Python中字符串、函数以及Bug
1.字符串:

1.字符串的驻留机制:
Pycharm对字符串进行了字符串优化,内容相同的就进行了强制驻留
在python中字符串是基本数据类型,是一个不可变的字符序列
Python的驻留机制是对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量

s1=''
s2=''
print(s1 is s2)#True
s3='abc%'
s4='abc%'
print(s3==s4)#True
print(s3 is s4)#True
import sys
a='abc%'
b='abc%'
a=sys.intern(b)
print(a is b)#True
2.字符串的查询操作方法:

s='hello,hello'
print(s.index('lo'))#3
print(s.find('lo'))#3
print(s.rindex('lo'))#9
print(s.rfind('lo'))#9
3.字符串的大小写转换:

s='hello,python'
a=s.upper()
print(a)#HELLO,PYTHON
#只要对字符串进行操作,字符串就会产生一个新的对象
4.字符串内容对齐操作的方法:

s='hello,Python'
print(s.center(20,'*'))#****hello,Python****
print(s.ljust(20,'*'))#hello,Python********
s='hello,Python'
print(s.zfill(20))#00000000hello,Python
print('-8910'.zfill(8))#-0008910
5.字符串劈分操作:

- split():
s='hello world Python'
lst=s.split()
print(lst)#['hello', 'world', 'Python']
s1='hello|world|Python'
print(s1.split(sep='|'))#['hello', 'world', 'Python']
print(s1.split(sep='|',maxsplit=1))#['hello', 'world|Python']
- rsplit():(右边)
print(s.rsplit())#['hello', 'world', 'Python']
print(s1.rsplit(sep='|'))#['hello', 'world', 'Python']
print(s1.rsplit(sep='|',maxsplit=1))#['hello|world', 'Python']
6.字符串判断方法:

s='hello world Python'
print(s.isidentifier())#False
print('hello'.isidentifier())#True
print('\t'.isspace())#True
print('abc'.isalpha())#True
print('张三1'.isalpha())#False
print('123'.isdecimal())#True

s='hello world'
print(s.replace('world','java'))#hello java
s1='hello world world world'
print(s1.replace('world','java',2))#hello java java world
lst=['hello','ajd','dsc']
print('|'.join(lst))#hello|ajd|dsc
print('*'.join('Python'))#P*y*t*h*o*n
7.字符串的比较操作:
运算符:> < >= <= == !=
print('apple'>'app')#True
print('apple'>'banana')#False
print(ord('a'),ord('b'))#97 98
print(chr(97),chr(98))#a b
==比较的是value
is 比较的是地址
'''
a=b='Python'
c='Python'
print(a==b)#True
print(b==c)#True
print(a is b)#True
print(b is c)#True
8.字符串的切片操作:
不可变类型,不具备增删改操作,切片后会产生一个新的对象
s='hello,Python'
s1=s[:5]#由于没有指定起始位置,从0开始
s2=s[6:]#没有终点,到末尾结束
s3='!'
newstr=s1+s3+s2
print(s1,s2,s3,newstr)#hello Python ! hello!Python
print(s[1:5:2])#el
9.格式化字符串:

'''第一种占位符'''
name='张三'
age=20
print('我叫%s,今年%d岁' % (name,age))
'''第二种占位符'''
print('我叫{0},今年{1}岁'.format(name,age))
print('%10d' % 99)#10指的是宽度 99
print('%10.3f' %3.1415926)# 3.142
print('{0:.3}'.format(3.1415926))#.3表示的是一共三位数,3.14
print('{0:.3f}'.format(3.1415926))#.3表示的是一共三位小数,3.142
print('{0:10.3f}'.format(3.1415926))#.3表示的是一共三位小数,宽度为10
10.字符串的编码转换
编码:讲字符串转换为二进制数据(bytes)
s='天涯共此时'
#编码
print(s.encode(encoding='GBK'))#GBK编码,一个中文占两个字节,10
print(s.encode(encoding='UTF-8'))#UTF-8,一个中文占三个字节,15
解码:将bytes类型数据转换成字符串类型
#解码
#byte代表一个二进制数据
byte=s.encode(encoding='GBK')
print(byte.decode(encoding='GBK'))
编码和解码的格式必须相同
2.函数:
1.函数的创建:
def haha(a,b):
c=a+b
return c
result=haha(10,20)
print(result)#30
2.函数的参数传递:
不写名字,按顺序传,写名字了,按照名字传
def haha(a,b):#a,b是形参
c=a+b
return c
result=haha(10,20)#10和20是实参
print(result)#30
res=haha(b=10,a=20)
print(res)#30,根据左侧变量的名字传,=左侧的变量的名称成为关键字参数
3.参数传递的内存分析:
def fun(arg1,arg2):
print('arg1',arg1)#arg1 11
print('arg2',arg2)#arg2 [22, 33, 44]
arg1=100
arg2.append(10)
print('arg1',arg1)#arg1 100
print('arg2',arg2)#arg2 [22, 33, 44, 10]
n1=11
n2=[22,33,44]
fun(n1,n2)#位置传参,arg1,arg2是形参,n1,n2是实参
print(n1,n2)#11 [22, 33, 44, 10]
4.函数的返回值:
函数返回多个值时,结果为元组
def fun(num):
odd=[]
even=[]
for i in num:
if i%2:
odd.append(i)
else:
even.append(i)
return odd,even
#函数调用
lst=[10,29,34,23,44,53,55]
print(fun(lst))#([29, 23, 53, 55], [10, 34, 44])
'''函数的返回值
(1)函数执行完毕,不用返回值,可以不用写return
(2)函数的返回值如果是1个,返回原类型
(3)函数的返回值如果是多个,返回的结果为元组
'''
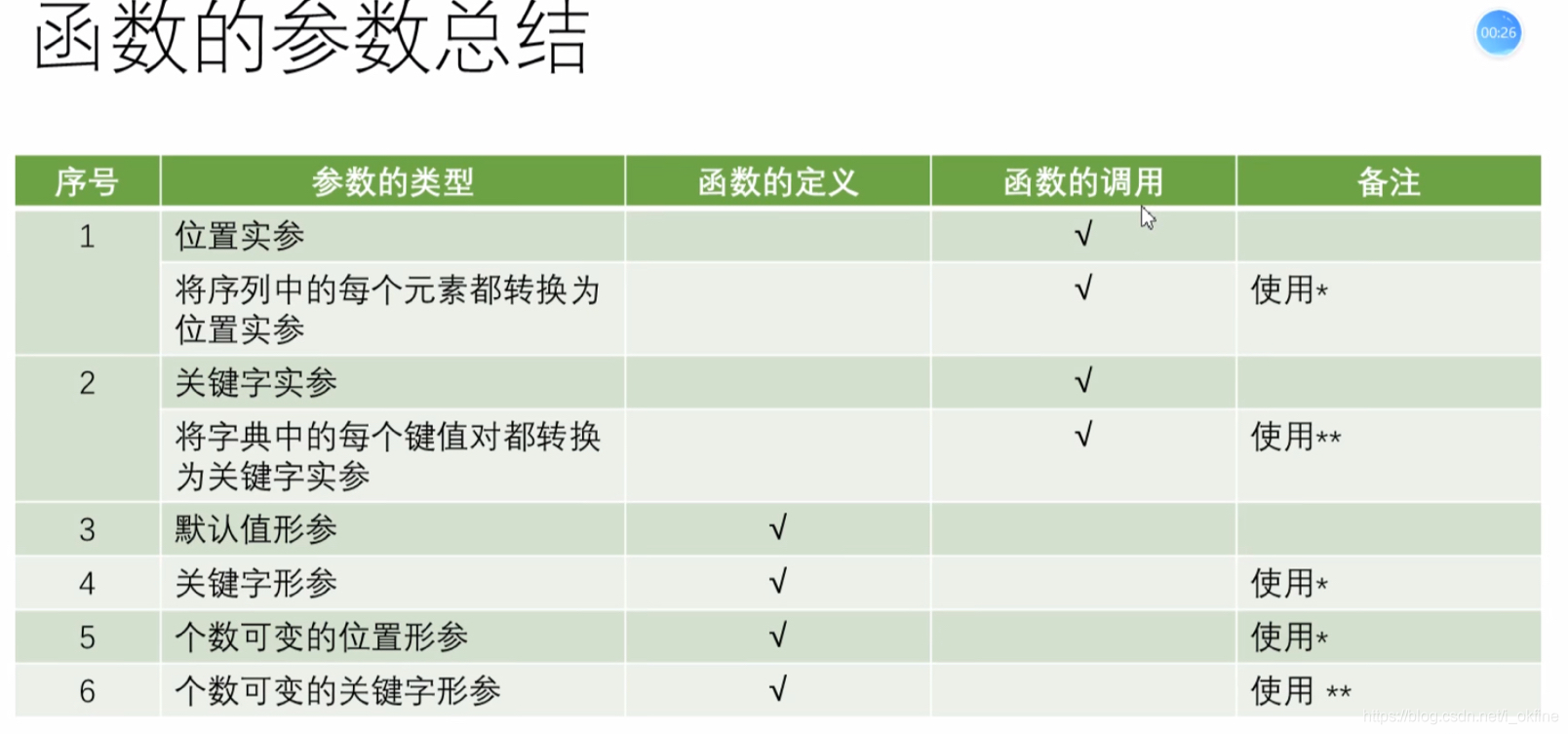
5.函数参数的定义:

- 个数可变的位置参数
#个数可变的位置参数
def fun(*args):#形参只能有一个,不然会报错
print(args)
fun(10)
fun(10,30)
fun(20,40,50)
'''
(10,)
(10, 30)
(20, 40, 50)'''
- 个数可变的关键字形参
def fun1(**args):#形参个数只能有一个
print(args)
fun1(a=10)
fun1(a=20,b=30,c=40)
#{'a': 20, 'b': 30, 'c': 40}
- 两种的结合:
def fun3(*args1,**args2):#既有位置参数又有关键字形参,只有一种形式
pass
def fun4(**args4,*argss):#程序报错
```
```python
def fun(a,b,c):
print('a=',a)
print('b=',b)
print('c=',c)
fun(10,20,30)
lst=[10,20,30]
fun(*lst)#在函数调用时,将列表中每个元素转换为位置实参传入
fun(a=100,b=200,c=300)#关键字实参
dic={'a':111,'b':222,'c':333}
fun(**dic)#在函数调用时,将字典中的键值对都转换为关键字实参传入
def fun3(**args2):#个数可变的关键字形参
print(args2)
fun2(10,20,30,40)
fun3(a=10,b=30,c=29,d=23)
def fun4(a,b,*,c,d):#从这颗*之后的调用只能采用关键字参数传递
pass
fun4(a=10,b=20,c=10,d=20)
fun4(10,20,c=10,d=20)
'''函数定义时的形参的顺序问题'''
def fun5(a,b,*,c,d,**args):
pass
def fun6(*args,**args2):
pass
def fun7(a,b=10,*args,**args2):
pass
6.斐波那契数列与递归函数:
def fib(n):
if n==1:
return 1
if n==2:
return 1
else:
return fib(n-1)+fib(n-2)
#斐波那契数列第六位上的数字
print(fib(6))#8
for i in range(1,7):
print(fib(i))#1 1 2 3 5 8
3.异常处理机制:
try:
a=int(input('请输入第一个整数'))
b=int(input('请输入第二个整数'))
result=a/b
print('结果为:',result)
except ZeroDivisionError:
print('对不起,除数不允许为0')
print('程序结束')
except先捕捉小的,再捕捉老的


try:
a=int(input('请输入第一个整数'))
b=int(input('请输入第二个整数'))
result=a/b
except BaseException as e:
print('出错了',e)
else:#没有错执行else部分,有错执行except
print('计算结果为:',result)
try:
a=int(input('请输入第一个整数'))
b=int(input('请输入第二个整数'))
result=a/b
except BaseException as e:
print('出错了',e)
else:#没有错执行else部分,有错执行except
print('计算结果为:',result)
finally:
print('无论程序是否产生异常,都会被执行的代码')

print(10/0)#ZeroDivisionError
lst=[0,1,2,3]
print(lst[4])#IndexError
dic={'name':'张三','age':20}
print(dic['gender'])#KeyError
print(num)#NameError
int a=20#SyntaxError,语法错误
a=int('hello')#ValueError
import traceback
try:
print(1/0)
except:
traceback.print_exc()
