OpenCv学习笔记12--FAST角点检测
此opencv系列博客只是为了记录本人对<>的学习笔记,所有代码在我的github主页https://github.com/RenDong3/OpenCV_Notes.
欢迎star,不定时更新...
在前面我们已经陆续介绍了许多特征检测算子,我们可以根据图像局部的自相关函数求得Harris角点,后面又提到了两种十分优秀的特征点以及他们的描述方法SIFT特征和SURF特征。SURF特征是为了提高运算效率对SIFT特征的一种近似,虽然在有些实验环境中已经达到了实时,但是我们实践工程应用中,特征点的提取与匹配只是整个应用算法中的一部分,所以我们对于特征点的提取必须有更高的要求,从这一点来看前面介绍的的那些特征点方法都不可取。
一 FAST算法原理
为了解决这个问题,Edward Rosten和Tom Drummond在2006年发表的“Machine learning for high-speed corner detection”文章中提出了一种FAST特征,并在2010年对这篇论文作了小幅度的修改后重新发表。FAST的全称为Features From Accelerated Segment Test。
Rosten等人将FAST角点定义为:若某像素点与其周围领域内足够多的像素点处于不同的区域,则该像素点可能为角点。也就是某些属性与众不同,考虑灰度图像,即若该点的灰度值比其周围领域内足够多的像素点的灰度值大或者小,则该点可能为角点。
二 FAST算法步骤
- 从图片中选取一个像素PP,下面我们将判断它是不是一个特征点。我们首先把它的亮度值设为IpIp;
- 设定一个合适的阈值tt;
- 考虑以该像素点为中心的一个半径等于3像素的离散化的Bresenham圆,这个圆的边界上有16个像素;
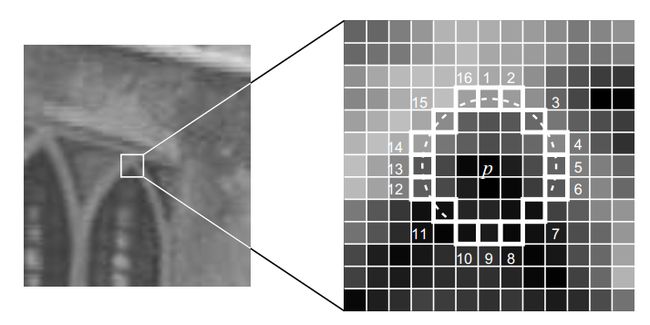
4.现在,如果在这个大小为16个像素的圆上有nn个连续的像素点,他们的像素值要么都比Ip+tIp+t大,要么都比Ip−tIp−t小,那么他就是一个角点。nn的值可以设置为12或者9,实验证明选择9可能会有更好的效果。
上面的算法中,对于图像中的每一个点,我们都要去遍历其邻域圆上的16个点的像素,效率较低。我们下面提出了一种高效的测试(high-speed test)来快速排除一大部分非角点的像素。该方法仅仅检查在位置1,9,5和13四个位置的像素,首先检测位置1和位置9,如果它们都比阈值暗或比阈值亮,再检测位置5和位置13。如果pp是一个角点,那么上述四个像素点中至少有3个应该必须都大于Ip+tIp+t或者小于Ip−tIp−t,因为若是一个角点,超过四分之三圆的部分应该满足判断条件。如果不满足,那么pp不可能是一个角点。对于所有点做上面这一部分初步的检测后,符合条件的将成为候选的角点,我们再对候选的角点,做完整的测试,即检测圆上的所有点。
上面的算法效率实际上是很高的,但是有点一些缺点:
- 当我们设置n<12n<12时就不能使用快速算法来过滤非角点的点;
-
检测出来的角点不是最优的,这是因为它的效率取决于问题的排序与角点的分布;
-
对于角点分析的结果被丢弃了;
-
多个特征点容易挤在一起。
三 使用机器学习做一个角点分类器

四 非极大值抑制

五 OpenCV库FAST特征检测
# -*- coding: utf-8 -*-
"""
Created on Mon Aug 27 16:09:48 2018
@author: lenovo
"""
'''
FAST角点检测
'''
import cv2
'''1、加载图片'''
img1 = cv2.imread('chess.jpg')
img1 = cv2.resize(img1,dsize=(600,400))
image1 = img1.copy()
'''2、提取特征点'''
#创建一个FAST对象,传入阈值t 可以处理RGB色彩空间图像
fast = cv2.FastFeatureDetector_create(threshold=50)
keypoints1 = fast.detect(image1,None)
#在图像上绘制关键点
image1 = cv2.drawKeypoints(image=image1,keypoints = keypoints1,outImage=image1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
#输出默认参数
print("Threshold: ", fast.getThreshold())
print("nonmaxSuppression: ", fast.getNonmaxSuppression())
print("neighborhood: ", fast.getType())
print("Total Keypoints with nonmaxSuppression: ", len(keypoints1))
#显示图像
cv2.imshow('fast_keypoints1',image1)
cv2.waitKey(20)
#关闭非极大值抑制
fast.setNonmaxSuppression(0)
keypoints1 = fast.detect(image1,None)
print("Total Keypoints without nonmaxSuppression: ", len(keypoints1))
image1 = cv2.drawKeypoints(image=image1,keypoints = keypoints1,outImage=image1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('fast_keypoints1 nms',image1)
cv2.waitKey(0)
cv2.destroyAllWindows()运行结果如下:



可以看到经过非极大值抑制之后,特征点从2762个降低到了411个。如果你修改阈值t,你会发现tt越大,检测到的特征点越小。
如果你还记得我们之前介绍SIFT特征和SURF特征,我们忽略算法参数的影响,从总体上来看,你会发现FAST的特征点数量远远多于前着。这是受多方面元素影响,一方面是受算法本身影响,这两个算法是完全不同的;另一方面FAST特征对噪声比较敏感,从图片上我们也可以观察到,比如广场上许多的的噪声点。
除了上面我所说的这些,FAST算法还有以下需要改进的地方:
- 由于FAST算法依赖于一个阈值tt,因此算法还需要人为干涉;
- FAST算法不产生多尺度特征而且FAST特征点没有方向信息,这样就会失去旋转不变性;
后面我会介绍ORB算法,ORB将基于FAST关键点检测的技术和基于BRIFE描述符的技术相结合,ORB算法解决了上面我所讲述到的缺点,可以用来替代SIFT和SURF算法,与两者相比,ORB拥有更快的速度。
注意,这里大部分内容参考大神的博客,还有一些这里并未多做解释,还是那句话,想了解更多原理相关,请移步大神博客,下面是连接:
https://www.cnblogs.com/zyly/p/9542164.html