NeurIPS 2021-《ALBEF》-先对齐再融合
【写在前面】
大规模的视觉和语言表征学习在各种视觉语言任务上显示出了良好的提升。现有的方法大多采用基于Transformer的多模态编码器来联合建模视觉token和单词token。由于视觉token和单词token不对齐,因此多模态编码器学习图像-文本交互具有挑战性。在本文中,作者引入了一种对比损失,通过在跨模态注意前融合(ALBEF)来调整图像和文本表示,从而引导视觉和语言表示学习 。
与大多数现有的方法不同,本文的方法不需要边界框标注或高分辨率的图像。为了改进从噪声web数据中学习,作者提出了动量蒸馏,这是一种从动量模型产生的伪目标中学习的自训练方法。作者从互信息最大化的角度对ALBEF进行了理论分析,表明不同的训练任务可以被解释为图像-文本对生成视图的不同方式。ALBEF在多个下游的语言任务上实现了SOTA的性能。在图像-文本检索方面,ALBEF优于在相同数量级的数据集上预训练的方法。在VQA和NLVR2上,ALBEF与SOTA的技术相比,实现了2.37%和3.84%的绝对性能提升,同时推理速度更快。
1. 论文和代码地址

Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
论文地址:https://arxiv.org/abs/2107.07651
代码地址:https://github.com/salesforce/A
2. Motivation
视觉语言预训练(VLP)旨在从大规模图像文本对中学习多模态表示,从而改进下游的视觉语言(V+L)任务。大多数现有的VLP方法(如LXMERT,UNITER,OSCAR)都依赖于预训练过的目标检测器来提取基于区域的图像特征,并使用多模态编码器将图像特征与单词token进行融合。多模态编码器被训练来解决需要共同理解图像和文本的任务,如掩蔽语言建模(MLM)和图像-文本匹配(ITM)。
这个VLP框架虽然有效,但也存在几个关键的限制:
(1)图像特征和词嵌入位于它们自己的空间中,这使得多模态编码器学习建模它们的交互具有挑战性;
(2)目标检测器标注成本高,计算成本高,因为它在预训练需要边界框标注,在推理过程中需要高分辨率(例如600×1000)图像;
(3)广泛使用的图像-文本数据集是从web中收集而来的,具有固有的噪声,现有的预训练目标如MLM可能会过度适应噪声文本,降低模型的泛化性能。
作者提出了 ALign BEfore Fuse(ALBEF) ,这是一个新的VLP框架来解决这些限制。作者首先用一个无检测器的图像编码器和一个文本编码器独立地对图像和文本进行编码。然后利用多模态编码器,通过跨模态注意,将图像特征与文本特征进行融合。作者在单模态编码器的表示上引入了一个中间的图像-文本对比(ITC)损失,它有三个目的:
(1)它将图像特征和文本特征对齐,使多模态编码器更容易执行跨模态学习;
(2)它改进了单模态编码器,以更好地理解图像和文本的语义;
(3)它学习了一个通用的低维空间来嵌入图像和文本,这使图像-文本匹配目标能够通过对比hard negative挖掘找到信息更丰富的样本。
为了改进在噪声监督下的学习,作者提出了动量蒸馏(MoD) ,使模型能够利用一个更大的web数据集。在训练过程中,作者通过取模型参数的移动平均来保持模型的动量版本,并使用动量模型生成伪目标作为额外的监督。对于MoD,该模型不会因为产生其他不同于web标注的合理输出而受到惩罚。作者证明,MoD不仅改进了预训练的任务,而且还改进了具有干净标注的下游任务。
此外,作者从互信息最大化的角度为ALBEF提供了理论论证。具体地说,作者证明了ITC和MLM最大化了图像-文本对不同视图之间互信息的下界,其中视图是通过从每对图像中获取部分信息而生成的。从这个角度来看,动量蒸馏可以被解释为使用语义上相似的样本生成新的视图。因此,ALBEF学习了语义不变的视觉语言表示。
3. 方法
3.1 Model Architecture
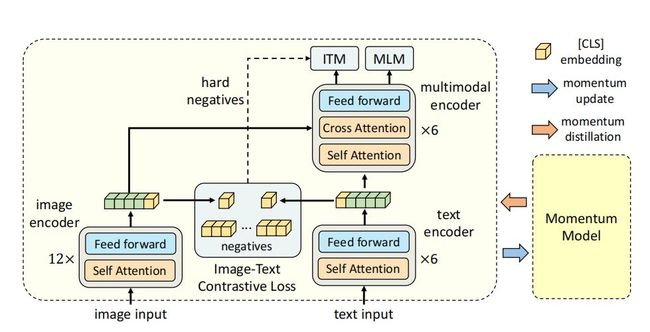
如上图所示,ALBEF包含一个图像编码器、一个文本编码器和一个多模态编码器。作者使用一个12层的视觉Transformer ViT-B/16作为图像编码器,并使用在ImageNet-1k上预训练的权重来初始化它。一个输入图像I被编码到一个嵌入序列中:{vcls,v1,…,vN},其中vcls是[CLS] token的嵌入。
作者对文本编码器和多模态编码器都使用了一个6层的Transformer。文本编码器使用BERT base模型的前6层进行初始化,多模态编码器使用BERT Base模型的最后6层进行初始化。文本编码器将输入文本T转换为嵌入序列{wcls,w1,…,wN},并输入多模态编码器。通过在多模态编码器的每一层进行交叉注意力,将图像特征与文本特征融合。




在上图中,作者展示了来自伪目标的前5个候选对象的示例,它们有效地捕获了图像的相关单词/文本。
此外,作者还将MoD应用于下游任务。每个任务的最终损失是原始任务的损失和模型的预测和伪目标之间的kl散度的加权组合。为简单起见,作者为所有预训练和下游任务设置了权重α=0.4。



5.实验
5.1. Evaluation on the Proposed Methods
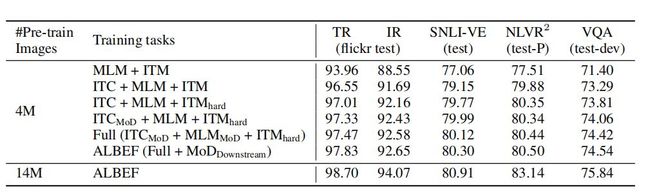
上表显示了本文方法的不同变体的下游任务的性能。与baseline预训练任务(MLM+ITM)相比,添加ITC大大提高了预训练模型的性能。所提出的 hard negative挖掘通过寻找信息更丰富的训练样本来改进ITM。添加动量蒸馏可以改进ITC(第4行)、MLM(第5行)和所有下游任务(第6行)的学习能力。
5.2. Evaluation on Image-Text Retrieval
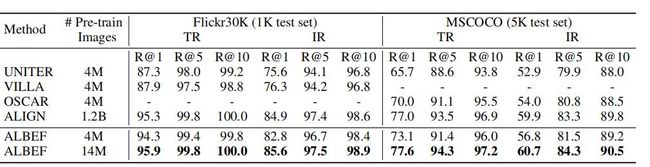
上表展示了图文检索fine-tuning的实验结果。
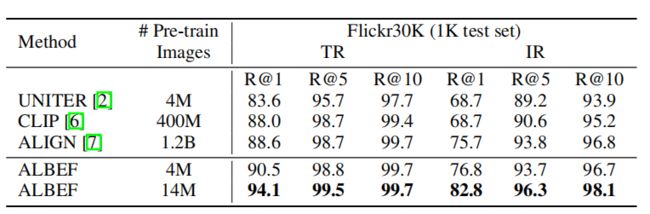
上表展示了图文检索Zero-shot的实验结果。
5.3. Evaluation on VQA, NLVR, and VE
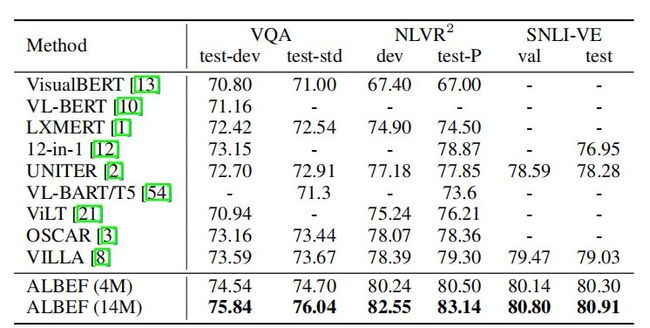
上表展示了本文方法和其他方法在其他下游任务上的实验结果对比。
5.4. Weakly-supervised Visual Grounding
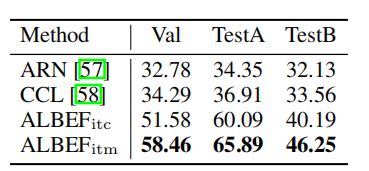
上表展示了本文方法弱监督visual grounding的结果。

上图展示了在多模态编码器的第三层的交叉注意图上的Grad-CAM可视化。

上图展示了在VQA模型的多模态编码器的交叉注意图上的Grad-CAM可视化。

上图展示了与单个单词对应的交叉注意图上的Grad-CAM可视化。
5.5. Ablation Study
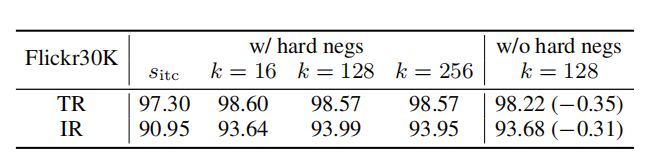
上表研究了不同的设计选择对图像-文本检索的影响。
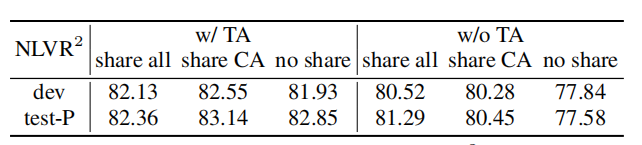
表7研究了文本赋值(TA)预训练和参数共享对NLVR2的影响。
6. 总结
本文提出了一种新的视觉语言表示学习框架ALBEF。ALBEF首先对齐单模态图像表示和文本表示,然后将它们与多模态编码器融合。作者通过理论和实验验证了提出的图像文本对比学习和动量蒸馏的有效性。与现有的方法相比,ALBEF在多个下游V+L任务上提供了更好的性能和更快的推理速度。
虽然本文在视觉语言表示学习方面显示了很好的结果,但在实践中部署它之前,对数据和模型进行额外的分析是必要的,因为网络数据可能包含意想不到的私人信息、不合适的图像或有害的文本,而且只优化准确性可能会产生不必要的社会影响。