2022.11.27 第10次周报
目录
- 摘要
- 深度学习(RNN推导)
-
- 1. RNN特点
- 2. 前向传播
- 3. 反向传播
- 4. 举例
- 5. RNN缺点
- 文献阅读
-
- 1.摘要
- 2.贡献
- 3.背景
- 4.PTMs概述
-
- 4.1 PTMs的分类
- 4.2 模型分析
- 5.PTMs的扩展
- 6. 使PTMs适应下游任务
- 7. 应用
- 8. 未来方向
- 9. 结论
- 总结
摘要
This week, I learnt about RNNs and understood the mathematical derivation of their forward propagation, loss functions and back propagation. In addition, I studied a review on pre-trained models for natural language processing. The article describes the history, concepts, extensions, applications and future directions of PTMs for NLP.
本周,我学习了RNN,了解了其前向传播、损失函数以及反向传播的数学推导过程。另外,我还学习了一篇关于自然语言处理的预训练模型的一个综述,文章介绍了用于NLP的PTMs的历史、概念、扩展、应用以及未来方向等。
深度学习(RNN推导)
1. RNN特点
1、串联结构,体现出“前因后果”,后面结果的生成,要参考前面的信息
2、所有特征共享同一套参数:面对不同的输入(两个方面),能学到不同的相应结果;极大减少了训练参数量;输入和输出数据在不同例子中可以有不同的长度
2. 前向传播


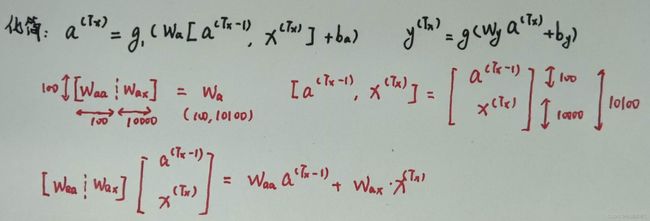

3. 反向传播

4. 举例


当0
梯度消失解决办法:LSTM
梯度爆炸解决办法:梯度修剪,意思就是观察梯度向量,如果它大于某个阈值,缩放梯度向量,保证它不会太大,这是比较鲁棒的办法。
5. RNN缺点
当【序列太长】时,容易导致【梯度消失】,参数更新只能捕捉到局部依赖关系,没法再捕捉序列之间的【长期】关联或者依赖关系
举例:The cat, which ate already, …, was full.
该句子最后面是用was还是were,取决于前面是cat还是cats,但是一旦中间的这个which句子很长,cat的信息根本传不到was这里。对was的更新没有任何帮助,这是RNN一个很大的不足之处。
文献阅读
论文题目:Pre-trained models for natural language processing: A survey
地址:https://linkspringer.53yu.com/article/10.1007/s11431-020-1647-3
1.摘要
最近,预训练模型(PTMs)的出现将自然语言处理(NLP)带入了一个新时代。在这次调查中,我们对NLP的PTMs进行了全面的回顾。我们首先简要地介绍了语言表征学习及其研究进展。然后,我们根据分类法从四个不同的角度对现有的PTMs进行了系统的分类。接下来,我们描述了如何使PTMs的知识适应下游的任务。最后,我们概述了PTMs在未来研究中的一些潜在方向。这项调查旨在成为理解、使用和开发各种NLP任务的PTMs的实践指南。
2.贡献
1.全面审查。对NLP的PTMs进行了全面的回顾,包括背景知识,模型架构,预训练任务,各种扩展,改编方法和应用。
2.新的分类法。提出了用于NLP的PTMs分类法,该分类法从四个不同的角度对现有PTMs进行了分类:1)表示类型,2)模型体系结构; 3)预训练任务的类型; 4)特定类型场景的扩展。
3.丰富的资源。收集了有关PTMs的大量资源,包括PTMs的开源实现,可视化工具,语料库和论文清单。
4.未来方向。讨论并分析现有PTMs的局限性,另外,建议了未来可能的研究方向。
3.背景
为什么要进行预训练?
随着深度学习的发展,模型参数的数量迅速增加。需要更大的数据集来完全训练模型参数并防止过度拟合。但是,由于注释成本极其昂贵,因此对于大多数NLP任务而言,构建大规模的标记数据集是一项巨大的挑战,尤其是对于语法和语义相关的任务。
相反,大规模的未标记语料库相对容易构建。为了利用巨大的未标记文本数据,我们可以首先从它们中学习良好的表示形式,然后将这些表示形式用于其他任务。最近的研究表明,借助从大型无注释语料库中的PTMs提取的表示形式,可以在许多NLP任务上显着提高性能。
预训练的优势可以归纳如下:
1.在庞大的文本语料库上进行预训练可以学习通用的语言表示形式并帮助完成下游任务。
2.预训练提供了更好的模型初始化,通常可以带来更好的泛化性能并加快目标任务的收敛速度。
3.可以将预训练视为一种正则化,以避免对小数据过度拟合。
4.PTMs概述
4.1 PTMs的分类

为了阐明NLP的现有PTMs的关系,这里建立了PTMs的分类法,从四个不同的角度对现有PTMs进行了分类:
1.表示类型:根据用于下游任务的表示,我们可以将PTMs分为非上下文和上下文楷模。
2.体系结构:PTMs使用的骨干网,包括LSTM,Transformer编码器,Transformer解码器和完整的Transformer体系结构。 “变压器”是指标准的编码器-解码器体系结构。 “ Transformer编码器”和“ Transformer解码器”分别表示标准Transformer体系结构的编码器和解码器部分。它们的区别在于,解码器部分使用带有三角矩阵的蒙版自我注意来防止令牌进入其未来(正确)位置。
3.预训练任务类型:PTMs使用的预训练任务的类型。
4.扩展:针对各种场景而设计的PTMs,包括知识丰富的PTMs,多语言或语言特定的PTMs,多模型PTMs,特定领域的PTMs和压缩的PTMs。
上图显示了分类法以及一些相应的代表性PTMs。此外,下表更详细地区分了一些代表性的PTMs。

4.2 模型分析
由于PTMs的巨大成功,重要的是要了解PTMs捕获了哪些知识,以及如何从PTMs中获取知识。大量文献分析了存储在预训练的非上下文和上下文嵌入中的语言知识和世界知识。
5.PTMs的扩展
文章提到了多个PTMs的扩展,主要分为知识丰富的PTMs、多语言和特定语言的PTMs、多模式PTMs、特定领域和特定任务的PTMs以及模型压缩。
知识丰富的PTMs: PTMs通常从通用大型文本语料库中学习通用语言表示,但是缺少特定领域的知识。将外部知识库中的领域知识整合到PTMs中被证明是有效的。
多语言和特定语言的PTMs: 尽管多语言PTMs在多种语言上表现良好,但最近的工作表明,使用单一语言训练的PTMs明显优于多语言结果。对于没有明确单词边界的中文,建模较大的粒度和多粒度词表示法已显示出巨大的成功。
多模式PTMs: 多语言PTMs、特定语言的PTMs、多模式PTMs、视频文本PTMs、图像文本PTMs以及音频文本PTMs。
特定领域和特定任务的PTMs: 大多数公开可用的PTMs都接受了通用域语料库(例如Wikipedia)的培训,这使它们的应用限于特定域或任务。
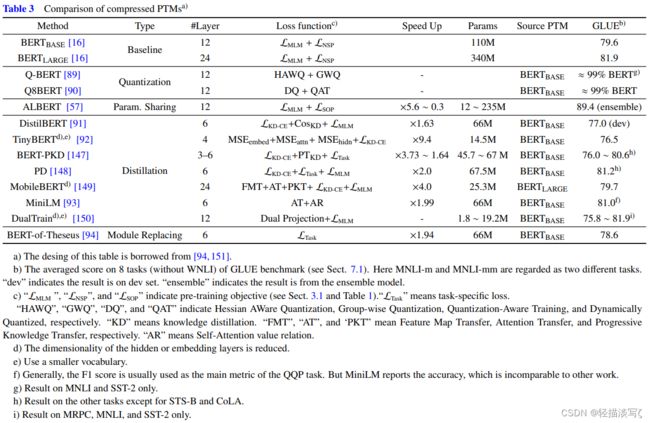
模型压缩: 由于PTMs通常至少包含数亿个参数,因此很难将PTMs部署在实际应用程序中的在线服务和资源受限的设备上。模型压缩是减小模型大小并提高计算效率的潜在方法。
有五种压缩PTMs的方法:(1)模型修剪,删除不重要的参数;(2)权重量化,使用较少的比特表示参数;(3)在相似模型单元之间共享参数;(4)知识提炼,它训练了一个较小的学生模型,该模型从原始模型的中间输出中学习型号;(5)模块更换,从而用更紧凑的替代品替换了原始PTMs的模块。
下表比较了一些代表性的压缩PTMs。
6. 使PTMs适应下游任务
尽管PTMs可以从大型语料库中获取通用语言知识,但是如何有效地将其知识适应下游任务仍然是关键问题。
转移学习
转移学习旨在使知识从源任务(或领域)适应目标任务(或领域)。下图给出了转移学习的示意图。
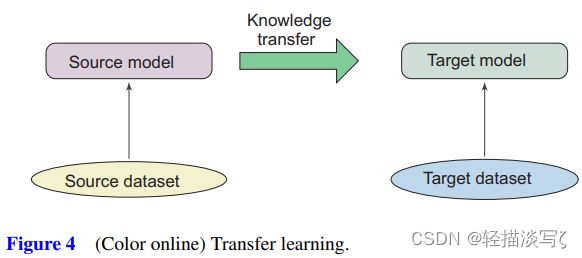
NLP中有很多类型的迁移学习,例如领域适应,跨语言学习,多任务学习。使PTMs适应下游任务是顺序转移学习任务,其中任务是顺序学习的,目标任务已标记数据。
7. 应用
本文总结了PTMs在一些经典的NLP任务中的一些应用:一般评估基准、问答、情感分析、命名实体识别、机器翻译、总结、对抗攻击与防御。
8. 未来方向
尽管PTMs已证明可以胜任各种NLP任务,但是由于语言的复杂性,仍然存在挑战。文中总结了PTMs的五个未来方向。
(1)PTMs的上限目前,PTMs尚未达到上限。当前更多的PTMs可以通过更多的培训步骤和更大的语料库得到进一步改善。通过增加模型的深度,可以进一步提高NLP的技术水平。通用PTMs一直是我们追求学习语言固有的普遍知识(甚至世界知识)的追求,设计更有效的模型架构,自我监督的预-使用现有的硬件和软件来培训任务,优化器和培训技能。
(2)PTMs的体系结构 变压器已被证明是一种有效的预训练架构。但是,变压器的主要局限性在于其计算复杂度,它是输入长度的平方。受GPU内存的限制,当前大多数PTMs不能处理长度超过512个令牌的序列。打破此限制需要改进Transformer的体系结构。因此,为PTMs寻找更有效的模型架构对于捕获更广泛的上下文信息很重要。
(3)面向任务的预训练和模型压缩在实践中,不同的下游任务需要PTMs的不同功能。 PTMs与下游任务之间的差异通常在于两个方面:模型架构和数据分发。更大的差异可能会导致PTMs的收益微不足道。例如,文本生成通常需要特定的任务来预训练编码器和解码器,而文本匹配则需要为句子对设计的预训练任务。
(4)超越微调的知识转移
当前,微调是将PTMs的知识转移到下游任务的主要方法,但缺点是其参数效率低下:每个下游任务都有自己的微调参数。一种改进的解决方案是修复PTMs的原始参数,并为特定任务添加小型的微调适配模块。因此,我们可以使用共享的PTMs服务多个下游任务。
(5)PTMs的可解释性和可靠性 尽管PTMs达到了令人印象深刻的性能,但其深层的非线性体系结构使决策过程变得高度透明。随着PTMs在生产系统中的广泛使用,PTMs的可靠性也成为一个令人关注的问题。对PTMs的对抗攻击的研究可通过充分暴露其漏洞来帮助我们了解其功能。 PTMs的对抗性防御也很有前途,它可以提高PTMs的健壮性并使它们对对抗攻击具有免疫力。
9. 结论
文章对NLP的PTMs进行了全面概述,包括背景知识,模型架构,预训练任务,各种扩展,适应方法,相关资源和应用程序。基于当前的PTMs,文章从四个不同的角度提出了PTMs的新分类法,另外还建议了PTMs的几种可能的未来研究方向。
总结
本周继续学习了循环神经网络,了解了其数学推导过程,对RNN有了进一步的认识,另外,本周学习了自然语言处理的预训练模型的一个综述,了解了PTMs以及其扩展等知识。下周会学习RNN的代码实现。