Controllable Multi-Interest Framework for Recommendation 论文阅读笔记
1. ABSTRACT
1.1 e-commerce recommender systems
近年来,由于深度学习的快速发展,神经网络在电子商务推荐系统中得到了广泛的应用,并且将推荐系统形式化为一个顺序推荐问题,并打算预测用户可能被交互的下一个项目。
Recently, neural networks have been widely used in e-commerce recommender systems, owing to the rapid development of deep learning. We formalize the recommender system as a sequential recommendation problem, intending to predict the next items that the user might be interacted with.
1.2 Disadvantages that exist
之前的工作都基本是根据用户的行为序列中给出一个单一的会话嵌入,这并不能反应用户在一段时期内的多重兴趣。
Recent works usually give an overall embedding from a user’s behavior sequence. However, a unified user embedding cannot reflect the user’s multiple interests during a period.
1.3 The paper was presented
(1)提出了一个新的可控多兴趣框架的顺序推荐,称为ComiRec;
(2)多兴趣模块:从用户行为序列中捕获多个兴趣;
(3)聚合模块:将项目输入其中获得总体建议,利用一个可控的因素来平衡推荐的准确性和多样性。
we propose a novel co ntrollable multi-i nterest framework for the sequential rec ommendation, called ComiRec.multi-interest moduleaggregation module
1.4 Deployed
(1)在亚马逊和淘宝数据集上得到了比最先进的模型更好的效果;
(2)该框架也已成功部署在阿里巴巴分布式云平台上。
We conduct experiments for the sequential recommendation on two real-world datasets,Amazon and Taobao. Experimental results demonstrate that our framework achieves significant improvements over state-of-the-art models . Our framework has also been successfully deployed on the offline Alibaba distributed cloud platform.
2. INTRODUCTION
2.1 An example of a multi-interest extraction module
电子商务平台的用户艾玛有多种兴趣,包括珠宝、手袋和化妆品。

(1)多兴趣提取模块可以从她的点击序列中捕获这三个兴趣;
(2)每个兴趣基于兴趣嵌入独立地从大规模项目池中检索项目;
(3)一个聚合模块组合了来自不同兴趣的项目;
(4)输出Emma的前n推荐项目。
2.2 Major contributions to the paper
(1)提出了一个集成可控性和多兴趣模块在一个推荐系统的全面的框架;
(2)通过一个在线推荐场景来研究可控性在个性化系统中的作用;
(3)在两个真实世界的具有挑战性的数据集上获得了state-of-the-art performance。
propose a comprehensive framework that integrates the controllability and multi-interest components in a unified recommender system.investigate the role of controllability on personalized systems by implementing and studying in an online recommendation scenario.framework achieves state-of-the-art performance on two real-world challenging datasets for the sequential recommendation.
3. RELATED WORK
3.1 Neural Recommender Systems
(1)NCF:使用神经网络架构来建模用户和项目的潜在特征;
(2)NFM:在建模二阶特征交互时,无缝地结合了FMs的线性度和建模高阶特征时神经网络的非线性交互;
(3)DeepFM:设计了一个端到端学习模型,同时强调低阶和高阶的特征交互作用;
(4)xDeepFM:扩展了DeepFM,可以明确地学习特定的有界度特征交互;
(5) DMF:训练一个基于显式评级和非偏好隐式反馈的用户和项目表示的公共低维空间;
(6)DCN:引入了一种新的交叉网络,在学习特定的有界度特征交互方面更有效;
(7)CMN:使用深度架构统一CF模型,利用潜在因子模型的全局结构的优势和非线性的基于邻域的结构的优势,以非线性方式统一两类CF模型。
3.2 Sequential Recommendation
(1)FPMC:包含了一个公共马尔可夫链和正规矩阵分解模型;
(2)HRM:扩展了FPMC模型,并使用了一个两层结构来构建一个来自最后一个事务的用户和项目的混合表示;
(3)GRU4Rec:基于RNN的方法来对整个会话进行建模;
(4)DREAM:基于递归神经网络(RNN)的学习用户的动态表示;
(5)Fossil:将基于相似性的方法与马尔可夫链平滑地集成;
(6)TransRec:将项目嵌入到一个向量空间中;
(7)RUM:使用了一个记忆增强的神经网络,并集成了协同过滤的建议;
(8)SASRec:使用一个基于自我注意力的顺序模型来捕捉长期语义,并使用注意力机制,在相对较少的行动基础上进行预测;
(9)DIN:设计了一个本地激活单元,自适应地从一个特定广告的过去行为中学习用户兴趣的表示;
(10)SDM:用多头自我注意模块编码行为序列以捕获多种类型的兴趣,用长期-短期门控融合模块包含长期偏好。
3.3 Recommendation Diversity
(1)聚合多样性:向用户推荐“长尾项目”的能力;
(2)许多研究集中于改善推荐系统的聚合多样性;
(3)其他的工作关注于推荐给个体用户的项目的多样性。
3.4 Attention
(1)最开始出现在计算机视觉领域;
(2)在自然语言处理方面取得了巨大的成功;
(3)同样也适用于推荐系统,在实际推荐任务中相当有用。
3.5 Capsule Network
(1)MIND:将胶囊引入推荐区域,利用胶囊网络基于动态路由机制捕获电子商务用户的多种兴趣。
(2)CARP :首先从用户和项目评审文档中提取观点和方面,并根据每个逻辑单元的组成观点和方面得到每个逻辑单元的表示,用于评级预测。
4. Paper core method

论文对MIND多行为召回进行了扩展,一方面改进了MIND中的动态路由算法(Comirec-DR),另一方面提出了一种新的多兴趣召回方法(Comirec-SA)。
4.1 Symbolic representation

4.2 Comirec-DR
4.3.1 Dynamic Routing算法流程

4.3.2 算法流程解释
(1)输入:序列{![]() }
}
(2)输出:多兴趣{![]() }
}
(3)1:对输入序列胶囊 与所产生的兴趣胶囊
与所产生的兴趣胶囊 的权重
的权重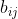 初始化为0
初始化为0
(4)2:开始循环,生成多个兴趣表征
(5)3:对每一个序列胶囊对应的所有兴趣胶囊的权重{![]() }进行Softmax归一化
}进行Softmax归一化
(6)4:对每个兴趣胶囊对应所有的序列胶囊执行以下公式:
![]()
(7)5:将得到的兴趣胶囊的表征通过squash激活函数:
![]()
(8)6:权重更新:
![]()
(9)7:得到最后的多兴趣推荐的项目
4.3.3 Comirec-DR与MIND的异同 
4.3 Comirec-SA
基于Attention的多兴趣建模方法
4.3.1 基于Attention的单一兴趣建模
![]()
4.3.2 基于Attention的多兴趣建模
(1)将![]() 扩充至
扩充至![]()
![]()
(2)通过以下公式得到用户的多兴趣表征
![]()
4.3.3 Model Training
(1)获取用户对应的推荐:
![]()
(2)目标函数:
![]()
![]()
4.3.3 多样性控制(Aggregation Module)
(1)每个兴趣嵌入都可以根据内部生产的接近程度独立地检索前n个项目,将这些来自不同兴趣的项目聚合起来,以获得整体的顶级项目。
![]()
(2)通过以下公式来衡量两个![]() 和
和![]() 之间的多样性,如果两个item的类别不相同,那么其结果就是1,反之就是0:
之间的多样性,如果两个item的类别不相同,那么其结果就是1,反之就是0:
![]()
(3)目标函数衡量我们推荐的结果:
![]()
(4)优化方式流程:

4.4 Connections with Existing Models
(1)MIMN
(2)MIND
5. EXPERIMENTS
5.1 Datasets

5.2 Competitors
| 模型 |
|
MostPopular
|
|
YouTube DNN
|
|
GRU4Rec
|
|
MIND
|
5.2 Evaluation Metrics
5.2.1 Recall

5.2.2 Hit Rate
![]()
5.2.3 Normalized Discounted Cumulative Gain

5.3 Controllable Study
5.3.1 Dataset

5.3.2 Evaluation Metrics

6. The Comirec model definition
6.1 Comirec-DR
基于paddle的Comirec-DR模型定义(飞桨AI Studio - 人工智能学习实训社区 (baidu.com))
class CapsuleNetwork(nn.Layer):
def __init__(self, hidden_size, seq_len, bilinear_type=2, interest_num=4, routing_times=3, hard_readout=True,
relu_layer=False):
super(CapsuleNetwork, self).__init__()
self.hidden_size = hidden_size # h
self.seq_len = seq_len # s
self.bilinear_type = bilinear_type
self.interest_num = interest_num
self.routing_times = routing_times
self.hard_readout = hard_readout
self.relu_layer = relu_layer
self.stop_grad = True
self.relu = nn.Sequential(
nn.Linear(self.hidden_size, self.hidden_size, bias_attr=False),
nn.ReLU()
)
if self.bilinear_type == 0: # MIND
self.linear = nn.Linear(self.hidden_size, self.hidden_size, bias_attr=False)
elif self.bilinear_type == 1:
self.linear = nn.Linear(self.hidden_size, self.hidden_size * self.interest_num, bias_attr=False)
else: # ComiRec_DR
self.w = self.create_parameter(
shape=[1, self.seq_len, self.interest_num * self.hidden_size, self.hidden_size])
def forward(self, item_eb, mask):
if self.bilinear_type == 0: # MIND
item_eb_hat = self.linear(item_eb) # [b, s, h]
item_eb_hat = paddle.repeat_interleave(item_eb_hat, self.interest_num, 2) # [b, s, h*in]
elif self.bilinear_type == 1:
item_eb_hat = self.linear(item_eb)
else: # ComiRec_DR
u = paddle.unsqueeze(item_eb, 2) # shape=(batch_size, maxlen, 1, embedding_dim)
item_eb_hat = paddle.sum(self.w[:, :self.seq_len, :, :] * u,
3) # shape=(batch_size, maxlen, hidden_size*interest_num)
item_eb_hat = paddle.reshape(item_eb_hat, (-1, self.seq_len, self.interest_num, self.hidden_size))
item_eb_hat = paddle.transpose(item_eb_hat, perm=[0,2,1,3])
# item_eb_hat = paddle.reshape(item_eb_hat, (-1, self.interest_num, self.seq_len, self.hidden_size))
# [b, in, s, h]
if self.stop_grad: # 截断反向传播,item_emb_hat不计入梯度计算中
item_eb_hat_iter = item_eb_hat.detach()
else:
item_eb_hat_iter = item_eb_hat
# b的shape=(b, in, s)
if self.bilinear_type > 0: # b初始化为0(一般的胶囊网络算法)
capsule_weight = paddle.zeros((item_eb_hat.shape[0], self.interest_num, self.seq_len))
else: # MIND使用高斯分布随机初始化b
capsule_weight = paddle.randn((item_eb_hat.shape[0], self.interest_num, self.seq_len))
for i in range(self.routing_times): # 动态路由传播3次
atten_mask = paddle.repeat_interleave(paddle.unsqueeze(mask, 1), self.interest_num, 1) # [b, in, s]
paddings = paddle.zeros_like(atten_mask)
# 计算c,进行mask,最后shape=[b, in, 1, s]
capsule_softmax_weight = F.softmax(capsule_weight, axis=-1)
capsule_softmax_weight = paddle.where(atten_mask==0, paddings, capsule_softmax_weight) # mask
capsule_softmax_weight = paddle.unsqueeze(capsule_softmax_weight, 2)
if i < 2:
# s=c*u_hat , (batch_size, interest_num, 1, seq_len) * (batch_size, interest_num, seq_len, hidden_size)
interest_capsule = paddle.matmul(capsule_softmax_weight,
item_eb_hat_iter) # shape=(batch_size, interest_num, 1, hidden_size)
cap_norm = paddle.sum(paddle.square(interest_capsule), -1, keepdim=True) # shape=(batch_size, interest_num, 1, 1)
scalar_factor = cap_norm / (1 + cap_norm) / paddle.sqrt(cap_norm + 1e-9) # shape同上
interest_capsule = scalar_factor * interest_capsule # squash(s)->v,shape=(batch_size, interest_num, 1, hidden_size)
# 更新b
delta_weight = paddle.matmul(item_eb_hat_iter, # shape=(batch_size, interest_num, seq_len, hidden_size)
paddle.transpose(interest_capsule, perm=[0,1,3,2])
# shape=(batch_size, interest_num, hidden_size, 1)
) # u_hat*v, shape=(batch_size, interest_num, seq_len, 1)
delta_weight = paddle.reshape(delta_weight, (
-1, self.interest_num, self.seq_len)) # shape=(batch_size, interest_num, seq_len)
capsule_weight = capsule_weight + delta_weight # 更新b
else:
interest_capsule = paddle.matmul(capsule_softmax_weight, item_eb_hat)
cap_norm = paddle.sum(paddle.square(interest_capsule), -1, keepdim=True)
scalar_factor = cap_norm / (1 + cap_norm) / paddle.sqrt(cap_norm + 1e-9)
interest_capsule = scalar_factor * interest_capsule
interest_capsule = paddle.reshape(interest_capsule, (-1, self.interest_num, self.hidden_size))
if self.relu_layer: # MIND模型使用book数据库时,使用relu_layer
interest_capsule = self.relu(interest_capsule)
return interest_capsuleclass ComirecDR(nn.Layer):
def __init__(self, config):
super(ComirecDR, self).__init__()
self.config = config
self.embedding_dim = self.config['embedding_dim']
self.max_length = self.config['max_length']
self.n_items = self.config['n_items']
self.item_emb = nn.Embedding(self.n_items, self.embedding_dim, padding_idx=0)
self.capsule = CapsuleNetwork(self.embedding_dim, self.max_length, bilinear_type=2,
interest_num=self.config['K'])
self.loss_fun = nn.CrossEntropyLoss()
self.reset_parameters()
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
def output_items(self):
return self.item_emb.weight
def reset_parameters(self, initializer=None):
for weight in self.parameters():
paddle.nn.initializer.KaimingNormal(weight)
def forward(self, item_seq, mask, item, train=True):
if train:
seq_emb = self.item_emb(item_seq) # Batch,Seq,Emb
item_e = self.item_emb(item).squeeze(1)
multi_interest_emb = self.capsule(seq_emb, mask) # Batch,K,Emb
cos_res = paddle.bmm(multi_interest_emb, item_e.squeeze(1).unsqueeze(-1))
k_index = paddle.argmax(cos_res, axis=1)
best_interest_emb = paddle.rand((multi_interest_emb.shape[0], multi_interest_emb.shape[2]))
for k in range(multi_interest_emb.shape[0]):
best_interest_emb[k, :] = multi_interest_emb[k, k_index[k], :]
loss = self.calculate_loss(best_interest_emb,item)
output_dict = {
'user_emb': multi_interest_emb,
'loss': loss,
}
else:
seq_emb = self.item_emb(item_seq) # Batch,Seq,Emb
multi_interest_emb = self.capsule(seq_emb, mask) # Batch,K,Emb
output_dict = {
'user_emb': multi_interest_emb,
}
return output_dict6.2 Comirec-SA
基于paddle的Comirec-SA模型定义(飞桨AI Studio - 人工智能学习实训社区 (baidu.com))
class MultiInterest_SA(nn.Layer):
def __init__(self, embedding_dim, interest_num, d=None):
super(MultiInterest_SA, self).__init__()
self.embedding_dim = embedding_dim
self.interest_num = interest_num
if d == None:
self.d = self.embedding_dim*4
self.W1 = self.create_parameter(shape=[self.embedding_dim, self.d])
self.W2 = self.create_parameter(shape=[self.d, self.interest_num])
def forward(self, seq_emb, mask = None):
'''
seq_emb : batch,seq,emb
mask : batch,seq,1
'''
H = paddle.einsum('bse, ed -> bsd', seq_emb, self.W1).tanh()
mask = mask.unsqueeze(-1)
A = paddle.einsum('bsd, dk -> bsk', H, self.W2) + -1.e9 * (1 - mask)
A = F.softmax(A, axis=1)
A = paddle.transpose(A,perm=[0, 2, 1])
multi_interest_emb = paddle.matmul(A, seq_emb)
return multi_interest_embclass ComirecSA(nn.Layer):
def __init__(self, config):
super(ComirecSA, self).__init__()
self.config = config
self.embedding_dim = self.config['embedding_dim']
self.max_length = self.config['max_length']
self.n_items = self.config['n_items']
self.item_emb = nn.Embedding(self.n_items, self.embedding_dim, padding_idx=0)
self.multi_interest_layer = MultiInterest_SA(self.embedding_dim,interest_num=self.config['K'])
self.loss_fun = nn.CrossEntropyLoss()
self.reset_parameters()
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
def output_items(self):
return self.item_emb.weight
def reset_parameters(self, initializer=None):
for weight in self.parameters():
paddle.nn.initializer.KaimingNormal(weight)
def forward(self, item_seq, mask, item, train=True):
if train:
seq_emb = self.item_emb(item_seq) # Batch,Seq,Emb
item_e = self.item_emb(item).squeeze(1)
multi_interest_emb = self.multi_interest_layer(seq_emb, mask) # Batch,K,Emb
cos_res = paddle.bmm(multi_interest_emb, item_e.squeeze(1).unsqueeze(-1))
k_index = paddle.argmax(cos_res, axis=1)
best_interest_emb = paddle.rand((multi_interest_emb.shape[0], multi_interest_emb.shape[2]))
for k in range(multi_interest_emb.shape[0]):
best_interest_emb[k, :] = multi_interest_emb[k, k_index[k], :]
loss = self.calculate_loss(best_interest_emb,item)
output_dict = {
'user_emb': multi_interest_emb,
'loss': loss,
}
else:
seq_emb = self.item_emb(item_seq) # Batch,Seq,Emb
multi_interest_emb = self.multi_interest_layer(seq_emb, mask) # Batch,K,Emb
output_dict = {
'user_emb': multi_interest_emb,
}
return output_dict6.3 论文作者实现代码链接
Controllable Multi-Interest Framework for Recommendation
参考:Controllable Multi-Interest Framework for Recommendation
飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)