中文信息处理(五)—— 文本分类与文本表示
文章目录
- 1. 文本分类
-
- 1.1 文本分类方法
-
- 基于传统机器学习的文本分类
- 1.2 文本分类的一般流程
- 2. 基于向量空间模型(VSM)的文本表示方法
-
- 2.1 one-hot表示
- 2.2 VSM
-
-
- ① 文档(Document)
- ② 项(Term)
-
- 2.3 特征选择常用方法
-
- ① 文档频率DF
- ② 信息增益IG
- ③ 互信息(MI)
- ④ χ 2 \chi^{2} χ2统计量
- 2.4 权重计算
-
- ① TF-IDF
- ② scikit-learn预处理
- 2.5 VSM的评价
- 3. 基于矩阵的文本表示方法
-
- 3.1 基于矩阵
- 3.2 奇异值分解(SVD分解)
- 3.3 评价
1. 文本分类
Text Categorization/Text Classification/TC
是根据给定文本的内容,将其判别为事先确定的若干个文本类别中的某一类或某几类的过程
给定:
• 一个实例的描述, x ∈ X x∈X x∈X, X X X是实例空间
• 一个固定的文本分类体系: C = c 1 , c 2 , … c n C={c1, c2,…cn} C=c1,c2,…cn
• 由于类别是事先定义好的,因此分类是有指导的(或者说是有监督的)
确定:
• 实例x的类别 c ( x ) ∈ C c(x)∈C c(x)∈C, c ( x ) c(x) c(x)是一个分类函数,定义域是X,值域是C
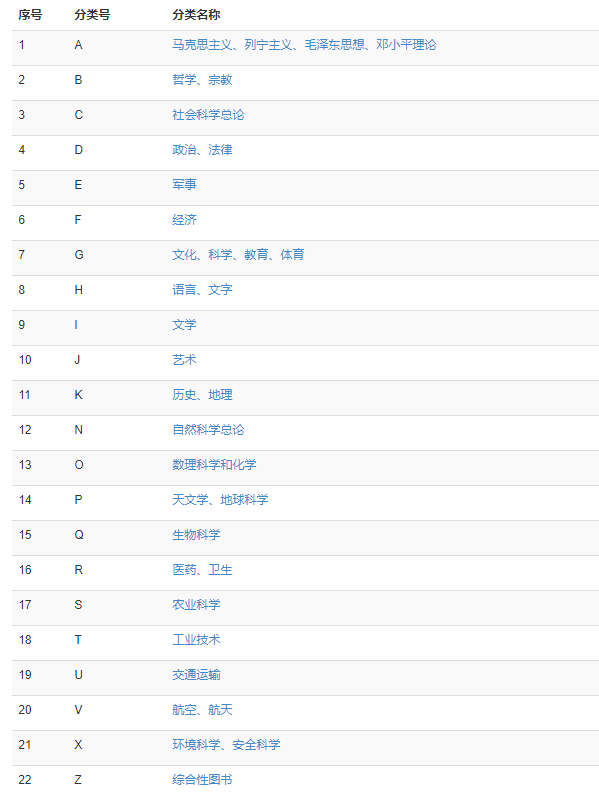
例如中图分类法:
1.1 文本分类方法
基于传统机器学习的文本分类
随着统计学习方法的发展,在90年代后解决大规模文本分类问题的主要套路是人工特征工程+浅层分类模型。整个文本分类问题拆分成特征工程和分类器两部分
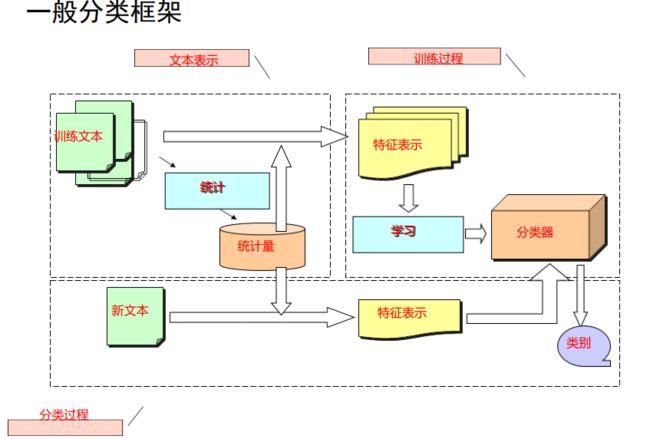
这里的特征工程也就是将文本表示为计算机可以识别的、能够代表该文档特征的特征矩阵的过程。我们通常将特征工程分为文本预处理、特征提取、文本表示等三个部分。
1.2 文本分类的一般流程
- 收集训练集和测试集,对文本进行预处理
- 数据清洗,去除指定无用的符号
- 让文本只保留汉字
- 对文本进行分词(词性标注)
- 去除停用词
- 对文本类别进行人工标注
- 对文本进行特征提取、文本表示
- 训练(学习)
- 评价:精确率、召回率、F1;宏平均、微平
均
对于特征工程中的文本表示,有下面几个方法:
2. 基于向量空间模型(VSM)的文本表示方法
对于下面两个文本,人类是如何区别的?
A. 中信证券建筑首席分析师罗鼎认为,发改委加大对重大基础设施建设项目审批力度,凸显逆周期调节重要性。
B. 2018年5月,太原国际马拉松赛被国际田联认定为银标赛事,成为全国第八个获得这项荣誉的马拉松赛
显然,在人的意识里,是通过几个关键词来区分文本的,这对于我们有一定的启发
2.1 one-hot表示
对一个语料库S中的所有句子 s ∈ S , s = w 1 w 2 … w n s∈S,s=w_1w_2…w_n s∈S,s=w1w2…wn。抽取其中包含的所有词汇 w i w_i wi,因为语气词对于文本的主题分类一般不起作用,所以去除其中的停用词(的、了、在、呢、啊等等),记为集合W。
对任意 w i ∈ W w_i ∈W wi∈W统计其在S中出现文档频次的文档频次 d f ( w ) df(w) df(w),依照频次大小降序排列,取排序前 N − M N-M N−M位或前 N N%-M%(N
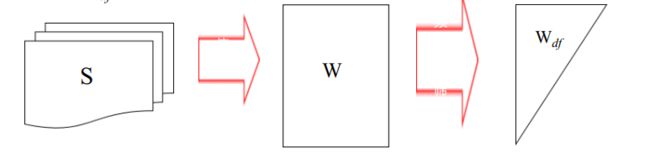
以 W d f W_{df} Wdf为基础可将一个文本表示为一个k维0-1向量V, k = ∣ W d f ∣ k = | W_{df}| k=∣Wdf∣,称之为one-hot表示或者词袋模型表示。
V i = { 1 , w i ∈ W d f , w i in s 0 , w i ∈ W d f , w i not in s (1) V_{i}=\left\{\begin{array}{c}1, \quad w_{i} \in W_{d f}, w_{i} \text { in } s \\ 0, \quad w_{i} \in W_{d f}, w_{i} \text { not in } s\end{array}\right. \tag{1} Vi={1,wi∈Wdf,wi in s0,wi∈Wdf,wi not in s(1)
One-hot模型是VSM的一种简化形式
例如:
A. 中信证券建筑首席分析师罗鼎认为,发改委加大对重大基础设施建设项目审批力度,凸显逆周期调节重要性。
B. 2018年5月,太原国际马拉松赛被国际田联认定为银标赛事,成为全国第八个获得这项荣誉的马拉松赛。
假设有特征词集Wtf = {证券,分析师,发改委,审批,马拉松,田联,赛事}。那么例句A、B分别表示为:
A = [ 1 , 1 , 1 , 1 , 0 , 0 , 0 ] B = [ 0 , 0 , 0 , 0 , 1 , 1 , 1 ] A = [1, 1, 1, 1, 0, 0, 0] B=[0, 0, 0, 0, 1, 1, 1] A=[1,1,1,1,0,0,0]B=[0,0,0,0,1,1,1]
2.2 VSM
向量空间模型,VSM,Vector Space Model,由Salton等人于20世纪70年代提出
VSM把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度(当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性 )。
VSM包括:
- 用于表征文档语义的特征
- 这些特征的组织方式
可以说,自然语言处理的核心是文本的向量化表示
① 文档(Document)
泛指一般的文献或文献中的片断(段落、句子组或句子),一般指一篇文章。
② 项(Term)
当文档的内容被简单地看成是它含有的基本语言单位(字、词、词组或短语等)所组成的集合时,这些基本的语言单位统称为项,即文档可以用项集(Term List)表示为 D ( T 1 , T 2 … , T n ) D(T_1,T_2…,T_n) D(T1,T2…,Tn)
注意:标点符号可以应用到文档的语体分类,在反动信息过滤中也有重要的作用 。
TF:一个词在一个文档出现次数
DF:一个词出现在几个文档中
2.3 特征选择常用方法
① 文档频率DF
文档频率(Document frequency ) 指在训练语料中出现某词条的文档数
选取的DF在某个范围内。因为出现太少,没有代表性,出现太多,没有区分度。
② 信息增益IG
对于特征词条t和文档类别c,IG考察c中出现和不出现t的文档频数来衡量t对于c的信息增益
I G ( t ) = − ∑ i = 1 m P ( c i ) lg P ( c i ) + P ( t ) ∑ i = 1 m P ( c i ∣ t ) lg P ( c i ∣ t ) + P ( t ˉ ) ∑ i = 1 m P ( c i ∣ t ˉ ) lg P ( c i ∣ t ˉ ) (2) I G(t)=-\sum_{i=1}^{m} P\left(c_{i}\right) \lg P\left(c_{i}\right)+P(t) \sum_{i=1}^{m} P\left(c_{i} \mid t\right) \lg P\left(c_{i} \mid t\right) +P(\bar{t}) \sum_{i=1}^{m} P\left(c_{i} \mid \bar{t}\right) \lg P\left(c_{i} \mid \bar{t}\right) \tag{2} IG(t)=−i=1∑mP(ci)lgP(ci)+P(t)i=1∑mP(ci∣t)lgP(ci∣t)+P(tˉ)i=1∑mP(ci∣tˉ)lgP(ci∣tˉ)(2)
其中 P ( C i ) P(C_i) P(Ci)表示类文档在语料中出现的概率, P(t)表示语料中包含特征词条 t 的文档的概率, P ( C i ∣ t ) P(C_i|t) P(Ci∣t) 表示文档包含特征词条 t 时属于类的条件概率, P ( t ˉ ) P(\bar{t}) P(tˉ)表示语料中不包含特征词条 t 的文档的概率, P ( C i ∣ t ˉ ) P(C_i|\bar{t}) P(Ci∣tˉ)表示文档不包含特征词条 t 时属于类的条件概率, m 表示文档类别数。
如果选择一个特征后,信息增益最大(信息不确定性减少的程度最大),那么我们就选取这个特征。
- 优点:考虑了词条未发生的情况,即虽然某个单词不出现也可能对判断文本类别有贡献。
- 缺点:非平衡问题下表现差(在类分布和特征值分布是高度不平衡的情况下其效果就会大大降低了)
③ 互信息(MI)
通过计算特征词条t和类别c之间的相关性来完成提取的 :
M I ( t , c ) = log P ( t c ) P ( t ) × P ( c ) (3) MI( t , c ) = \log \frac { P ( t c ) } { P ( t ) \times P ( c ) } \tag{3} MI(t,c)=logP(t)×P(c)P(tc)(3)
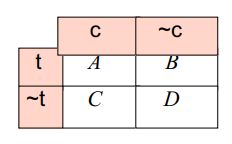
如果用A表示包含特征词条t且属于类别c的文档频数,B为包含t但是不属于c的文档频数,C表示属于c但不包含t的文档频数,N表示语料中文档的总数,t和c的互信息可由下式计算 :
M I ( t , c ) ≈ lg A × N ( A + C ) × ( A + B ) (4) M I(t, c) \approx \lg \frac{A \times N}{(A+C) \times(A+B)} \tag{4} MI(t,c)≈lg(A+C)×(A+B)A×N(4)
④ χ 2 \chi^{2} χ2统计量
度量特征词条t和文档类别c之间的相关程度,并假设t和c之间符合具有一阶自由度的分布 。(特征词条对于某类的统计值越高,它与该类之间的相关性越大,携带的类别信息也越多,当的值为0时,属性t与类别c完全独立 )
令N表示训练语料中的文档总数 ,D是既不属于c也不包含t的文档频数 ,可用下式表示:
χ 2 ( t , c ) = N ( A D − C B ) 2 ( A + C ) ( B + D ) ( A + B ) ( C + D ) (5) \chi^{2}(t, c)=\frac{N(A D-C B)^{2}}{(A+C)(B+D)(A+B)(C+D)} \tag{5} χ2(t,c)=(A+C)(B+D)(A+B)(C+D)N(AD−CB)2(5)
其中, N = A + B + C + D N=A+B+C+D N=A+B+C+D
(注:一般上面公式只适用于二分类的情况)
几种特征选择方法性能比较:
依据上一步得到文本的表示特征,构建向量空间模型, 计算每个句子表示向量表示中每一个特征维度的权重(权重计算)
2.4 权重计算
① TF-IDF
词频-逆文档频度(Term Frequency - InverseDocument Frequency,TF-IDF)
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。为了同时考虑两部分的影响,提出了TF-IDF ,定义如下:
词 频 ( T F ) = 某个词在文章中的出现次数 文章的总词数 (6) 词频(TF) =\frac{\text { 某个词在文章中的出现次数 }}{\text { 文章的总词数 }} \tag{6} 词频(TF)= 文章的总词数 某个词在文章中的出现次数 (6)
逆 文 档 频 率 ( I D F ) = log 语料库文档数 包含该词的文档数 (7) 逆文档频率(I D F)=\log \frac{\text { 语料库文档数 }}{\text { 包含该词的文档数 }} \tag{7} 逆文档频率(IDF)=log 包含该词的文档数 语料库文档数 (7)
T F − I D F = T F ∗ I D F (8) TF-IDF=TF*IDF \tag{8} TF−IDF=TF∗IDF(8)
可以看到,IDF反应了一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低。一个极端的情况,如果一个词在所有的文本中都出现,那么它的IDF值应该为0。
常用的IDF我们需要做一些平滑,使语料库中没有出现的词也可以得到一个合适的IDF值。
逆 文 档 频 率 ( I D F ) = log 语料库文档数 包含该词的文档数+1 逆文档频率(I D F)=\log \frac{\text { 语料库文档数 }}{\text { 包含该词的文档数+1 }} 逆文档频率(IDF)=log 包含该词的文档数+1 语料库文档数
② scikit-learn预处理
用scikit-learn进行TF-IDF预处理,有两种方法可以进行TF-IDF的预处理 :
CountVectorizer+TfidfTransformer
from sklearn. feature extraction. text import Tfidftransformer
from sklearn. feature extraction. text import Countvectorizer
corpus=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple"]
vectorizer=Countvectorizer()
trans former Tfidftrans former()
tfidf =transformer fit transform(vectorizer.fit_transform(corpus))
print tfidf
用scikit-learn进行TF-IDF预处理
输出格式: (文档id,全局词id,tfidf权重)

2.5 VSM的评价
优点:
简单易用
缺点:
-
维数灾难现象
在大数据环境下,高维的特征对于深层语义表示而言,其计算复杂度是难以接受的。 -
词汇鸿沟现象
one-hot:

显然,二者是正交的, s i m ( s t a r , s u n ) = 0 sim(star,sun)=0 sim(star,sun)=0,任意两个词之间都是孤立的,丢失了词之间语义关联关系的信息,所以提出了基于矩阵的文本表示方法 。
3. 基于矩阵的文本表示方法
1954年,Harris最早提出了词语义的分布假说
(distributional hypothesis),他认为:“具有相似上下
文的词语也具有相似的语义” 。奠定了词语分布式语义表示(distributional semantic representation) 的理论基础。现在,在此基础上,主要分为基于矩阵的表示和基于神经网络的表示两种类型。
Count-based distributional representation (基于分布式表示)

上下文信息嵌入到了词向量表示中(词嵌入,word embedding)
每个词都在一个低维空间中表示为一个稠密、实值的向量。
3.1 基于矩阵
基于矩阵的文本深层表示以“词-上下文”矩阵为核心,需要构建一个“词-上下文”矩阵,从矩阵中获取词的表示。
在“词-上下文”矩阵中,每行对应一个词,每列表示一种不同的上下文,矩阵分量表示对应的上下文对该词影响的权重。
- 例一:以词共现作为权重为例
I love monkeys.
Apes and monkeys love bananas
窗口值设为2
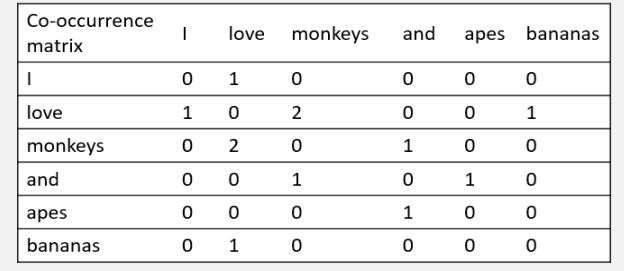
在这种表示下,矩阵中的一行,就成为了对应词的表示,这种表示描述了该词的上下文的分布。比如此时的bananas的词向量就是[0 1 0 0 0 0]
- 例二:文档级上下文
D1, I love monkeys.
D2, Apes and monkeys love bananas

此时的bananas的词向量就是[0, 1]
一般来说,对于上下文的选择可分为:
-
文档级,将该词出现的整个文档作为上下文
-
词窗口级,将该词上下文中选取长度固定的词窗口内的词作为上下文
-
n-gram窗口级,将该词上下文首先表示为ngram模型,之后再选取长度固定的词窗口内的ngram 词组作为上下文
相对而言,词窗口级因具有较低的稀疏性以及保留了词序信息,从而使词语义的建模精度达到最高。
3.2 奇异值分解(SVD分解)
当数据量较大时,构建得到的“词-上下文”矩阵维度较高,通常还需要进行矩阵分解以便降低维度。常用矩阵分解方法主要有奇异值分解等。
文档级一般使用较多,但是当数据量很大时,构建得到的“词-上下文”矩阵维度
较高,通常还需要进行矩阵分解以便降低维度。常用矩阵分解方法主要有奇异值分解等。
潜在语义分析(Latent semantic analysis, LSA)
主成分分析 (Principal Component Analysis, PCA)
指通过对大量的文本集进行统计分析,从中提取出词语的上下文使用含义。技术上通过奇异值分解SVD分解等处理,消除了同义词、多义词的影响,提高了后续处理的精度。
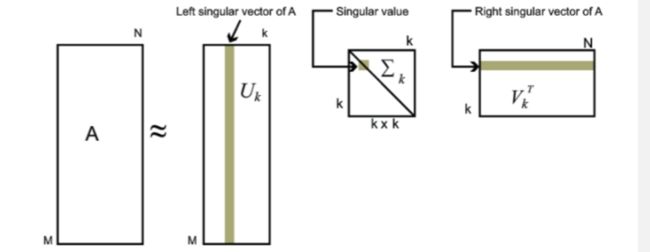
A ≈ U Σ V T (7) \large \mathbf{A} \approx \mathbf{U} \mathbf{\Sigma} \mathbf{V}^{\mathbf{T}} \tag{7} A≈UΣVT(7)
输入有m个词,对应n个文本。而Aij则对应第i个词在第j个文本的特征值(共现频率、 TF-IDF值)。
引入一个中间变量,称之为主题。k是我们假设的主题数,一般要比文本数少。SVD分解后:
- U i l U_{il} Uil对应第i个词和第l个主题的相关度
- Σ l m Σ_{lm} Σlm对应第l个主题和第m个主题的相关度
- V j m V_{jm} Vjm对应第j个文本和第m个主题的相关度
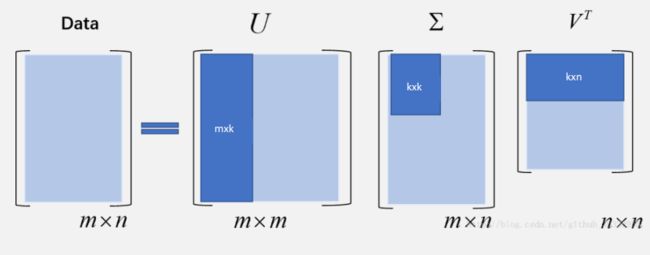
待分解矩阵 A : m × n A:m×n A:m×n
U : m × m U:m×m U:m×m:由左奇异向量组成
Σ : m × n Σ:m×n Σ:m×n:主对角线为奇异值,其他为0
V : n × n V:n×n V:n×n:由右奇异向量组成
U和V均为酉矩阵( U T U = I , V T V = I U^TU=I,V^TV=I UTU=I,VTV=I)
怎么得到?
用n×n的方阵 A T A A^TA ATA做特征值分解,得到n个特征值和特征向量v,作为右奇异向量,得到右侧的V矩阵: ( A T A ) v i = λ i v i ( A ^ { T } A ) v _ { i } = \lambda_ { i } v _ { i } (ATA)vi=λivi
用m×m的方阵 A A T A A^{T} AAT做特征值分解,得到m个特征值和特征向量u,作为左奇异向量,得到左侧的U矩阵 : ( A A T ) u i = λ i u i \left(A A^{T}\right) u_{i}=\lambda_{i} u_{i} (AAT)ui=λiui
流程:
(1)分析文档集合,建立词汇-文本矩阵A。
(2)对词汇-文本矩阵进行奇异值分解。
(3)对SVD分解后的矩阵进行降维
(4)使用降维后的矩阵构建潜在语义空间
从此模型开始,模型进入了不可解释的阶段,但是因为表示效果很好,所以继续使用
3.3 评价
优点:
1)可以刻画同义词;
2)无监督/完全自动化。
缺点:
1)无法解决一词多义问题;
2)高维度矩阵做奇异值分解是非常耗时;
3)特征向量没有对应的物理解释