2021年8月21日 Python图像全景拼接
在《喜羊羊与灰太狼》2021年1月出的一部《运动英雄传之筐出胜利》中,在最后一集的结尾,有一部分对着一个大背景的平移镜头,使用Python可以根据此部分镜头还原出大背景。
喜羊羊与灰太狼之筐出胜利 第60集 冠军
准备工作
导入相关库
import numpy as np
import cv2
import matplotlib.pyplot as plt
from pyod.models.knn import KNN
读取视频中的第一帧
video = cv2.VideoCapture(r'60.mp4') # 读取视频
ret, leftframe = video.read() # 读取帧
由于后期拼接图片需要使用透明度,所以这里将图片转为4通道
b_channel, g_channel, r_channel = cv2.split(leftframe)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
# 最小值为0
#alpha_channel[:, :int(b_channel.shape[0] / 2)] = 100
leftframe = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
#cv2.imshow('leftframe',leftframe)
参考https://blog.csdn.net/qq878594585/article/details/81901703,首先要检测图片的关键特征点。现在SIFT可在cv2中直接使用,参考https://www.dtmao.cc/news_show_359297.shtml
hessian=400
surf=cv2.SIFT_create(hessian) #将Hessian Threshold设置为400,阈值越大能检测的特征就越少
# 更新openCV版本即可使用SIFT,参考https://www.dtmao.cc/news_show_359297.shtml
kp1,des1=surf.detectAndCompute(leftframe,None) #查找关键点和描述符
读取下一帧后同样的操作
ret, rightframe = video.read() # 读取下一帧
b_channel, g_channel, r_channel = cv2.split(rightframe)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
# 最小值为0
#alpha_channel[:, :int(b_channel.shape[0] / 2)] = 100
rightframe = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
print("frameshape:",leftframe.shape,rightframe.shape)
kp2,des2=surf.detectAndCompute(rightframe,None) #查找关键点和描述符
# frameshape: (1080, 1920, 4) (1080, 1920, 4)
计算关键点偏移向量
这里继续参考https://blog.csdn.net/qq878594585/article/details/81901703
FLANN_INDEX_KDTREE=0 #建立FLANN匹配器的参数
indexParams=dict(algorithm=FLANN_INDEX_KDTREE,trees=5) #配置索引,密度树的数量为5
searchParams=dict(checks=50) #指定递归次数
#FlannBasedMatcher:是目前最快的特征匹配算法(最近邻搜索)
flann=cv2.FlannBasedMatcher(indexParams,searchParams) #建立匹配器
matches=flann.knnMatch(des1,des2,k=2) #得出匹配的关键点
good=[]
#提取优秀的特征点
for m,n in matches:
if m.distance < 0.7*n.distance: #如果第一个邻近距离比第二个邻近距离的0.7倍小,则保留
good.append(m)
src_pts = np.array([ kp1[m.queryIdx].pt for m in good if kp2[m.trainIdx].pt[1]<=933]) #查询图像的特征描述子索引
dst_pts = np.array([ kp2[m.trainIdx].pt for m in good if kp2[m.trainIdx].pt[1]<=933]) #训练(模板)图像的特征描述子索引
#H=cv2.findHomography(src_pts,dst_pts) #生成变换矩阵
h,w=leftframe.shape[:2]
h1,w1=rightframe.shape[:2]
获取所有检测到的关键点偏移向量
sandian=dst_pts-src_pts
print("sandian:",sandian.shape)
# sandian: (298, 2)
如果把这些散点在图上表示出来是这样的
import mpl_toolkits.axisartist as axisartist
from matplotlib.patches import ConnectionPatch
# https://zhuanlan.zhihu.com/p/40399870
fig=plt.figure()
#使用axisartist.Subplot方法创建一个绘图区对象ax
ax1=axisartist.Subplot(fig,121)
ax2=axisartist.Subplot(fig,122)
#fig,(ax1,ax2)=plt.subplots(1,2)
for ax in (ax1,ax2):
#通过set_visible方法设置绘图区所有坐标轴隐藏
#ax.axis[:].set_visible(False)
#ax.new_floating_axis代表添加新的坐标轴
ax.axis["x"] = ax.new_floating_axis(0,0)
ax.axis["x"].toggle(all=False)
#给x坐标轴加上箭头
ax.axis["x"].set_axisline_style("-|>", size = 1.0)
#添加y坐标轴,且加上箭头
ax.axis["y"] = ax.new_floating_axis(1,0)
ax.axis["y"].toggle(all=False)
ax.axis["y"].set_axisline_style("-|>", size = 1.0)
#设置x、y轴上刻度显示方向
#ax1.axis["x"].set_axis_direction("top")
ax.axis["y"].set_axis_direction("right")
#plt.subplot(1,2,1)
ax1.scatter(*sandian.T)
#plt.subplot(1,2,2)
ax2.scatter(*sandian.T)
ax2.set_xlim(-1,1)
ax2.set_ylim(-1,1)
#将绘图区对象添加到画布中
fig.add_axes(ax1)
fig.add_axes(ax2)
fig.tight_layout(pad=2)
# https://matplotlib.org/stable/gallery/userdemo/connect_simple01.html#sphx-glr-gallery-userdemo-connect-simple01-py
for i in [(-1,-1),(-1,1)]:
con=ConnectionPatch(i,i,ax1.transData,ax2.transData)
fig.add_artist(con)

可以看到大部分的散点都集中在一小部分区域,只有几个异常点,需要将异常点排除,然后取平均值得到最终的平移向量,这里参考https://blog.csdn.net/weixin_42199542/article/details/106885459的方法。
# 参考:https://blog.csdn.net/weixin_42199542/article/details/106885459
clf = KNN(0.5)
clf.fit(sandian)
y_test_pred = clf.predict(sandian)
sandian=sandian[y_test_pred==0]
# 取平均值得到平移向量
pingyi=np.mean(sandian,0)
print("pingyi:",pingyi)
plt.scatter(*sandian.T)
plt.scatter(*pingyi,c='red')
# pingyi: [0.30781024 0.24436529]

准备合成
后续要用到的变量:
h,w是原有图片的高和宽
h1,w1是新图片的高和宽
zuo为原有图片需要平移的向量
you为新图片需要平移的向量
rows和cols是合成大图的高和宽
pingyi是由新图片的左上角指向原有图片左上角的向量(np.array的坐标系以左上角作为原点)
随着图像的平移,坐标系可能会发生变化,这里用一张图来说明一下。

(黑色是原有图片,红色是新图片,绿色是合成的大图,蓝色是pingyi)
此图中,pingyi在x轴方向上的数值(即pingyi[0])是小于0的,此时新图片应向右侧平移,即向x轴正方向平移,同时大图的宽度(cols)为pingyi在x轴方向上的数值的绝对值+新图片的宽度(w1);
而pingyi在y轴方向上的数值(即pingyi[1])是大于0的,此时原有图片向下平移,即向y轴正方向平移,同时大图的高度(rows)为pingyi
在y轴方向上的数值的绝对值+原有图片的高度(h)。
rows,cols=0,0
zuo,you=[0,0],[0,0]
for i in [0,1]:
if pingyi[i]>0:
zuo[i]=pingyi[i]
else:
you[i]=-pingyi[i]
if pingyi[1]<0:
if h1 + abs(int(round(pingyi[1]))) > rows:
rows = h1 + abs(int(round(pingyi[1]))) # 扩展底图
else:
if h + abs(int(round(pingyi[1]))) > rows:
rows = h + abs(int(round(pingyi[1])))
if pingyi[0]<0:
if w1 + abs(int(round(pingyi[0]))) > cols:
cols = w1 + abs(int(round(pingyi[0])))
else:
if w + abs(int(round(pingyi[0]))) > cols:
cols = w + abs(int(round(pingyi[0])))
print("rows:",rows,"cols:",cols)
# rows: 1080 cols: 1920
分析图片
在镜头移动的过程中不断有字幕产生遮挡画面,因此合成时若镜头向下移动,则应用新图片覆盖原有图片,从而遮挡字幕;若镜头向上移动,则应用原有图片覆盖新图片,防止字幕露出。
具体代码如下:
(由于最终此部分放到函数中执行,所以若单独执行,则应先执行leftgray,rightgray=leftframe,rightframe)
镜头向下移动时,先将原有图片平移并扩大,之后将新图片覆盖上去。
if pingyi[1]<0:
M = np.float32([[1,0,zuo[0]],[0,1,zuo[1]]])
leftdst = cv2.warpAffine(leftgray,M,(cols,rows),borderValue=(0,0,0,0))
#cv2.namedWindow('leftdst', 0)
#cv2.imshow('leftdst',leftdst)
#cv2.namedWindow('rightdst', 0)
#cv2.imshow('rightdst',rightdst)
print("dstshape:",leftdst.shape)
weizhix=abs(int(round(you[0])))
weizhiy=abs(int(round(you[1])))
print("weizhi:",weizhix,weizhiy)
#cv2.imwrite(r'leftdst.png',leftdst)
#cv2.imwrite(r'rightgray.png',rightgray)
leftdst[weizhiy:weizhiy+h1,weizhix:weizhix+w1]=rightgray[:,:]
镜头向上移动时,先将新图片平移并扩大,再根据原有图片的透明度将原有图片覆盖上去,最终显示的图像为原有图片*原有图片的透明度+新图片*(1-原有图片的透明度),由于此场景下透明度只有不透明和透明,所以最终显示图像的透明度为原有图片和新图片透明度的并集。这里透明度图层的数值为最大255的整数,通过运算后达到并集的效果。
else:
M = np.float32([[1,0,you[0]],[0,1,you[1]]])
rightdst = cv2.warpAffine(rightgray,M,(cols,rows),borderValue=(0,0,0,0))
print("dstshape:",rightdst.shape)
weizhix=abs(int(round(zuo[0])))
weizhiy=abs(int(round(zuo[1])))
print("weizhi:",weizhix,weizhiy)
#rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,:3]=leftgray[:,:,:3]
#rightdst=cv2.addWeighted(rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w],leftgray[:,:,2],leftgray[:,:,:3],1-leftgray[:,:,2],0)
alpha = leftgray[:,:,3] / 255.0
#print(alpha[:10,:10])
#result = np.zeros(rightdst.shape[:2]+(4,))
#cv2.imshow('result',result)
#cv2.imwrite(r'rightdst.png',rightdst)
#cv2.imwrite(r'leftgray.png',leftgray)
#cv2.waitKey(1000)
print(rightdst.shape[:2]+(4,),leftgray.shape)
print(rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0].shape)
print(leftgray[weizhiy:weizhiy+h,weizhix:weizhix+w,1].shape)
print(weizhiy,weizhiy+h,weizhix,weizhix+w)
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0] + alpha * leftgray[:,:,0]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,1] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,1] + alpha * leftgray[:,:,1]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,2] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,2] + alpha * leftgray[:,:,2]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3] = (1 - (1-rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3]/255) * (1-leftgray[:,:,3]/255)) * 255
加入循环
对于合成后的图片,需要再将其与第三张图合成,此时若对原合成图片再次检测关键点,则会浪费大量内存、延长代码运行时间,并且由于图片过大,关键点不集中,最终的效果会不理想。基于每相邻两帧的画面都有重叠部分,因此可以不考虑整张大图的其他部分的关键点,可以将上一张新图片中检测到的关键点位移后作为下一次检测的原有图片的关键点。
global kp1,des1,rows,cols
kp1,des1=kp2,des2
for j in kp1:
j.pt=(j.pt[0]+you[0],j.pt[1]+you[1])
if pingyi[1]<0:
return leftdst
else:
return result
将上述过程定义为pinjie函数,然后加入循环读取视频中的每一帧进行合成。
i=0
while 1: # 逐帧读取
ret, rightframe = video.read() # 读取下一帧
if not ret:
break
b_channel, g_channel, r_channel = cv2.split(rightframe)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
# 最小值为0
#alpha_channel[:, :int(b_channel.shape[0] / 2)] = 100
rightframe = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
#cv2.imshow('frame',frame)
#if i%5==0:
print(i)
leftframe=pinjie(leftframe,rightframe)
#cv2.namedWindow('dst', 0)
#cv2.imshow('dst',leftframe)
#cv2.waitKey(1000)
print()
cv2.imwrite(r'dst.png',leftframe)
i+=1
初次结果
首次正式运行,结果是这样的:(原图过大无法插入,这里是缩小后的图片)

问题一分析
可以看到,在图像的边缘出现了黑边,并且放大后可以看到镜头绕一圈后原有的部分变模糊了,越早出现的画面越模糊,与较晚出现的画面形成了明显的对比。

仔细研究后,我找到了原因。
程序中多次使用cv2.warpAffine函数,并且平移的向量基本上均为小数,多次非整数的平移使最终的图片变模糊,使透明度通道的透明部分和不透明部分的界限不明显,则会产生黑边。
M = np.float32([[1,0,zuo[0]],[0,1,zuo[1]]])
leftdst = cv2.warpAffine(leftgray,M,(cols,rows),borderValue=(0,0,0,0))
M = np.float32([[1,0,you[0]],[0,1,you[1]]])
rightdst = cv2.warpAffine(rightgray,M,(cols,rows),borderValue=(0,0,0,0))
同时,由于此场景下透明度只能为透明或不透明,所以可以将设置透明度的语句中的除改为整除。
alpha = leftgray[:,:,3] // 255.0
...
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3] = (1 - (1-rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3]//255) * (1-leftgray[:,:,3]//255)) * 255
具体说明
在寻找问题的时候,看到了这个https://zhuanlan.zhihu.com/p/89684929,于是有了思路,就测试了一下。
当平移整数个像素时:
d = np.array([[255, 200, 0, 50],
[200, 255, 50, 0],
[ 0, 50, 255, 200],
[ 50, 0, 200, 255]], np.uint8)
M = np.float32([[1,0,1],[0,1,1]])
M2 = np.float32([[1,0,-1],[0,1,-1]])
for i in range(100):
d = cv2.warpAffine(d,M,(10,10))
d = cv2.warpAffine(d,M2,(10,10))
print(d)
"""[[255 200 0 50 0 0 0 0 0 0]
[200 255 50 0 0 0 0 0 0 0]
[ 0 50 255 200 0 0 0 0 0 0]
[ 50 0 200 255 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]]
"""
当平移小数个像素时:
d = np.array([[255, 200, 0, 50],
[200, 255, 50, 0],
[ 0, 50, 255, 200],
[ 50, 0, 200, 255]], np.uint8)
M = np.float32([[1,0,0.5],[0,1,0.5]])
M2 = np.float32([[1,0,-0.5],[0,1,-0.5]])
for i in range(100):
d = cv2.warpAffine(d,M,(10,10))
d = cv2.warpAffine(d,M2,(10,10))
print(d)
"""[[ 3 4 6 7 7 6 5 3 1 0]
[ 4 7 10 12 12 10 9 6 3 1]
[ 6 10 13 15 15 13 11 8 4 1]
[ 7 12 15 16 16 14 12 8 5 2]
[ 7 12 15 16 15 14 11 8 4 1]
[ 6 10 13 14 14 12 9 6 3 1]
[ 5 9 11 12 11 9 6 3 1 0]
[ 3 6 8 8 8 6 3 1 0 0]
[ 1 3 4 5 4 3 1 0 0 0]
[ 0 1 1 2 1 1 0 0 0 0]]
"""
之后又用图片测试了一下,发现不断进行小数个像素的平移确实会变模糊。
解决方案
既然知道了问题,那就很好解决,将原有图片和新图片需要平移的量四舍五入取整即可。
M = np.float32([[1,0,int(round(zuo[0]))],[0,1,int(round(zuo[1]))]])
leftdst = cv2.warpAffine(leftgray,M,(cols,rows),borderValue=(0,0,0,0))
M = np.float32([[1,0,int(round(you[0]))],[0,1,int(round(you[1]))]])
rightdst = cv2.warpAffine(rightgray,M,(cols,rows),borderValue=(0,0,0,0))
注意
这里只是对仿射变换所需的变换矩阵中进行取整,而不是直接修改pingyi,这样可以避免不断取整造成的误差累计。
图片说明:
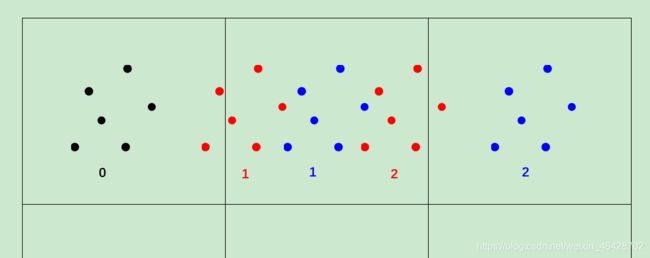
原来的黑色点0平移后应到红色点1,但由于取整到了蓝色点1,若直接修改pingyi,则第二次平移时会直接平移到蓝色点2,误差变大。而正确的平移是红色点2,若对红色点2取整,则结果还是蓝色点1,误差较小。
问题二分析
可以看到,左侧仍旧露出了部分字幕。
仔细思考后,我发现了原因。
目前判断镜头向上向下移动的变量是pingyi,但此变量实际的含义是从新图片的左上角指向原有图片的左上角的向量(np.array的坐标系以左上角作为原点),因此,在以下这种情况时可以正常判断。

(黑色是原有图片,红色是新图片)
但当这个镜头把右侧和下面部分移动完,从左侧向上移动时,新图像的加入则不需要扩大原有图像的尺寸了。

(黑色是原有图片,红色是新图片,蓝色是上一次的新图片)
此时,按照正确的判断方法,红色图片相对于蓝色图片的左上角是向上平移的,但是用目前的判断方法的话,相对于黑色图片的左上角是向下平移的,于是就会出现问题。
解决方案
这个解决方法也很简单,记录上次的pingyi,每次用当前的pingyi减去上次的pingyi即为相对上次图片平移的向量。
last_x,last_y=0,0
...
global kp1,des1,rows,cols,last_x,last_y
...
up_or_down=pingyi[1]-last_y
last_x,last_y=pingyi
...
if up_or_down<0:
...
else:
...
...
if up_or_down<0:
return leftdst
else:
return rightdst
再次运行结果
解决以上问题后,再次运行,结果是这样的:(原图过大无法插入,这里是缩小后的图片)

可见效果好了很多,模糊和黑边都没有了,左侧大片字幕没有了,虽然有些地方还是有点错位,字幕也没有完全去掉,但总的来说效果还是不错的。

(没有模糊了,但是还是有错位和字幕)
完整代码
# 参考:https://blog.csdn.net/qq878594585/article/details/81901703
import numpy as np
import cv2
import matplotlib.pyplot as plt
from pyod.models.knn import KNN
clf_name = 'KNN'
clf = KNN(0.5)
hessian=400
surf=cv2.SIFT_create(hessian) #将Hessian Threshold设置为400,阈值越大能检测的特征就越少
rows,cols=0,0
last_x,last_y=0,0
def pinjie(leftgray,rightgray):
global kp1,des1,rows,cols,last_x,last_y
print("grayshape:",leftgray.shape,rightgray.shape)
kp2,des2=surf.detectAndCompute(rightgray,None) #查找关键点和描述符
FLANN_INDEX_KDTREE=0 #建立FLANN匹配器的参数
indexParams=dict(algorithm=FLANN_INDEX_KDTREE,trees=5) #配置索引,密度树的数量为5
searchParams=dict(checks=50) #指定递归次数
#FlannBasedMatcher:是目前最快的特征匹配算法(最近邻搜索)
flann=cv2.FlannBasedMatcher(indexParams,searchParams) #建立匹配器
matches=flann.knnMatch(des1,des2,k=2) #得出匹配的关键点
good=[]
#提取优秀的特征点
for m,n in matches:
if m.distance < 0.7*n.distance: #如果第一个邻近距离比第二个邻近距离的0.7倍小,则保留
good.append(m)
src_pts = np.array([ kp1[m.queryIdx].pt for m in good if kp2[m.trainIdx].pt[1]<=933]) #查询图像的特征描述子索引
dst_pts = np.array([ kp2[m.trainIdx].pt for m in good if kp2[m.trainIdx].pt[1]<=933]) #训练(模板)图像的特征描述子索引
#H=cv2.findHomography(src_pts,dst_pts) #生成变换矩阵
h,w=leftgray.shape[:2]
h1,w1=rightgray.shape[:2]
sandian=dst_pts-src_pts
print("sandian:",sandian.shape)
#plt.figure(1)
#plt.scatter(*sandian.T)
# 参考:https://blog.csdn.net/weixin_42199542/article/details/106885459
# train kNN detector
clf.fit(sandian)
# If you want to see the predictions of the training data, you can use this way:
#y_train_scores = clf.decision_scores_
#plt.figure(2)
y_test_pred = clf.predict(sandian)
sandian=sandian[y_test_pred==0]
pingyi=np.mean(sandian,0)
print("pingyi:",pingyi)
#plt.scatter(*sandian.T)
#plt.scatter(*pingyi,c='red')
# h,w是原有图片的高和宽
# h1,w1是新图片的高和宽
# zuo为原有图片需要平移的向量
# you为新图片需要平移的向量
# 因为最终是在一张大底图上合成,所以有时原有图片和新图片都需要平移
# rows和cols是大底图的高和宽
zuo,you=[0,0],[0,0]
for i in [0,1]:
if pingyi[i]>0:
zuo[i]=pingyi[i]
else:
you[i]=-pingyi[i]
if pingyi[1]<0:
if h1 + abs(int(round(pingyi[1]))) > rows:
rows = h1 + abs(int(round(pingyi[1])))
else:
if h + abs(int(round(pingyi[1]))) > rows:
rows = h + abs(int(round(pingyi[1])))
if pingyi[0]<0:
if w1 + abs(int(round(pingyi[0]))) > cols:
cols = w1 + abs(int(round(pingyi[0])))
else:
if w + abs(int(round(pingyi[0]))) > cols:
cols = w + abs(int(round(pingyi[0])))
print("rows:",rows,"cols",cols)
up_or_down=pingyi[1]-last_y
last_x,last_y=pingyi
if up_or_down<0: # 如果不加int和round会造成不断进行小数的仿射变换,最会终产生模糊
M = np.float32([[1,0,int(round(zuo[0]))],[0,1,int(round(zuo[1]))]])
leftdst = cv2.warpAffine(leftgray,M,(cols,rows),borderValue=(0,0,0,0))
#cv2.namedWindow('leftdst', 0)
#cv2.imshow('leftdst',leftdst)
#cv2.namedWindow('rightdst', 0)
#cv2.imshow('rightdst',rightdst)
print("dstshape:",leftdst.shape)
weizhix=abs(int(round(you[0])))
weizhiy=abs(int(round(you[1])))
print("weizhi:",weizhix,weizhiy)
#cv2.imwrite(r'leftdst.png',leftdst)
#cv2.imwrite(r'rightgray.png',rightgray)
leftdst[weizhiy:weizhiy+h1,weizhix:weizhix+w1]=rightgray[:,:]
else:
M = np.float32([[1,0,int(round(you[0]))],[0,1,int(round(you[1]))]])
rightdst = cv2.warpAffine(rightgray,M,(cols,rows),borderValue=(0,0,0,0))
print("dstshape:",rightdst.shape)
weizhix=abs(int(round(zuo[0])))
weizhiy=abs(int(round(zuo[1])))
print("weizhi:",weizhix,weizhiy)
#rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,:3]=leftgray[:,:,:3]
#rightdst=cv2.addWeighted(rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w],leftgray[:,:,2],leftgray[:,:,:3],1-leftgray[:,:,2],0)
alpha = leftgray[:,:,3] // 255.0
#print(alpha[:10,:10])
#result = np.zeros(rightdst.shape[:2]+(4,))
#cv2.imshow('result',result)
#cv2.imwrite(r'rightdst.png',rightdst)
#cv2.imwrite(r'leftgray.png',leftgray)
#cv2.waitKey(1000)
print(rightdst.shape[:2]+(4,),leftgray.shape)
print(rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0].shape)
print(leftgray[weizhiy:weizhiy+h,weizhix:weizhix+w,1].shape)
print(weizhiy,weizhiy+h,weizhix,weizhix+w)
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,0] + alpha * leftgray[:,:,0]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,1] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,1] + alpha * leftgray[:,:,1]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,2] = (1. - alpha) * rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,2] + alpha * leftgray[:,:,2]
rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3] = (1 - (1-rightdst[weizhiy:weizhiy+h,weizhix:weizhix+w,3]//255) * (1-leftgray[:,:,3]//255)) * 255
#cv2.namedWindow('dst', 0)
#cv2.imshow('dst',leftdst)
#cv2.waitKey(1000)
#plt.show()
kp1,des1=kp2,des2
for j in kp1:
j.pt=(j.pt[0]+you[0],j.pt[1]+you[1])
if up_or_down<0:
return leftdst
else:
return rightdst
video = cv2.VideoCapture(r'60.mp4') # 读取视频
#for i in range(270):
# video.read()
ret, leftframe = video.read() # 读取帧
b_channel, g_channel, r_channel = cv2.split(leftframe)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
# 最小值为0
#alpha_channel[:, :int(b_channel.shape[0] / 2)] = 100
leftframe = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
#cv2.imshow('leftframe',leftframe)
kp1,des1=surf.detectAndCompute(leftframe,None) #查找关键点和描述符
i=0
while i<=3700:
#for i in range(1200): # 逐帧读取
ret, rightframe = video.read() # 读取下一帧
if not ret:
break
b_channel, g_channel, r_channel = cv2.split(rightframe)
alpha_channel = np.ones(b_channel.shape, dtype=b_channel.dtype) * 255
# 最小值为0
#alpha_channel[:, :int(b_channel.shape[0] / 2)] = 100
rightframe = cv2.merge((b_channel, g_channel, r_channel, alpha_channel))
#cv2.imshow('frame',frame)
#if i%5==0:
print(i)
leftframe=pinjie(leftframe,rightframe)
#cv2.namedWindow('dst', 0)
#cv2.imshow('dst',leftframe)
#cv2.waitKey(1000)
print()
cv2.imwrite(r'dst.png',leftframe)
i+=1
引申
将图片的仿射变换改成透视变换,再通过cv2.VideoCapture调用手机的摄像头,即可进行手机拍摄照片的全景拼接。(手机运行Python可用Aid-learning、QPython 3、Pydroid 3、Termux、Linux Deploy等,也可将图片传输至电脑,在电脑上拼接)