Faster R-CNN 详解
Faster R-CNN
-
- 一、详解 RPN
-
- (一)网络结构
- (二)Anchor
- (三)Loss 设计
- (四)训练 RPN
- (五)共享卷积层
- 二、更多细节
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文链接 1 论文链接 2
Faster R-CNN 是一个 end-to-end 的目标检测算法。相比 Fast R-CNN 有更高的精度和速度。其 主要思想有以下 2 点:
(1)提出了 Region Proposal Network【RPN】,替代了传统的生成候选框的方法。
(2)将 Region Proposal Network【RPN】与检测网络【Fast R-CNN】共享卷积层,大幅提高网络的检测速度。
一、详解 RPN
(一)网络结构
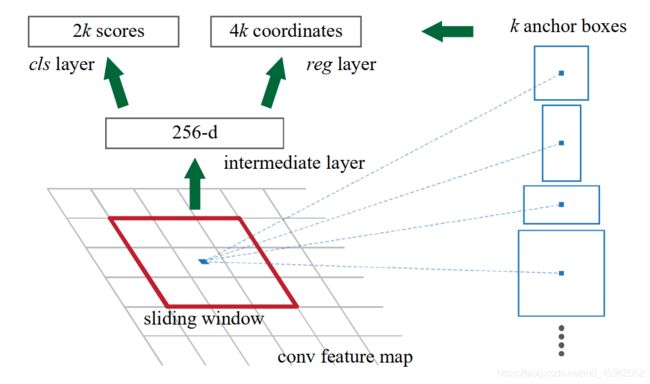
图 1:RPN 网络结构
Faster R-CNN 相比 Fast R-CNN 的最大改进就在于提出了 RPN 网络。所以 Faster R-CNN 可以看做:RPN + Fast R-CNN。RPN 网络使用卷积神经网络提取候选框,替代了传统的基于底层视觉信息的生成候选框的方法,比如 selective search、edge boxes。在速度上和精度上都有了显著的提高。
RPN 网络的输入: 经过 CNN 后生成的 feature map
RPN 网络的输出: 分类【objectness 置信度】+ 回归【所有 proposals 的左上角坐标(x, y),宽高(w, h)】
因为我们的最终目标是要将 RPN 和 Fast R-CNN 共享卷积。对于共享部分的网络的输出是一个 feature map。所以对于 RPN 网络非共享的第一层。我们使用一个 n × n n \times n n×n 的卷积核,对共享部分生成的 feature map 进行卷积操作,并将最后的维度缩减至低维(ZF 256 维,VGG 512 维)。
然后使用 两个并列的全连接层(使用 1 × 1 1 \times 1 1×1 卷积实现),分别输出分类和回归的结果。其中分类的分支用来判断是否是一个物体([0, 1]),即判断候选框中的 objectness(对象性)。或者说是判断候选框中的物体是背景还是前景。回归的分支用于最小化候选框与 ground truth 的差值。其中 分类的输出通道数为 2k,回归的输出通道数为 4k(k 为一个 feature map 中的点生成的 anchor 的个数)。网络的结构见图 1。
(二)Anchor
对于 RPN 网络,最重要的一个概念就是 anchor。那么 什么是 anchor?
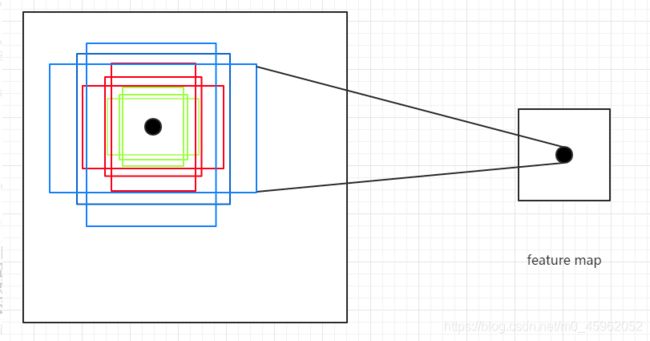
图 2:Anchor 的定义
在引入 Anchor 之前,我们需要思考一个问题。我们 如何生成一系列大小各不相同的 region proposals 呢? 其实可以这样,我们可以 先在原始图片中生成各种大小,长宽比例的窗口。对于与 ground truth 有高重叠的窗口,我们对其进行修正。对于那些与 ground truth 重叠很低的窗口,我们不进行修正。最后筛选出于 ground truth 重叠很高的窗口,就得到了最后的 region proposals。
那么如何生成各种大小,长宽比例的窗口呢? 记生成窗口的边长(正方形)为 scale,窗口的长宽比为 aspect ratio。记它们的个数为 N s c a l e , N a s p e c t r a t i o N_{scale},N_{aspect \; ratio} Nscale,Naspectratio。那么我们就可以 先生成一个正方形,然后再将长宽缩放到对应的比例。即为生成的窗口。那么一次,我们能生成 N s c a l e × N a s p e c t r a t i o N_{scale}\times N_{aspect \; ratio} Nscale×Naspectratio 个窗口。
我们 将 feature map 上的点,映射到原始图片上的一个区域。以这个区域的中心点生成如上我们所说的窗口,那么这个窗口,就叫做 anchor。设 feature map 的长和宽分别为 w 和 h,那么生成的 anchor 的个数为 w × h × N s c a l e × N a s p e c t r a t i o w \times h \times N_{scale}\times N_{aspect \; ratio} w×h×Nscale×Naspectratio
Faster R-CNN 中的 anchor 有 3 种不同的尺度 { 128 × 128 , 256 × 256 , 512 × 512 } \{128 \times 128,256×256,512×512\} {128×128,256×256,512×512} 3 种形状也就是不同的长宽比 W : H = { 1 : 1 , 1 : 2 , 2 : 1 } W:H=\{1:1,1:2,2:1\} W:H={1:1,1:2,2:1},这样 feature map 中的点就可以组合出来 9 个不同形状不同尺度的 Anchor Box。(见图 2)。我们依次将 feature map 上的点映射到原图,生成 anchor,那么这个 anchor,几乎可以覆盖整个图片中的各种位置和大小。
同时,anchor 具有平移不变性,我们可以这样理解,对于一幅图片中要定位的物体,无论在图片的哪个地方,我们都能定位出来。所以对于每个 feature map 上的点,我们都生成固定尺度、形状的 anchor。这也使 anchor 具有 Translation-Invariant(平移不变性)。
(三)Loss 设计
对于 RPN 网络,我们是要进行训练的,那么进行训练一定需要标签。这个标签,我们怎么定义呢?对于正样本我们将类别标签标记为 1,负样本我们将类别标签标记为 0,其余的 anchor 我们不参与训练。候选框的坐标还使用原 anchor 的坐标。我们下来看 正负样本的定义。
正样本:(1)与 ground truth IOU 最高的那些 anchor。(2)与 ground truth IOU > 0.7 的 anchor
负样本:与 ground truth IOU < 0.3 的那些 anchor
RPN 网络有 2 部分输出,分类和回归,所以我们的损失函数的要兼顾分类和回归。损失函数见如下式子:
L ( { p i } , { t i } ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) L(\{p_i\}, \{t_i\})=\frac{1}{N_{cls}}\sum_iL_{cls}(p_i, p_i^*)+\lambda \frac{1}{N_{reg}}\sum_ip_i^*L_{reg}(t_i,t_i^*) L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
i i i 代表在当前 batch 中的一个样本。 p i p_i pi 代表 anchor 中的物体是前景的概率。 p i ∗ p_i^* pi∗ 代表 ground truth,对于正例用 1 表示,负例用 0 表示。(正负例的定义见上面的内容)。 t i t_i ti 是一个长度为 4 的向量。 t i ∗ t_i^* ti∗ 为正样本的 Bounding Box。 L c l s L_{cls} Lcls 是交叉熵损失,用于判断是否为物体。 L r e g L_{reg} Lreg 是 smooth L1 损失(图像见图3),之所以不使用 L 2 L_2 L2 损失,是因为当预测的偏移值与真值差距较大时,使用 L 2 L_2 L2 损失的导数太大,模型容易发散,不收敛。因此在大于 1 时采用了导数较小的函数。下面是三种常见的损失。
![]()
![]()

分别对三个式子求偏导:

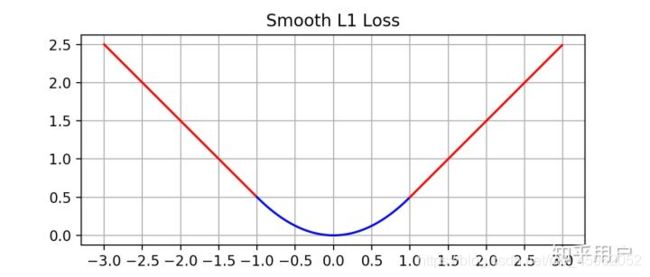
图 3:smooth L 1 L_1 L1 Loss 的图像
p i ∗ L r e g p_i^*L_{reg} pi∗Lreg 可以理解为,只有当生成的 anchor 与 ground truth 的距离够近,也就时是标签是正样本时,我们才回归此 anchor 的坐标。对此时的 anchor 的坐标与 ground truth 再进行拉近。否则,当标签为负样本时,也就时 anchor 与 ground truth 过远。我们不再对坐标进行调整。其中 t t t 向量的定义如下:
t x = ( x − x a ) / w a t_x=(x-x_a) / w_a tx=(x−xa)/wa
t y = ( y − y a ) / h a t_y=(y-y_a)/h_a ty=(y−ya)/ha
t w = l o g ( w / w a ) t_w=log(w/w_a) tw=log(w/wa)
t h = l o g ( h / h a ) t_h=log(h/h_a) th=log(h/ha)
t ∗ t^* t∗ 向量的定义如下:
t x ∗ = ( x ∗ − x a ) / w a t_x^*=(x^*-x_a)/w_a tx∗=(x∗−xa)/wa
t y ∗ = ( y ∗ − y a ) / h a t_y^*=(y^*-y_a)/h_a ty∗=(y∗−ya)/ha
t w ∗ = l o g ( w ∗ / w a ) t_w^*=log(w^*/w_a) tw∗=log(w∗/wa)
t h ∗ = l o g ( h ∗ / h a ) t_h^*=log(h^*/h_a) th∗=log(h∗/ha)
x x x, x a x_a xa, x ∗ x^* x∗ 分别代表:预测后的 box 的 x 坐标值、anchor box 的 x 坐标值、ground truth box 的 x 坐标值。(y,w,h 的定义同理)
(四)训练 RPN
每个 batch 都是由多个正样本与多个负样本组合而成。其中正负样本的比例为 1 : 1 1 : 1 1:1。我们使用的 batch size = 256,也就是对于每个 batch 我们输入 128 个正样本和 128 个负样本。当正样本数量没有达到 128 时,我们使用负样本填充。
与检测网络部分的共享层,在 ImageNet 数据集上进行预训练。其他层使用均值为 0,方差为 0.01 的高斯分布初始化。然后使用我们生成的 anchor 样本进行 fine turn。使用 SGD 优化器,学习率为 0.001 训练 60k 个 mini-batch,然后使用学习率为 0.0001 训练 20k 个 mini-batch,momentum = 0.9,weight decay = 0.0005。
(五)共享卷积层

图 4:共享卷积层后的网络结构
因为 RPN 网络的前半部分和检测网络的前半部分的结构相同。我们可以将 RPN 网络和检测网络相同的网络结构抽取出来进行共享(如图 4)。那么我们如何进行训练呢?我们可以使用如下 4 个步骤实现卷积层的共享并训练:
(1)使用 ImageNet 预训练 RPN 网络的共享层,然后在生成的 anchor 上 fine turn。
(2)定义一个单独的 Fast R-CNN,先在 ImageNet 进行预训练,然后在第 1 步生成的 region propoals 上 fine turn。
(3)使用第 2 步中微调后的 Fast R-CNN 网络重新初始化 RPN 网络,固定共享卷积层【即设置学习率为 0,不更新】,仅微调 RPN 网络独有的层【此时共享卷积层】
(4)固定第 3 步中共享卷积层,利用第 3 步中得到的 region proposals,仅微调 Fast R-CNN 独有的层,至此形成统一网络如上图 4 所示。
作者通过实验表明:共享卷积层比不共享卷积层有更高的 mAP 值。这说明当检测网络的参数用于 RPN 网络时,生成的 region proposals 的质量有很大的提高。
二、更多细节
anchor 使用 3 个尺度 { 128 , 256 , 512 } \{128, 256, 512\} {128,256,512},3 个长宽比 { 1 : 1 , 1 : 2 , 2 : 1 } \{1:1, 1:2, 2:1\} {1:1,1:2,2:1},生成 9 种 anchor。训练和测试时 Fast R-CNN 使用的都是单尺度,将短边缩放到 600 pixel。
对于 anchor 生成到图片边界之外的情况,我们需要进行特殊处理。在训练的时候我们需要忽略所有的跨边界的 anchor。对于 1000 x 600 pixel 的图像,我们大约生成 20k 个 anchor(≈ 60 x 40 x 9)。经过筛掉跨边界的 anchor 后,剩下的 anchor 数量大约为 6k。如果在训练中不忽略跨界 anchor,它们就会在目标中引入大型的、难以纠正的误差项,训练就不会收敛。在测试时将整个测试图片输入 RPN 网络,对于跨边界的 anchor 我们裁剪到图像的边界。
无论是训练还是测试,在经过 RPN 网络后使用阈值为 0.7 的 NMS 去除重复的 region(剩下大约 2k 个 region),然后 挑出 top-N 个 region proposals 将其送入之后的网络进行检测。 注意:NMS 的使用并不会降低精度,可以减少更多的误报的 region,对最后的检测结果有提高。
参考链接:
https://papers.nips.cc/paper/5638-faster-r-cnn-towards-real-time-object-detection-with-region-proposal-networks.pdf
https://blog.csdn.net/wopawn/article/details/52223282
https://www.jianshu.com/p/19483787fa24