人工智能演义第二回:遇险阻创始人早逝,敢坚持三剑客逆袭

神经网络是什么?
神经网络是人工智能领域目前最热门的一种机器学习方法,是目前最为火热的研究方向之一——深度学习的基础。
神经网络这个概念听起来无比深奥,很多非技术人士大都不明白它到底是个啥。让我们继续往下看试试是否可以“窥一斑而知全豹”。

△看图猜动物,左右滑动查看更多
猜一下,以上动物是什么?或者是由哪种动物组合成的?
也许答案你不到一秒就可以脱口而出,凭借人类大脑强大的辨识能力,尽管图中的动物经过变形处理或者视觉误差,我们还是能快速猜出这是什么动物。这就归功于我们大脑的1000多亿个神经元组成的复杂网络,即使动物们并非我们熟知的模样,我们依然可以轻松识别出。
神经网络技术正是受到人类神经元的启发,通过模拟人脑神经网络以实现类人工智能的功能。
人脑中的神经元大家初中时就很熟悉了:
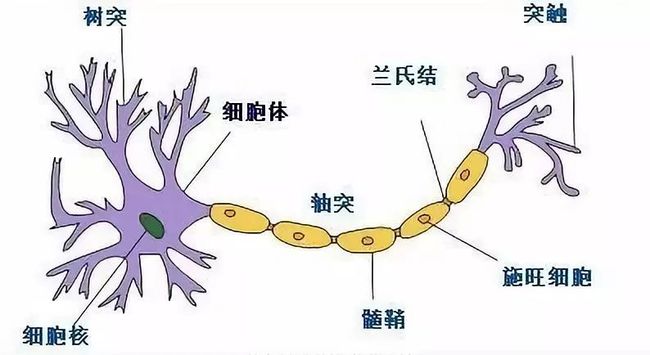
而人工智能神经网络正是模拟人类大脑:
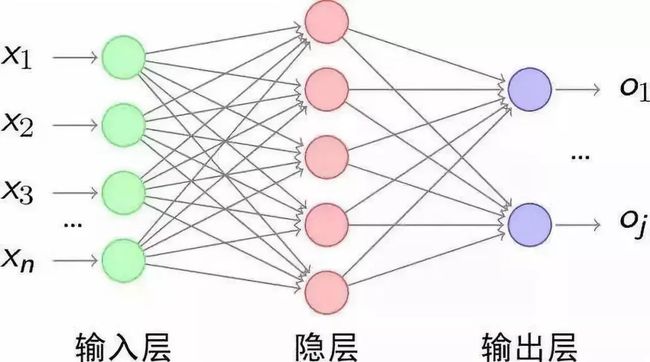
要进一步理解神经网络,我们必须要厘清以下概念:
人工智能:人工智能是一个非常大的概念,其最初定义是要让机器的行为看起来就像是人所表现出的智能行为一样。我们经常听到的语音识别、图像识别、自然语言理解等领域都是具体的人工智能方向,而机器学习、神经网络等概念都属于实现人工智能所需要的一些技术。
机器学习:机器学习是人工智能的一门分支,指通过学习过往经验来提升机器的智能性的一类方法。根据样本和训练的方式,又可以分为监督学习、无监督学习、半监督学习和强化学习等类型。
神经网络:在人工智能领域一般指人工神经网络,是一种模仿动物神经网络行为特征,进行分布式并行信息处理人工智能模型。我们通常使用的神经网络都需要通过训练数据进行参数的学习,所以神经网络也可以被归为一种机器学习方法。
深度学习:作为人工智能领域的新兴方向,深度学习目前还没有严格的定义,一般我们把一些具备较多中间隐含层的神经网络称为深度学习模型。

至暗时刻
2019年,ACM决定将2018年ACM图灵奖授予YoshuaBengio、Geoffrey Hinton和YannLeCun三位深度学习之父,以表彰他们给人工智能带来的重大突破,这些突破使深度神经网络成为计算的关键组成部分。ACM主席 Cherri M. Pancake 表示,“人工智能如今是整个科学界发展最快的领域之一,也是社会上讨论最广的主题之一。
AI的发展、人们对AI的兴趣,很大程度上是因为深度神经网络的近期进展,而Bengio、Hinton和LeCun为此奠定了重要基础”。
神经网络的发展过程遇到了哪些波折?“深度学习三巨头”有哪些有趣的故事?而这些年热门的深度学习又和神经网络有什么样的关系?
今天院长为大家一一道来。
大家知道,我们现在所说的人工神经网络确实是受生物神经网络启发而设计出来的。在1890年,实验心理学先驱William James在他的巨著《心理学原理》中第一次详细论述人脑结构及功能。其中提到神经细胞受到刺激激活后可以把刺激传播到另一个神经细胞,并且神经细胞激活是细胞所有输入叠加的结果。这一后来得到验证的假说也成为了人工神经网络设计的生物学基础。
基于这一假说,一系列模拟人脑神经计算的模型被相继提出,具有代表性的有Hebbian Learning Rule, Oja's Rule和 MCP NeuralModel等,他们与现在通用的神经网络模型已经非常相似,例如在Hebbian Learning模型中,已经可以支持神经元之间权重的自动学习。当然,现有的人工神经网络只是对人脑结构的最初级模拟,成人的大脑中估计有1000亿个神经元之多,其复杂性远超目前的所有人工神经网络模型。
1958年,就职于Cornell航空实验室的 Frank Rosenblatt 将这些最初的神经网络模型假说付诸于实施,利用电子设备构建了真正意义上的第一个神经网络模型:感知机(Perceptron)。Rosenblatt现场演示了其学习识别简单图像的过程,在当时的社会引起了轰动,并带来了神经网络的第一次大繁荣。许多学者和科研机构纷纷投入到神经网络的研究中,连美国军方大力资助了神经网络的研究,并认为神经网络比“原子弹工程”更重要。

△Frank Rosenblatt
然而好景不长,上回曾经提到的达特茅斯会议的组织者明斯基(HR图灵学院|阿兰图灵开山鼻祖,达特茅斯豪杰聚义),同时也是 Rosenblatt 的同事兼中学同学,在一次会议上和罗森布拉特大吵,认为神经网络不能解决人工智能的问题。
随后,明斯基和麻省理工学院的另一位教授佩珀特(Seymour Papert)合作,写出了《感知机:计算几何学》(Perceptrons:An Introduction to Computational Geometry)一书。该书几乎对处于萌芽中神经网络判处了死刑,书中明斯基和佩珀特证明单层神经网络不能解决XOR(异或)问题,说明神经网络的计算能力实在有限。但“感知机”的缺陷被明斯基以一种敌意的方式呈现出来,当时对Rosenblatt是个致命打击,不久后他因为一次沉船事故离开了人世。原来的政府资助机构也逐渐停止对神经网络研究的支持,神经网络为代表联结主义也随之进入了第一个至暗时刻。
整个70年代,神经网络的研究都处在寒冬之中。1974年,哈佛大学的博士生波斯(Paul Werbos)一篇博士论文证明了在神经网络多加一层,并且利用“反向传播”(back-propagation)学习方法,可以解决XOR问题。之前明斯基所刚提出的神经网络致命伤就被这增加的一层神经网络所轻松化解,这也为之后深度学习方法的提出埋下了伏笔。但这篇论文发表时正处在神经网络研究的低谷,并没有引起足够的关注。
直到八十年代中期,以John Hopfield, David Rumelhar及Hinton为代表的一批科学家进一步将反向传播传播方法引入神经网络的训练中,并提出了Hopfiled Networks和Boltzmann Machine等新的神经网络结构,主导了神经网络的又一次复兴。我们如今耳熟能详的递归神经网络(RNN)、长短期记忆网络(LSTM)和卷积神经网络(CNN)都在这一时期被相继提出。然而,当科学家们在实际训练这些模型时,却又遇到各种各样的问题,一方面当时的神经网络很容易过拟合,另一方面又缺乏足够的数据和计算能力。

深度学习三巨头
到90年代,以支持向量机(SVM)为代表的统计机器学习方法逐渐取代神经网络成为了人工智能的主流。相比于神经网络方法,支持向量机有着更扎实的统计理论基础,有着更好问题优化与求解方法。神经网络再一次陷入低谷,大量之前从事相关研究者开始转向其他方向。不过还是有很多科学家一直在默默坚守,坚信神经网络技术终有一天能够再次爆发,其中最为代表性的就是前面提到的深度学习三位创始人——Yoshua Bengio、Geoffrey Hinton 和 Yann LeCun。

△深度学习三巨头
进入新世纪以来,互联网的飞速发展对AI提出了更多需求,一方面可供训练的数据量大大增加,另一方面问题场景越来越复杂,需要有通用和模块化的方法来快速适应不同的问题,而神经网络在这方面相比于当时流行的统计学习方法都更有优势。
2006年,Hinton在Nature发表了“Reducing the Dimensionality of Data with Neural Networks”一文,提出训练更多层的神经网络来提升神经网络的泛化能力,并给出了具体的解决方案,吹响了神经网络第二次复兴的号角,并引领了深度学习这一AI的新方向。后续深度学习的发展并没有完全按照Hinton这边论文的思路,更多的是依靠算力的增加、数据的增加以及在模型训练里增加的各种技巧。
2010年Hinton和Deng Li把DNN用于声学模型建模,用于替代传统的隐马尔科夫模型,语音识别的词错误率相对降低了30%,震惊了整个AI界。2012年由Hinton和他的学生提出的AlexNet在图像领域著名的ImageNet比赛中,将图像分类错误率由25.8%下降至10%,再次让所有人惊叹于深度学习的威力。在之后的几年中,深度学习又被应用到自然语言处理、语音图像合成、自动驾驶、搜索推荐等几乎人工智能的所有领域,并刷新了几乎所有AI竞赛的最好成绩。在深度学习带动下,AI在这几年中再一次赢来爆发。
那么深度学习方法和传统的神经网络又有什么样的关系呢?
院长在这里在做个技术总结。最早期的神经网络“感知机”只有单层网络结构,被证明无法解决“异或问题”,存在先天的硬伤。后来证明增加神经网络层数并引入反向传播算法之后解决这一问题,这样神经网络的这一短板就被补齐了。然而,神经网络问题从数学上不能保证取得全局最优解(又一硬伤),当训练数据量小的时候容易过拟合,且存在其他一些模型训练的问题,导致再次沉沦。之后Hinton提出采用更多层的神经网络加预训练方法可以解决上述问题,这也就是深度学习的起源。再后来大家发现随着数据量和计算能力的提升,即使不采取预训练方法,单纯增加神经网络层数,也可以达到同样效果。随后更多的深度神经网络模型和训练方法被陆续提出,深度学习开始走向快车道。
最后在总结一下深度学习三位创始人对领域的贡献。Hinton的身世显赫,是著名逻辑学家布尔(布尔代数创始人)的后裔,从出身就带着与计算机的不解缘分。他像是深度学习领域的哲学家,不断地思考与反思,为大家指引前行的方向。在最近的一次人工智能会议上,Hinton表示自己对于反向传播“非常怀疑”,并提出“应该抛弃它并重新开始”。Bengio为深度学习的发展和推广做出了很多基础的贡献,除了大量重要论文外,他还主导研发了Theano深度学习框架,一度成为非常主流的深度学习工具,并带动了后续tensorflow与pytorch等平台的出现。Lecun是Hinton的博士后学生,也是神经网络的坚定信仰者,早在80年代他就在贝尔实验室提出了如今大名鼎鼎的卷积神经网络,当时还叫LeNet,并被广泛应用于支票的数字识别。2013年Lecun加盟Facebook组建FAIR并任职第一任主任,致力于深度学习学术界与工业界的结合。

深度学习在企业场景的应用
近年来,以Resnet和Bert为代表的深度学习算法在计算机视觉和自然语言处理领域继续披荆斩棘,不断创造各项记录。除了模型的创新,这些模型更得益于更大规模的训练样本及更强的算力的支持,很多人也在质疑深度学习这样的发展模式还能持续多久。相比于神经网络,人类在面对新问题时拥有者更好的学习效率和效果,这样说明当前神经网络的实现机制和真正人脑的神经学习机制还存在着很大的差异。如何更好探索好的网络先验结构与参数,以及引入先验知识或者通过迁移学习、多任务学习的方式进行小样本的学习已经成为了近期新的研究热点。特别是在企业服务场景,相对to C场景样本量更少,业务性更强,如何将深度学习方法与这些场景相结合也成为一个重要课题。
深度学习方法在e成科技的对话机器人、人岗匹配、音视频面试等场景起到了非常重要的作用,院长在前几期反复提到的Bert就是其中的重要代表。但作为一家to B企业,e成科技的很多算法都有自身的特殊场景,同时也面临着数据相对不足的问题。为了能使深度学习方法最大限度地发挥威力,e成科技的算法工程师们也进行了非常多的尝试与探索,在后续的专栏中,院长将会为各位小伙伴们慢慢介绍。
作为HR+AI赛道的领跑者,e成科技从创立起就将AI技术基因根植于业务场景,凭自身在AI能力和人力资本行业经验的独特优势,以及来自全球顶尖跨媒体技术实验室的AI核心团队,致力于将AI技术深度应用于人力资本全场景中,推动人力资本智能变革。6年来,e成科技积累了诸多技术、数据、场景和创新应用,并通过打造HR赛道首个AI能力开放平台,把技术赋能给整个人力资本领域。
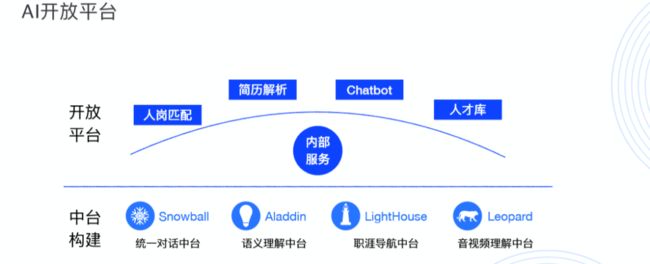
△e成科技打造HR赛道首个AI开放平台
e成科技AI开放平台可以根据您的业务需求,灵活调用OpenAPI接口或私有云部署,提供NLP能力、实体识别、归一化知识图谱、人岗匹配、简历解析、HR机器人等成熟AI技术基础能力,AI产品组件,定制化解决方案等多种智能服务。

e成科技AI开放平台提供的AI算法能力、AI产品和AI解决方案,将帮助企业轻松、快速、零门槛拥有属于自己的AI能力及产品,实现数字化升级弯道超车。自投入使用以后,e成科技AI开放平台已助力多家企业合作伙伴应用落地,包括招聘选拔、员工服务、薪酬绩效、培训发展等人力资本全场景的应用,应用中展现出智能化、高准确率、高效率、更便捷等突出优势,高效助力用户AI技术在人力资本场景的落地。
未来,随着科技飞速发展,AI技术正在根据大数据和深度学习不断优化和升级。e成科技愿意借助于自身在AI开放平台、技术、产品、行业经验等独特优势,助您实现人力资本数字化新升级!
作者:e成科技AI算法负责人刘洋