学习笔记:CLIPstyler: Image Style Transfer with a Single Text Condition 具有单一文本条件的图像风格迁移
[CVPR-2022] CLIPstyler: Image Style Transfer with a Single Text Condition 具有单一文本条件的图像风格迁移
- 摘要
- 1. 背景
- 2. 方法
-
- 2.1 基本框架
- 2.2 StyleNet
- 2.3 损失函数
- 3. 实验
-
- 3.1 风格迁移结果
- 3.2 对比实验
- 3.3 不同patch大小的输出结果
- 3.4 消融实验
- 4. 快速风格迁移
- 5. 总结
论文链接:https://arxiv.org/abs/2112.00374v3
代码链接:https://github.com/cyclomon/CLIPstyler
摘要
现有的神经风格迁移方法需要参考风格图像将风格图像的纹理信息迁移到内容图像。 然而,在许多实际情况下,用户可能没有参考的风格图像,但仍然有兴趣通过想象来传递风格。 为了处理此类应用需求,本文提出了一个新框架,该框架可以在“没有”风格图像,只有所需风格的文本描述的情况下实现风格迁移。 使用预训练文本-图像嵌入模型 CLIP,本文演示了仅在单个文本条件下对内容图像风格的调制。 具体来说,本文提出了一种具有多视图增强的patch文本-图像匹配损失,以实现逼真的纹理传输。 广泛的实验结果证实了利用反映语义查询文本的真实纹理进行的成功的图像风格迁移。
1. 背景
-
风格迁移是指将一张风格图像中的颜色和纹理风格迁移到另一张内容图像上,同时保存内容图像的结构。然而,现有的神经风格迁移方法通常需要参考风格图像,但在许多实际情况下,用户可能没有可参考的风格图像,但仍然有兴趣通过想象来迁移风格。例如,用户可以想象能够将自己的照片转换为莫奈或梵高风格,而无需拥有著名画家的画作,或者仅凭想象力将日光图像转换为夜间图像。
-
目前,有几种方法已尝试使用具有传达所需风格的文本条件来处理图像。这些方法通常使用预训练的文本-图像嵌入模型将文本条件的语义信息传递到视觉域。然而,这些方法往往存在缺点,由于嵌入模型的性能限制,语义不能得到正确反映,并且由于该方法严重依赖于预训练的生成模型,因此操作仅限于特定的内容域(如人脸)。
2. 方法
为了解决上述问题,本文提出了一种新的图像风格迁移方法,利用对比语言-图像预训练模型(CLIP)来传递文本条件的语义纹理。本文训练一个轻量级的CNN网络,该网络可以表达与文本条件相关的纹理信息,并产生逼真的结果。内容图像由该网络转换,通过匹配传输图像的CLIP模型输出与文本条件之间的相似性来遵循文本条件。此外,当网络针对多个内容图像进行训练时,无论内容图像如何,本文的方法都可以实现文本驱动的风格迁移。
2.1 基本框架
图中是本文的基本框架,目的是通过预先训练的CLIP模型,将目标文本的语义风格迁移到内容图像上。与现有方法的不同之处在于,本文没有风格图像作为参考。
由于本文的模型仅在由CLIP监督的情况下获得语义转换后的图像,因此存在几个问题需要解决:
(1)如何从CLIP模型中提取语义纹理信息,并将纹理应用于内容图像;
(2)如何正则化训练,使输出图像质量不受影响。
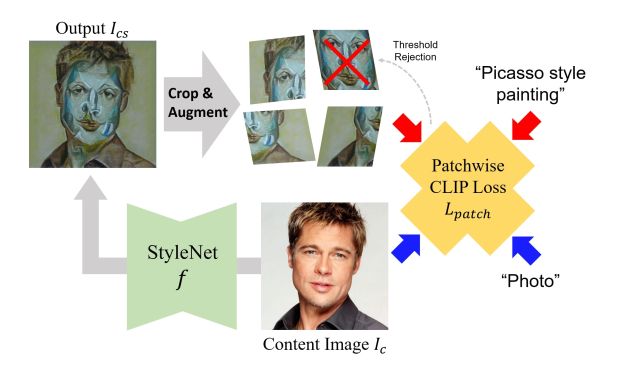
当给定一个内容图像 I I Ic 时,我们的目标是获得风格迁移输出 I I Ics。但使用传统的像素优化方法并不能得到想要的纹理。为了解决这一问题,本文引入了一种CNN编码器-解码器模型StyleNet f f f,该模型可以捕获内容图像的层次视觉特征,同时在深度特征空间对图像进行风格化,以获得真实的纹理表示。另外,利用多视图增强和基于CLIP的损失对模型进行优化训练,使其输出具有目标纹理。
2.2 StyleNet
对于StyleNet f f f,由于作者对网络进行了 200 次迭代训练并且输入图像的分辨率相对较高,因此使用的网络必须是轻量级的,本文使用了轻量级 U-Net 架构。该网络具有三个下采样层和三个上采样层,其中每个下采样层的通道大小为16,32 和 64。为了稳定训练,本文在 f f f 的最后一层包含 sigmoid 函数,使像素值范围在 [0, 1] 范围内。本文还在输入输出特征之间加入一个跳跃连接,来更好地保留内容信息。
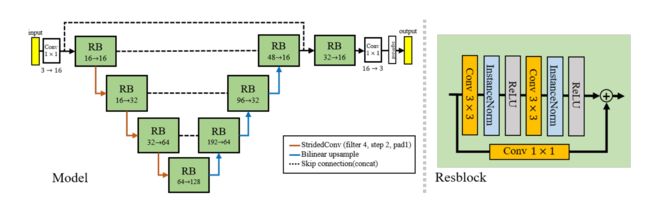
对于图像风格迁移这类注重每个像素的任务来说,每个样本的每个像素点的信息都是非常重要的,所以像BN这种每个批量的所有样本都做归一化的算法就不太适用了,因为BN计算归一化统计量时考虑了一个批量中所有图片的内容,从而造成了每个样本独特细节的丢失。同理对于LN这类需要考虑一个样本所有通道的算法来说可能忽略了不同通道的差异,也不太适用于图像风格迁移这类应用。
Instance Normalization(IN),一种更适合对单个像素有更高要求的场景的归一化算法(IST,GAN等)。IN的算法非常简单,计算归一化统计量时考虑单个样本,单个通道的所有元素。
2.3 损失函数
本文提出了一种新的用于纹理传输的 patch-wise CLIP损失。具体来说,对于输出图像 I I Ics,从中随机裁剪足够数量的patch,并使用不同的透视图对裁剪后的patch进行增强,然后通过计算查询文本条件与处理后的patch之间的相似度来获得CLIP损失。通过应用这种 patch-wise CLIP损失,可以将风格迁移到内容图像的每个局部区域,同时使图像风格更加生动和多样化。
采用随机透视增强有助于本文的框架从两个角度接近其目标:第一,模型用对抗性解决方案欺骗CLIP会变得更加困难,因为现在它必须同时在大多数随机增强的图像上产生适当的扰动; 第二,在大规模预训练过程中,CLIP可能会学习对同一对象在不同视图下的几何信息进行建模。 透视增强提供的多个视图产生了具有不同视图几何信息的CLIP表示,这就有助于模型以3D结构感知的方式探索CLIP模型的语义信息。
由于patch采样和增强的随机性,神经网络 f f f 易于针对最小化损失分数的特定patch进行优化,因此会导致图像过度风格化。为了缓解这个问题,作者提出了一种新的阈值正则化方法以拒绝高分patch的梯度优化过程。利用给定的阈值 τ τ τ,使相应patch的计算损失无效。提出的 patch-wise CLIP 损失定义为:
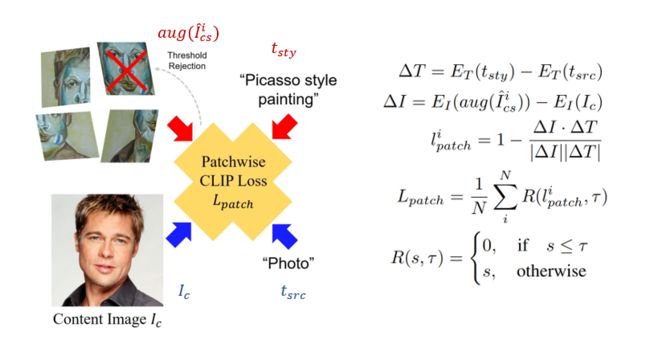
其中, I I Icsi 是生成图像的第 i i i个裁剪patch, a u g aug aug是随机透视增强, R R R(∙, ∙)表示阈值函数。
对于整体损失函数,本文使用四种不同的损失:
-
L L Ldir 调制内容图像的整个部分,例如色调、全局语义;
-
L L Lpatch 局部纹理风格化;
-
L L Lc 计算从预训练的VGG-19网络提取的内容和输出图像的特征之间的均方误差,来保持输入图像的内容信息;
-
L L Lc 总变正则化损失,减轻不规则像素的侧边伪影。
总损失函数:
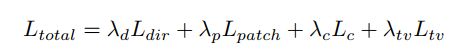
3. 实验
3.1 风格迁移结果
图中展示了本文方法的风格迁移结果。使用相应的文本条件,就可以在不改变图像内容的情况下,成功转换出符合文本条件的图像风格。不仅可以对艺术风格进行迁移,还可以对范围广泛的一般纹理风格进行迁移。并且不仅可以控制纹理类型,还可以控制每个风格的详细条件。例如,在使用文本条件(“白色羊毛”和“绿色水晶”)时提供带有纹理的颜色的附加信息。
3.2 对比实验
3.2.1 与现有风格迁移方法的比较
这里选择几种最先进的艺术风格迁移方法进行对比,包括任意风格迁移(AdaAttn、SANet、CST 和 AdaIN)和像素优化 (Gatys et al.)。
从图中可以看出,尽管只使用文本条件,但本文方法的结果能够得到与baseline相似的风格迁移结果。并且能够在不破坏原始内容的形状结构的情况下,在各个位置都有生动的纹理图案。
3.2.2 与文本引导操作模型的比较
这里选择使用CLIP和预训练的StyleGAN结合的最先进的方法进行对比。

-
本文的方法可以在内容图像上表达与查询文本条件匹配的真实纹理;
-
StyleGAN-NADA只能更改内容图像的一部分,或者更改不能充分反映文本条件的语义;
-
StyleCLIP是在学习的潜在域内操作图像,所以除第三行之外的所有结果都无法根据文本条件转换图像。
3.2.3 结合CLIP的比较
由于本文的方法是使用基于 CLIP 损失进行的网络权重优化,所以为了进一步比较,作者还研究了其他方法是否可以通过结合 CLIP 损失来产生更好的风格迁移结果。

-
本文的优化网络显示出更高的质量;
-
通过像素优化(PixOptim+CLIP),图像无法反映文本条件的语义;
-
VQGAN+CLIP 和 AdaIN+CLIP,纹理应用于内容,但内容结构受到了严重影响。
3.3 不同patch大小的输出结果
为了计算CLIP损失,需要确定合适的patch裁剪大小。这个实验就是通过更改patch的大小来获得各种迁移效果。如果在训练中使用较大的patch,可以有更大的“笔触”,也就是可以粗略地风格化内容图像;使用较小的patch,就可以将更精细的风格模式应用于内容图像。本文选择了128×128作为实验设置。
3.4 消融实验
(a)当使用所有损失时,可以获得感知域中的最佳结果;
(b)删除全局方向损失 L L Ldir(StyleCLIP中提出的损失,在本文中也有应用),删除这一损失无法捕获全局语义,可以看到以不规则模式映射的颜色;
(c)当阈值拒绝被删除时,图像过度聚焦在特定的图像块上,因此会导致图像过度风格化;
(d)不使用增强,无法反映三维逼真的纹理;
(e)将透视增强替换为随机仿射变换,会导致不需要的伪影;
(f)最后,是删除本文提出的 patch-wise CLIP损失,可以看到除了颜色外,纹理几乎没有变化。
4. 快速风格迁移
在本文的默认框架中,需要为单一内容图像训练网络 f f f 以应用给定的风格。为了克服这个问题,作者选择一种使用各种纹理patch而不是单一内容图像来训练 f f f 的方法。一旦以这种方式训练网络,训练后的网络就可以用于各种内容图像。
作为训练集,本文从 DIV2k 的高分辨率纹理图像中随机裁剪patch。为了更快地训练,本文使用预训练的 VGG 编码器-解码器网络而不是 U-Net 作为神经网络 f f f,并且只对解码器网络进行微调。在训练步骤中使用相同的损失函数。
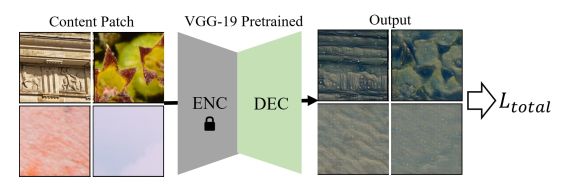
进一步的细节详见原文。
下图是快速风格迁移方法的结果,由于使用不同的纹理输入训练模型,因此可以实时对任意内容图像进行风格转换。
从图中可以看出,结果图像反映了文本条件的语义纹理。另外,结果可以适应具有不同结构多样性的任何类型的内容输入。
然而,在某些情况下(例如 “霓虹灯”、“火”),图像在不必要的区域(例如背景)上具有纹理。 尽管如此,结果表明本文的快速迁移能够为任意内容图像实现高质量的风格传输。
5. 总结
本文提出了一种新颖的图像风格迁移框架,仅使用文本条件来迁移语义纹理信息。 使用patch-wise CLIP损失和增强方案,通过简单地更改文本条件而不需要任何风格图像来获得逼真的纹理传输结果。