- 实例分割(Instance division)
- RCNN系列算法前言
-
- 一、开山之作:RCNN
-
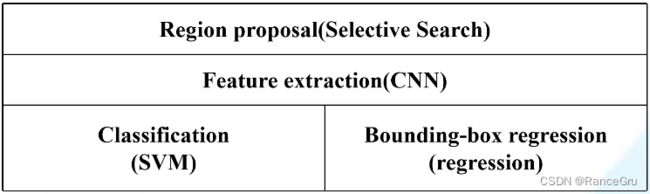
- 1、 候选区域生成
- 2、 CNN特征提取
- 3、 SVM分类器
- 4、位置精修
- 5、总体
- 二、端到端:Fast RCNN
-
- 1、 候选区域与特征提取
- 2、RoI全连接、分类器与边界框回归器
- 3、总体
- 三、走向实时:Faster RCNN
-
- 1、RPN与anchor
- 2、RPN 与 Fast_RCNN的loss损失
- 3、总体
- FCN前言
-
- 一、FCN整体结构
- 二、FCN细分结构
-
- 1、FCN-32s
- 2、FCN-16s
- 3、FCN-8s
- Mask R-CNN
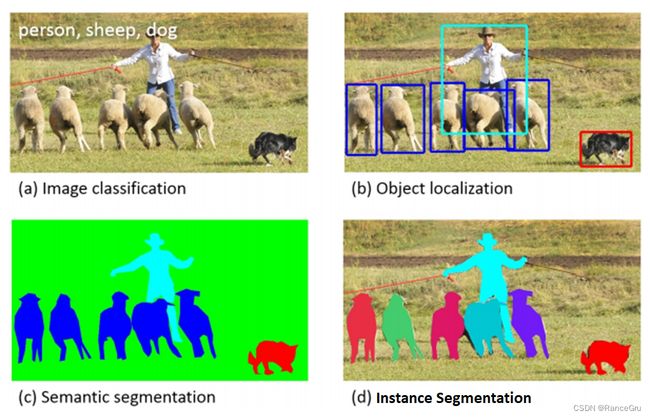
目标检测(Object Detection)
计算机视觉中关于图像识别有四大类任务:
(1)分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
(2)定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
(3)检测-Detection:解决“在哪里?是什么?”的问题,即定位出这个目标的位置并且知道目标物是什么。
(4)分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。

-
什么是目标检测
目标检测的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。目标检测分为两大系列——RCNN系列和YOLO系列,RCNN系列是基于区域检测的代表性算法,YOLO是基于区域提取的代表性算法 -
目标检测的核心问题
(1)分类问题:即图片(或某个区域)中的图像属于哪个类别。
(2)定位问题:目标可能出现在图像的任何位置。
(3)大小问题:目标有各种不同的大小。
(4)形状问题:目标可能有各种不同的形状。 -
目标检测算法分类
基于深度学习的目标检测算法主要分为两类:Two stage和One stage。1)Tow Stage
先进行区域生成,该区域称之为region proposal(简称RP,一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
任务流程:特征提取 --> 生成RP --> 分类/定位回归。
常见tow stage目标检测算法的代表就是RCNN系列算法。2)One Stage
不用RP,直接在网络中提取特征来预测物体分类和位置。
任务流程:特征提取–> 分类/定位回归。
常见的one stage目标检测算法的代表就是YOLO系列算法。
语义分割(Semantic segmentation)
通俗且具体到实际图像上来说,语义分割其实就是对于细化版的分类,就是对于一张图像上说,传统的图像分类是把图像中出现的物体进行检测并识别是属于什么类别的,也就是对于一整张图片进行分类。那么现在就有人想对于图中每一个像素点都进行分类。与分类不同的是,深度网络的最终结果是唯一重要的,语义分割不仅需要在像素级别上进行区分,而且还需要一种机制将编码器不同阶段学习到的区分特征投影到像素空间上。
当我们把一张图上某一个像素点都进行分类后,每一个像素点都会有被赋予一个类别。当每一个像素都被标记上不同的类别之后,将每一个对应不同类别的像素点赋予新的颜色之后再次重新组合成一张图片。这个时候对于这张图片来说,从像素级别上就把所有所有进行了区分,赋予颜色重新再次连起来之后在图像上就表现出图中的某个物体从这整张图片上分割了下来且具备这物体的所有的语义信息。可以说图像分割就是图像分类的细推理,从粗推理到细推理的过程。
语义分割只能划分类别,而同类无法划分,因此在语义分割之后还需要用实例分割来划分同类别的不同实例 。
实例分割(Instance division)
实例分割同时利用目标检测和语义分割的结果,通过目标检测提供的目标最高置信度类别的索引,将语义分割中目标对应的Mask抽取出来。实例分割顾名思义,就是把一个类别里具体的一个个对象(具体的一个个例子)分割出来。举例来说,如果一张照片中有多个人,对于语义分割来说,只要将所由人的像素都归为一类,但是实例分割还要将不同人的像素归为不同的类。也就是说实例分割比语义分割更进一步。
RCNN系列算法前言
工程应用中,检测算法以one-stage算法yolo系列等为主,因为one-stage通常来说速度快,可以完成良好的实时检测,而two-stage算法代表RCNN系列略有不及,但一些深度学习框架如百度PaddlePaddle开源了用于目标检测的RCNN模型,从而可以快速构建满足各种场景的应用,包括但不仅限于安防监控、医学图像识别、交通车辆检测、信号灯识别、食品检测等等。
作为经典的目标检测框架Faster R-CNN,虽然是2015年的论文,但是它至今仍然是许多目标检测算法的基础,这在飞速发展的深度学习领域十分难得。而在Faster R-CNN的基础上改进的Mask R-CNN在2018年被提出,并斩获了ICCV2017年的最佳论文。Mask R-CNN可以应用到人体姿势识别,并且在实例分割、目标检测、人体关键点检测三个任务都取得了很好的效果。
Mask R-CNN是承继于Faster R-CNN,Mask R-CNN只是在Faster R-CNN上面增加了一个Mask Prediction Branch(Mask预测分支),并且在ROI Pooling的基础之上提出了ROI Align。所以要想理解Mask R-CNN,就要先熟悉Faster R-CNN。同样的,Faster R-CNN是承继于Fast R-CNN,而Fast R-CNN又承继于R-CNN,因此,为了能让大家更好的理解基于CNN的目标检测方法,我们从R-CNN开始切入,一直简单介绍到Mask R-CNN。
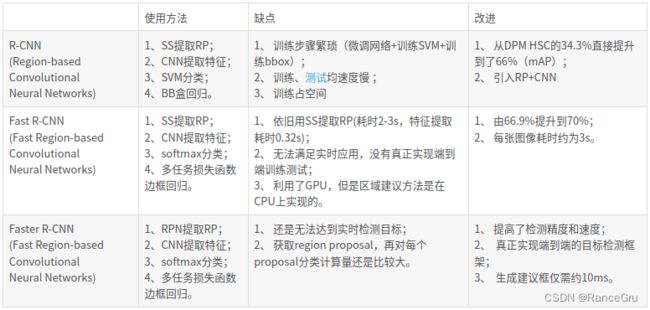
一、开山之作:RCNN
RCNN算法由Ross Girshick等人发表在CVPR 2014,将卷积神经网络应用于特征提取,并借助于CNN良好的特征提取性能,一举将PASCAL VOC数据集的检测率从35.1%提升到了53.7%。
RCNN仍然延续传统物体检测思想,将物体检测当做分类任务处理,即先提取一系列的候选区域,然后对候选区域进行分类,具体过程主要包含四步:
1、 候选区域生成
采用Region Proposal提取候选区域,例如SS(Selective Search)算法,先将图像分割成小矩形区域,然后合并包含同一物体可能性最高的区域并输出,在这一步提取约2000个候选区域。在提取完需要将每一个区域进行归一化处理,把候选区域缩放到227×227,得到固定大小的图像。
SS算法首先通过简单的区域划分算法,将图片划分成很多小区域,再通过相似度和区域大小(小的区域先聚合,这样是防止大的区域不断的聚合小区域,导致层次关系不完全)不断的聚合相邻小区域,类似于聚类的思路。这样就能解决object层次问题。

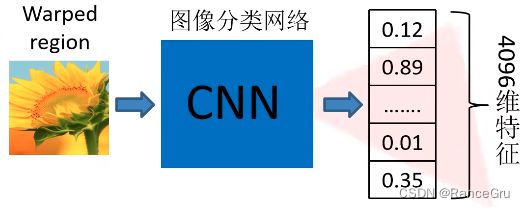
2、 CNN特征提取
将上述固定大小的图像,利用CNN深度网络得到固定维度的特征输出。比如输入Alexnet CNN网络,在Alexnet中并没有直接执行全连接层直接分类,而是截停在展平处理,获得一个2000×4096特征矩阵
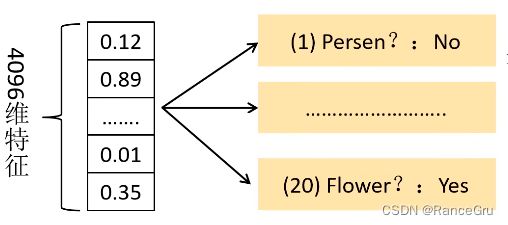
3、 SVM分类器
使用线性二分类器SVM对输出的特征进行分类,得到是否属于此类的结果,并采用难样本挖掘来平衡正负样本的不平衡。以PASCAL VOC数据集为例,该数据集中有20个类别,因此设置20个SVM分类器。将2000×4096的特征与20个SVM组成的权值矩阵4096×20相乘,获得2000×20维矩阵,表示2000个候选区域分别属于20个分类的概率,因此矩阵的每一行之和为1。
意思是一共有2000个候选框,每个候选框都存在4096维特征,而每一个候选框的每一维都需要执行20个SVM二分类判断,这里的20个SVM代表的是20个类别。那么2000×4096维矩阵中每一行代表其中一个候选框,4096×20维矩阵中每一列代表其中一种类别分类器,第一行与每一列相乘得到的是第一个候选框20类中属于每一类的概率得到的就是2000×20维矩阵中第一行,以此类推得到2000个候选框在20类中属于每一类的概率。

分别对2000×20维矩阵中每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中概率最大的一些候选框。 非极大值抑制剔除重叠建议框的具体实现方法是:
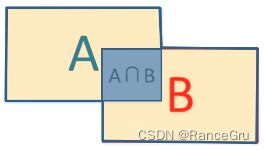
第一步:定义 IoU 指数(Intersection over Union),即 (A∩B) / (AUB)交并比 ,即AB的重合区域面积与AB总面积的比。直观上来讲 IoU 就是表示候选框AB重合的比率, IoU越大说明AB的重合部分占比越大,即A和B越相似。
第二步:找到每一类中2000个候选框中类别概率最高的候选框,计算其他候选框与该候选框的相似度IoU值,删除所有IoU值大于阈值的候选框。这样可以只保留少数重合率较低的候选框,去掉重复区域,因为 对于同一个目标可能有很多个不同大小的候选框,那么通过这个方法去除其他保留最高分类概率的高质量候选框。
比如下面的例子,A是向日葵类对应的所有候选框中概率最大的区域,B是另一个区域,计算AB的IoU,其结果大于阈值,那么就认为AB属于同一朵向日葵,所以应该保留A,删除B,因为同一个目标只需要一个锚框,这就是非极大值抑制。

4、位置精修
通过回归器,对特征进行边界回归以得到更为精确的目标区域。通过 SS算法得到的候选区域位置不一定准确,因此用20个回归器对20个类别中剩余的候选框进行回归操作,最终得到每个类别的修正后的目标区域。具体实现如下:
如图,黄色框表示候选框 Region Proposal,绿色窗口表示实际区域Ground Truth(人工标注的),红色窗口表示 Region Proposal 进行回归后的预测区域,可以用最小二乘法解决线性回归问题。
通过回归器可以得到候选区域的四个参数,分别为:候选区域的x和y的偏移量,高度和宽度的缩放因子。可以通过这四个参数对候选区域的位置进行精修调整,就得到了红色的预测区域。

5、总体
优点:
R-CNN 对之前物体识别算法的主要改进是使用了预先训练好的卷积神经网络来抽取特征,有效的提升了识别精度。
RCNN虽然显著提升了物体检测效果,但仍然存在3个角度问题:
- 训练和测试速度慢,RCNN需要多步训练,步骤繁琐且训练速度较慢,对一张图像我们可能选出上千个兴趣区域,这样导致每张图像需要对卷积网络做上千次的前向计算。
- 由于实际分类中的全连接网络,因此输入尺寸是固定的,造成了精度的降低。
- 候选区域是需要提前提取并保存,占用空间较大。
二、端到端:Fast RCNN
在RCNN之后,SPPNet算法解决了重复卷积计算与固定输出尺度两个问题,但仍然存在RCNN的其他弊端。在2015年,Ross Girshick独自提出了更快、更强的Fast RCNN算法,不仅训练的步骤可以实现端到端,而且算法基于VGG16网络,在训练速度上比RCNN快了近9倍多,在测试速度上快了213倍,并在VOC 2012数据集上达到了68.4%的检测率。
1、 候选区域与特征提取
同样使用SS(Selective Search)算法,不同于RCNN直接将图像分割成小矩形区域,Fast-RCNN先确定候选框位置,然后将整张图像送入卷积网络,一次性计算整张图像特征,最后根据先前确定RoI候选框的坐标映射RoI获得想要的RoI候选特征图,不需要重复计算就提取约2000个候选框的特征图。

将整幅图送到卷积网络中进行区域生成,而不是像RCNN那样一个个的候选区域,虽然仍采用Selective Search方法,但共享卷积的优点使得计算量大大减少。
2、RoI全连接、分类器与边界框回归器
对每个样本候选框矩阵使用特征池化(RoI Pooling)的方法来进行特征尺度变换,这种方法可以有任意大小图片的输入,使得训练过程更加灵活、准确,而不需要限制图像尺寸。
将候选特征图划分为固定数量(7×7),然后进行最大池化下采样maxpool来得到一个7×7特征矩阵,然后展平为一维向量(vector)。再经过两个全连接层(fully connected layers,FC),得到ROI特征向量(ROI feature vector)。
通过展平为一维向量(vector)。再经过两个全连接层(fully connected layers,FCs),得到ROI特征向量(ROI feature vector)。之后 ROI feature vector 并联两个FCs,其中一个用于目标概率预测softmax分类器,另一个用于边界框参数的回归bbox regressor回归器(bbox 表示 bounding box)。
这里使用的是不同于RCNN的SVM,将分类与回归网络放到一起训练,并且为了避免SVM分类器带来的单独训练与速度慢的缺点,使用了softmax函数进行分类。softmax分类器的输出为N+1个,N是指你的类别,1是指除了指定类别之外的东西都归属于背景类。以PASCAL VOC数据集为例,该数据集中有20个类别,因此设置21个softmax分类器。
因为有N+1个分类的候选框,每个候选框都有 ( d x 、 d y 、 d w 、 d h ) (d_x、d_y、d_w、d_h) (dx、dy、dw、dh)四个参数,所以 bbox regressor 的全连接层FCs输出了 4×(N+1) 个节点。

Fast RCNN提供了计算回归公式,通过候选框提供的 ( P x 、 P y 、 P w 、 P h ) (P_x、P_y、P_w、P_h) (Px、Py、Pw、Ph)数据以及全连接层输出的 ( d x 、 d y 、 d w 、 d h ) (d_x、d_y、d_w、d_h) (dx、dy、dw、dh)参数进行计算。

因为在Fast RCNN 中需要预测N+1个类别的概率以及边界框的回归参数,所以定义了两个损失函数:分类损失和边界框回归损失,两个损失之和就是总损失。
( v x 、 v y 、 v w 、 v h ) (v_x、v_y、v_w、v_h) (vx、vy、vw、vh)的计算就需要逆反计算上面的回归公式。




3、总体

RCNN由四部分组成,因此需要多步训练,非常繁琐。而Fast RCNN将CNN特征提取,边界框分类器,bbox regression边界框回归三部分结合到了一起,都融合到同一个CNN中。那么Fast RCNN就只有两部分了:先通过SS算法获取候选框,再通过CNN完成特征提取、分类和边界框回归。
Fast RCNN算法虽然取得了显著的成果,但在该算法中,Selective Search需要消耗2~3秒,而特征提取仅需要0.2秒,因此这种区域生成发方限制了Fast RCNN算法的发挥空间,这也为后来的Faster RCNN算法提供了改进方向。
优点:
对整个图像进行特征抽取,然后再选取提议区域,从而减少重复计算;
缺点:
1、尽管用到了GPU,但Region proposal还是在CPU上实现的。在CPU中,用SS算法提取一张图片的候选框区域大约需要2s,而完成整个CNN则只需要0.32s,因此Fast RCNN 计算速度的瓶颈是Region proposal。
2、无法满足实时应用,没有真正实现端到端训练测试;
三、走向实时:Faster RCNN
Faster RCNN 是作者 Ross Girshick 继 RCNN 和 Fast RCNN后的又一力作。同样使用 VGG16作为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。在2015年的ILSVRC以及cOco竞赛中获得多个项目的第一名。该算法最大的创新点在于提出了RPN(Region Proposal Network)网络来替代SS算法,利用Anchor机制将区域生成与卷积网络联系到一起,将检测速度一举提升到了14 FPS(Frames Per Second),并在VOC 2012测试集上实现了70.4%的检测结果。
1、RPN与anchor
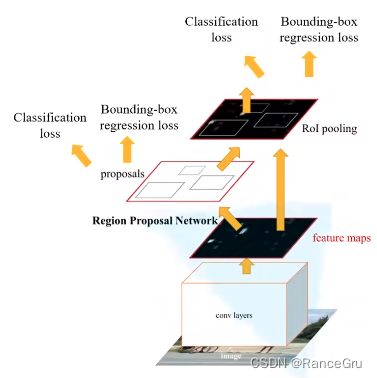
Faster RCNN 其实就是RPN+Fast RCNN的组合,RPN取代了SS的位置,用于特征图生成之后的候选框提取。
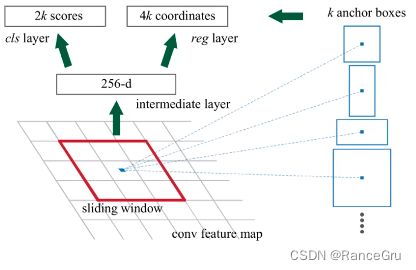
将图像输入卷积网络得到相应的特征图feature maps,使用RPN网络在特征图上生成候选框,将RPN生成的候选框投影到特征图上获得ROI区域的特征矩阵。

图中的 conv feature map 是原图像输入卷积网络得到的特征图,通过3×3的sliding window滑动窗口处理,每滑动到一个位置上就会产生一个256-d的一维向量。这里的256是ZF网络的该向量再通过两个全连接层,最后分别输出分类概率2k scores和边界框回归参数4k coordinates,其中k是指 k个 anchor boxes,2k个scores是每个 anchor box 分别为前景和背景的概率(注意这里只区分前景和背景,所有的类别都归为前景),4k个coordinates是因为每个anchor box 有四个参数。
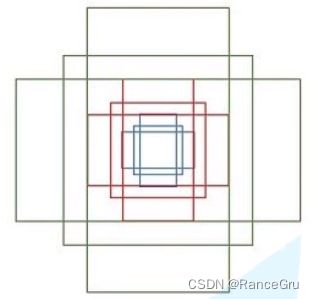
那么什么是 anchor呢?首先要明确,anchor不是候选框(Proposal),在特征图中通过确定一个滑动窗口,再通过滑动窗口的中心点寻找对于原图的点,将原图的高宽除以特征图的高宽取整得到两者比例,通过比例就可以在原图中找到对应的一个像素点,以该像素点为中心,画出n个不同大小和长宽比的框,称为anchor ,这些anchor里面可能包含目标,也可能没有目标。因为我们在一张图中想找的的目标的大小和长宽比并不是固定的,所以这里同一个点可以设置n个不同大小和长宽比的anchor来进行预测。
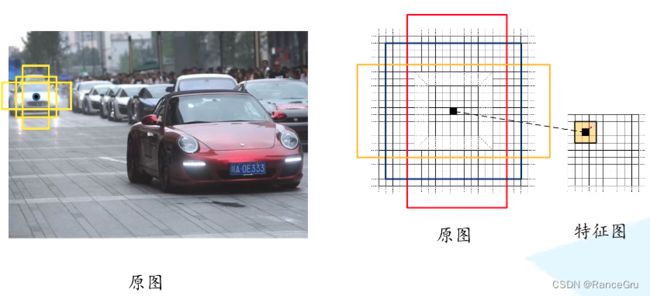
怎么确定这个n的个数呢?论文中设计每个anchor的面积和长宽比:
面积 ( 12 8 2 , 25 6 2 , 51 2 2 ) (128^2,256^2,512^2) (1282,2562,5122)
长宽比 ( 1 : 1 , 1 : 2 , 2 : 1 ) (1:1,1:2,2:1) (1:1,1:2,2:1)
计算可得n为3×3=9,如下图所示,蓝色的三个anchor是面积为128×128的,红色是面积为256×256的,绿色是512×512的。
2k个scores是每个 anchor box 分别为前景和背景的概率(注意这里只区分前景和背景,所有的类别都算前景),cls两两为一组判断分别为前景后景的概率。
reg和Fast RCNN的一样,由全连接层输出每个 anchor box 都有 ( d x 、 d y 、 d w 、 d h ) (d_x、d_y、d_w、d_h) (dx、dy、dw、dh)四个参数。
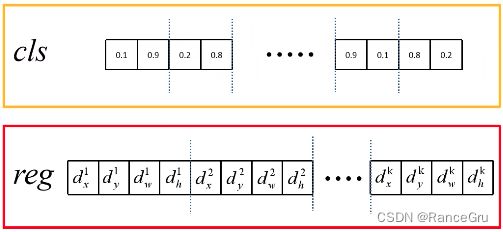
anchor与候选框的关系是什么?假设有一张 1000x600x3 的图像,用3x3的卷积核进行特征提取得到60x40的特征图,则共有 60x40x9 (约2w个)个anchor。舍弃一些超过图片边界的 anchor 后,剩下约 6000 个anchor。对于这6000 个 anchor,通过RPN生成的边界框回归参数将每个 anchor 调整为候选框(前面提到了每个anchor经过RPN都输出2个概率和4个边界框回归参数),这里就能看到proposal是在anchor中提取出来的,这个过程也就是 RPN 生成候选框的过程。RPN 生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩下 2000 个候选框。
2、RPN 与 Fast_RCNN的loss损失


RPN对cls和reg执行预测判断,对RPN进行损失计算,和Fast RCNN的损失计算相似需要计算分类与边界框的损失和,但是这里的cls分类是前景背景分类,reg边界框是anchor边界回归。
对于cls的计算有两种说法,一种是使用多分类2k个anchor,另一种是二值交叉熵分类k个anchor。
多分类损失:
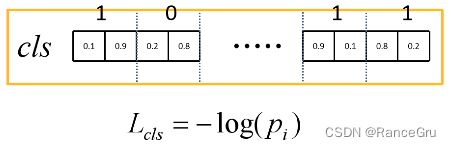
两两一组anchor,分别对应背景与前景(所需检测目标统称归属为前景), p i ∗ p^*_i pi∗的值是最上面的1、0等真实样本值, p i p_i pi则是矩形框中的0.1、0.9等预测值。
根据 p i ∗ p^*_i pi∗来输入 p i p_i pi的值,计算-log的值。
二值分类损失:

一个矩形代表一个anchor, p i ∗ p^*_i pi∗的值是最上面的1、0等真实样本值, p i p_i pi则是矩形框中的0.1、0.9等预测值。 p i ∗ p^*_i pi∗使得公式前后哪部分为0。
边界框回归损失:

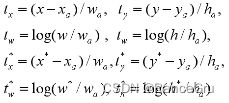
Fast RCNN损失:
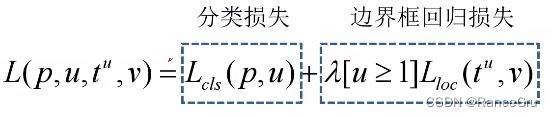
之前讲过Faster RCNN 其实就是RPN+Fast RCNN的组合,RPN取代了SS的位置,用于特征图生成之后的候选框提取。所以在具体分类时一样使用到Fast RCNN损失。

结合RPN预测的候选框映射到原特征图中得到一个个特征矩阵,再通过 ROI pooling 层缩放到7x7大小的特征图,接着将特征图展平为vector,之后通过一系列全连接层得到预测结果。
3、总体

Anchor可以看做是图像上很多固定大小与宽高的方框,由于需要检测的物体本身也是一个个大小宽高不同的方框,因此Faster RCNN将Anchor当做强先验的知识,接下来只需要将Anchor与真实物体进行匹配,进行分类与位置的微调即可。相比起没有Anchor的物体检测算法,这样的先验无疑降低了网络的收敛速度,再加上一系列的工程优化,使得Faster RCNN达到了物体检测侧中的一个高峰。
FCN前言
全卷积网络FCN全称是 Fully Convolutional Networks for Semantic Segmentation, 用于语义分割的首个端对端的针对像素级预测的全卷积网络,对图像进行像素级的分类,从而解决了语义级别的图像分割问题。
与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全连接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。FCN虽然在现在看来存在一些问题,准确度也不够了,但是FCN开创了语义分割的新时代。语义分割后续的发展基本上都是在FCN上提出的理念上进行的。
FCN的卷积网络部分可以采用VGG、GoogleNet、AlexNet等作为前置基础网络,在这些的预训练基础上进行迁移学习与finetuning,对反卷积的结果跟对应的正向feature map进行叠加输出(这样做的目的是得到更加准确的像素级别分割),根据上采样的倍数不一样分为FCN-8S、FCN-16S、FCN-32S。
核心思想:
- 不含全连接层的全卷积网络,可适应任意尺寸输入,全卷积的含义是将分类网络的全连接层全部替换成了卷积层;
- 反卷积层增大图像尺寸,输出精细结果;
- 结合不同深度层结果的跳级结构,确保鲁棒性和精确性。
不足:
- 得到的结果还不够精细,对细节不够敏感;
- 未考虑像素与像素之间的关系,缺乏空间一致性等。
一、FCN整体结构
在传统的CNN网络中,在最后的卷积层之后会连接上若干个全连接层和softmax,将卷积层产生的特征图(feature map)映射成为一个固定长度的特征向量。一般的CNN结构适用于图像级别的分类和回归任务,因为它们最后都期望得到输入图像的分类的概率,如VGG16网络最后输出一个1000维的向量表示输入图像属于每一类的概率。
但是FCN网络与经典CNN在卷积层结束之后使用全连接层进行分类不同,FCN将全连接层全部转化为卷积层可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后奇偶在上采样的特征图进行像素的分类。
下图是VGG16的模型架构,在7 × 7 × 512后连接上的是3个全连接层分别是1 × 1 × 4096,1 × 1 × 4096,1 × 1 × 1000和softmax。

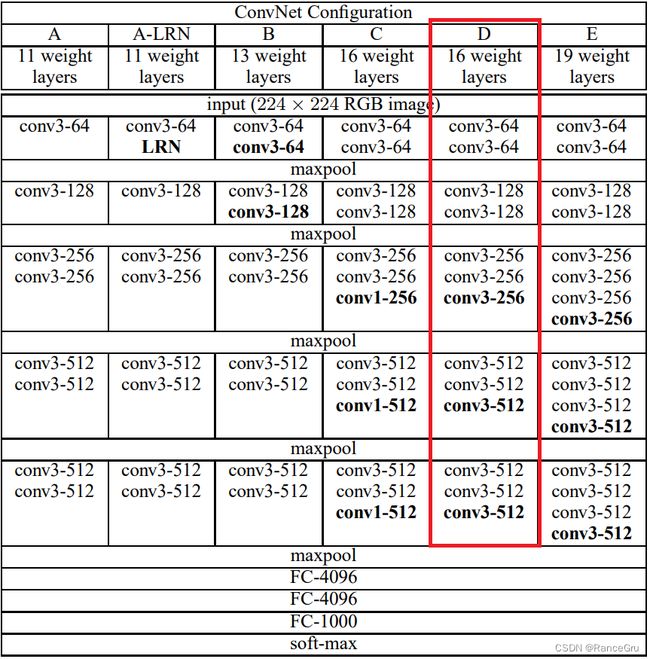
在VGG分类网络当中,将7 × 7 × 512 矩阵首先进行Flatten展平处理,得到一个长度为25088个节点的向量,通过全连接层输出后得到长度4096维的向量。每一维输出向量都要和输入进行全连接,则总共有25088 × 4096个权重参数。
上面提到FCN不使用全连接层,而是直接使用卷积核大小7 × 7 ,步距为1,卷积核个数为4096的卷积操作代替全连接层,其中一个卷积核对应7 × 7 × 512个参数,刚好与全连接层的输入节点个数相同,所以实际上全连接层输出中一个节点所对应的参数个数与一个卷积核的参数是一样的都是102760448。故直接将全连接层每一个节点所对应的权重参数进行reshape处理,就能直接赋值给卷积层进行使用了,并且保留了高度和宽度信息。
剩下的全连接层也是如此转换。

二、FCN细分结构
对照VGG16的conv和pool的结构,conv6代表第一个全连接层对应的卷积层,conv7代表第二个全连接层对应的卷积层,以此类推。
FCN-32s是指将pool5的预测结果上采样了32倍还原回了原图大小,同理pool4下采样16倍,pool3下采样8倍,pool2下采样4倍,pool1下采样2倍。

1、FCN-32s

- 从VGG16 Backbone中的pool5开始,保存其输出 w 32 × h 32 × 512 \frac{w}{32}×\frac{h}{32}×512 32w×32h×512并继续执行后面操作。
- FC6和FC7代替的是VGG16 Backbone最后两个FC-4096(1×1×4096与1×1×4096),FC6代表第一个全连接层对应的卷积层,FC7代表第二个全连接层对应的卷积层。
- 输入图片宽高为w×h,经过VGG16 Backbone多次下采样,使得Conv5后输出的宽高为 w 32 × h 32 \frac{w}{32}×\frac{h}{32} 32w×32h。
- pool5下采样输出 w 32 × h 32 × 512 \frac{w}{32}×\frac{h}{32}×512 32w×32h×512,并作为输入传入FC6。
- FC6的卷积层步长为1,padding为3,不对高宽进行改变下得到输出 w 32 × h 32 × 4096 \frac{w}{32}×\frac{h}{32}×4096 32w×32h×4096,输出大小不会发生变化。
- FC7由于卷积核大小为1 × 1 ,所以输出大小也不会发生变化。
- FC7之后在执行一个Conv2d操作,通过1 × 1的卷积层,高宽仍不发生变化,输出通道数变为类别个数(包含背景类)。
- 通过一个卷积核为64,步长为32的ConvTranspose2d转置卷积上采样32倍,得到 h × w × N u m C l s h×w×NumCls h×w×NumCls输出,恢复原图大小,再进行softmax处理就能得到每一个像素的预测类别。
直接进行的上采样倍率太大
2、FCN-16s

- 从VGG16 Backbone中的pool4开始,保存pool4和pool5输出 w 16 × h 16 × 512 \frac{w}{16}×\frac{h}{16}×512 16w×16h×512和 w 32 × h 32 × 512 \frac{w}{32}×\frac{h}{32}×512 32w×32h×512并继续执行后面操作。
- FC6和FC7代替的是VGG16 Backbone最后两个FC-4096(1×1×4096与1×1×4096),FC6代表第一个全连接层对应的卷积层,FC7代表第二个全连接层对应的卷积层。
- 输入图片宽高为w×h,经过VGG16 Backbone多次下采样,使得Conv5后输出的宽高为 w 32 × h 32 \frac{w}{32}×\frac{h}{32} 32w×32h。
- pool5下采样输出 w 32 × h 32 × 512 \frac{w}{32}×\frac{h}{32}×512 32w×32h×512,并作为输入传入FC6。
- FC6的卷积层步长为1,padding为3,不对高宽进行改变下得到输出 w 32 × h 32 × 4096 \frac{w}{32}×\frac{h}{32}×4096 32w×32h×4096,输出大小不会发生变化。
- FC7由于卷积核大小为1 × 1 ,所以输出大小也不会发生变化。
- FC7之后在执行一个Conv2d操作,通过1 × 1的卷积层,高宽仍不发生变化,输出通道数变为类别个数(包含背景类)。
- 通过一个卷积核为4×4,步长为2的ConvTranspose2d转置卷积上采样2倍,得到 w 16 × h 16 × N u m C l s \frac{w}{16}×\frac{h}{16}×NumCls 16w×16h×NumCls输出。
- 对pool4保存的输出 w 16 × h 16 × 512 \frac{w}{16}×\frac{h}{16}×512 16w×16h×512进行一个卷积核大小为1 × 1,步长为1的卷积操作,得到输出 w 16 × h 16 × N u m C l s \frac{w}{16}×\frac{h}{16}×NumCls 16w×16h×NumCls。
- 将第八步与第九步的输出相加,再进行一次卷积核为32×32,步长为16的ConvTranspose2d转置卷积上采样16倍,恢复原图大小。再进行softmax处理就能得到每一个像素的预测类别。
与FCN-32s第一个不同之处在于第一个转置卷积。FCN-32s是直接上采样32倍,而FCN-16s则是先上采样2倍,再与来自Max-pooling4输出的特征图相加,最后上采样16倍,得到了原图尺寸。
3、FCN-8s
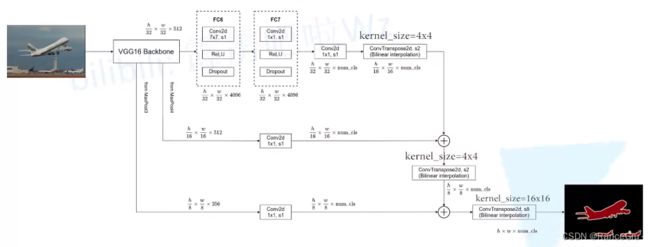
- 从VGG16 Backbone中的pool3开始,保存pool3、pool4和pool5的输出 w 8 × h 8 × 256 \frac{w}{8}×\frac{h}{8}×256 8w×8h×256、 w 16 × h 16 × 512 \frac{w}{16}×\frac{h}{16}×512 16w×16h×512和 w 32 × h 32 × 512 \frac{w}{32}×\frac{h}{32}×512 32w×32h×512并继续执行后面操作。
- FC6和FC7代替的是VGG16 Backbone最后两个FC-4096(1×1×4096与1×1×4096),FC6代表第一个全连接层对应的卷积层,FC7代表第二个全连接层对应的卷积层。
- 输入图片宽高为w×h,经过VGG16 Backbone多次下采样,使得Conv5后输出的宽高为 w 32 × h 32 \frac{w}{32}×\frac{h}{32} 32w×32h。
- pool5下采样输出 w 32 × h 32 × 512 \frac{w}{32}×\frac{h}{32}×512 32w×32h×512,并作为输入传入FC6。
- FC6的卷积层步长为1,padding为3,不对高宽进行改变下得到输出 w 32 × h 32 × 4096 \frac{w}{32}×\frac{h}{32}×4096 32w×32h×4096,输出大小不会发生变化。
- FC7由于卷积核大小为1 × 1 ,所以输出大小也不会发生变化。
- FC7之后在执行一个Conv2d操作,通过1 × 1的卷积层,高宽仍不发生变化,输出通道数变为类别个数(包含背景类)。
- 通过一个卷积核为4×4,步长为2的ConvTranspose2d转置卷积上采样2倍,得到 w 16 × h 16 × N u m C l s \frac{w}{16}×\frac{h}{16}×NumCls 16w×16h×NumCls输出。
- 对pool4保存的输出 w 16 × h 16 × 512 \frac{w}{16}×\frac{h}{16}×512 16w×16h×512进行一个卷积核大小为1 × 1,步长为1的卷积操作,得到输出 w 16 × h 16 × N u m C l s \frac{w}{16}×\frac{h}{16}×NumCls 16w×16h×NumCls。
- 将第八步与第九步的输出相加,再进行一次卷积核为4×4,步长为2的ConvTranspose2d转置卷积上采样2倍,得到 w 8 × h 8 × N u m C l s \frac{w}{8}×\frac{h}{8}×NumCls 8w×8h×NumCls输出。
- 对pool3保存的输出 w 8 × h 8 × 512 \frac{w}{8}×\frac{h}{8}×512 8w×8h×512进行一个卷积核大小为1 × 1,步长为1的卷积操作,得到输出 w 8 × h 8 × N u m C l s \frac{w}{8}×\frac{h}{8}×NumCls 8w×8h×NumCls。
- 将第十步与第十一步的输出相加,再进行一次卷积核为16×16,步长为8的ConvTranspose2d转置卷积上采样8倍,恢复原图大小。再进行softmax处理就能得到每一个像素的预测类别。
FCN-8s中不仅利用到了来自Maxpooling4的输出,还利用到了来自Maxpooling3的输出,最终上采样8倍,得到最终的原图尺寸。
Mask R-CNN
未完待续。。。