Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
ALBEF:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
论文链接:https://arxiv.org/abs/2107.07651
代码:https://github.com/salesforce/ALBEF
引入了一种对比损失,通过在跨模态注意前融合(ALBEF)来调整图像和文本表示,从而引导视觉和语言表示学习 。
为了改进从噪声web数据中学习,作者提出了动量蒸馏,这是一种从动量模型产生的伪目标中学习的自训练方法。
Motivation
大多数现有的VLP方法(如LXMERT,UNITER,OSCAR)都依赖于预训练过的目标检测器来提取基于区域的图像特征,并使用多模态编码器将图像特征与单词token进行融合。
(1)图像特征和词嵌入位于它们自己的空间中,这使得多模态编码器学习建模它
们的交互具有挑战性;
(2)目标检测器标注成本高,计算成本高,因为它在预训练需要边界框标注,在
推理过程中需要高分辨率(例如600×1000)图像;
(3)广泛使用的图像-文本数据集是从web中收集而来的,具有固有的噪声

一个图像编码器、一个文本编码器和一个多模态编码器。使用一个12层的视觉TransformerViT-B/16作为图像编码器,并使用在ImageNet-1k上预训练的权重来初始化它。一个输入图像I被编码到特征tokens序列,使用[CLS] token的嵌入对齐。
对文本编码器和多模态编码器都使用了一个6层的Transformer。文本编码器使用BERT base模型的前6层进行初始化,多模态编码器使用BERT Base模型的最后6层进行初始化。文本编码器将输入文本T转换为文本嵌入tokens,并输入多模态编码器。通过在多模态编码器的每一层进行交叉注意力,将图像特征与文本特征融合。
学习了一个相似性函数,使匹配的图像-文本对具有更高的相似性得分,受MoCo的启发,作者维护了两个队列来存储动量单模态编码器的最新的M个图像-文本表示
Image-Text Contrastive Learning
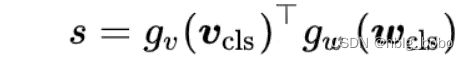
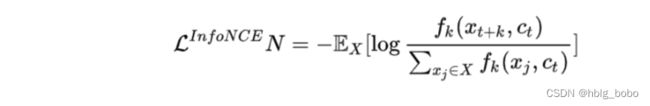

预训练pretask
ALBEF预训练任务分为图文对比(Image-Text Contrastive Learning)、.掩码建模(Masked Language Modeling)、.图文匹配(Image-Text Matching)三个任务。
掩码建模 Masked Language Modeling
通常屏蔽给定句子中特定百分比的单词,模型期望基于该句子中的其他单词预测这些被屏蔽的单词。这样的训练方案使这个模型在本质上是双向的,因为掩蔽词的表示是根据出现的词来学习的,不管是左还是右。你也可以把它想象成一个填空式的问题陈述。
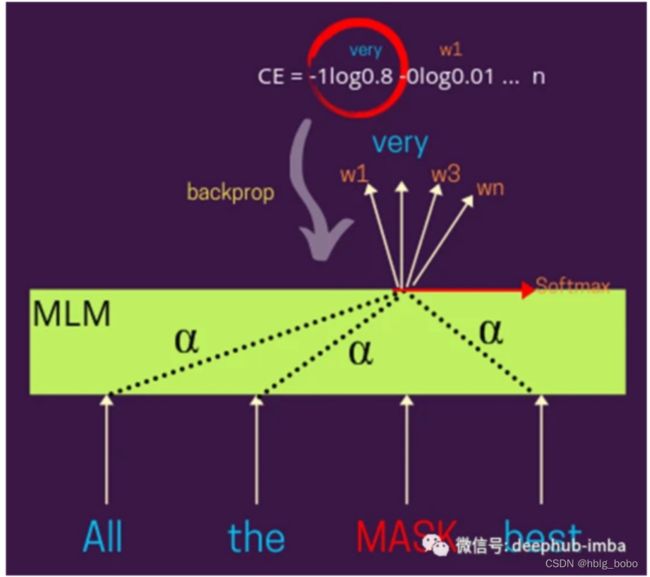
图文匹配 Image-Text Matching
图像-文本匹配可以预测一对图像和文本是正的(匹配)还是负的(不匹配)。使用多模态编
码器的输出嵌入的[CLS] token作为图像-文本对的联合表示,并附加一个全连接(FC)层,
然后是softmax来预测一个两类概率

其中, yitem是一个表示ground truth标签的二维one-hot向量。
动量蒸馏
Momentum Distillation to Learn from Noisy Image-Text Pairs
文本可能包含与图像无关的单词,或者图像可能包含文本中没有描述的实体。对于ITC学习,图像的负样本文本也可能与图像的内容相匹配。对于MLM,可能存在其他与描述图像相同(或更好)的标注不同的词。然而,ITC和MLM的one-hot标签会惩罚所有负标签预测,不管它们的正确性如何。为了解决这个问题,作者提出从动量模型生成的伪目标中学习。动量模型是一个连续发展的教师模型,它由单模态和多模态编码器的指数移动平均版本组成。在训练过程中,训练基础模型,使其预测与动量模型的预测相匹配


代码运行:
环境要求:
pytorch 1.8.0
transformers 4.8.1
timm 0.4.9
跨模态检索finetune
下载 MSCOCO or Flickr30k 数据集
下载json标注文件.(https://storage.googleapis.com/sfr-pcl-dataresearch/ALBEF/data.tar.gz)
修改配置文件In configs/Retrieval_coco.yaml or configs/Retrieval_flickr.yaml, 修改 图像路径以及json文件路径.
使用预训练的权重对下游跨模态检索数据集进行finetune,根据显卡数量修改--
npro_per_node,同时根据显存大小修改.yaml中的batch size