【步态识别】GaitSet 算法学习+配置环境+代码调试运行《GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition》
目录
- 1. 论文&代码源
- 2. 配置环境
-
- 2.1 硬件环境
- 2.2 软件配置
- 3. 运行代码
-
- 3.1 关于CASIA-B数据集
- 3.2 pretreatment.py
-
- 3.2.1 log2str函数
- 3.2.2 log_print函数
- 3.2.3 cut_img函数
- 3.2.4 cut_pickle函数
- 3.2.5 图像预处理完整代码
- 3.3 config.py
- 3.4 train.py
-
- 运行结果
- 3.5 test.py
-
- 3.5.1 概念补充:probe set与gallery set
- 3.5.2 运行结果
- 4. 算法核心代码
-
- 4.1 gaitset.py☆
- 4.2 model.py
- 4.3 triplet.py
- 5. (原作)运行结果
- 附录
关于GaitSet核心算法,建议直接跳到 “4. 算法核心代码——4.1 gaitset.py”
1. 论文&代码源
论文地址:https://ieeexplore.ieee.org/document/9351667
CASIA-B数据集下载地址:http://www.cbsr.ia.ac.cn/china/Gait%20Databases%20CH.asp
代码下载地址:https://github.com/AbnerHqC/GaitSet
2. 配置环境
2.1 硬件环境
1. 确定显卡型号
右键“此电脑”——“管理”——“设备管理器”——“显示适配器”查看GPU型号,以我的电脑为例:

版本为NVIDIA GeForce GTX 1650 SUPER。
2. 下载NVIDIA驱动程序
在NVIDIA驱动程序下载页面选择显卡相应的版本号、操作系统、下载类型等:


3. CUDA与cuDNN版本的选择及下载
打开“NVIDIA Control Panel”——“系统信息”——“组件”

此处显示的是显卡所支持的CUDA(最高)版本,在NVIDIA DEVELOPER CUDA10.0可以进行下载,我选择的是10.0版本,对应选项见下图:

cuDNN选择v7.6.5.32,同样可以在NVIDIA DEVELOPER cudnn进行下载。
♦可以看到CUDA安装包有2G的大小,尽量将其下载到除C盘外的其他磁盘内,下载教程参见:CUDA、CUDNN在windows下的安装及配置;上述详细解释及配置调试验证参见:Windows11 显卡GTX1650 搭建CUDA+cuDNN环境,并安装对应版本的Anaconda和TensorFlow-GPU(本文代码所基于的环境无需安装TensorFlow)。
2.2 软件配置
我下载的Python版本为3.7.8,根据Anaconda与Python版本对应下载Anaconda3-2020.02-Windows-x86_64
其他软件版本见下表:
| NAME | VERSION |
|---|---|
| Python | 3.7.8 |
| Anaconda | Anaconda3-2020.02 |
| Pycharm | 2019.1.4 |
3. 运行代码
ERROR1
论文作者给出的原始代码在运行前出现from XX import XX红色波浪线报错的情况:

原因是代码无法在项目文件夹中找到需要import的源代码,因为原始项目的构架如下图所示: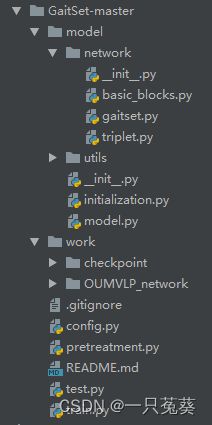
所有需要人为主动编译和运行过程中被动编译的代码所在的文件类型都是普通文件夹:![]()
现在我们需要将项目中需要被编译构建的文件视为源代码(类似C语言中的.h文件),因此将项目架构变更为下图:
项目更改前后的对应关系如下图所示:

※补充

Source Root:表明该文件夹内的子文件夹及其代码是源代码,需要进行编译;
Excluded:表明该文件夹下的内容不会被IDEA创建索引,可以类比代码段中的注释内容;
Resorces Root:表明该文件夹内含有项目中使用的资源文件,如:图像、配置XML和属性文件等;
Template Folder:存放模板的文件夹。
(官方解释网址:PyCharm 2019.1 Help)
3.1 关于CASIA-B数据集
CASIA-B是中国科学院自动化研究所提供的CASIA步态数据库其中之一。CASIA步态数据库有三个数据集:Dataset A(小规模库), Dataset B(多视角库)和Dataset C(红外库),文章采用的是Dataset B,这是一个大规模、多视角的数据集,采集于20051月,数据集内包含124个人,每个人有0°,18°,……,180°共11个视角,在普通(nm),穿大衣(cl)和背包(bg)3种行走状态。
数据集可以直接在CASIA步态数据库中下载(png格式步态轮廓数据),如需完整的视频资源可以在同一界面填写申请协议。

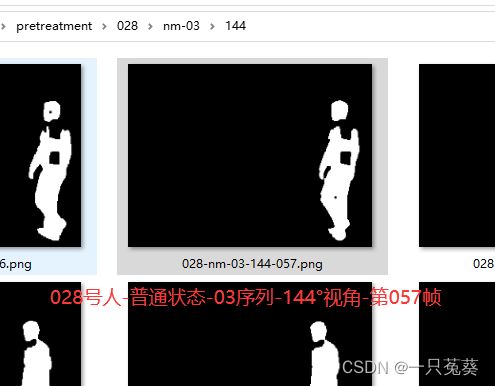
关于数据集内步态轮廓png文件的命名格式是按照:行人编号-行走条件-序列号-视角(角度)-帧数
3.2 pretreatment.py
目的: 对数据集进行预处理。将原始大小为320×240像素的图像按照人像边界顶点进行裁剪,生成64×64像素的图像。
这里仅仅是图像预处理,对于GaitSet操作使用的图像并非分辨率为64×64大小的,而是64×44,具体原因参见data_set.py文件。


# -*- coding: utf-8 -*-
# @Author : Abner
# @Time : 2018/12/19
import os
from scipy import misc as scisc
import cv2
import numpy as np
from warnings import warn
from time import sleep
import argparse
from multiprocessing import Pool
from multiprocessing import TimeoutError as MP_TimeoutError
#*全大写单词用于log中描述状态(comment)
START = "START"
FINISH = "FINISH"
WARNING = "WARNING"
FAIL = "FAIL"
def boolean_string(s):
if s.upper() not in {'FALSE', 'TRUE'}:
raise ValueError('Not a valid boolean string')
return s.upper() == 'TRUE'
#*这一部分(以下三行)是在原作者代码基础上更改的,能够直接调用系统的路径地址,对数据进行载入和导出
wd = os.getcwd()
input_path = os.path.join(wd, 'input_data_path')
output_path = os.path.join(wd, 'output_data_path')
parser = argparse.ArgumentParser(description='Test')
parser.add_argument('--input_path', default=input_path, type=str,
help='Root path of raw dataset.')
parser.add_argument('--output_path', default=output_path, type=str,
help='Root path for output.')
parser.add_argument('--log_file', default='./pretreatment.log', type=str,
help='Log file path. Default: ./pretreatment.log') #*训练后自动生成的日志文件
parser.add_argument('--log', default=False, type=boolean_string,
help='If set as True, all logs will be saved. '
'Otherwise, only warnings and errors will be saved.'
'Default: False') #*若代码运行无误,程序日志文件将被保存;否则,保存警告和错误信息
parser.add_argument('--worker_num', default=1, type=int,
help='How many subprocesses to use for data pretreatment. '
'Default: 1') #*定义由多少个并行程序对数据进行预处理,默认值是1
opt = parser.parse_args()
INPUT_PATH = opt.input_path
OUTPUT_PATH = opt.output_path
IF_LOG = opt.log
LOG_PATH = opt.log_file
WORKERS = opt.worker_num
#*输出图像的高度和宽度均为64个像素
T_H = 64
T_W = 64
用户需要修改inputdata_path和outputdata_path两个变量。
input_data_path: CASIA-B数据集在本地文件的地址。(注意:数据集压缩包内的小数据集依旧是压缩包的形式,同样需要进行解压缩操作,也就是需要将数据集进行两次解压。)
output_data_path: 数据集预处理后存放的路径。此文件必须是一个空文件,否则会出现ERROR2:
FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。
建议将上述两个文件夹并列作为两个子文件存在在一起,方便比对预处理前后的数据差异。
3.2.1 log2str函数
此函数用于定义生成日志的格式(不重要)。
#*日志报告数据生成函数
#*输入变量:pid-进程序号(process ID)
#* comment-状态描述
#* logs-内容描述
def log2str(pid, comment, logs):
str_log = '' #*str_log变量初始值为空
if type(logs) is str:
logs = [logs]
for log in logs:
str_log += "# JOB %d : --%s-- %s\n" % (
pid, comment, log)
return str_log
3.2.2 log_print函数
此函数用于将日志打印输出(不重要)。
#*日志报告打印函数
#*输入变量同log2str函数
def log_print(pid, comment, logs):
str_log = log2str(pid, comment, logs)
if comment in [WARNING, FAIL]: #*若运行过程出现警告或报错,执行此if函数
with open(LOG_PATH, 'a') as log_f: #*显示错误地址
log_f.write(str_log)
if comment in [START, FINISH]:
if pid % 500 != 0: #*每执行500步打印输出一次
return
print(str_log, end='')
3.2.3 cut_img函数
此函数用于将图像进行裁剪(不是特别重要,知道操作流程是怎么回事就行)。
#*图像裁剪函数
#*输入变量:img-待处理图像
#* seq_info-序列组信息
#* frame_name-序列组内文件名
#* pid-进程序号
def cut_img(img, seq_info, frame_name, pid):
# A silhouette contains too little white pixels
#*如果人像剪影白色像素点过少
# might be not valid for identification.
#*可能会有无效识别的情况出现,见下文WARNING1
if img.sum() <= 10000:
message = 'seq:%s, frame:%s, no data, %d.' % (
'-'.join(seq_info), frame_name, img.sum())
warn(message)
log_print(pid, WARNING, message)
return None
# Get the top and bottom point
#*获取图像上下顶点
y = img.sum(axis=1)
y_top = (y != 0).argmax(axis=0)
y_btm = (y != 0).cumsum(axis=0).argmax(axis=0)
img = img[y_top:y_btm + 1, :]
# As the height of a person is larger than the width,
#*当人像剪影的高度大于宽度时
# use the height to calculate resize ratio.
#*用高度去计算大小调整比率
_r = img.shape[1] / img.shape[0]
_t_w = int(T_H * _r)
img = cv2.resize(img, (_t_w, T_H), interpolation=cv2.INTER_CUBIC)
# Get the median of x axis and regard it as the x center of the person.
#*获取x轴的中心点,将其视为人像的x轴中点
sum_point = img.sum()
sum_column = img.sum(axis=0).cumsum()
x_center = -1
for i in range(sum_column.size):
if sum_column[i] > sum_point / 2:
x_center = i
break
if x_center < 0:
message = 'seq:%s, frame:%s, no center.' % (
'-'.join(seq_info), frame_name)
warn(message)
log_print(pid, WARNING, message)
return None
h_T_W = int(T_W / 2)
left = x_center - h_T_W
right = x_center + h_T_W
if left <= 0 or right >= img.shape[1]:
left += h_T_W
right += h_T_W
_ = np.zeros((img.shape[0], h_T_W))
img = np.concatenate([_, img, _], axis=1)
img = img[:, left:right]
return img.astype('uint8')
axis=0 压缩行: 将每一列的像素值相加,图像矩阵压缩为一行
axis=1 压缩列: 将每一列的像素值相加,图像矩阵压缩为一列

argmax: 获取最大值的索引值
3.2.4 cut_pickle函数
此函数用于获取已裁剪完毕的图像(也不重要)。
#*图像获取函数
#*输入变量:seq_info-序列组信息
#* pid-进程序号
def cut_pickle(seq_info, pid):
seq_name = '-'.join(seq_info)
log_print(pid, START, seq_name)
seq_path = os.path.join(INPUT_PATH, *seq_info)
out_dir = os.path.join(OUTPUT_PATH, *seq_info)
frame_list = os.listdir(seq_path)
frame_list.sort()
count_frame = 0
for _frame_name in frame_list:
frame_path = os.path.join(seq_path, _frame_name)
img = cv2.imread(frame_path)[:, :, 0]
img = cut_img(img, seq_info, _frame_name, pid)
if img is not None:
# Save the cut img
#*保存已完成裁剪的图像
save_path = os.path.join(out_dir, _frame_name)
cv2.imwrite(save_path, img)
count_frame += 1
# Warn if the sequence contains less than 5 frames
#*当有效图像数量少于5张时会产生警告,见下文WARNING2
if count_frame < 5:
message = 'seq:%s, less than 5 valid data.' % (
'-'.join(seq_info))
warn(message)
log_print(pid, WARNING, message)
log_print(pid, FINISH,
'Contain %d valid frames. Saved to %s.'
% (count_frame, out_dir))
此外,在预处理过程中会出现两种类型的警告:
WARNING1
UserWarning: seq:005-bg-01-000, less than 5 valid data.
少于5个有效数据,打开原始数据可以看到这个文件夹下确实缺少数据↓
UserWarning: seq:005-bg-01-018, frame:005-bg-01-018-128.png, no data, 0.
缺少白色像素点引起的警告,此警告对应的图像确实如此↓

以上两种警告均由数据集本身数据缺失引起(大概?),暂且无需理会。
3.2.5 图像预处理完整代码
# -*- coding: utf-8 -*-
# @Author : Abner
# @Time : 2018/12/19
import os
from scipy import misc as scisc
import cv2
import numpy as np
from warnings import warn
from time import sleep
import argparse
from multiprocessing import Pool
from multiprocessing import TimeoutError as MP_TimeoutError
START = "START"
FINISH = "FINISH"
WARNING = "WARNING"
FAIL = "FAIL"
def boolean_string(s):
if s.upper() not in {'FALSE', 'TRUE'}:
raise ValueError('Not a valid boolean string')
return s.upper() == 'TRUE'
wd = os.getcwd()
input_path = os.path.join(wd, 'D:\PyCharm\Project\Gaitset\GaitDatasetB-silh0\pretreatment')
output_path = os.path.join(wd, 'D:\PyCharm\Project\Gaitset\GaitDatasetB-silh0\output')
parser = argparse.ArgumentParser(description='Test')
parser.add_argument('--input_path', default=input_path, type=str,
help='Root path of raw dataset.')
parser.add_argument('--output_path', default=output_path, type=str,
help='Root path for output.')
parser.add_argument('--log_file', default='./pretreatment.log', type=str,
help='Log file path. Default: ./pretreatment.log')
parser.add_argument('--log', default=False, type=boolean_string,
help='If set as True, all logs will be saved. '
'Otherwise, only warnings and errors will be saved.'
'Default: False')
parser.add_argument('--worker_num', default=1, type=int,
help='How many subprocesses to use for data pretreatment. '
'Default: 1')
opt = parser.parse_args()
INPUT_PATH = opt.input_path
OUTPUT_PATH = opt.output_path
IF_LOG = opt.log
LOG_PATH = opt.log_file
WORKERS = opt.worker_num
T_H = 64
T_W = 64
def log2str(pid, comment, logs):
str_log = ''
if type(logs) is str:
logs = [logs]
for log in logs:
str_log += "# JOB %d : --%s-- %s\n" % (
pid, comment, log)
return str_log
def log_print(pid, comment, logs):
str_log = log2str(pid, comment, logs)
if comment in [WARNING, FAIL]:
with open(LOG_PATH, 'a') as log_f:
log_f.write(str_log)
if comment in [START, FINISH]:
if pid % 500 != 0:
return
print(str_log, end='')
def cut_img(img, seq_info, frame_name, pid):
# A silhouette contains too little white pixels
# might be not valid for identification.
if img.sum() <= 10000:
message = 'seq:%s, frame:%s, no data, %d.' % (
'-'.join(seq_info), frame_name, img.sum())
warn(message)
log_print(pid, WARNING, message)
return None
# Get the top and bottom point
y = img.sum(axis=1)
y_top = (y != 0).argmax(axis=0)
y_btm = (y != 0).cumsum(axis=0).argmax(axis=0)
img = img[y_top:y_btm + 1, :]
# As the height of a person is larger than the width,
# use the height to calculate resize ratio.
_r = img.shape[1] / img.shape[0]
_t_w = int(T_H * _r)
img = cv2.resize(img, (_t_w, T_H), interpolation=cv2.INTER_CUBIC)
# Get the median of x axis and regard it as the x center of the person.
sum_point = img.sum()
sum_column = img.sum(axis=0).cumsum()
x_center = -1
for i in range(sum_column.size):
if sum_column[i] > sum_point / 2:
x_center = i
break
if x_center < 0:
message = 'seq:%s, frame:%s, no center.' % (
'-'.join(seq_info), frame_name)
warn(message)
log_print(pid, WARNING, message)
return None
h_T_W = int(T_W / 2)
left = x_center - h_T_W
right = x_center + h_T_W
if left <= 0 or right >= img.shape[1]:
left += h_T_W
right += h_T_W
_ = np.zeros((img.shape[0], h_T_W))
img = np.concatenate([_, img, _], axis=1)
img = img[:, left:right]
return img.astype('uint8')
def cut_pickle(seq_info, pid):
seq_name = '-'.join(seq_info)
log_print(pid, START, seq_name)
seq_path = os.path.join(INPUT_PATH, *seq_info)
out_dir = os.path.join(OUTPUT_PATH, *seq_info)
frame_list = os.listdir(seq_path)
frame_list.sort()
count_frame = 0
for _frame_name in frame_list:
frame_path = os.path.join(seq_path, _frame_name)
img = cv2.imread(frame_path)[:, :, 0]
img = cut_img(img, seq_info, _frame_name, pid)
if img is not None:
# Save the cut img
save_path = os.path.join(out_dir, _frame_name)
cv2.imwrite(save_path, img)
count_frame += 1
# Warn if the sequence contains less than 5 frames
if count_frame < 5:
message = 'seq:%s, less than 5 valid data.' % (
'-'.join(seq_info))
warn(message)
log_print(pid, WARNING, message)
log_print(pid, FINISH,
'Contain %d valid frames. Saved to %s.'
% (count_frame, out_dir))
if __name__ == '__main__':
pool = Pool(WORKERS)
results = list()
pid = 0
print('Pretreatment Start.\n'
'Input path: %s\n'
'Output path: %s\n'
'Log file: %s\n'
'Worker num: %d' % (
INPUT_PATH, OUTPUT_PATH, LOG_PATH, WORKERS))
id_list = os.listdir(INPUT_PATH)
id_list.sort()
# Walk the input path
for _id in id_list:
seq_type = os.listdir(os.path.join(INPUT_PATH, _id))
seq_type.sort()
for _seq_type in seq_type:
view = os.listdir(os.path.join(INPUT_PATH, _id, _seq_type))
view.sort()
for _view in view:
seq_info = [_id, _seq_type, _view]
out_dir = os.path.join(OUTPUT_PATH, *seq_info)
os.makedirs(out_dir)
results.append(
pool.apply_async(
cut_pickle,
args=(seq_info, pid)))
sleep(0.02)
pid += 1
pool.close()
unfinish = 1
while unfinish > 0:
unfinish = 0
for i, res in enumerate(results):
try:
res.get(timeout=0.1)
except Exception as e:
if type(e) == MP_TimeoutError:
unfinish += 1
continue
else:
print('\n\n\nERROR OCCUR: PID ##%d##, ERRORTYPE: %s\n\n\n',
i, type(e))
raise e
pool.join()
3.3 config.py
conf = {
"WORK_PATH": "./work",
"CUDA_VISIBLE_DEVICES": "0,1,2,3", #*使用的GPU编号(一般设为0,若有多个GPU,可以根据剩余容量选择相应的编号)
"data": {
'dataset_path': "your_dataset_path", #*数据预处理后的路径,即前文中的output_data_path
'resolution': '64', #*输出图像的分辨率(无需更改)
'dataset': 'CASIA-B', #*数据集名称
# In CASIA-B, data of subject #5 is incomplete.
#*在CASIA-B数据集中,5号文件是不完整的
# Thus, we ignore it in training.
#*因此我们在训练的过程中忽略掉即可
# For more detail, please refer to
#*更多的细节信息可以参考
# function: utils.data_loader.load_data
#*函数:utils.data_loader.load_data(前面文件换位置了,找的时候记得别找错地方)
'pid_num': 73, #*设定用于训练的人数,CASIA-B中一共有124个人,在这里作者选定73个人用于训练,剩余的用于测试
'pid_shuffle': False, #*在124个中随机选出73个人
},
"model": {
'hidden_dim': 256, #*最后一层全连接层的隐藏层数量
'lr': 1e-4, #*学习率为0.0001
'hard_or_full_trip': 'full', #*损失函数
'batch_size': (8, 16), #*批次p*k = 8*16
'restore_iter': 0, #*第几步开始训练
'total_iter': 80000, #*训练次数
'margin': 0.2, #*损失函数的margin参数
'num_workers': 3, #*线程数
'frame_num': 30, #*每个批次的帧数
'model_name': 'GaitSet',
},
}
值得注意的是,这里的batch_size是由两个数组成的一个元组(p, k),其中p是人数,k是p个人每人拿k个样本,所以一个batch训练的样本数量是p×k。
3.4 train.py
from initialization import initialization
from GaitSet.config import conf
import argparse
def boolean_string(s):
if s.upper() not in {'FALSE', 'TRUE'}:
raise ValueError('Not a valid boolean string')
return s.upper() == 'TRUE'
parser = argparse.ArgumentParser(description='Train')
parser.add_argument('--cache', default=True, type=boolean_string,
help='cache: if set as TRUE all the training data will be loaded at once'
' before the training start. Default: TRUE')
opt = parser.parse_args()
m = initialization(conf, train=opt.cache)[0]
print("Training START")
m.fit()
print("Training COMPLETE")
Traceback (most recent call last):
File "D:/PyCharm/Project/Gaitset/GaitSet-master/GaitSet/train.py", line 18, in <module>
m = initialization(conf, train=opt.cache)[0]
File "D:\PyCharm\Project\Gaitset\GaitSet-master\GaitSet\modelfile\initialization.py", line 57, in initialization
train_source, test_source = initialize_data(config, train, test)
File "D:\PyCharm\Project\Gaitset\GaitSet-master\GaitSet\modelfile\initialization.py", line 15, in initialize_data
train_source, test_source = load_data(**config['data'], cache=(train or test))
File "D:\PyCharm\Project\Gaitset\GaitSet-master\GaitSet\modelfile\data_loader.py", line 42, in load_data
pid_list = np.load(pid_fname)
File "D:\Anaconda\envs\GaitSet-master\lib\site-packages\numpy\lib\npyio.py", line 441, in load
pickle_kwargs=pickle_kwargs)
File "D:\Anaconda\envs\GaitSet-master\lib\site-packages\numpy\lib\format.py", line 743, in read_array
raise ValueError("Object arrays cannot be loaded when "
ValueError: Object arrays cannot be loaded when allow_pickle=False
当allow_pickle=False时,无法加载对象数组
可以看到最终问题出在numpy的format.py文件中,查看numpy.load解释文件

在1.16.3及之后版本中,allow_pickle的默认值为False。
主要有2种解决方法:
1. 降低numpy版本
在Terminal中键入
pip install numpy==1.16.2
将numpy版本降到1.16.2及以下版本。
但是并不推荐这种方法,因为降级后的版本在其他地方调用时可能出现不兼容的情况(有待验证?)。
2. 更改numpy.load()函数
定位到报错最后一个文件下,将红色框内的代码注释掉:


..\aten\src\ATen\native\cuda\LegacyDefinitions.cpp:38: UserWarning: masked_scatter_ received a mask with dtype torch.uint8, this behavior is now deprecated,please use a mask with dtype torch.bool instead.
..\aten\src\ATen\native\cuda\LegacyDefinitions.cpp:48: UserWarning: masked_select received a mask with dtype torch.uint8, this behavior is now deprecated,please use a mask with dtype torch.bool instead.
...
masked_scatter_接收了一个dtype torch.uint8的掩码,这种行为现在已被废弃,请使用dtype torch.bool的掩码来代替。
masked_select收到了一个dtype torch.uint8的掩码,这种行为现在已经被废弃,请使用dtype torch.bool的掩码代替。
疯狂出现warning,原因是因为数据类型不对,只需要在triplet.py下图这个位置加上红框框住的两行代码,将uint8类型转换为bool类型即可。
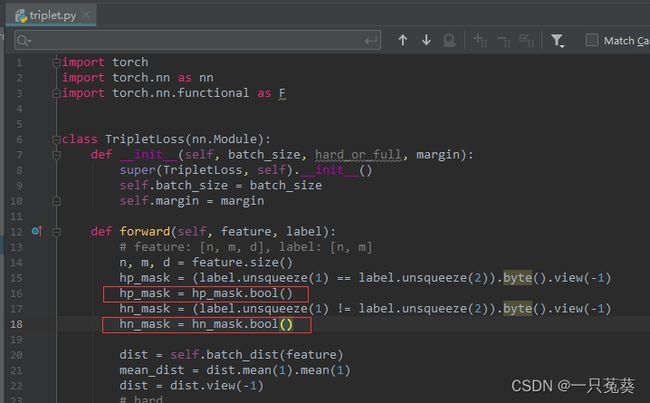
ERROR4
RuntimeError: CUDA out of memory. Tried to allocate 660.00 MiB (GPU 0; 4.00 GiB total capacity; 2.95 GiB already allocated; 0 bytes free; 14.10 MiB cached)
CUDA没有内存了。尝试分配660.00 MiB (GPU 0; 4.00 GiB总容量; 2.95 GiB已分配; 0字节空闲; 14.10 MiB缓存)
程序运行所需内存超出了GPU内存容量,此问题一般有两种解决方法:
1. 减小数据运算量
修改batch_size大小,使一个batch所需计算的数据量在可接受范围内。
2. 释放占用GPU容量的无关进程
打开cmd命令提示符,键入
nvidia-smi
查看当前占用GPU内存的进程,通过命令:

taskkill -PID 进程号 -F
杀死不需要的进程,腾出GPU空间。
因为我的GPU容量本来就很小,把别的进程都杀掉也跑不起来程序,,,所以选择第一种改变batch_size大小的方法.一个batch只训练两个人的16个样本,程序就能正常RUN起来啦~
#batch_size=(8, 16)
batch_size=(2, 16)
运行结果

train了将近7个小时后……

每迭代100次打印输出一条,每迭代1000次打印输出一次运算时间,迭代全部结束后输出一次总运行时间。
这里的hard和full分别表示的困难样本对损失和所有样本对损失。
hard: 对每个条带进行计算,找出每个样本对应的正样本对中的最大距离,找出每个样本的每个负样本对中最小距离,这就相对于进行困难样本挖掘。
full: 对每个条带进行计算,计算每个正样本对和负样本对之间的triplet loss。
3.5 test.py
3.5.1 概念补充:probe set与gallery set
训练集和测试集均有probe set和gallery set,probe字面意思是探针,gallery为画廊,可以把它们分别理解为验证集和注册集。
比如一个身份识别系统,每个注册用户在注册id时上传的身份照片就构成了gallery set;在用户下次使用系统,进行身份认证拍摄的照片,就构成了probe set。步态识别的任务就是从gallery set和probe set先后分别提取出一个特征,计算两个特征之间的距离(通常是欧氏距离),找到距离最近(差距最小or损失最少)的作为识别结果。
注意!
training set和test set与probe set和gallery set没有什么一一对应关系!!
下图能够较为直观得理解这四者之间的关系

gaitset在训练集中学习如何匹配probe set和gallery set,将这一学习能力应用于测试集的配对,所以在使用过程中,数据库是可以随时改变且不需要再次训练的。
from datetime import datetime
import numpy as np
import argparse
from initialization import initialization
from evaluator import evaluation
from config import conf
def boolean_string(s):
if s.upper() not in {'FALSE', 'TRUE'}:
raise ValueError('Not a valid boolean string')
return s.upper() == 'TRUE'
parser = argparse.ArgumentParser(description='Test')
parser.add_argument('--iter', default='80000', type=int,
help='iter: iteration of the checkpoint to load. Default: 80000')
parser.add_argument('--batch_size', default='1', type=int,
help='batch_size: batch size for parallel test. Default: 1')
parser.add_argument('--cache', default=False, type=boolean_string,
help='cache: if set as TRUE all the test data will be loaded at once'
' before the transforming start. Default: FALSE')
opt = parser.parse_args()
# Exclude identical-view cases
def de_diag(acc, each_angle=False):
result = np.sum(acc - np.diag(np.diag(acc)), 1) / 10.0
if not each_angle:
result = np.mean(result)
return result
m = initialization(conf, test=opt.cache)[0]
# load modelfile checkpoint of iteration opt.iter
print('Loading the modelfile of iteration %d...' % opt.iter)
m.load(opt.iter)
print('Transforming...')
time = datetime.now()
test = m.transform('test', opt.batch_size)
print('Evaluating...')
acc = evaluation(test, conf['data'])
print('Evaluation complete. Cost:', datetime.now() - time)
# Print rank-1 accuracy of the best modelfile
# e.g.
# ===Rank-1 (Include identical-view cases)===
# NM: 95.405, BG: 88.284, CL: 72.041
for i in range(1):
print('===Rank-%d (Include identical-view cases)===' % (i + 1))
print('NM: %.3f,\tBG: %.3f,\tCL: %.3f' % (
np.mean(acc[0, :, :, i]),
np.mean(acc[1, :, :, i]),
np.mean(acc[2, :, :, i])))
# Print rank-1 accuracy of the best modelfile,excluding identical-view cases
# e.g.
# ===Rank-1 (Exclude identical-view cases)===
# NM: 94.964, BG: 87.239, CL: 70.355
for i in range(1):
print('===Rank-%d (Exclude identical-view cases)===' % (i + 1))
print('NM: %.3f,\tBG: %.3f,\tCL: %.3f' % (
de_diag(acc[0, :, :, i]),
de_diag(acc[1, :, :, i]),
de_diag(acc[2, :, :, i])))
# Print rank-1 accuracy of the best modelfile (Each Angle)
# e.g.
# ===Rank-1 of each angle (Exclude identical-view cases)===
# NM: [90.80 97.90 99.40 96.90 93.60 91.70 95.00 97.80 98.90 96.80 85.80]
# BG: [83.80 91.20 91.80 88.79 83.30 81.00 84.10 90.00 92.20 94.45 79.00]
# CL: [61.40 75.40 80.70 77.30 72.10 70.10 71.50 73.50 73.50 68.40 50.00]
np.set_printoptions(precision=2, floatmode='fixed')
for i in range(1):
print('===Rank-%d of each angle (Exclude identical-view cases)===' % (i + 1))
print('NM:', de_diag(acc[0, :, :, i], True))
print('BG:', de_diag(acc[1, :, :, i], True))
print('CL:', de_diag(acc[2, :, :, i], True))
3.5.2 运行结果

因为前面的batch_size被我改小了,所以最后的Rank-1结果和作者给出的差异有点大。
4. 算法核心代码
首先放一下GaitSet的算法流程图:

4.1 gaitset.py☆
首先对gaitset模型进行初始化操作。在__init__部分,仅定义各层的操作,实际操作顺序在下面的foward函数中进行定义。
定义主体部分的卷积池化操作:
输入图片的通道数为1,卷积操作后的通道数为32,64,128,定义C1~C6六个层,分别为:
C1层:输入通道数1,输出通道数32,卷积核5×5,padding2
C2(+P)层:输入通道数32,输出通道数32,卷积核3×3,padding1,池化核2×2
C3层:输入通道数32,输出通道数64,卷积核3×3,padding1
C4(+P)层:输入通道数64,输出通道数64,卷积核3×3,padding1,池化核2×2
C5层:输入通道数64,输出通道数128,卷积核3×3,padding1
C6层:输入通道数128,输出通道数128,卷积核3×3,padding1
定义MGP部分的卷积池化操作:
因为输入来自C2层,所以输入通道数为32,卷积操作后的通道数为64,128,定义G1~G4四个层,分别为:
G1层:输入通道数32,输出通道数64,卷积核3×3,padding1
G2层:输入通道数64,输出通道数64,卷积核3×3,padding1
G3层:输入通道数64,输出通道数128,卷积核3×3,padding1
G4层:输入通道数128,输出通道数128,卷积核3×3,padding1
最大池化层,池化核2×2
定义前向传播forward函数:
输入的数据集是已经过图像预处理后的数据集,torch.size为[128,30,64,44],指的是128(8×16)个人,每个人有30帧图像,图像大小为64×44。
前向传播流程与上图相一致,将输入序列经过C1,C2卷积池化操作后进行SP(引入frame_max函数,将C1和C2层操作完的30帧图像进行最大值提取,并合成一帧,这一帧的特征就是SetPooling,因此G1层的torch.size变为[128,32,32,22]),然后上面的MGP和下面的主体分别、交互进行(交互指的是主体经过SP向MGP输入数据,下称“融合”),通过相加运算实现数据的融合。
HPM部分负责将图像分为5个尺度,分别为1,2,4,8,16条,并且将不可以进行训练的Tensor数据转化为自定义的Parameter,方面后续传入module中进行训练(成为模型的一部分)。
实现水平金字塔池化并完成全连接。首先将特征图在高度(h)尺度上进行分条,假设有 S S S个尺度,那么在尺度 s ∈ 1 , 2 , . . . , S s \in 1, 2, ..., S s∈1,2,...,S上,特征图高度被分为 2 s − 1 2^{s-1} 2s−1条,总共有 Σ s = 1 S 2 s − 1 \Sigma_{s=1}^S 2^{s-1} Σs=1S2s−1 条,然后对这些条进行全局池化,池化公式为:
f s , t ′ = m a x p o o l ( z s , t ) + a v g p o o l ( z s , t ) f'_{s,t} = maxpool(z_{s,t})+avgpool(z_{s,t}) fs,t′=maxpool(zs,t)+avgpool(zs,t)
其中 m a x p o o l maxpool maxpool和 a v g p o o l avgpool avgpool分别表示全局最大池化和全局平均池化,最后经过全连接 f c fc fc将特征映射到判别空间。

import torch
import torch.nn as nn
import numpy as np
from basic_blocks import SetBlock, BasicConv2d
class SetNet(nn.Module):
def __init__(self, hidden_dim):
super(SetNet, self).__init__()
self.hidden_dim = hidden_dim
self.batch_frame = None
#***注意此部分在__init__部分,仅定义各层的操作,实际操作顺序见Foward函数
#*主体部分的卷积、池化操作
_set_in_channels = 1 #*输入图片的通道数为1
_set_channels = [32, 64, 128] #*通道数列表
self.set_layer1 = SetBlock(BasicConv2d(_set_in_channels, _set_channels[0], 5, padding=2))
#*C1层:输入通道数1,输出通道数32,卷积核5×5,padding2
self.set_layer2 = SetBlock(BasicConv2d(_set_channels[0], _set_channels[0], 3, padding=1), True)
#*C2层:输入通道数32,输出通道数32,卷积核3×3,padding1,池化核2×2
self.set_layer3 = SetBlock(BasicConv2d(_set_channels[0], _set_channels[1], 3, padding=1))
#*C3层:输入通道数32,输出通道数64,卷积核3×3,padding1
self.set_layer4 = SetBlock(BasicConv2d(_set_channels[1], _set_channels[1], 3, padding=1), True)
#*C4层:输入通道数64,输出通道数64,卷积核3×3,padding1,池化核2×2
self.set_layer5 = SetBlock(BasicConv2d(_set_channels[1], _set_channels[2], 3, padding=1))
#*C5层:输入通道数64,输出通道数128,卷积核3×3,padding1
self.set_layer6 = SetBlock(BasicConv2d(_set_channels[2], _set_channels[2], 3, padding=1))
#*C6层:输入通道数128,输出通道数128,卷积核3×3,padding1
#*MGP部分的卷积、池化操作
_gl_in_channels = 32 #*以C2层输出数据作为这一部分的输入,可知C2层的输出通道数为32
_gl_channels = [64, 128] #*通道数列表
self.gl_layer1 = BasicConv2d(_gl_in_channels, _gl_channels[0], 3, padding=1)
#*G1层:输入通道数32,输出通道数64,卷积核3×3,padding1
self.gl_layer2 = BasicConv2d(_gl_channels[0], _gl_channels[0], 3, padding=1)
#*G2层:输入通道数64,输出通道数64,卷积核3×3,padding1
self.gl_layer3 = BasicConv2d(_gl_channels[0], _gl_channels[1], 3, padding=1)
#*G3层:输入通道数64,输出通道数128,卷积核3×3,padding1
self.gl_layer4 = BasicConv2d(_gl_channels[1], _gl_channels[1], 3, padding=1)
#*G4层:输入通道数128,输出通道数128,卷积核3×3,padding1
self.gl_pooling = nn.MaxPool2d(2)
#*最大池化层,池化核2×2
#*HPM部分的操作
self.bin_num = [1, 2, 4, 8, 16] #*将图像分为5个尺度,分别为1、2、4、8、16条
#*将不可以进行训练的Tensor数据转化为自定义的Parameter,
#*方面后续传入module中进行训练(成为模型的一部分)
#*init.xarier_uniform的作用类似于参数初始化,xavier-保持输入前后方差一致,uniform-均匀初始化
self.fc_bin = nn.ParameterList([
nn.Parameter(
nn.init.xavier_uniform_(
torch.zeros(sum(self.bin_num) * 2, 128, hidden_dim)))])
#*三个参数31*2,128,256
#*遍历module进行初始化
for m in self.modules():
if isinstance(m, (nn.Conv2d, nn.Conv1d)):
nn.init.xavier_uniform_(m.weight.data)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight.data)
nn.init.constant(m.bias.data, 0.0)
elif isinstance(m, (nn.BatchNorm2d, nn.BatchNorm1d)):
nn.init.normal(m.weight.data, 1.0, 0.02)
nn.init.constant(m.bias.data, 0.0)
#*framem_max和frame_median就是在实现SetPooling的操作
#*第二维度求最大函数
def frame_max(self, x):
if self.batch_frame is None:
return torch.max(x, 1) #*返回每行的最大值及其索引值
else:
_tmp = [
torch.max(x[:, self.batch_frame[i]:self.batch_frame[i + 1], :, :, :], 1)
for i in range(len(self.batch_frame) - 1)
]
max_list = torch.cat([_tmp[i][0] for i in range(len(_tmp))], 0)
arg_max_list = torch.cat([_tmp[i][1] for i in range(len(_tmp))], 0)
return max_list, arg_max_list
#*第二维度求平均函数
def frame_median(self, x):
if self.batch_frame is None:
return torch.median(x, 1) #*返回每行的平均值及其索引值
else:
_tmp = [
torch.median(x[:, self.batch_frame[i]:self.batch_frame[i + 1], :, :, :], 1)
for i in range(len(self.batch_frame) - 1)
]
median_list = torch.cat([_tmp[i][0] for i in range(len(_tmp))], 0)
arg_median_list = torch.cat([_tmp[i][1] for i in range(len(_tmp))], 0)
return median_list, arg_median_list
#*前向传播函数
#*这里就是核心算法操作顺序
def forward(self, silho, batch_frame=None): #*silho是裁剪处理完的数据集,silho torch.size([128,30,64,44])指的是128(8*16)个人(样本),每个人有30帧图像,图像大小为64*44
# n: batch_size, s: frame_num, k: keypoints_num, c: channel
if batch_frame is not None:
batch_frame = batch_frame[0].data.cpu().numpy().tolist()
_ = len(batch_frame)
for i in range(len(batch_frame)):
if batch_frame[-(i + 1)] != 0:
break
else:
_ -= 1
batch_frame = batch_frame[:_]
frame_sum = np.sum(batch_frame)
if frame_sum < silho.size(1):
silho = silho[:, :frame_sum, :, :]
self.batch_frame = [0] + np.cumsum(batch_frame).tolist()
n = silho.size(0) #*n=128
x = silho.unsqueeze(2) #*在索引值为2的位置插入一个维度,表示通道数
#*此处silho torch.size([128,30,1,64,44])
del silho
x = self.set_layer1(x) #*C1层:[128,30,1,64,44]--->[128,30,32,64,44]
x = self.set_layer2(x) #*C2层:[128,30,32,64,44]--->[128,30,32,32,22],含有一层池化,图像高度宽度压缩一半
#*下面引入frame_max函数,将C1和C2层操作完的30帧图像进行最大值提取,并合成一帧,这一帧的特征就是SetPooling,因此G1层的torch.size变为[128,32,32,22]
gl = self.gl_layer1(self.frame_max(x)[0]) #*G1层:[128,30,32,32,22]--->[128,64,32,22]
gl = self.gl_layer2(gl) #*G2层:[128,64,32,22]--->[128,64,32,22]
gl = self.gl_pooling(gl) #*[128,64,32,22]--->[128,64,16,11],池化一次,图像高度宽度压缩一半
x = self.set_layer3(x) #*C3层:[128,30,32,32,22]--->[128,30,64,32,22]
x = self.set_layer4(x) #*C4层:[128,30,64,32,22]--->[128,30,64,16,11],含有一层池化,图像高度宽度压缩一半
gl = self.gl_layer3(gl + self.frame_max(x)[0]) #*G3层:融合C4层输出的SetPooling和G2层(相加),再进行卷积 [128,64,16,11]--->[128,128,16,11]
gl = self.gl_layer4(gl) #*G4层:[128,128,16,11]--->[128,128,16,11]
x = self.set_layer5(x) #*C5层:[128,30,64,16,11]--->[128,30,128,16,11]
x = self.set_layer6(x) #*C6层:[128,30,128,16,11]--->[128,30,128,16,11],这里没有池化层嗷
x = self.frame_max(x)[0] #*进行一次SP [128,30,128,16,11]--->[128,128,16,11]
gl = gl + x #*将G4层与C6层融合(相加)
#*HPM部分的操作
feature = list() #*feature是一个列表类型的数据
n, c, h, w = gl.size() #*n,c,h,w分别对应torch.size([128,128,16,11]
for num_bin in self.bin_num: #*循环取金字塔数据
z = x.view(n, c, num_bin, -1)
#*view函数的作用相当于numpy中的reshape,即重新定义矩阵的形状
#*参数-1可以动态调整这个维度位置上元素的个数,以保证列表中总元素的数量是不变的
#*因此在这一for循环中,z torch.size分别为
#*torch.size([128,128,1,176])
#*torch.size([128,128,2,88])
#*torch.size([128,128,4,44])
#*torch.size([128,128,8,22])
#*torch.size([128,128,16,11])
z = z.mean(3) + z.max(3)[0] #*对最后一个维度求均值和最大值,并对应相加
#*这里应用的是全局池化,将三维特征变为一维特征。全局池化的公式是f=maxpool+avgpool
#*其中maxpool和avgpool分别表示全局最大池化核全局平均池化
#*(之所以这样用是因为作者发现这样的实验效果最佳,具体原因未知??)
feature.append(z) #*append函数能够实现在列表末尾添加元素,上面计算的z直接添加到feature末尾
#*对于MGP层同样进行全局池化操作
z = gl.view(n, c, num_bin, -1)
z = z.mean(3) + z.max(3)[0]
feature.append(z)
#*实现HPP
feature = torch.cat(feature, 2).permute(2, 0, 1).contiguous()
#*cat函数实现元素的连接
#*permute函数调整维度顺序(2->0, 0->1, 1->2)
#*contiguous函数实现深拷贝(操作后原始数据不变)
#*操作后feature torch.size([62,128,128])
feature = feature.matmul(self.fc_bin[0])
#*实现矩阵的乘法,fc_bin:62*128*256
#*可以理解为有62个条带,每个条带是128维,对每个条带进行FC全连接
feature = feature.permute(1, 0, 2).contiguous()
return feature, None
4.2 model.py
此文件主要是对模型训练、测试、损失等模块的初始化(预定义??)一些杂七杂八的内容,对其中几个自定义函数作简要分析。
collate_fn: 定义DataLoader如何取出数据集中的步态图像
select_frame: 定义图像的取出是按照随机有放回的原则,取出30帧
fit: 对模型进行训练,也就是反向传播的过程,训练出权重系数
np2ts: 数据类型转换numpy to tensor
transform: 测试模型
import math
import os
import os.path as osp
import random
import sys
from datetime import datetime
import numpy as np
import torch
import torch.nn as nn
import torch.autograd as autograd
import torch.optim as optim
import torch.utils.data as tordata
# from model.network import TripletLoss, SetNet
from triplet import TripletLoss
from gaitset import SetNet
# from model.utils import TripletSampler
from sampler import TripletSampler
class Model:
def __init__(self,
hidden_dim,
lr,
hard_or_full_trip,
margin,
num_workers,
batch_size,
restore_iter,
total_iter,
save_name,
train_pid_num,
frame_num,
model_name,
train_source,
test_source,
img_size=64):
self.save_name = save_name
self.train_pid_num = train_pid_num
self.train_source = train_source
self.test_source = test_source
self.hidden_dim = hidden_dim
self.lr = lr
self.hard_or_full_trip = hard_or_full_trip
self.margin = margin
self.frame_num = frame_num
self.num_workers = num_workers
self.batch_size = batch_size
self.model_name = model_name
self.P, self.M = batch_size
self.restore_iter = restore_iter
self.total_iter = total_iter
self.img_size = img_size
self.encoder = SetNet(self.hidden_dim).float()
self.encoder = nn.DataParallel(self.encoder)
self.triplet_loss = TripletLoss(self.P * self.M, self.hard_or_full_trip, self.margin).float()
self.triplet_loss = nn.DataParallel(self.triplet_loss)
self.encoder.cuda()
self.triplet_loss.cuda()
self.optimizer = optim.Adam([
{'params': self.encoder.parameters()},
], lr=self.lr)
self.hard_loss_metric = []
self.full_loss_metric = []
self.full_loss_num = []
self.dist_list = []
self.mean_dist = 0.01
self.sample_type = 'all'
def collate_fn(self, batch):
batch_size = len(batch)
feature_num = len(batch[0][0])
seqs = [batch[i][0] for i in range(batch_size)]
frame_sets = [batch[i][1] for i in range(batch_size)]
view = [batch[i][2] for i in range(batch_size)]
seq_type = [batch[i][3] for i in range(batch_size)]
label = [batch[i][4] for i in range(batch_size)]
batch = [seqs, view, seq_type, label, None]
def select_frame(index):
sample = seqs[index]
frame_set = frame_sets[index]
if self.sample_type == 'random':
frame_id_list = random.choices(frame_set, k=self.frame_num)
_ = [feature.loc[frame_id_list].values for feature in sample]
else:
_ = [feature.values for feature in sample]
return _
seqs = list(map(select_frame, range(len(seqs))))
if self.sample_type == 'random':
seqs = [np.asarray([seqs[i][j] for i in range(batch_size)]) for j in range(feature_num)]
else:
gpu_num = min(torch.cuda.device_count(), batch_size)
batch_per_gpu = math.ceil(batch_size / gpu_num)
batch_frames = [[
len(frame_sets[i])
for i in range(batch_per_gpu * _, batch_per_gpu * (_ + 1))
if i < batch_size
] for _ in range(gpu_num)]
if len(batch_frames[-1]) != batch_per_gpu:
for _ in range(batch_per_gpu - len(batch_frames[-1])):
batch_frames[-1].append(0)
max_sum_frame = np.max([np.sum(batch_frames[_]) for _ in range(gpu_num)])
seqs = [[
np.concatenate([
seqs[i][j]
for i in range(batch_per_gpu * _, batch_per_gpu * (_ + 1))
if i < batch_size
], 0) for _ in range(gpu_num)]
for j in range(feature_num)]
seqs = [np.asarray([
np.pad(seqs[j][_],
((0, max_sum_frame - seqs[j][_].shape[0]), (0, 0), (0, 0)),
'constant',
constant_values=0)
for _ in range(gpu_num)])
for j in range(feature_num)]
batch[4] = np.asarray(batch_frames)
batch[0] = seqs
return batch
def fit(self):
if self.restore_iter != 0:
self.load(self.restore_iter)
self.encoder.train()
self.sample_type = 'random'
for param_group in self.optimizer.param_groups:
param_group['lr'] = self.lr
triplet_sampler = TripletSampler(self.train_source, self.batch_size)
train_loader = tordata.DataLoader(
dataset=self.train_source,
batch_sampler=triplet_sampler,
collate_fn=self.collate_fn,
num_workers=self.num_workers)
train_label_set = list(self.train_source.label_set)
train_label_set.sort()
_time1 = datetime.now()
_time0 = datetime.now()
for seq, view, seq_type, label, batch_frame in train_loader:
self.restore_iter += 1
self.optimizer.zero_grad()
for i in range(len(seq)):
seq[i] = self.np2var(seq[i]).float()
if batch_frame is not None:
batch_frame = self.np2var(batch_frame).int()
feature, label_prob = self.encoder(*seq, batch_frame)
target_label = [train_label_set.index(l) for l in label]
target_label = self.np2var(np.array(target_label)).long()
triplet_feature = feature.permute(1, 0, 2).contiguous()
triplet_label = target_label.unsqueeze(0).repeat(triplet_feature.size(0), 1)
(full_loss_metric, hard_loss_metric, mean_dist, full_loss_num
) = self.triplet_loss(triplet_feature, triplet_label)
if self.hard_or_full_trip == 'hard':
loss = hard_loss_metric.mean()
elif self.hard_or_full_trip == 'full':
loss = full_loss_metric.mean()
self.hard_loss_metric.append(hard_loss_metric.mean().data.cpu().numpy())
self.full_loss_metric.append(full_loss_metric.mean().data.cpu().numpy())
self.full_loss_num.append(full_loss_num.mean().data.cpu().numpy())
self.dist_list.append(mean_dist.mean().data.cpu().numpy())
if loss > 1e-9:
loss.backward()
self.optimizer.step()
if self.restore_iter == 80000:
print(datetime.now() - _time0)
if self.restore_iter % 1000 == 0:
print(datetime.now() - _time1)
_time1 = datetime.now()
if self.restore_iter % 100 == 0:
self.save()
print('iter {}:'.format(self.restore_iter), end='')
print(', hard_loss_metric={0:.8f}'.format(np.mean(self.hard_loss_metric)), end='')
print(', full_loss_metric={0:.8f}'.format(np.mean(self.full_loss_metric)), end='')
print(', full_loss_num={0:.8f}'.format(np.mean(self.full_loss_num)), end='')
self.mean_dist = np.mean(self.dist_list)
print(', mean_dist={0:.8f}'.format(self.mean_dist), end='')
print(', lr=%f' % self.optimizer.param_groups[0]['lr'], end='')
print(', hard or full=%r' % self.hard_or_full_trip)
sys.stdout.flush()
self.hard_loss_metric = []
self.full_loss_metric = []
self.full_loss_num = []
self.dist_list = []
# Visualization using t-SNE
# if self.restore_iter % 500 == 0:
# pca = TSNE(2)
# pca_feature = pca.fit_transform(feature.view(feature.size(0), -1).data.cpu().numpy())
# for i in range(self.P):
# plt.scatter(pca_feature[self.M * i:self.M * (i + 1), 0],
# pca_feature[self.M * i:self.M * (i + 1), 1], label=label[self.M * i])
#
# plt.show()
if self.restore_iter == self.total_iter:
break
def ts2var(self, x):
return autograd.Variable(x).cuda()
def np2var(self, x):
return self.ts2var(torch.from_numpy(x))
def transform(self, flag, batch_size=1):
self.encoder.eval()
source = self.test_source if flag == 'test' else self.train_source
self.sample_type = 'all'
data_loader = tordata.DataLoader(
dataset=source,
batch_size=batch_size,
sampler=tordata.sampler.SequentialSampler(source),
collate_fn=self.collate_fn,
num_workers=self.num_workers)
feature_list = list()
view_list = list()
seq_type_list = list()
label_list = list()
for i, x in enumerate(data_loader):
seq, view, seq_type, label, batch_frame = x
for j in range(len(seq)):
seq[j] = self.np2var(seq[j]).float()
if batch_frame is not None:
batch_frame = self.np2var(batch_frame).int()
# print(batch_frame, np.sum(batch_frame))
feature, _ = self.encoder(*seq, batch_frame)
n, num_bin, _ = feature.size()
feature_list.append(feature.view(n, -1).data.cpu().numpy())
view_list += view
seq_type_list += seq_type
label_list += label
return np.concatenate(feature_list, 0), view_list, seq_type_list, label_list
def save(self):
os.makedirs(osp.join('checkpoint', self.model_name), exist_ok=True)
torch.save(self.encoder.state_dict(),
osp.join('checkpoint', self.model_name,
'{}-{:0>5}-encoder.ptm'.format(
self.save_name, self.restore_iter)))
torch.save(self.optimizer.state_dict(),
osp.join('checkpoint', self.model_name,
'{}-{:0>5}-optimizer.ptm'.format(
self.save_name, self.restore_iter)))
# restore_iter: iteration index of the checkpoint to load
def load(self, restore_iter):
self.encoder.load_state_dict(torch.load(osp.join(
'checkpoint', self.model_name,
'{}-{:0>5}-encoder.ptm'.format(self.save_name, restore_iter))))
self.optimizer.load_state_dict(torch.load(osp.join(
'checkpoint', self.model_name,
'{}-{:0>5}-optimizer.ptm'.format(self.save_name, restore_iter))))
4.3 triplet.py
定义Batch All的三元损失(triplet loss)函数:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TripletLoss(nn.Module):
def __init__(self, batch_size, hard_or_full, margin):
super(TripletLoss, self).__init__()
self.batch_size = batch_size
self.margin = margin
def forward(self, feature, label):
# feature: [n, m, d], label: [n, m]
n, m, d = feature.size()
hp_mask = (label.unsqueeze(1) == label.unsqueeze(2)).byte().view(-1)
hp_mask = hp_mask.bool()
hn_mask = (label.unsqueeze(1) != label.unsqueeze(2)).byte().view(-1)
hn_mask = hn_mask.bool()
dist = self.batch_dist(feature)
mean_dist = dist.mean(1).mean(1)
dist = dist.view(-1)
# hard
hard_hp_dist = torch.max(torch.masked_select(dist, hp_mask).view(n, m, -1), 2)[0]
hard_hn_dist = torch.min(torch.masked_select(dist, hn_mask).view(n, m, -1), 2)[0]
hard_loss_metric = F.relu(self.margin + hard_hp_dist - hard_hn_dist).view(n, -1)
hard_loss_metric_mean = torch.mean(hard_loss_metric, 1)
# non-zero full
full_hp_dist = torch.masked_select(dist, hp_mask).view(n, m, -1, 1)
full_hn_dist = torch.masked_select(dist, hn_mask).view(n, m, 1, -1)
full_loss_metric = F.relu(self.margin + full_hp_dist - full_hn_dist).view(n, -1)
full_loss_metric_sum = full_loss_metric.sum(1)
full_loss_num = (full_loss_metric != 0).sum(1).float()
full_loss_metric_mean = full_loss_metric_sum / full_loss_num
full_loss_metric_mean[full_loss_num == 0] = 0
return full_loss_metric_mean, hard_loss_metric_mean, mean_dist, full_loss_num
def batch_dist(self, x):
x2 = torch.sum(x ** 2, 2)
dist = x2.unsqueeze(2) + x2.unsqueeze(2).transpose(1, 2) - 2 * torch.matmul(x, x.transpose(1, 2))
dist = torch.sqrt(F.relu(dist))
return dist
5. (原作)运行结果


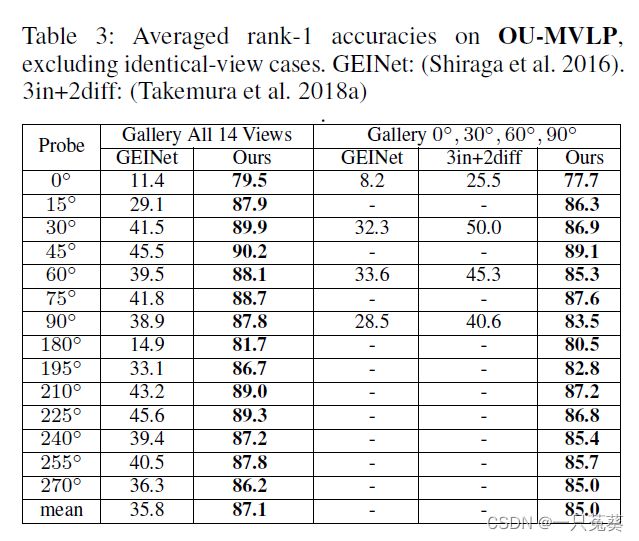

附录
我在项目中配置的包及版本号参见以下表格,里面绝大多数的包是没有被调用的,如果用户使用的是一个没有安装任何Package的空白环境,可以根据代码中import的内容依次安装;如果用户已经安装了Package,但是出现了因版本原因报错的现象,可以根据下表核对版本,适当升级或降低相应版本。
| Package | Version |
|---|---|
| absl-py | 1.3.0 |
| aiohttp | 3.8.1 |
| aiosignal | 1.2.0 |
| argon2-cffi | 20.1.0 |
| async-timeout | 4.0.2 |
| async_generator | 1.1 |
| asynctest | 0.13.0 |
| attrs | 21.4.0 |
| backcall | 0.2.0 |
| beautifulsoup4 | 4.11.1 |
| blas | 1 |
| bleach | 4.1.0 |
| blinker | 1.4 |
| brotli | 1.0.9 |
| brotli-bin | 1.0.9 |
| brotlipy | 0.7.0 |
| ca-certificates | 2022.07.19 |
| cachetools | 4.2.2 |
| certifi | 2022.9.24 |
| cffi | 1.14.6 |
| charset-normalizer | 2.0.4 |
| click | 8.0.4 |
| colorama | 0.4.4 |
| cryptography | 37.0.1 |
| cudatoolkit | 10.0.130 |
| cycler | 0.11.0 |
| dataclasses | 0.8 |
| decorator | 4.4.2 |
| defusedxml | 0.7.1 |
| dominate | 2.6.0 |
| entrypoints | 0.3 |
| fftw | 3.3.9 |
| fonttools | 4.25.0 |
| freetype | 2.10.4 |
| frozenlist | 1.2.0 |
| glib | 2.69.1 |
| google-auth | 2.6.0 |
| google-auth-oauthlib | 0.5.2 |
| grpcio | 1.42.0 |
| gst-plugins-base | 1.18.5 |
| gstreamer | 1.18.5 |
| h5py | 2.10.0 |
| hdf5 | 1.10.4 |
| icc_rt | 2022.1.0 |
| icu | 58.2 |
| idna | 3.3 |
| imageio | 2.19.3 |
| importlib-metadata | 4.11.3 |
| intel-openmp | 2021.4.0 |
| ipykernel | 5.3.4 |
| ipython | 7.16.1 |
| ipython_genutils | 0.2.0 |
| jedi | 0.17.0 |
| jinja2 | 3.0.3 |
| joblib | 1.1.0 |
| jpeg | 9e |
| jsonschema | 3.0.2 |
| jupyter-core | 4.11.1 |
| jupyter_client | 7.1.2 |
| jupyter_core | 4.8.1 |
| jupyterlab_pygments | 0.1.2 |
| kiwisolver | 1.3.1 |
| lerc | 3 |
| libbrotlicommon | 1.0.9 |
| libbrotlidec | 1.0.9 |
| libbrotlienc | 1.0.9 |
| libclang | 12.0.0 |
| libdeflate | 1.8 |
| libffi | 3.4.2 |
| libiconv | 1.16 |
| libogg | 1.3.5 |
| libpng | 1.6.37 |
| libprotobuf | 3.20.1 |
| libsodium | 1.0.18 |
| libtiff | 4.4.0 |
| libvorbis | 1.3.7 |
| libwebp | 1.2.4 |
| libwebp-base | 1.2.4 |
| libxml2 | 2.9.14 |
| libxslt | 1.1.35 |
| lz4-c | 1.9.3 |
| m2w64-gcc-libgfortran | 5.3.0 |
| m2w64-gcc-libs | 5.3.0 |
| m2w64-gcc-libs-core | 5.3.0 |
| m2w64-gmp | 6.1.0 |
| m2w64-libwinpthread-git | 5.0.0.4634.697f757 |
| markdown | 3.3.4 |
| markupsafe | 2.0.1 |
| matplotlib | 3.5.2 |
| matplotlib-base | 3.5.2 |
| mistune | 0.8.4 |
| mkl | 2021.4.0 |
| mkl-service | 2.4.0 |
| mkl_fft | 1.3.1 |
| mkl_random | 1.2.2 |
| msys2-conda-epoch | 20160418 |
| multidict | 6.0.2 |
| munkres | 1.1.4 |
| nbclient | 0.5.13 |
| nbconvert | 6.0.7 |
| nbformat | 5.1.3 |
| nest-asyncio | 1.5.1 |
| networkx | 2.5.1 |
| ninja | 1.10.2 |
| ninja-base | 1.10.2 |
| notebook | 6.4.3 |
| numpy | 1.16.2 |
| numpy-base | 1.21.5 |
| oauthlib | 3.2.0 |
| olefile | 0.46 |
| opencv-python | 4.6.0.66 |
| openssl | 1.1.1q |
| packaging | 21.3 |
| pandas | 1.1.5 |
| pandoc | 2.12 |
| pandocfilters | 1.5.0 |
| parso | 0.8.3 |
| pcre | 8.45 |
| pickleshare | 0.7.5 |
| pillow | 8.4.0 |
| pip | 21.2.2 |
| ply | 3.11 |
| prettytable | 2.5.0 |
| prometheus_client | 0.13.1 |
| prompt-toolkit | 3.0.20 |
| protobuf | 3.20.1 |
| pyasn1 | 0.4.8 |
| pyasn1-modules | 0.2.8 |
| pycparser | 2.21 |
| pyecharts | 1.9.1 |
| pygments | 2.11.2 |
| pyjwt | 2.4.0 |
| pyopenssl | 22.0.0 |
| pyparsing | 3.0.9 |
| pyqt | 5.15.7 |
| pyqt5-sip | 12.11.0 |
| pyreadline | 2.1 |
| pyrsistent | 0.17.3 |
| pysnooper | 1.1.1 |
| pysocks | 1.7.1 |
| python | 3.7.13 |
| python-dateutil | 2.8.2 |
| python-fastjsonschema | 2.16.2 |
| pytorch | 1.2.0 |
| pytz | 2021.3 |
| pywavelets | 1.1.1 |
| pywin32 | 228 |
| pywinpty | 0.5.7 |
| pyzmq | 22.2.1 |
| qt-main | 5.15.2 |
| qt-webengine | 5.15.9 |
| qtwebkit | 5.212 |
| ranger | 0.1 |
| requests | 2.27.1 |
| requests-oauthlib | 1.3.0 |
| rsa | 4.7.2 |
| scikit-image | 0.17.2 |
| scikit-learn | 0.24.2 |
| scipy | 1.7.3 |
| seaborn | 0.11.2 |
| send2trash | 1.8.0 |
| setuptools | 58.0.4 |
| simplejson | 3.17.6 |
| sip | 6.6.2 |
| six | 1.16.0 |
| sklearn | 0 |
| soupsieve | 2.3.2.post1 |
| sqlite | 3.39.3 |
| tensorboard-data-server | 0.6.0 |
| tensorboard-plugin-wit | 1.8.1 |
| terminado | 0.9.4 |
| testpath | 0.5.0 |
| threadpoolctl | 2.2.0 |
| tifffile | 2020.9.22 |
| tk | 8.6.12 |
| toml | 0.10.2 |
| torch | 1.12.1 |
| torchsnooper | 0.8 |
| torchvision | 0.4.0 |
| tornado | 6.2 |
| tqdm | 4.61.1 |
| traitlets | 4.3.3 |
| typing-extensions | 4.1.1 |
| typing_extensions | 4.1.1 |
| urllib3 | 1.26.9 |
| vc | 14.2 |
| vs2015_runtime | 14.27.29016 |
| wcwidth | 0.2.5 |
| webencodings | 0.5.1 |
| werkzeug | 2.0.3 |
| wheel | 0.37.1 |
| win_inet_pton | 1.1.0 |
| wincertstore | 0.2 |
| winpty | 0.4.3 |
| xarray | 0.16.2 |
| xz | 5.2.6 |
| yarl | 1.8.1 |
| zeromq | 4.3.4 |
| zipp | 3.6.0 |
| zlib | 1.2.12 |
| zstd | 1.5.2 |
参考博客:
【论文翻译】-- GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition
【原创·论文翻译】GaitSet-旨在用自己的语言表达出作者的真实意图
跑通GaitSet(跑不通你来揍我)
GaitSet源代码解读(一)
GaitSet源代码解读(二)
GaitSet源代码解读(三)