【阅读笔记】应用LRP,通过将相关性从模型的输出层反向传播到其输入层来解释基于RNN的DKT模型(二)
提示:Interpreting Deep Learning Models for Knowledge Tracing与Towards Interpretable Deep Learning Models for Knowledge Tracing在应用分层相关传播(LRP)方法上最大的不同是Multiplicative Connection的处理。评估结果表明,所分配的相关值定性和定量地捕捉了对模型预测的对级贡献。此外,它们还可以从模型输入中获取技能级别的语义信息,包括技能特定的差异、距离和内部关系。
文章目录
- 前言
- 1.LPR Method
-
- Weighted Linear Connection
- Multiplicative Connection
- 2.Interpreting DKT Models using LRP Method
-
- Example
- 3.Evaluation
-
- Data and DLKT Model Training
- Pair‑Level Evaluation
-
- Consistency Experiment
- Deletion Experiment
- Skill‑Level Evaluation
-
- Semantic Information
- Relationship Information
- 4.Discussion
-
- Summary of the Key Findings
- Potential Application
- Conclusion
- 参考文献
- 笔记
前言
为了解决当今DLKT模型的“黑箱”问题,提出了一种利用可解释人工智能(xAI)技术的解释方法。具体而言,解释方法侧重于从DLKT模型的顺序输入的角度理解其预测。
我们进行了综合评估,以验证所提出的解释方法在技能-答案对水平的可行性和有效性。此外,解释结果还捕捉了技能级别的语义信息,包括技能特定的差异、距离和内部关系。
对比参考:
【阅读笔记】应用LRP,通过将相关性从模型的输出层反向传播到其输入层来解释基于RNN的DKT模型
1.LPR Method
Weighted Linear Connection
一般形式:a = f (Wh + Wx + b)
其中f()为深度学习模型中常用的激活函数。假设激活函数不改变相关性分布,则加权连接可进一步表示为:
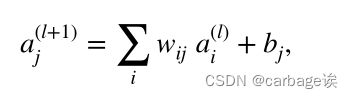
相关性计算:
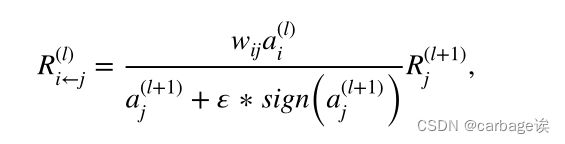
Multiplicative Connection
这里是与作者2020年Towards Interpretable Deep Learning Models for Knowledge Tracing论文中LRP方法最大的不同
一般形式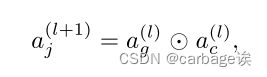
在前馈方向上,“门”神经元和“源”神经元共同决定应该保留多少信息,并最终对模型的决策做出贡献。对于解释过程,之前的研究简单地将全部功劳归于“源”神经元。我们主张“门”神经元和“源”神经元都应该接受上层的积分。前馈过程(即预测过程)中,“门”神经元和“源”神经元共同决定了上层的输出,因此在反向传播过程(即解释过程)中,两个神经元的贡献不可忽视。相关性分布如下: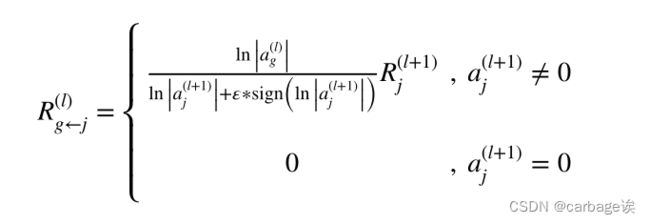
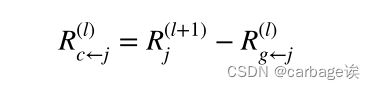
2.Interpreting DKT Models using LRP Method
LSTM中具有两种连接类型的前馈预测路径和解释其预测结果的反向传播路径

计算式:
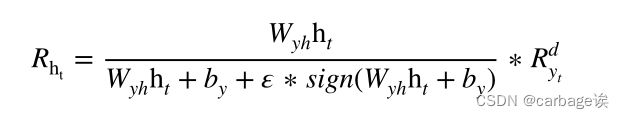
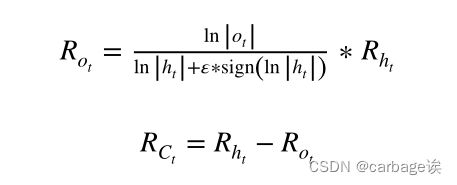
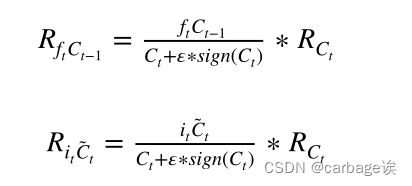



最后一步是将上面四个相关值相加,得到输入xt与输出yt在第d维的相关性:

Example
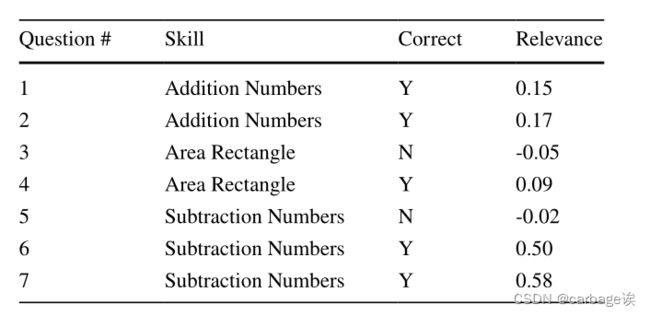
以实际数据为例,对分析结果进行了验证。给定一个经过训练的数学DLKT模型和一个学习者的练习序列作为输入,输入序列由七个连续的技能-答案对组成,其中的问题测试三种不同的技能。下表显示了问题ID、相应的技能以及学习者是否正确回答问题。假设第8个问题是关于技能减数的测试,构建的DLKT模型预测学习者会正确回答这个问题。通过执行所提出的解释方法,每个输入对(即从第1对到第7对)的计算相关值在表1的最后一列中给出。计算出的相关值可以是正的,也可以是负的,范围从-0.05到0.58。
更重要的是,这些价值观与答案的正确性和测试技能密切相关。例如,第7题测试相同的技能(即减法数),且答案正确,对应的相关值0.58为正且较大。第三个问题测试了不同的技能(即面积矩形),并被错误回答,对应的相关值-0.05为负且较小。
这个案例展示了充分理解解读结果的可能性和必要性,从而对其进行综合评价。
3.Evaluation
验证采用LRP方法解释DLKT模型预测结果的可行性
Data and DLKT Model Training
dataset:ASSISTment 2009-2010
具体来说,使用它的数学“技能构建”数据集,过滤掉所有重复的练习序列和没有标记技能的练习序列。最终,用于训练和测试DLKT模型的数据集由4151名学生的325,637个回答记录组成,涉及26,688个问题,涉及110项技能。
DLKT模型采用LSTM结构,隐含维数为256。
在训练过程中,mini-batch size和dropout分别设置为20和0.5。模型训练采用Adam优化算法,迭代次数设置为500,初始学习率设置为0.01。
建立DLKT模型并进行五倍交叉验证,其AUC、ACC和f1得分分别为0.75、0.72和0.79。在乘法连接上执行所设计的解释算法时,稳定器中的参数ε可调大一点,以保持“门”神经元接收到的相关性低于“源”神经元。
在解释任务中,总共使用了48673个练习序列,每个序列由15个独立的技能-答案对组成。对于每个序列,将其前14对技能-答案作为所构建DLKT模型的输入,最后一对技能-答案作为基础真理,验证模型对第15题的预测。DLKT模型正确预测了34292个序列的最后一个问题,其中正预测数和负预测数分别为25015和9277。然后在配对级别和技能级别进行评估。
Pair‑Level Evaluation
Consistency Experiment
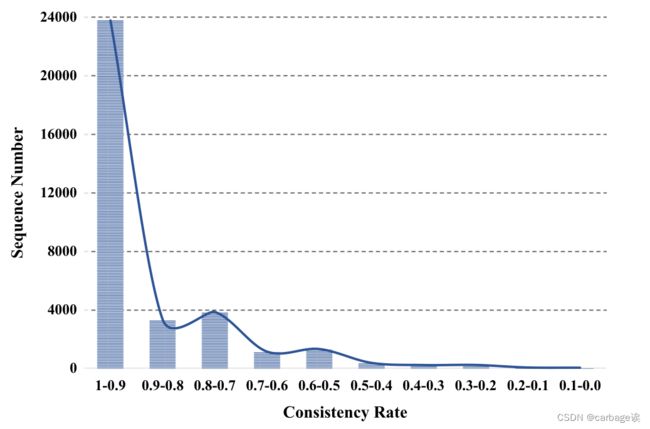
直观地说,一个正确回答的问题将对预测结果提供积极的贡献,因此计算出的相关性应该是一个正的值。相反,错误回答的问题应该被赋予负相关性值,因为它对预测结果的贡献是负的。进行了第一个实验来验证它。具体地说,在输入练习问题中定义一致性问题,假定它是“正确回答的具有正相关性值的问题”或“错误回答的具有负相关性值的问题”。因此,计算练习序列中一致问题的百分比,并将其命名为序列的一致率。显然,较高的一致性反映了大多数正确回答的问题被赋给了正相关性值,而大多数错误回答的问题被赋给了负相关性值。
利用所有34292个正确预测序列,采用所提出的解释方法计算其技能-答案对的相关值,然后计算每个序列的一致性率。下图显示了技能-答案对输入序列的一致性率的直方图。很明显,大多数序列实现了90%(或以上)的一致性率,而只有少数序列具有较低的一致性率。因此,实验结果验证了得到的相关值的符号与问题是否被正确回答高度相关。从上面的例子中,所有正确回答的问题都获得了正相关性值,而两个错误回答的问题获得了负相关性值。
Deletion Experiment
例子还表明,相关值的数量可能反映了对应的技能-答案对对模型预测的重要性。因此,设计了另一个实验来观察DLKT模型在删除特定技能-答案对时预测性能的变化。如前所述,在解释数据集中,34292个序列被正确预测,其中正预测和负预测分别为25015和9277。对于正向预测组(即最后一个问题被正确回答的25,015个序列),将每个序列中的技能-答案对按相关性值排序,并按递减顺序删除对(即先删除最大的正向答案)。同样,我们将阴性预测组中的每个序列(即最后一个问题被错误回答的9277个序列)根据相关性值进行排序,并按递增顺序删除对(即先删除最大的阴性序列)。此外,进行了随机配对删除,然后比较模型的性能。下图通过跟踪模型在删除配对数量上的准确性,说明了两组的比较结果。可以看到,对于两组来说,使用基于关联的方法删除技能回答对,与使用随机方法相比,显著降低了模型的准确性。换句话说,具有较大关联值的技能-答案对通常对模型的最终预测有更强的影响。
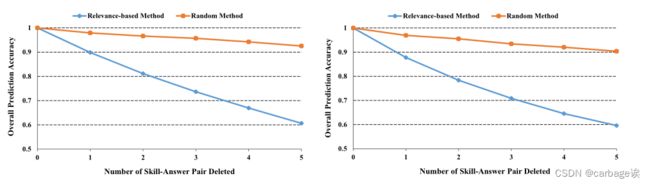
进一步将剩余的14,381个被错误预测的序列放在解释数据集中,包括7,591个阳性预测和6,790个阴性预测。对于正预测组,即序列中最后一个问题回答错误,但模型预测答案正确的,将每个序列中的对根据相关性排序,并按递减顺序删除,然后将结果与随机方法的结果进行比较。对于阴性预测组,进行了类似的实验,但按递增顺序删除每个序列中的对。下图通过跟踪模型在删除配对数量上的准确性,说明了两组的比较结果。可以看到,对于两组来说,使用排序相关性值删除技能-答案对显著提高了模型的准确性,与使用随机方法相比。因此,所有的删除实验都验证了相关性值表明对应对对模型预测的重要性。

简而言之,一致性实验和删除实验验证了计算的相关值定性和定量地捕捉了对模型预测的对级贡献。简单地说,相关性的符号决定了对应的技能-答案对是否支持模型的正向预测(即正确回答下一个问题)。如果符号为正,相应的技能-答案对倾向于增加模型的正预测的概率。如果符号为负,相应的技能-答案对倾向于降低模型的积极预测的概率。同时,相关性的绝对值反映了相应技能-答案对的数量增加或减少了正向预测的概率。因此,该方法对DLKT模型的解释是可行和有效的。
Skill‑Level Evaluation
Semantic Information
基于之前的发现,进一步检查相关值是否捕获了来自模型输入的语义信息。正如前面提到的,每个技能回答对通常测试一个特定的技能(例如,“整数排序”或“整数相加”),并且在每个顺序中,不同的对可能测试相同或不同的技能。定义最后一对测试的技能,即第15对技能回答,作为预测技能。在每个序列的前14对中,计算测试序列中预测技能的对的数量。仍然使用前面实验中正确预测的34292个序列,下图显示了计数结果的分布,其中正预测和负预测分别显示。可以发现,无论是积极的预测组还是消极的预测组,预测技能的技能-答案序列可能有不同的数量(从1到13)。例如,在阳性预测组中,超过2000个序列只有一对预测技能,而只有大约550个序列有13对预测技能。换句话说,大多数单个序列包含多个技能。直观地看,学习者之前在预测技能方面的表现很重要,这样的技能回答对比序列中的其他对对最终预测的贡献更大。因此,进行了一个实验来研究解释结果是否能捕捉到这一现象。

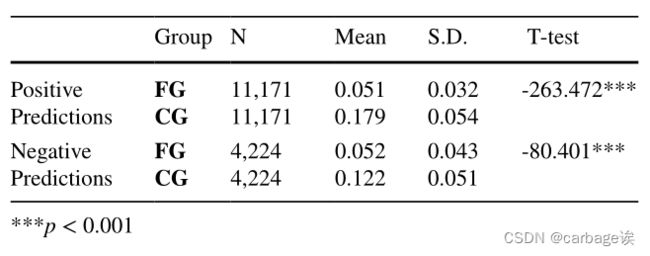
对于每个序列,我们取所有配对在预测技能上的计算相关值,然后简单地计算它们绝对值的平均值。将不同序列的所有计算均值放入同一技能组(SKG)中。同样,我们计算每个序列中所有其他对的平均值,并将所有计算的平均值放入不同的技能组(DKG) (即对每一个序列,计算与第15个技能对相同的相关性的平均值与不同的平均值进行比较)。然后进行双尾t检验,下表总结了结果。在正向预测方面,SKG组的均值显著高于DKG组(t = 149.914, p < .001)。对于阴性预测,SKG组的平均值也显著高于DKG组(t = 40.538, p < .001)。这些结果验证了相关值可以反映出对预测技能的重要性。这一发现也表明,在特定技能预测任务下,解释结果可以部分捕获技能-答案对的语义。需要注意的是,在本实验中,去掉了预测技能上0对和14对的序列,因为无法计算SKG组和DKG组的平均值。

此外,还考察了计算出的相关值是否能够意识到对应的对与用于预测的最后一个问题之间的距离。具体来说,简单地将每个序列中的前7对作为远对,后7对作为近对。对于每个序列,取测试预测技能的远对的所有相关值,并计算它们绝对值的平均值。将所有正确预测序列的计算平均值放入远组(FG)中。类似地,从每个序列的最后7对中组成接近组(CG)。然后我们进行双尾t检验,下表总结了结果。对于积极预测,CG的平均值显著高于FG的平均值(t = -263.472, p < .001)。对于负面预测,CG的均值也显著高于FG的均值(t = -80.401, p < .001)。结果表明,越接近最后一个问题进行预测的技能-答案对往往获得更大的相关性值,这在直觉上是合理的。注意,在这个实验中,删除了前7对或后7对中预测技能上没有任何配对的序列。
Example
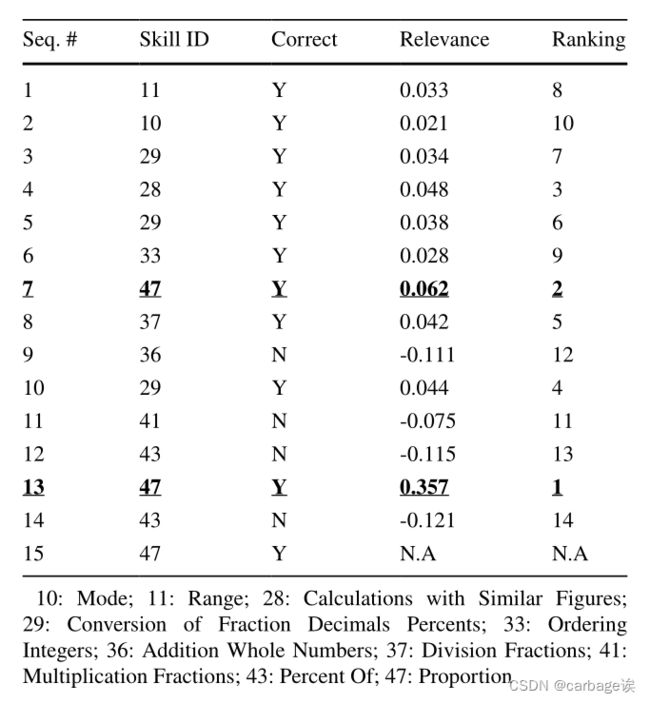
下表展示了一个具体的例子。可以看到,预测的技能是比例(即技能ID为47的第15对),这是正确的回答和预测。前14对包含10种不同的技能(例如,加法或乘法整数),其中只有第7对和第13对直接测试技能比例。如果两对回答都正确,那么它们的相关值(第13对0.357,第7对0.062)都是正的,是所有相关值中最大的。此外,第13对的相关性值明显大于第7对的相关性值,这意味着它对DLKT模型的最终预测贡献最大。
Relationship Information
在已有研究的基础上,进一步研究了解释结果是否能够保留技能的内在联系,并获取有意义的信息,特别是在诊断目的上。在实践中,对于某些技能A和B,学习者如果不能理解技能B,就很难理解技能A。在这种情况下,两种技能往往是密切相关的,它们之间可能存在先决条件或包含关系。因此,设计了一种简单的方法,利用前面的解释结果来识别技能之间的这种关系。具体来说,在每个正确预测序列的前14对技能回答中,选择所有与预测技能不同的错误回答对。然后根据技能对这些技能进行分组,找出负值最大的技能。因此,对于每个预测技能,获得另一个技能,称为相邻技能。对于每个预测技能,都可能有多个从不同序列派生的相邻技能,并且一个预测技能可能是另一个预测技能的相邻技能。预测技能和相邻技能以及它们的有向联系可以进一步表述为一个有向技能特异性诊断图,其中技能为节点,每个有向链接从相邻技能开始,到预测技能结束。下图展示了由名为Ucient的社交网络分析工具(Borgatti et al, 2002)自动生成的使用最频繁链接的技能的图表。
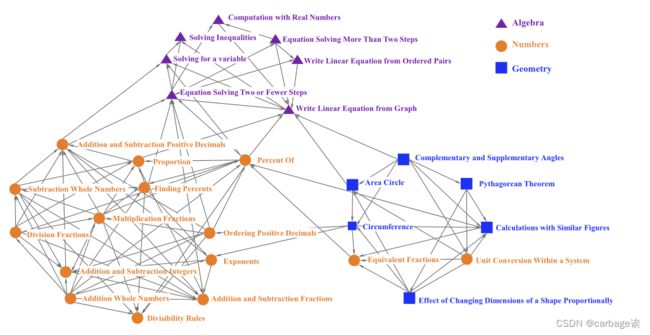
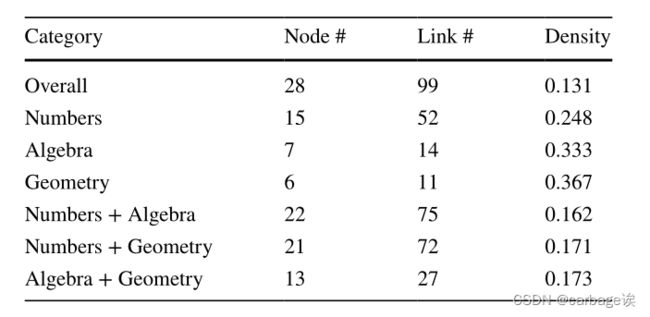
很明显,可以看到这些技能通常被分成三个组,每个组大致对应一个更高层次的数学类别,即数字、代数和几何。虽然数字类的一些技能与几何类的技能混合在一起,但每个集群内部的链接明显多于集群之间的链接。下表总结了不同类别的网络密度。作为社会网络分析中用来描述网络连通性的常用指标,网络密度被定义为网络中现有链接与所有可能链接的比例。可以看到整体网络密度为0.131,而每个类别的密度都要大得多。例如,几何类和代数类的密度分别为0.367和0.333。
此外,在图表中看到了许多技能之间有意义的联系。例如,多个技能被定向到数字集群中的技能加减分数。此外,技能百分比和写线性方程在三个聚类的中心位置,这表明他们可能在学习这些技能中起桥梁作用。此外,图上的每个预测技能都有许多相邻的技能。例如,两个相邻技能,即解两步以上的方程和解两步或更少的方程,是预测技能的相邻技能,从有序对写线性方程。从原始的技能-答案配对序列中,也可以找到错误率较高的技能。因此,每个预测技能都有两个技能集,即相邻技能集和错误技能集。然后,将覆盖率定义为两个技能集中的技能数量除以错误技能集中的技能数量。
对于图上的所有预测技能,平均覆盖率约为0.79,这表明图可以捕捉到大多数与预测技能相关的易出错技能。请注意,该实验是在ASSISTment 2009的技能构建数据集上运行的,其中的问题按一些序列中的更高级别类别分组。由于解译方法倾向于最近的技能,只选择最相关的技能(即负相关性值最大的技能),数据集的这一特性可能会降低识别跨类关系的可能性。
4.Discussion
Summary of the Key Findings
针对现有DLKT模型决策过程不透明的问题,采用xAI技术对模型预测进行解释。所设计的事后解释方法一般适用于广泛的DLKT模型。利用LSTM结构在DLKT模型上实现了所提出的解译方法,并通过综合实验验证了解释结果。从配对的角度来看,发现大多数输入序列具有较高的一致性率,这意味着大多数正确回答的问题被分配为正相关性值,而大多数错误回答的问题被分配为负相关性值。此外,相关值表示对应的技能-答案对对模型最终预测的重要性。从技能水平的角度,发现解释结果能够从输入中获取语义信息,包括技能相关的差异、距离和内部关系。因此,判读结果可以帮助识别与预测技能相关的易出错技能。综上所述,确认所提出的解释方法的有效性是合理的。
Potential Application
所获得的解释结果在支持教育中的各种智能服务和应用方面具有很大的潜力。假设一个DLKT模型建立在某一学科(如几何)的某一类技能上,并且有一个新学习者的练习序列,其中关于技能K的最后一个问题回答错误,计算出的相关值和生成的技能特异性诊断图可以直接用来发现当前新学习者可能存在的薄弱技能。下图演示了一个简化的诊断工作流。诊断服务首先将除最后一对外的整个序列作为DLKT模型的输入,并据此获得最后一个问题的正确概率。如果模型的预测与实际情况相冲突,它可能需要来自当前学习者的更多练习信息或更精确的DLKT模型。否则,服务可以开始执行解释方法,为所有输入对生成相关值。

在输入的技能-答案对中,对负相关性值较大的对进行检查,以确定它们中是否至少有一个测试了相同的技能K。如果是,系统可以将技能K添加到可疑的弱技能集合中。此外,如果在诊断图中还能找到其他具有较大负相关值的配对,且指向技能K,也会被加入到可疑弱技能集合中。这些可疑的弱技能可以直接提供给学习者或教师,也可以用来构建ITS或MOOC平台的推荐引擎。它们还可以通过引入专家经验或教育关系信息,如前提关系或包含关系,来分析K技能薄弱的可能根源。这个例子也说明了解释结果可以用来提供单个学习者的技能掌握信息(如可疑技能),而大多数DLKT模型不能直接输出技能掌握信息,只能输出下一题的预测正确性。
Conclusion
在论文中,设计了一种用于知识追踪的事后解释方法,该方法可应用于一般的基于rnn的DLKT模型。通过使用反向传播机制将模型输出逐步映射到输入层,解释方法为每个单独的输入技能-答案对分配一个相关值。在配对水平和技能水平上进行了综合实验来评估所提出的方法。评价结果表明,所分配的相关值定性和定量地捕捉了对模型预测的对级贡献。此外,它们还可以从模型输入中获取技能级别的语义信息,包括技能特定的差异、距离和内部关系。
参考文献
本文章文字大部分为论文翻译内容,加上个人学习过程中的重点标识,方便后期回顾理解
Lu Y, Wang D, Chen P, et al. Interpreting deep learning models for knowledge tracing[J]. International Journal of Artificial Intelligence in Education, 2022: 1-24.
笔记
验证使用事后解释方法解释模型预测结果的可行性:
- 通过实验了解事后解释方法解释结果与模型预测结果之间的关系
- 进行了数据(问题)删除实验,分析结果【加入随机数据(问题)删除,进行对比分析】
- 捕捉技能级别的语义信息:
- 技能特定的差异【学习者之前在预测技能方面的表现很重要,这样的技能回答对比序列中的其他对对最终预测的贡献更大】
- 技能特定的距离【计算出的相关值是否能够意识到对应的对与用于预测的最后一个问题之间的距离】
- 技能特定的内部关系(还未完全理解)