推荐系统(7):推荐算法之基于协同过滤推荐算法
目录
0. 相关文章链接
1. 协同过滤的算法思想
1.1. 基于内容的推荐中不足之处
1.2. 协同过滤算法思想推导
1.3. 使用协同过滤算法的步骤
1.4. 使用协同过滤算法中需要注意的点
2. 协同过滤的推荐方法
3. 基于近邻的协同过滤
3.1. 什么是基于近邻的协同过滤
3.2. 基于用户的CF
3.3. 基于物品的CF
3.4. UserCF和ItemCF的对比
4. 基于模型的协同过滤
4.1. 什么是基于模型的协同过滤
4.2. 基于模型的协同过滤思想
4.3. LFM隐语义模型
4.3.1. LFM的主要应用方面
4.3.2. 什么是隐语义模型(LFM)
4.3.3. 隐语义模型的核心思想
4.4. ALS矩阵分解模型
4.4.1. 什么是矩阵分解
4.4.2. LFM的进一步理解
4.4.3. 矩阵因子分解概述
4.4.4. 交替最小二乘法(ALS)
5. 协同过滤算法的优缺点
0. 相关文章链接
推荐系统文章汇总
1. 协同过滤的算法思想
1.1. 基于内容的推荐中不足之处
基于内容的推荐方法用户易于理解,简单有效,但是它的缺点也十分明显。
- 它要求内容必须能够抽取出有意义的特征,且要求这些特征内容有良好的结构性
- 推荐精度较低,相同内容特征的物品差异性不大。因为以上这些原因,在推荐系统中基于内容的推荐往往会和其他方法混合使用。
1.2. 协同过滤算法思想推导
比如你想看一个电影,但是不知道具体看哪一部,你会怎么做?
- 问问周围兴趣相似的朋友,看看他们最近有什么好的电影推荐。(基于用户)
- 看看电影的相似程度,比如都喜欢看僵尸片,那就会找电影名带有僵尸、丧尸之类的电影。(基于物品)
比如到玩具店去给小男孩选玩具,应该怎么选?
- 我看到大部分小男孩都在玩变形金刚,给他买个变形金刚怎么样?(基于用户)
- 我知道这个小男孩有很多乐高模型,给他买一个最新版的乐高模型怎么样?(基于物品)
由此可以推导出协同过滤算法思想,如下所示:
- 协同过滤算法就是基于上面的思想,主要包含基于用户的协同过滤推荐算法以及基于物品的协同过滤推荐算法。
- 基于物品的协同过滤算法的核心思想:给用户推荐那些和他们之前喜欢的物品相似的物品,用户U 购买了A 物品,推荐给用户U 和A 相似的物品B /C /D
- 基于用户的协同过滤算法的核心思想:是先计算用户U 与其他的用户的相似度,然后取和U 最相似的几个用户,把他们购买过的物品推荐给用户U
1.3. 使用协同过滤算法的步骤
- 收集用户偏好。
- 找到相似的用户或者物品。
- 计算推荐。
- 评估
1.4. 使用协同过滤算法中需要注意的点
这里的基于物品的协同过滤和之前的基于内容的推荐算法不一样,基于内容的推荐算法仅仅考虑物品的内容特征,而协同过滤包括物品+用户
这里的基于用户的协同过滤和之前的基于人口统计学推荐算法不一样,基于人口统计学推荐算法考虑的是用户的基本属性(用户画像),基于用户的协同过滤考虑的是用户的对于物品的评价(喜好)
协同:用户与用户之间、用户和网站之间等进行不断的互动,慢慢过滤掉自己不感兴趣的物品,从而满足自己的需求。
2. 协同过滤的推荐方法
协同过滤和基于内容这2种方法对比:
- 基于内容(Content based,CB)主要利用的是用户评价过的物品的内容特征,而基于协同过滤(Collaboraitive Filtering,CF)方法还可以利用其他用户评分过的物品内容
- CF可以解决CB的一些局限
- 物品内容不完全或者难以获得时,依然可以通过其他用户的反馈给出推荐
- CF基于用户之间对物品的评价质量,避免了CB仅依赖内容可能造成的对物品质量判断的干扰
- CF推荐不受内容限制,只要其他类似用户给出了对不同物品的兴趣,CF就可以给用户推荐出内容差异很大的物品(但有某种内在联系)
协同过滤的方法分类:
- 基于近邻的协同过滤:
- 基于用户(User-CF)
- 基于物品(Item-CF)
- 基于模型的协同过滤:
- 奇异值分解(SVD)
- 潜在语义分析(LSA)
- 支持向量机(SVM)
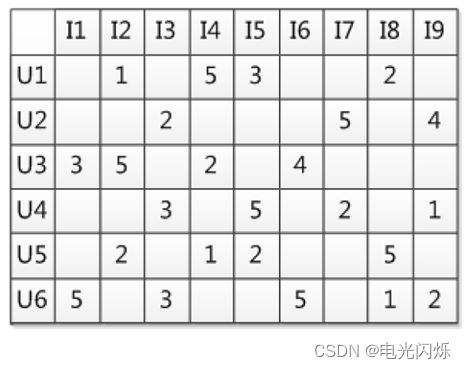
3. 基于近邻的协同过滤
3.1. 什么是基于近邻的协同过滤
- 基于用户的协同过滤(UserCF):给用户推荐和用户相似的其他用户喜欢的东西。
- 基于物品的协同过滤(ItemCF):给用户推荐和用户喜欢的东西相似的其他东西。
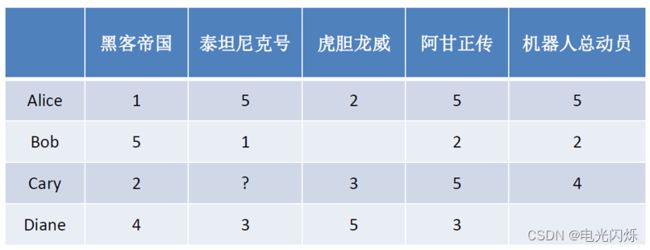
- 基于近邻的推荐系统根据的是相同 “口碑” 准则,如下所示,是否应该给Cary推荐《泰坦尼克号》?答案是肯定的
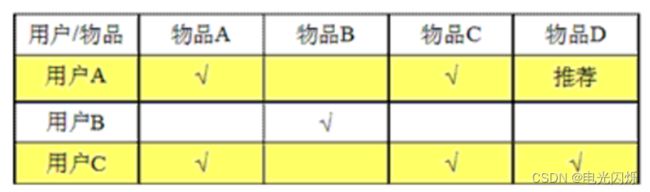
3.2. 基于用户的CF
用户A喜欢的物品用户C都喜欢,我们认为用户A与用户C相似,
那么用户C喜欢的东西可能用户A也喜欢,因此将用户C喜欢的物品推荐给用户A。
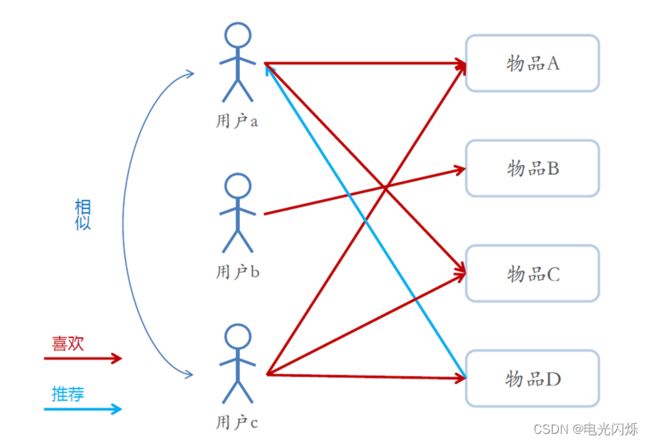
思想总结如下:
- 基于用户的协同过滤推荐的基本原理是,根据所有用户对物品的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,并推荐近邻所偏好的物品
- 在一般的应用中是采用计算“K-近邻”的算法;基于这 K 个邻居的历史偏好信息,为当前用户进行推荐
- User-CF和基于人口统计学的推荐机制
- 两者都是计算用户的相似度,并基于相似的“邻居”用户群计算推荐
- 它们所不同的是如何计算用户的相似度:基于人口统计学的机制只考虑用户本身的特征,而基于用户的协同过滤机制可是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好
模型核心算法伪代码表示如下:

基于该核心算法,完成用户商品矩阵:
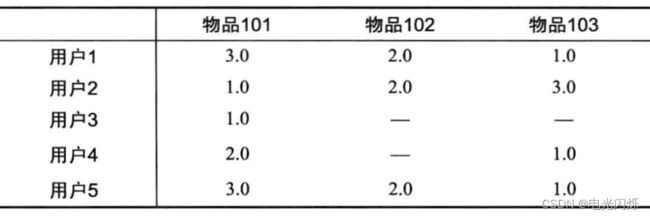
预测用户对于未评分的物品的分值,然后按照降序排序,进行推荐。
3.3. 基于物品的CF
喜欢物品A的用户都喜欢物品C,那么我们认为物品A与物品C相似,
那么喜欢物品A的用户也可能会喜欢物品C,因此,将物品C推荐给喜欢物品A的用户。
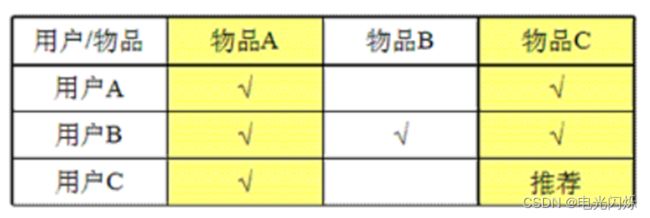
思想总结如下:
- 基于项目的协同过滤推荐的基本原理与基于用户的类似,只是使用所有用户对物品的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户
- Item-CF和基于内容(CB)的推荐
- 其实都是基于物品相似度预测推荐,只是相似度计算的方法不一样,前者是从用户历史的偏好推断,而后者是基于物品本身的属性特征信息
- 同样是协同过滤,在基于用户和基于项目两个策略中应该如何选择呢?
- 电商、电影、音乐网站,用户数t远大于物品数量
- 新闻网沾,物品(新闻文本)数员可能大于用户数量
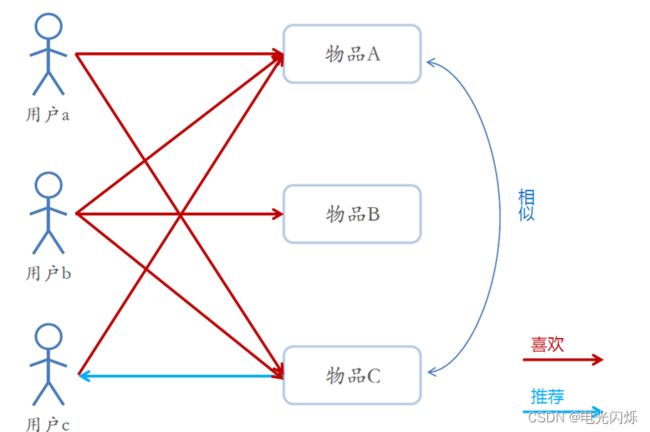
先计算出物品-物品的相似矩阵:

基于上面的结果:

给用户推送预测偏好值n个最高的物品。
3.4. UserCF和ItemCF的对比
基于用户的协同过滤(UserCF) 和基于物品协同( itemCF) 在算法上十分类似,推荐系统选择哪种算法,主要取决于推荐系统的考量指标。两者主要的优缺点总结如下。
1)从推荐的场景考虑:
Item CF 是利用物品间的相似性来推荐的,所以假如用户的数量远远超过物品的数量,那么可以考虑使用Item CF ,比如购物网站,因其物品的数据相对稳定,因此计算物品的相似度时不但计算量较小,而且不必频繁更新;
UserCF 更适合做新闻、博客或者微内容的推荐系统,因为其内容更新频率非常高,特别是在社交网络中, UserCF 是一个更好的选择,可以增加用户对推荐解释的信服程度。
而在一个非社交网络的网站中,比如给某个用户推荐一本书, 系统给出的解释是某某和你有相似兴趣的人也看了这本书, 这很难让用户信服,因为用户可能根本不认识那个人;但假如给出的理由是因为这本书和你以前看过的某本书相似,这样的解释相对合理,用户可能就会采纳你的推荐。UserCF 是推荐用户所在兴趣小组中的热点,更注重社会化, 而ItemCF 则是根据用户历史行为推荐相似物品,更注重个性化。所以UserCF 一般用在新闻类网站中,如Digg;而ItemCF 则用在其他非新闻类网站中,如Amazon 、hulu 等。因为在新闻类网站中,用户的兴趣爱好往往比较粗粒度,很少会有用户说只看某个话题的新闻,而且往往某个话题也不是每天都会有新闻。
个性化新闻推荐更强调新闻热点,热门程度和时效性是个性化新闻推荐的重点,个性化是补充,所以UserCF 给用户推荐和他有相同兴趣爱好的人关注的新闻,这样在保证了热点和时效性的同时,兼顾了个性化。另外一个原因是从技术上考虑的,作为一种物品,新闻的更新非常快,随时会有新的新闻出现,如果使用Item CF的话,需要维护一张物品之间相似度的表,实际工业界这张表一般是一天一更新,这在新闻领域是万万不能接受的。
但是,在图书、电子商务和电影网站等领域, ItemCF 则能更好地发挥作用。因为在这些网站中,用户的兴趣爱好一般是比较固定的,而且相比于新闻网站更加细腻。在这些网站中,个性化推荐一般是给用户推荐他自己领域的相关物品。另外,这些网站的物品数量更新速度不快,相似度表一天一次更新可以接受。而且在这些网站中,用户数量往往远远大于物品数量, 从存储的角度来讲,UserCF 需要消耗更大的空间复杂度,另外,ItemCF可以方便地提供推荐理由,增加用户对推荐系统的信任度,所以更适合这些网站。
2)系统的多样性
在系统的多样性(也被称为覆盖率,指一个推荐系统能否给用户提供多种选择〉指标下, Item CF 的多样性要远远好于UserCF ,因为UserCF 会更倾向于推荐热门的物品。也就是说, ItemCF 的推荐有很好的新颖性,容易发现并推荐长尾里的物品。所以大多数情况,ItemCF的精度稍微小于UserCF,但是如果考虑多样性, UserCF却比ItemCF要好很多。
由于UserCF 经常推荐热门物品,所以它在推荐长尾里的项目方面的能力不足;而Item CF只推荐A 领域给用户,这样它有限的推荐列表中就可能包含了一定数量的非热门的长尾物品。ItemCF 的推荐对单个用户而言,显然多样性不足,但是对整个系统而言,因为不同的用户的主要兴趣点不同,所以系统的覆盖率会比较好。
3)用户特点对推荐算法影响的比较
对于UserCF ,推荐的原则是假设用户会喜欢那些和他有相同喜好的用户喜欢的东西,但是假如用户暂时找不到兴趣相投的邻居,那么UserCF 的推荐效果就会大打折扣,因此用户是否适应UserCF 算法跟他有多少邻居是成正比关系的。
基于物品的协同过滤算法也是有一定前提的,即用户喜欢和他以前购买过的物品相同类型的物品,那么我们可以计算一个用户喜欢的物品的自相似度。一个用户喜欢物品的自相似度大,就说明他喜欢的东西都是比较相似的,即这个用户比较符合ItemCF 方法的基本假设,那么他对ItemCF 的适应度自然比较好,反之,如果自相似度小,就说明这个用户的喜好习惯并不满足ItemCF 方法的基本假设, 那么用ItemCF 方法所做出的推荐对于这种用户来说,其推荐效果可能不是很好。
User-CF和Item-CF的比较如下所示:



4. 基于模型的协同过滤
4.1. 什么是基于模型的协同过滤
基于模型的推荐又可以叫基于知识的推荐算法,模型是通过专家知识预先设定好的一些规则和计算公式,常常用于实时推荐,相比其他离线推荐算法可以缩短推荐实现,本项目中实时推荐算法通过根据具体业务构建了相应的推荐模型来实现推荐。

4.2. 基于模型的协同过滤思想

4.3. LFM隐语义模型
4.3.1. LFM的主要应用方面
LFM主要应用在两个方面:
- 一个是用户评分预测,
- 一个是物品隐类Top-N热门排行。
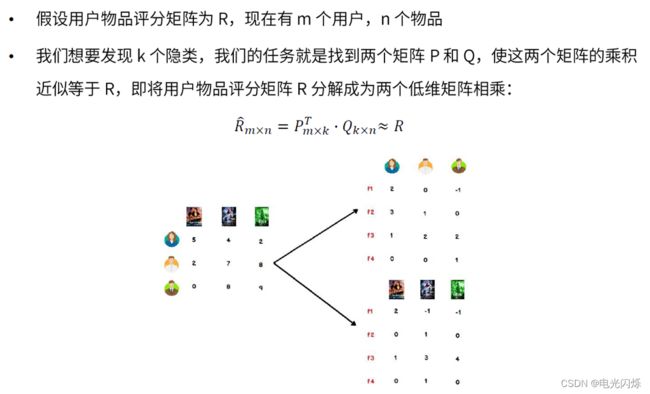
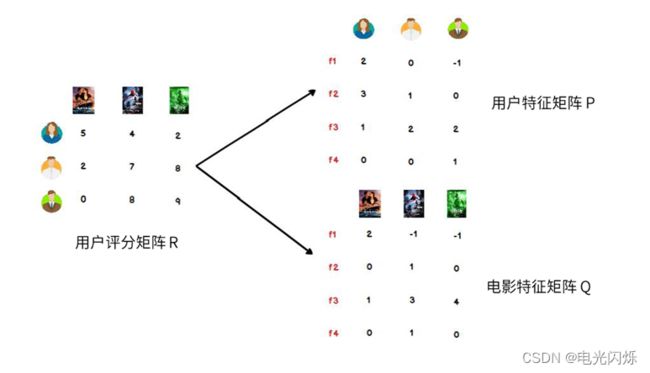
假设用户物品评分矩阵为R,现在有u个用户,i个物品,我们想要发现F个隐类,我们的任务就是找到两个矩阵U和V,使这两个矩阵的乘积近似等于R,即将用户物品评分矩阵R分解成为两个低维矩阵相乘:
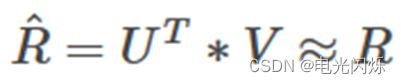
4.3.2. 什么是隐语义模型(LFM)

4.3.3. 隐语义模型的核心思想
案例如下:

上面提取出来特征是我们很容易看出来的,但是在实际中,用户和物品的很多特征是隐藏着的,我们很难直接看到,需要使用LFM隐语义模型来进行提取建模。
由此可以总结出隐语义模型的核心思想如下所示:
- 用户具有一定的特征,决定着他做出的选择。
- 物品具有一定的特征,影响着用户是否选择它。
- 用户之所以选择某一个商品,是因为用户特征与物品特征相互匹配。
4.4. ALS矩阵分解模型
4.4.1. 什么是矩阵分解
1)LFM降维方法-矩阵因子分解
2)矩阵因子分解详解(上)
3)矩阵因子分解详解(下)
4.4.2. LFM的进一步理解

4.4.3. 矩阵因子分解概述

在协同过滤推荐算法中,最主要的是产生用户对物品的打分,用户对物品的打分行为可以表示成一个评分矩阵A(m*n),表示m个用户对n各物品的打分情况。如下图所示:
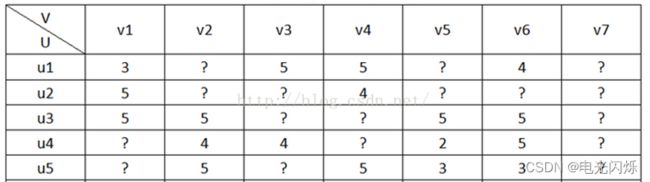
其中,A(i,j)表示用户user i对物品item j的打分。但是,用户不会对所有物品打分,图中?表示用户没有打分的情况,所以这个矩阵A很多元素都是空的,我们称其为“缺失值(missing value)”,是一个稀疏矩阵。在推荐系统中,我们希望得到用户对所有物品的打分情况,如果用户没有对一个物品打分,那么就需要预测用户是否会对该物品打分,以及会打多少分。这就是所谓的“矩阵补全(填空)”。
我们从另外一个层面考虑用户对物品的喜爱程序,而不是通过用户的推荐。用户之所以喜欢一个物品,绝大对数是因为这个物品的某些属性和这个用户的属性是一致或者是接近的,比如一个人总是具有爱国情怀或者侠义情怀,那么根据这些推断一定喜欢比如《射雕英雄传》、抗战剧等电视剧,因为这些电视剧所表达的正是侠义和爱国。可以设想用户拥有某些隐含的特征、物品也具有某种隐含的特征,如果这些特征都相似,那么很大程度上用户会喜欢这个物品。
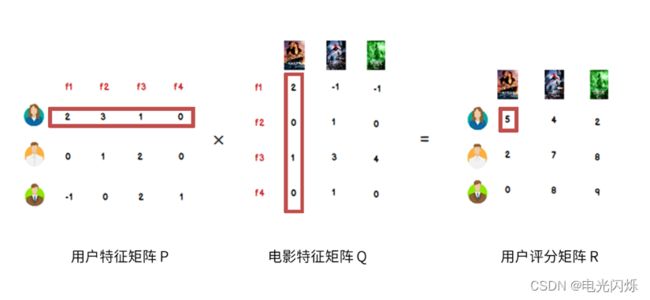
根据上面的假设,我们可以把评分矩阵表示成两个低纬度的矩阵相乘,如下:
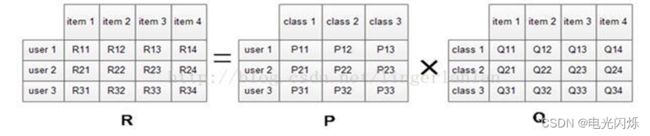
我们希望学习到一个P代表user的特征,Q代表item的特征。特征的每一个维度代表一个隐性因子,比如对电影来说,这些隐性因子可能是导演,演员等。当然,这些隐性因子是机器学习到的,具体是什么含义我们不确定。
ALS 的核心就是下面这个假设:打分矩阵A是近似低秩的。换句话说,一个  的打分矩阵A 可以用两个小矩阵
的打分矩阵A 可以用两个小矩阵 ![]() 和
和 ![]() 的乘机来近似:
的乘机来近似:![]() ,
,![]() 。这样我们就把整个系统的自由度从
。这样我们就把整个系统的自由度从![]() 一下降到了
一下降到了 ![]() 。一个人的喜好映射到了一个低维向量
。一个人的喜好映射到了一个低维向量![]() ,一个电影的特征变成了纬度相同的向量
,一个电影的特征变成了纬度相同的向量![]() ,那么这个人和这个电影的相似度就可以表述成这两个向量之间的内积
,那么这个人和这个电影的相似度就可以表述成这两个向量之间的内积![]() 。
。
我们把打分理解成相似度,那么“打分矩阵A(m*n)”就可以由“用户喜好特征矩阵U(m*k)”和“产品特征矩阵V(n*k)”的乘积 来近似了。这种方法被称为概率矩阵分解算法(probabilistic matrix factorization,PMF)。ALS算法是PMF在数值计算方面的应用。
4.4.4. 交替最小二乘法(ALS)
1)模型的求解—损失函数

2)模型的求解—ALS算法

3)模型的求解—梯度下降算法
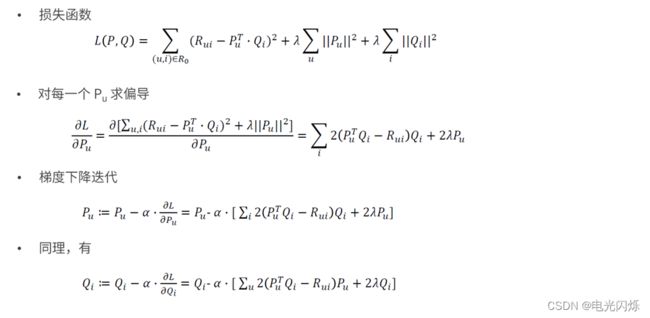
为了使低秩矩阵X和Y尽可能地逼近R,需要最小化下面的平方误差损失函数:
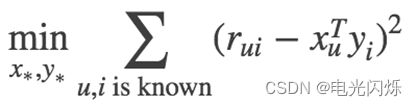
考虑到矩阵的稳定性问题,使用吉洪诺夫正则化Tikhonov regularization,则上式变为:
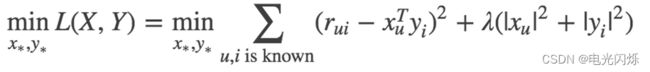
所以整个矩阵分解模型的损失函数为:
有了损失函数之后,下面就开始谈优化方法了,通常的优化方法分为两种:交叉最小二乘法(alternative least squares)和随机梯度下降法(stochastic gradient descent)。本次使用交叉最小二乘法(ALS)来最优化损失函数。算法的思想就是:我们先随机生成![]() 然后固定它求解
然后固定它求解 ![]() ,再固定
,再固定![]() 求解
求解![]() ,这样交替进行下去,直到取得最优解min(C)。因为每步迭代都会降低误差,并且误差是有下界的,所以ALS 一定会收敛。但由于问题是非凸的,ALS 并不保证会收敛到全局最优解。但在实际应用中,ALS 对初始点不是很敏感,是不是全局最优解造成的影响并不大。
,这样交替进行下去,直到取得最优解min(C)。因为每步迭代都会降低误差,并且误差是有下界的,所以ALS 一定会收敛。但由于问题是非凸的,ALS 并不保证会收敛到全局最优解。但在实际应用中,ALS 对初始点不是很敏感,是不是全局最优解造成的影响并不大。
算法的执行步骤:
- 第一步:先随机生成一个
 。一般可以取
。一般可以取 值或者全局均值。
值或者全局均值。 - 第二步:固定 (即:认为 是已知的常量),来求解
 。
。
此时,损失函数为:
由于C中只有Vj一个未知变量,因此C的最优化问题转化为最小二乘问题,用最小二乘法求解Vj的最优解:
固定j(j=1,2,......,n),则:C的导数
令
得到:
即:
令
则:
按照上式依次计算v1,v2,......,vn,从而得到
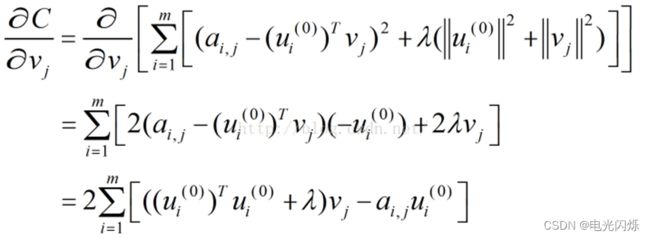

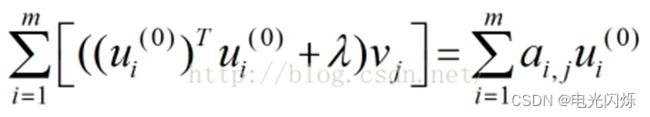
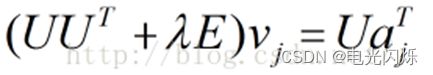
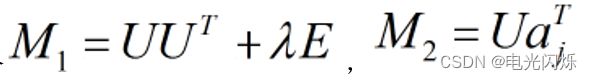

- 第三步:固定
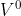 (即:认为 是已知的量),来求解
(即:认为 是已知的量),来求解 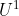 。
。
此时,损失函数为:
同理,用步骤2中类似的方法,可以计算ui的值:
令
得到:
即:
令
则:
依照上式依次计算u1,u2,......,um,从而得到
。
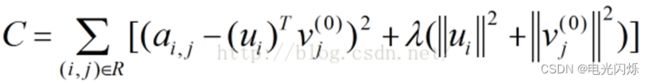
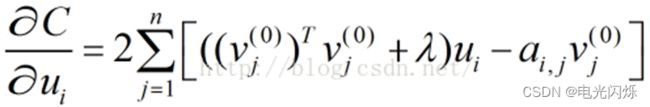

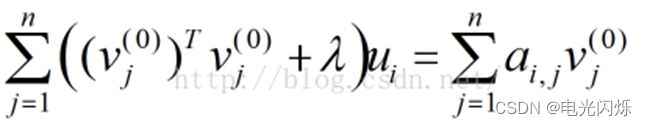
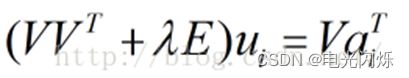
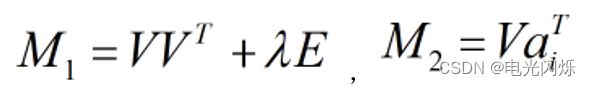

- 第四步:循环执行步骤2、3,直到损失函数C的值收敛(或者设置一个迭代次数N,迭代执行步骤2、3 N次后停止)。这样,就得到了C最优解对应的矩阵U、V。
5. 协同过滤算法的优缺点

注:其他推荐系统相关文章链接由此进 -> 推荐系统文章汇总