Deep Match to Rank Model for Personalized Click-Through Rate Prediction
Abstract
点击率(CTR)预测是推荐系统和许多其他应用领域的核心任务。对于CTR预测模型来说,个性化是提高性能和增强用户体验的关键。近年来,人们提出了几种模型来从隐含(implicitly)反映用户个性化偏好的用户行为数据中提取用户兴趣。然而,现有的CTR预测研究主要集中在用户表示(user representation )上,而较少关注用户与项目之间的相关性,这直接衡量了用户对目标项目的偏好程度。基于此,我们提出了一个新的模型,称为深度匹配到排名(DMR Deep Match to Rank),该模型将协同过滤的思想结合到匹配方法中,用于CTR预测中的排名任务。在DMR中,我们设计了用户到项目网络(User-to-Item Network)和项目到项目( Item-to-Item Network)网络,以两种形式表示相关性。在用户到项目网络中,我们通过嵌入空间中相应表示的内积来表示用户和项目之间的相关性。同时,提出了一个辅助匹配网络(auxiliary match network)来监督训练,并推动更大的内积来代表更高的相关性。在项目到项目网络中,我们首先通过注意机制计算用户交互项目和目标项目之间的项目到项目相似性,然后将相似性进行汇总,以获得另一种形式的用户到项目关联。我们在公共数据集和工业数据集上进行了大量实验,以验证我们的模型的有效性,该模型显著优于最先进的模型。
Introduction
匹配和排序(Matching and ranking)是推荐系统中信息检索的两个经典阶段。在匹配阶段,aka。候选项生成,通过将用户与项目匹配,从整个项目集中检索一小部分候选项。基于协同过滤的方法被广泛用于计算用户与项目的相关性并选择最相关的项目。在排名阶段,排名模型为通过不同匹配方法生成的候选人分配可比分数,并将前N个评分项目呈现给最终用户。在推荐系统中,用户点击是一个非常重要的评价指标,点击率(CTR)预测受到了学术界和工业界的广泛关注。
个性化是提高CTR预测性能、增强用户体验的关键。许多基于深度学习的方法被提出用于CTR预测,这些方法可以学习隐式特征交互,增强模型的能力。这些方法大多注重为自动特征交互设计网络结构(Cheng等人,2016年;He and Chua 2017年;Wang等人,2017年)。最近,有人提出了几种模型来从点击和购买等用户行为数据中提取用户兴趣(Zhou et al.2018;2019),这对于用户没有明确表示兴趣的推荐设置非常重要。为了表示用户兴趣,考虑了用户交互项和目标项之间的项对项关联。然而,这些模型主要侧重于用户表示,而忽略了表示用户与项目的相关性。用户对项目的相关性直接衡量用户对目标项目的个性化偏好,这在基于协同过滤的匹配方法中得到了仔细的建模。
基于这些观察结果,我们提出了一种称为深度匹配排名(Deep Match to Rank,DMR)的新模型,该模型在匹配方法中使用协同过滤的思想来捕获用户与项目的相关性,从而提高了CTR预测的性能。用户到项目网络和项目到项目网络是DMR中分别代表用户到项目相关性的两个子网络。在用户到项目网络中,我们通过嵌入空间中相应表示的内积直接计算用户和项目之间的相关性,其中用户表示是从用户行为中提取的。考虑到最近的行为更好地反映了用户的时间兴趣,我们应用注意机制自适应地学习每个行为相对于其在行为序列中的位置的权重。同时,我们提出了一个辅助匹配网络,以推送更大的内积来表示更高的相关性,并帮助用户更好地适应项目网络。单独的辅助匹配网络可以看作是一种匹配方法,其任务是根据用户的历史行为预测下一步点击哪个项目,并在DMR中联合训练匹配模型和排名模型。在Item-to-Item网络中,我们首先通过同时考虑位置信息的注意机制计算用户交互项目和目标项目之间的项目间相似性。然后我们将项目之间的相似性相加,以获得另一种形式的用户-项目相关性。请注意,在匹配阶段,为了满足用户需求的多样性,通常会通过多种匹配方法生成候选项,并且不同方法之间的用户与项目相关性得分不具有可比性。在DMR中,相关性的强度可以以统一的方式相互比较。
本文的主要贡献如下:
•我们指出了捕捉用户和项目之间相关性的重要性,这可以使CTR预测模型更加个性化和有效。基于此,我们提出了一个称为DMR的新模型,该模型将协同过滤的思想应用于匹配方法中,分别表示与用户到项目网络和项目到项目网络的相关性
我们设计了辅助匹配网络,将其视为一个匹配模型,以帮助更好地训练用户到项目网络。据我们所知,DMR是第一个在CTR预测中联合训练匹配和排名的模型.。
考虑到最近的行为对用户的时间兴趣贡献更大,我们在注意机制中引入位置编码,以自适应地学习每个行为的权重我们在公共数据集和工业数据集上进行了广泛的实验,结果表明,与最先进的模型相比,DMR有了显著的改进。我们的代码1公开可用于再现性。
代码1:
GitHub - lvze92/DMR: Deep Match to Rank Model for Personalized Click-Through Rate Prediction
Related Work
近年来,基于深度学习的CTR预测模型受到了广泛关注,并取得了显著的效果。与传统的线性模型相比,基于深度学习的方法可以提高模型的性能,并通过非线性变换学习隐式特征交互。通过从高维稀疏特征中学习低维表示,深度模型可以更好地估计很少出现的特征组合(Cheng等人,2016)。
然而,稀疏特征的大维数在实际应用中带来了巨大的挑战:深层模型可能会过度拟合和过度泛化。在此基础上,提出了不同的模型,以改善模型特征交互,提高CTR预测的性能。Wide&Deep(Cheng et al.2016)通过联合训练结合了线性模型和非线性深度模型的优点。深度交叉(Deep Crossing)(Shan等人,2016年)应用深度残差网络( deep residual network)来学习交叉特征。PNN(Qu等人,2016)引入了乘积(product)层和完全连接的层,以探索高阶功能交互。基于可以模拟二阶特征交互的因子分解机(FM)(Rendle 2010),AFM(Xiao et al.2017)通过注意机制学习加权特征交互(Bahdanaau、Cho和Bengio 2015)。DeepFM(郭等人,2017)和NFM(他和蔡2017)通过将FM应用于深度网络,将低阶和高阶特征交互结合起来。DCN(Wang et al.2017)引入交叉网络来学习某些有限度特征交互。在我们提出的DMR中,用户与项目相关性的表示可以被视为用户与项目之间的一种特征交互。
与搜索排名不同的是,在推荐系统和许多其他应用中,用户并没有清楚地表达他们的意图。因此,从用户行为中捕捉用户兴趣对于CTR预测至关重要,而上述模型对此关注较少。可变长度的用户行为特征通常通过简单的平均池(average pooling)(Covington、Adams和Sargin 2016)转化为固定长度向量,这意味着所有行为都同等重要。DIN(Zhou et al.2018)通过加权和池来表示用户兴趣,改进了这一点,其中每个用户行为相对于目标项目的权重通过注意机制自适应学习。DIEN(Zhou等人,2019年)不仅提取用户兴趣,还对兴趣的时间演变进行建模。DSIN(Feng等人,2019年)利用行为序列中的会话信息来模拟兴趣的演变。在我们的模型中,受Transformer(Vaswani et al.2017)的启发,我们将位置编码引入注意机制,以捕捉用户的暂时兴趣。尽管取得了很大的进展,但这些方法侧重于用户表示,而忽略了表示用户与项目的相关性,这直接衡量了用户对目标项目的偏好程度。在所提出的DMR中,我们注意表示用户对项目的相关性,以提高个性化CTR模型的性能。
基于协同过滤(CF)的方法在匹配阶段非常成功地构建了推荐系统(Su和Khoshgoftaar,2009)。在这些方法中,项对项CF(Sarwar et al.2001;Linden,Smith和York 2003)由于其可解释性和实时个性化的效率,已被广泛应用于工业推荐设置中。通过预先计算项目之间的相似性矩阵,向用户推荐与用户单击的项目相似的项目。为了计算项目间的相似性,早期的工作主要集中在统计指标上,如余弦相似性和皮尔逊系数。He等人(2018年)提出了基于深度学习的方法NAIS,用于项对项CF,并采用注意机制来区分用户行为的不同重要性,这与DIN(Zhou等人,2018年)的观点类似。与item-to-item CF不同,基于矩阵分解的CF方法(Koren 2008;Koren,Bell和Volinsky 2009)通过缩减空间中相应表示的内积直接计算用户和项目之间的相关性。基于相似的内积形式,提出了基于深度学习的方法,从用户的历史行为中学习用户表示,这可以看作是因子分解技术的非线性推广。Covington、Adams和Sargin(2016)将 pose matching 作为极端多重分类,其中预测问题将根据用户的历史行为对用户下一步单击的项目进行准确分类。Hidasi等人(2016年)将GRU(Cho等人,2014年)应用于基于会话的建议任务。TDM(Zhu et al.2018)使用基于树的方法来超越基于内积的方法。在我们的模型中,一方面,我们使用用户表示和项目表示之间的内积来获得一种用户到项目的相关性;另一方面,我们应用注意机制来表示项与项之间的相似性,并进一步获得另一种用户与项之间的相关性。
Deep Match to Rank Model
在这一部分中,我们详细介绍了深度匹配排名(DMR)模型的设计。首先,我们从特征表示和多层感知器两个方面概述了基于深度学习的CTR模型的基本结构。然后,我们介绍了DMR的总体结构和两个子网络,以建模用户与项目的相关性。
Feature Representation
我们的推荐系统有四类特征:User Profile, User Behavior, Target Item and Context. 。User Profile包含用户ID、消费级别等信息;Target Item中的特征包括项目ID、类别ID等。;User Behavior是用户交互项目的顺序列表,具有相应的特征,如项目ID、类别ID等。;Context包括时间、匹配方法和相应的匹配分数corresponding matching score等。
大多数特征是分类的,可以转化为一个高维的热向量。在基于深度学习的模型中,通过嵌入层将独热向量转化为低维密集特征。例如,项ID的嵌入矩阵可以用V=[v1;v2;…;vK]表示∈ RK×dv,其中K是不同项目的总数,vj∈ Rdv是第j项的维数为dv的嵌入向量。嵌入层不需要独热向量和嵌入矩阵之间复杂的矩阵乘法,通过查表得到嵌入向量。
分类特征的嵌入向量和来自用户配置文件、用户行为、目标项和上下文的规范化连续特征的串联分别形成特征向量xp、xb、xt、xc。特别是,用户行为包含多个项目,相应的特征向量是一个特征向量列表,由xb=[e1;e2;…;eT]表示∈ RT×de,其中表示t-th行为特征向量的et是多个特征向量的串联,de是et的维数,T是用户行为的长度。请注意,对于每个用户,行为的数量是不同的,T是可变的。用户行为和目标项在相同的特征空间中,共享相同的嵌入矩阵,以减少存储空间。
Multiple Layer Perceptron (MLP)
将所有特征向量连接起来,形成实例的完整表示,然后将其输入到具有完全连接层的MLP中。隐藏层由PRelu(He等人2015)激活,最终输出层由二元分类任务的sigmoid函数激活。MLP的输入长度需要固定,因此需要通过池层将用户行为xb的特征向量列表转换为固定长度的特征向量。交叉熵损失函数与sigmoid函数一起被广泛使用,其对数分量可以抵消sigmoid函数中指数的副作用。输入特征向量x的损失=[xp,xb,xt,xc],然后单击标签y∈ {0,1}是:

The structure of Deep Match to Rank
基于深度学习的CTR模型的基本结构很难通过内隐特征交互来获取用户与项目的相关性。在DMR中,我们提出了两个子网络,即用户对项目网络和项目对项目网络来建模用户对项目的相关性,这可以提高个性化CTR模型的性能。DMR的结构如图1所示。

User-to-Item Network
用户到项目网络遵循基于矩阵分解的匹配方法中的表示形式,通过对应表示的内积直接建模用户与目标项目之间的相关性,可以将其视为用户与项目之间的一种特征交互。
为了获得用户表示,我们求助于用户行为特征。用户在推荐设置中没有明确地表现出兴趣,而用户行为隐含地反映了用户的兴趣。表示用户兴趣的一种简单方法是在用户行为特征上使用平均池,它认为每个行为对最终用户兴趣的贡献是相等的。然而,用户兴趣可能会随着时间的推移而变化,最近的行为更能反映用户的暂时兴趣。根据发生的时间为每个行为分配权重可以缓解问题,但也很难找到最佳权重。
在用户到项目网络中,我们采用位置编码的注意机制作为查询(query),自适应地学习每个行为的权重,其中用户行为的位置是按发生时间排序的行为序列中的序列号。公式如下:


下面是关于注意力网络的三个细节,为了简化,我们在方程式中省略了这些细节。首先,可以添加更多隐藏层以获得更好的表示。其次,除了位置编码之外,还可以向注意网络中添加更多反映用户兴趣强度的上下文特征,例如行为类型、停留时间等。在我们的应用中,位置对权重的影响最大。第三,位置按行为时间的相反顺序编码,以确保最近的行为获得第一个位置。
目标项目代表v‘∈ Rdv直接从嵌入矩阵V中查找?=[v’1;v‘2;…;v’K]∈ RK×dv。V'是针对目标项的单独嵌入矩阵,不与针对用户行为和目标项的输入特征的嵌入矩阵V共享嵌入。为了区分这两个嵌入矩阵,我们把V称为输入表示,把V‘目标项的输出表示,如图1所示。通过这种方式,虽然增加了内存空间,但与共享嵌入时仅将嵌入大小增加一倍相比,该模型更具表现力。我们将在下面的实验部分验证这一结论。
使用用户表示u和目标项表示v’,我们应用内积运算来表示用户与项目的相关性:
![]()
我们希望较大的r代表更强的相关性,从而对点击预测产生积极影响。然而,从反向传播的角度来看,仅通过点击标签的监督来确保这一点并不容易。此外,嵌入矩阵V‘中参数的学习完全依赖于唯一的相关单元r,在此基础上,我们提出了一个辅助匹配网络,该网络从用户行为中引入标签来监督用户对项目网络的学习。
辅助匹配网络的任务是根据之前的T-1个行为预测第T个行为,这是一项极端的多分类任务。按照用户表示u的形式,我们可以得到前T-1个行为的用户表示,记为uT−1.∈ Rdv。在前T-1的行为下,用户点击项目j的概率可用softmax函数表示为:

然而,计算公式(6)中pj的成本是巨大的,与项目总数K成正比。为了有效地训练这样一个具有数百万类的分类任务,我们采用了负采样技术(Mikolov等人,2013),从背景分布中采样负例。我们将负采样的辅助匹配网络损耗定义为:

通过从用户行为中引入标签,辅助匹配网络可以推动更大的r来表示更强的相关性,并帮助更好地训练嵌入矩阵V’及其他参数。理解用户到项目网络的另一种方法是,在统一模型中联合训练排名模型和匹配模型,其中匹配方法是辅助匹配网络。在匹配阶段,通过多种分数不可比的匹配方法生成候选对象,每个候选对象只具有相应匹配方法的相关性分数。与仅将匹配分数作为特征输入MLP不同,用户到项目网络能够获得给定任意目标项目的用户到项目相关性分数,并且相关性以统一的方式进行比较。
Item-to-Item Network
除了直接计算用户对项目的相关性外,我们还提出了项目对项目网络来间接表示相关性。我们首先对用户交互项和目标项之间的相似性进行建模,然后对它们进行总结,以获得另一种用户-项目相关性。为了使关联表示更具表现力,我们使用用户到项目网络中使用的内积以外的注意机制来建模项目到项目的相似性。以用户交互项、目标项和位置编码作为输入,项与项的相似性公式如下:

Experiments
在本节中,我们将介绍在公共数据集和工业数据集上进行的实验。首先,我们给出了数据集和比较方法。接下来,我们展示了DMR的实验结果,并与最新的方法进行了比较。此外,我们还对DMR进行了消融研究,以验证我们提出的技术的有效性。
Datasets
Public Dataset 包含8天内从淘宝随机抽取的广告显示和点击日志。它包含2600万条日志,114万用户和84万条项目。前7天的日志用于训练组,最后一天的日志用于测试组。
Industrial Dataset我们从阿里巴巴的在线推荐系统3收集印象和点击日志,形成行业数据集。我们使用前14天的日志作为训练集,第二天的日志作为测试集。整个数据集包含11.8亿个示例,1090万用户和4860万项目。
2https://tianchi.aliyun.com/dataset/dataDetail?dataId=56
3https://www.1688.com
Compared Methods
•LR逻辑回归(LR)是一个经典的线性模型,可以被视为一个浅层神经网络。线性模型通常需要手动特征工程才能更好地执行。在这里,我们添加了用户行为和目标项目的叉积
Wide&Deep(Cheng et al.2016)Wide&Deep有一个宽部分和一个深部分,它结合了线性模型和非线性深度模型的优点以及联合训练。我们的实施范围与上述LR相同
PNN(Qu et al.2016)PNN(Qu et al.2016)引入了product层和完全连接的层,以探索高阶功能交互
DIN(Zhou等人,2018年)DIN通过自适应学习注意力权重,代表用户对目标项目的兴趣。注意,如果没有两个用户到项目的相关性和位置编码的使用,我们的模型几乎变成了DIN模型
DIEN(Zhou等人,2019年)DIEN通过两层GRU对目标项目的用户兴趣演变进行建模。
Results on Public and Industrial Datasets
在公共数据集上的实验中,我们将学习率设置为0.001,批量大小设置为256,项目嵌入大小设置为32,用户行为序列的最大长度设置为50。MLP中隐藏层的维数分别为512、256和128。此外,辅助匹配网络中的阴性样本数设置为2000,辅助损失β的权重设置为0.1。在工业数据集上的实验中,除了将项目嵌入大小设置为64外,超参数几乎与上述相同。
表1显示了公共数据集和工业数据集的比较结果。我们使用ROC下的面积(AUC)作为评估指标,这在二元分类问题中被广泛使用。所有实验重复5次,并报告平均结果。

LR的性能明显低于Wide&Deep和其他基于深度学习的模型,这表明了深度神经网络中非线性变换和高阶特征交互的有效性。PNN得益于product层,比宽与深更好地实现了特征交互和预成型(Preform)。
在用户没有明确表示兴趣的推荐设置中,捕获用户兴趣非常重要。在基于深度学习的模型中,Wide&deep和PNN表现最差,尤其是在工业数据集上,这证明了从用户行为中提取用户兴趣的重要性。DIN代表用户对目标项目的兴趣,但忽略了用户行为中的顺序信息。DIEN的性能优于DIN,这主要归功于两层GRU结构,它捕捉到了用户交互的演变。
基于用户兴趣表示,DMR进一步以用户对项目网络和项目对项目网络两种形式捕获用户对项目的相关性。DMR通过相关性表示,充分考虑了用户对目标项目的个性化偏好,显著优于所有比较方法,包括LR、Wide&Deep、PNN、DIN和DIEN。
Ablation Study
在本节中,我们对DMR进行消融研究,以验证我们提出的技术的有效性。表2给出了公共数据集和工业数据集上不同成分的DMR的比较结果。

Effectiveness of User-to-Item Relevance Representation
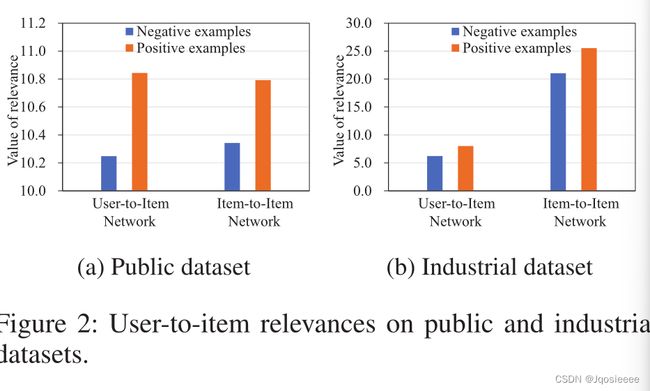
为了使表示更具表现力,我们应用不同的操作来建模用户与项目的相关性。用户对项目网络使用基于内积的操作,项目对项目网络使用注意网络来计算相关性。从表2可以看出,两个子网络的组合比单独使用表现更好,这表明了两种不同类型的用户对项目关联的有效性,并且两种形式的用户对项目关联是互补的,而不是冗余的。我们探讨了公共数据集和工业数据集上两种用户对项目关联的价值,如图2所示。这些值分别在正例和负例上取平均值。正如预期的那样,正面例子的用户与项目的相关性高于负面例子,这意味着我们关于用户与项目相关性的模型是合理的。
Effectiveness of Auxiliary Match Network
从表2可以看出,DMR比没有辅助匹配网络的DMR获得更好的性能。辅助匹配网络从用户行为引入标签来监督训练,并在用户表示和项目表示之间推送更大的内积来表示更高的相关性。图3显示了DMR在公共和工业数据集上的学习曲线。我们可以看到,目标损耗Ltarget和辅助损耗LNS一起降低,这意味着匹配和排名的联合训练有效。

用户到项目网络使用额外的嵌入矩阵V'来表示目标项目,可以将其视为辅助匹配网络softmax层的参数。我们尝试将项目的嵌入大小增加一倍,并共享嵌入以获得DMR double,其参数数量与DMR相同。如表2所示,我们观察到DMR的性能优于DMR Double,这验证了单独嵌入矩阵的有效性。
Effectiveness of Positional Encoding
如表2所示,在用户到项目的网络中,DMR比没有位置编码的DMR性能更好。通过位置编码,DMR考虑用户行为序列中的序列信息,提取用户的时间兴趣。在工业数据集上,在用户到项目网络中没有位置编码的DMR比没有整个用户到项目网络的DMR性能更差,这意味着没有位置编码的用户到项目网络很难适应。
我们研究了用户行为序列中不同位置的注意权重。图4显示了公共数据集和工业数据集上项目对项目网络的平均权重。虽然注意力权重受到多个因素的影响,但总体趋势是,最近的行为会像预期的那样获得更高的激活权重,尤其是在工业数据集上。

Results from Online A/B Testing
我们在阿里巴巴的推荐系统中进行在线A\/B测试。与DIN相比,DMR将CTR提高了5.5%,每个用户的点击率提高了12.8%,DIN是我们系统中CTR模型的最新版本。基于重大的推广,我们已部署DMR在线服务的建议。
Conclusions
在个性化CTR预测领域,提出了一种新的深度匹配排名(DMR)模型,以获取用户和项目之间的相关性。受匹配方法中协同过滤思想的启发,DMR分别使用用户到项目网络和项目到项目网络来建模用户到项目的相关性。提出了一种辅助匹配网络,以帮助更好地训练用户到项目网络。据我们所知,DMR是第一个在CTR预测中联合训练匹配和排名的模型。此外,在两个子网络中引入位置编码来模拟用户的时间兴趣。DMR显著提高了性能,并已部署在我们阿里巴巴的在线推荐系统中。