第03周:吴恩达机器学习课后编程题ex3神经网络——Python
1 Multi-class Classifification 多类分类
在本练习中,使用逻辑回归和神经网络识别手写数字(从 0 到 9)。在练习的第一部分,将扩展之前的逻辑回归实现并将其应用到 one-vs-all 分类。
1.1 Dataset数据集
ex3data1.mat 中为您提供了一个数据集,其中包含 5000 个手写数字的训练示例。2 .mat 格式意味着数据具有 以原生 Octave/MATLAB 矩阵格式保存,而不是文本 (ASCII) 格式,如 csv 文件。
因此,若将数据加载到python中,则需要用到工具SciPy。
from scipy.io import loadmat
data = loadmat('ex3data1.mat') #导入数据
print(data)打印出来的数据集:

再来看看输入与输出也就是x和y数组的维度
print(data['X'].shape,data['y'].shape)#看X和y矩阵的维度输出为:X是(5000,400),这说明数据集中共有5000个样本,手写数字的像素点有值为255,空白像素点的位置为0,每个样本都是20*20像素的灰度图像,从数据集输出可看出,每个样本在X中都是一行,形成5000*400的矩阵。而y则表示图像中表示的数字类(用1-10表示数字0-9)。
![]()
1.2 Visualizing the data
随机打印100个样本看看
def print100_image(X):
#从数据中所有行里随机选100个样本组成sample_X数列
sample_X = np.random.choice(np.arange(X.shape[0]),100)
sample_image = X[sample_X, :]#(100,400)
fig, ax_array = plt.subplots(nrows = 10, ncols = 10, sharex=True,sharey = True,figsize=(8,8))
#以10*10呈现
for row in range(10):
for column in range(10):
ax_array[row,column].matshow(sample_image[10*row+column].reshape((20,20)),cmap='gray_r')
plt.xticks([])
plt.yticks([])
plt.show() 1.3 Vectorizing Logistic Regression
1.3 Vectorizing Logistic Regression
- 在此问题中,还是会用到sigmoid函数
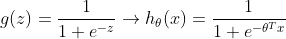
在程序中定义sigmoid函数
def sigmoid(x):
return 1/(1+np.exp(-x))同时定义代价函数
![J(\theta)=\frac{1}{m}\sum_{i=1}^{m}[-y^{(i)}log(h_\theta(x^{(i)}))-(1-y^{(i)})log(1-h_\theta(x^{(i)}))]+\frac{\lambda}{2m}\sum_{j=1}^n\theta_j^2](http://img.e-com-net.com/image/info8/049fca2b180547028ed01ed9eb18ac29.gif)
def cost(theta, X, y, learningRate):
#根据输入的参数值theta,数据X,标签y,以及正则化参数λ计算损失
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
#根据公式列出计算代价的函数(此时不含正则化部分)
pre_cost = np.multiply(-y,np.log(sigmoid(X * theta.T)))-np.multiply((1-y),np.log(1-sigmoid(X*theta.T)))
#继续计算代价函数正则化部分
reg = (learningRate/(2*len(X)))*np.sum(theta[1:],2)
#所以两个部分加起来就是代价函数
finished_cost = np.sum(pre_cost)/len(X) + reg用np.matrix()函数把变量变成numpy矩阵
- 正则化梯度下降

同上边的正则化代价函数类似,分成两部分定义
def reg_gradient(theta,X,y,Lambda):
thetaReg = theta[1:]
pre_gradient = (X.T*(sigmoid(X*theta)-y))/len(X)
#插入一维0,使得对θ_0不惩罚,便于计算
reg = np.concatenate([np.array([0]),(Lambda/len(X))*thetaReg])
return pre_gradient + reg1.4 One-vs-all Classifification
实现一对多分类通过训练多个正则化logistic回归分类器。现有10个可能的类(0-9),逻辑回归只能一次在2个类之间进行分类,每个分类器区分样本属于“类别 i”和“不是 i”。
from scipy.optimize import minimize
def one_vs_all(X,y,Lambda,num_label):#共有10个数字标签,所以num_label=10
all_theta = np.zeros((num_label,X.shape[1])+)
for i in range(1,num_label+1):
theta = np.zeros(X.shape[1]+1) #求Θi
yi = np.array([1 if label == i else 0 for label in y])
ret = minimize(fun = cost, x0=theta,args=(X,yi,1),method='TNC',jac=reg_gradient,options={'disp':True})
all_theta[i-1,:]=ret.x
return all_theta此时得出的θ的维度是10*401,每行分别一个表示判断数字的分类器,接着求出all_theta
all_theta = one_vs_all(data['X'], data['y'], 10, 1)
print(all_theta)即可得到对应的θ值
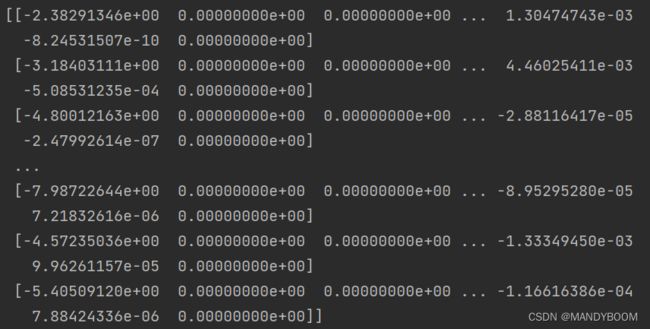
1.4.1 One-vs-all Prediction
最后预测每个图像的标签,取最终概率最高的类为输出标签
def predict_all(X, all_theta):
# 对测试数据进行预测
num_labels = all_theta.shape[0]
# 把矩阵X加入一行零元素
X = np.insert(X, 0, values=np.ones(X.shape[0]), axis=1)
# 将矩阵X和all_theta转换为numpy型矩阵
X = np.matrix(X)
all_theta = np.matrix(all_theta)
# 计算样本属于每一类的概率
h = sigmoid(X * all_theta.T)
# 找到每个样本中预测概率最大的值
h_max = np.argmax(h, axis=1)
# 数组是零索引的,所以+1才是真正的标签
h_max = h_max + 1
return h_max调用预定义的预测函数
prediction=predict_all(data['X'],all_theta) #返回的预测值n*1的向量 #返回的预测值n*1的向量
correct = [1 if a == b else 0 for (a, b) in zip(prediction, data['y'])] # 判断预测值和标签是否相同
accuracy = (sum(map(int, correct)) / float(len(correct))) # 计算预测正确率,就是correct中1的个数
print('accuracy = {0}%'.format(accuracy * 100))得到最终accuracy=94.46%