创建自己的图像分割数据集并利用Unet实现图像分割(pytorch)
一、 配置lanelme数据集标注工具
1.安装labelme
labelme安装参考链接,从这个链接中选取你要安装的labelme版本,按照教程操作即可。
注:在安装时候可能出现一些版本报错,这时候只需要按照出现的提示安装指定版本的即可。(也可以直接将结果复制出来百度,一般都很容易解决)
安装成功后在cmd输入labelme就会自动跳出labelme的窗口。


本身的标记操作也很简单。标记好之后直接保存就好。
2. 标记数据导出
标记好的数据是以json数据格式储存。

json数据记录了标记的位置,图片的位置等信息
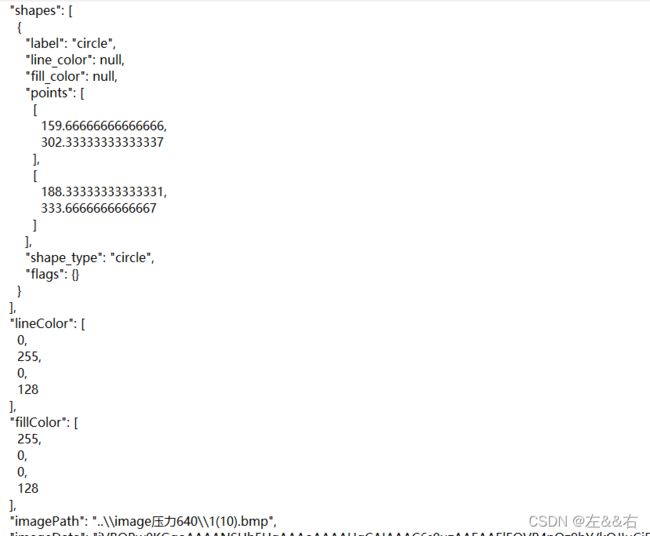
需要利用程序将json导出为标准数据集。
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
import base64
def JSON_to_IMG(json_file, save_file):
"""
将指定目录下的json标注文件全部转换为以下文件:①jpg原图文件、 ②png标签文件
③其他相关说明文件 。存储在指定路径下
:param json_file: Json格式所在文件夹
:param save_file: 转换后的文件存储文件夹
"""
#如果存储路径不存在就创建文件目录
if not osp.exists(save_file):
os.mkdir(save_file)
#文件目录下的所有json文件名称
count = os.listdir(json_file)
#遍历目录下的所有json文件
for i in range(0, len(count)):
#获取json文件全路径名称
path = os.path.join(json_file, count[i])
#如果是imagedata格式文件进行读取
if os.path.isfile(path):
#打开json文件
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
#将图片中背景赋值为0
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
#获取json文件名并将.json改为_json用作文件夹目录
#out_dir = osp.basename(count[i]).replace('.json', '.png')
out_pic_name = str(i) + ".png"#原图
out_label_name = str(i) + "label.png"#标签图
out_label_viz_name = str(i) + "_label_viz.png"#带标注的图片
out_labeltxt_name = str(i) + "_label_names.txt"#标签名对应值
out_info_name = str(i) + "_info.yaml"
#在目标文件夹下保存原始图片
PIL.Image.fromarray(img).save(osp.join(save_file, out_pic_name))
#保存标签图片
utils.lblsave(osp.join(save_file, out_label_name), lbl)
#保存带标注的可视化图片
PIL.Image.fromarray(lbl_viz).save(osp.join(save_file, out_label_viz_name))
with open(osp.join(save_file, out_labeltxt_name), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(save_file, out_info_name), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('完成了对Json文件: %s的IMG格式转换!' % osp.basename(count[i]))
print("指定目录下的所有JSON文件完成转换!")
#程序主入口
json_file = r"E:\lu\dataset\original\lu\json"#这里json文件所在文件夹的全路径
save_file = r"E:\lu\dataset\original\lu\dataset"#这里填写转换后文件保存的文件夹全路径
JSON_to_IMG(json_file, save_file)#调用上方定义的转换函数完成批量转换
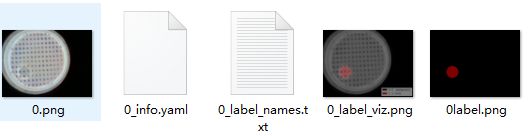
上述程序在notebook中实现,将json文件所在路径下所有的json文件转化为如下所示格式
二、实现数据标注后图像分割建立数据集
1.利用Java实现将单一目录下的图案与分割后图片对应输出为csv文件。
import org.apache.commons.compress.archivers.dump.InvalidFormatException;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.*;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class TakeFilePathAndName {
public static void main(String[] args) throws IOException {
// This is the path where the file's name you want to take.
String path = "E:\\lu\\dataset\\original\\lu\\dataset";
// get file list where the path has
File file = new File(path);
// get the folder list
File[] array = file.listFiles();
Workbook worktrain = new HSSFWorkbook();
Sheet trainsheet = worktrain.createSheet("sheet1");
int traincount = 0;
for (int i = 0; i < array.length; i++) {
if(array[i].getName().endsWith(".png")&array[i].getName().length()<9){
Row trainsheetRow = trainsheet.createRow(traincount);
String stringCellValue = array[i].getName();
Cell trainsheetRowCell = trainsheetRow.createCell(0);
trainsheetRowCell.setCellValue(stringCellValue);
Cell trainsheetRowCell1 = trainsheetRow.createCell(1);
trainsheetRowCell1.setCellValue(stringCellValue.replace(".png","label.png"));
traincount++;
}
}
File trainFile = new File("E:\\lu\\dataset\\original\\lu\\excell\\train.xls");
FileOutputStream trainStream = new FileOutputStream(trainFile);
worktrain.write(trainStream);
}
}
上述代码在运行时候可能会出现某些包不存在的情况,因为java实现excel操作需要一些其它的包的依赖。这里我建立了一个idea的maven工程,pom文件具体依赖配置如下。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>pythonutils</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>6</source>
<target>6</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.2</version>
</dependency>
</dependencies>
</project>
这是java的实现,是因为我对java比较熟悉,也可以用python,c等语言实现。(csv的分割符为,所示实现方式很多)具体就是读取某一目录下的文件,然后根据一定法则筛选出输入图片以及对应的标签图片,然后保存为.csv文件。
输出.csv文件格式如下所示,第一列为输入图片,第二列为标签图片:

三、利用FCN实现数据分割
深度学习网络只需要确定三个东西即可,输入,输出,网络。
这里我们的输入是原始图片,输出是图像分割,网络采用Unet。
代码如下:
from dataloader import rgbSensorDataset,ToTensor
from torchvision import transforms, utils
from torch.utils.data import Dataset, DataLoader
from net import ResNetUNet
from collections import defaultdict
import torch.nn.functional as F
from loss import dice_loss
import torchvision.utils
import torch
import torch.optim as optim
from torch.optim import lr_scheduler
import time
import copy
import math
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
from skimage import io
from PIL import Image
csv_file_train = 'E:\lu\dataset\original\lu\excell\\train.csv'
csv_file_test = 'E:\lu\dataset\original\lu\excell\\test.csv'
images_folder_train = 'E:\lu\dataset\original\lu\dataset\\'
images_folder_test ='E:\lu\dataset\original\lu\dataset\\'
train_set = rgbSensorDataset(csv_file = csv_file_train,
root_dir = images_folder_train,
transform=transforms.Compose([
transforms.ToTensor()
]))
val_set = rgbSensorDataset(csv_file = csv_file_test,
root_dir = images_folder_test,
transform=transforms.Compose([
transforms.ToTensor()
]))
batch_size = 4
dataloaders = {
'train': DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=2),
'val': DataLoader(val_set, batch_size=batch_size, shuffle=True, num_workers=2,drop_last=True)}
def calc_loss(pred, target, metrics, bce_weight=0.5):
bce = F.binary_cross_entropy_with_logits(pred, target)
pred = F.sigmoid(pred)
dice = dice_loss(pred, target)
loss = bce * bce_weight + dice * (1 - bce_weight)
metrics['bce'] += bce.data.cpu().numpy() * target.size(0)
metrics['dice'] += dice.data.cpu().numpy() * target.size(0)
metrics['loss'] += loss.data.cpu().numpy() * target.size(0)
return loss
def print_metrics(metrics, epoch_samples, phase):
outputs = []
for k in metrics.keys():
outputs.append("{}: {:4f}".format(k, metrics[k] / epoch_samples))
print("{}: {}".format(phase, ", ".join(outputs)))
def train_model(model, optimizer, scheduler, num_epochs=25):
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = 1e10
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
since = time.time()
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
for param_group in optimizer.param_groups:
print("LR", param_group['lr'])
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
metrics = defaultdict(float)
epoch_samples = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = calc_loss(outputs, labels, metrics)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
epoch_samples += inputs.size(0)
print_metrics(metrics, epoch_samples, phase)
epoch_loss = metrics['loss'] / epoch_samples
# deep copy the model
if phase == 'val' and epoch_loss < best_loss:
print("saving best model")
best_loss = epoch_loss
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('{:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val loss: {:4f}'.format(best_loss))
# load best model weights
model.load_state_dict(best_model_wts)
return model
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
num_class = 1
model = ResNetUNet(n_class=1)
model = nn.DataParallel(model)
model = model.to(device)
# freeze backbone layers
#for l in model.base_layers:
# for param in l.parameters():
# param.requires_grad = False
optimizer_ft = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-4)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=30, gamma=0.1)
model = train_model(model, optimizer_ft, exp_lr_scheduler, num_epochs=60)
torch.save(model.state_dict(), 'E:\\lu\\dataset\\original\\lu\\saved_models\\re.pth')
由于我使用的是notebook,这里以代码段的方式将代码贴出。
在运行时候需要网络的依赖,网络代码如下:
import torch
import torch.nn as nn
from torchvision import models
def convrelu(in_channels, out_channels, kernel, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel, padding=padding),
nn.ReLU(inplace=True),
)
class ResNetUNet(nn.Module):
def __init__(self, n_class):
super().__init__()
self.base_model = models.resnet18(pretrained=True)
self.base_layers = list(self.base_model.children())
self.layer0 = nn.Sequential(*self.base_layers[:3]) # size=(N, 64, x.H/2, x.W/2)
self.layer0_1x1 = convrelu(64, 64, 1, 0)
self.layer1 = nn.Sequential(*self.base_layers[3:5]) # size=(N, 64, x.H/4, x.W/4)
self.layer1_1x1 = convrelu(64, 64, 1, 0)
self.layer2 = self.base_layers[5] # size=(N, 128, x.H/8, x.W/8)
self.layer2_1x1 = convrelu(128, 128, 1, 0)
self.layer3 = self.base_layers[6] # size=(N, 256, x.H/16, x.W/16)
self.layer3_1x1 = convrelu(256, 256, 1, 0)
self.layer4 = self.base_layers[7] # size=(N, 512, x.H/32, x.W/32)
self.layer4_1x1 = convrelu(512, 512, 1, 0)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv_up3 = convrelu(256 + 512, 512, 3, 1)
self.conv_up2 = convrelu(128 + 512, 256, 3, 1)
self.conv_up1 = convrelu(64 + 256, 256, 3, 1)
self.conv_up0 = convrelu(64 + 256, 128, 3, 1)
self.conv_original_size0 = convrelu(3, 64, 3, 1)
self.conv_original_size1 = convrelu(64, 64, 3, 1)
self.conv_original_size2 = convrelu(64 + 128, 64, 3, 1)
self.conv_last = nn.Conv2d(64, n_class, 1)
def forward(self, input):
x_original = self.conv_original_size0(input)
x_original = self.conv_original_size1(x_original)
layer0 = self.layer0(input)
layer1 = self.layer1(layer0)
layer2 = self.layer2(layer1)
layer3 = self.layer3(layer2)
layer4 = self.layer4(layer3)
layer4 = self.layer4_1x1(layer4)
x = self.upsample(layer4)
layer3 = self.layer3_1x1(layer3)
x = torch.cat([x, layer3], dim=1)
x = self.conv_up3(x)
x = self.upsample(x)
layer2 = self.layer2_1x1(layer2)
x = torch.cat([x, layer2], dim=1)
x = self.conv_up2(x)
x = self.upsample(x)
layer1 = self.layer1_1x1(layer1)
x = torch.cat([x, layer1], dim=1)
x = self.conv_up1(x)
x = self.upsample(x)
layer0 = self.layer0_1x1(layer0)
x = torch.cat([x, layer0], dim=1)
x = self.conv_up0(x)
x = self.upsample(x)
x = torch.cat([x, x_original], dim=1)
x = self.conv_original_size2(x)
out = self.conv_last(x)
return out
dataloader代码如下所示:
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# In[2]:
class rgbSensorDataset(Dataset):
"""RGB dataset """
def __init__(self, csv_file, root_dir, transform = None):
"""
init
"""
self.labels_file = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.labels_file)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
img_name = os.path.join(self.root_dir,self.labels_file.iloc[idx, 0])
image = io.imread(img_name)
# !!! choose the LABEL
#angle = self.labels_file.iloc[idx, 9]
labels_name = os.path.join(self.root_dir,self.labels_file.iloc[idx, 1])
labels = io.imread(labels_name)
if self.transform:
image = self.transform(image)
labels = self.transform(labels[:,:,0])
return [image,labels]
运行后输出如下图所示

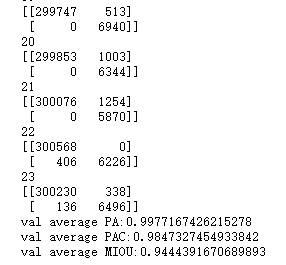
最后将保存的模型加载后将测试集输入查看结果,这里实现了三个评级指标(PA,PAC,MIOU)这些都可以通过混淆矩阵得出。代码如下:
def generate_matrix(gt_image, pre_image,num_class=2):
mask = (gt_image >= 0) & (gt_image < num_class)#ground truth中所有正确(值在[0, classe_num])的像素label的mask
label = num_class * gt_image[mask].astype('int') + pre_image[mask]
# np.bincount计算了从0到n**2-1这n**2个数中每个数出现的次数,返回值形状(n, n)
count = np.bincount(label, minlength=num_class**2)
confusion_matrix = count.reshape(num_class, num_class)#21 * 21(for pascal)
return confusion_matrix
def Pixel_Accuracy(confusion_matrix):
Acc = np.diag(confusion_matrix).sum() / confusion_matrix.sum()
return Acc
def Pixel_Accuracy_Class(confusion_matrix):
Acc = np.diag(confusion_matrix) / confusion_matrix.sum(axis=1)
Acc = np.nanmean(Acc)
return Acc
def Mean_Intersection_over_Union(confusion_matrix):
MIoU = np.diag(confusion_matrix) / (
np.sum(confusion_matrix, axis=1) + np.sum(confusion_matrix, axis=0) -
np.diag(confusion_matrix))
MIoU = np.nanmean(MIoU) #跳过0值求mean,shape:[21]
return MIoU
testcount = 0
PA = 0
PAC = 0
MIOU = 0
for inputs, labels in dataloaders['val']:
inputs = inputs.to(device)
labels = labels.to(device)
pred = model(inputs)
inputs1 = inputs.cpu()
labels1 = labels.cpu().numpy()
pred = F.sigmoid(pred)
pred1 = pred.data.cpu().numpy()
for lenumber in range(batch_size):
# print(testcount)
matrix =generate_matrix(np.clip((np.array(labels1[lenumber].squeeze().transpose(0, 1))*255).astype('uint8'),0,1),np.clip((pred1[lenumber].squeeze().transpose(0, 1)*255).astype('uint8'),0,1))
# print(matrix)
PA = PA + Pixel_Accuracy(matrix)
PAC = PAC + Pixel_Accuracy_Class(matrix)
MIOU = MIOU + Mean_Intersection_over_Union(matrix)
testcount = testcount + 1
print('val average PA:{}'.format(PA/testcount))
print('val average PAC:{}'.format(PAC/testcount))
print('val average MIOU:{}'.format(MIOU/testcount))
得到的混淆矩阵以及评价参数如下图所示;