树莓派 神经网络植入
直觉 (Intuition)

Imagine you’re solving a Jigsaw puzzle. You have completed most of it. Suppose you need to fix a piece in the middle of a picture ( which is nearly complete ). You need a choose a piece from the box which would into a fit in the space and also complete the whole picture.
想象您正在解决拼图游戏。 您已经完成了大部分工作。 假设您需要在图片中间修复一块(几乎完成了)。 您需要从包装盒中选择一块,以适合该空间并完成整个图片。
I’m sure you can do this quickly. But how’s your brain doing this?
我确定您可以快速完成此操作。 但是你的大脑怎么样?
First, it analyses the picture around the empty slot ( where you need to fix a piece of the puzzle ). If there’s a tree in the picture, you’ll search for a green coloured piece ( which is obvious! ). So, in a nutshell, our brain is able to predict the piece ( which will fit into the slot ) by knowing the surrounding context of the image.
首先,它分析空白插槽(您需要修复其中的难题)周围的图片。 如果图片中有一棵树,您将搜索一块绿色的(这很明显!)。 因此,简而言之,我们的大脑就能通过了解图像的周围环境来预测片段(将适合插槽)。
Our model, in this tutorial, is going to perform a similar task. It will learn the image’s context and then predict a part of the image ( which is missing ) using this learned context.
在本教程中,我们的模型将执行类似的任务。 它将学习图像的上下文,然后使用此学习的上下文预测图像的一部分(丢失)。
代码实施 (Code Implementation)
I recommend you should open this notebook (the TF implementation) in another tab so that you have an intuition of what’s going on.
我建议您在另一个选项卡中打开此笔记本(TF实现),以便直观了解正在发生的事情。
问题陈述 (Problem Statement)
We’d like our model to predict a part of an image. Given an image with a hole (a part of the image array which contains only zeros), our model will predict the original image which is complete.
我们希望我们的模型能够预测图像的一部分。 给定一个带Kong的图像(图像数组的一部分仅包含零),我们的模型将预测完整的原始图像。
So our model will reconstruct the missing part of the image using the context it learned during training.
因此,我们的模型将使用在训练中学习到的上下文来重建图像的缺失部分。

数据 (The Data)
We’ll select a single domain for our task. We are choosing a number of mountain images that are a part of the Intel Image Classification dataset by Puneet Bansal on Kaggle.
我们将为任务选择一个域。 我们正在选择许多山峰图像,这些山峰图像是Kaggle上Puneet Bansal 撰写的“ 英特尔图像分类”数据集中的一部分。
Why only images of mountains?
为什么只有山的影像?
Here, we choose images which belong to a particular domain. If we choose a dataset which has in the wild images, our model will not perform well. Hence, we restrict it to a single domain.
在这里,我们选择属于特定域的图像。 如果我们选择包含野外图像的数据集,则我们的模型将无法正常运行。 因此,我们将其限制为单个域。

Download the data which I have hosted on GitHub using wget
使用wget下载我在GitHub上托管的数据
!wget https://github.com/shubham0204/Dataset_Archives/blob/master/mountain_images.zip?raw=true -O images.zip!unzip images.zipTo make our training data, we’ll iterate through each image in our dataset and perform the below tasks on it,
为了制作训练数据,我们将遍历数据集中的每个图像,并在其上执行以下任务,
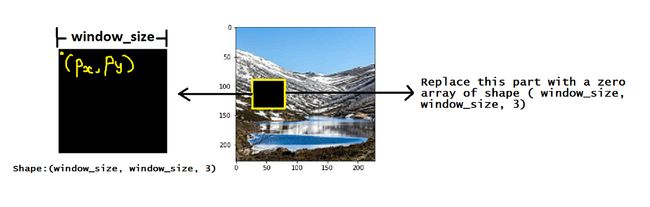
First, we’ll read our image file using
PIL.Image.open(). Convert thisImageobject to a NumPy array usingnp.asarray().首先,我们将使用
PIL.Image.open()读取图像文件。 使用np.asarray()将此Image对象转换为NumPy数组。- Determine a window size. This will be the side length of the square which we are going to take from the original image. 确定窗口大小。 这将是我们将从原始图像中获取的正方形的边长。
Generate 2 random numbers within the range
[ 0 , image_dim — window_size ]. Whereimage_dimis the size of our square input image.生成
[ 0 , image_dim — window_size ]范围内的2个随机数。 其中image_dim是正方形输入图像的大小。These two numbers (called
pxandpy) are the positions from where the original image will be cropped. Select the part of the image array and replace it with a zero array.这两个数字(称为
px和py)是裁剪原始图像的位置。 选择图像阵列的一部分,并将其替换为零阵列。
The code looks like this,
代码看起来像这样,
x = []
y = []
input_size = ( 228 , 228 , 3 )
# Take out a square region of side 50 px.
window_size = 50
# Store the original images as target images.
for name in os.listdir( 'mountain_images/' ):
image = Image.open( 'mountain_images/{}'.format( name ) ).resize( input_size[0:2] )
image = np.asarray( image ).astype( np.uint8 )
y.append( image )
for name in os.listdir( 'mountain_images/' ):
image = Image.open( 'mountain_images/{}'.format( name ) ).resize( input_size[0:2] )
image = np.asarray( image ).astype( np.uint8 )
# Generate random X and Y coordinates within the image bounds.
px , py = random.randint( 0 , input_size[0] - window_size ) , random.randint( 0 , input_size[0] - window_size )
# Take that part of the image and replace it with a zero array. This makes the "missing" part of the image.
image[ px : px + window_size , py : py + window_size , 0:3 ] = np.zeros( ( window_size , window_size , 3 ) )
# Append it to an array
x.append( image )
# Normalize the images
x = np.array( x ) / 255
y = np.array( y ) / 255
# Train test split
x_train, x_test, y_train, y_test = train_test_split( x , y , test_size=0.2 )具有跳过连接的自动编码器模型 (Auto Encoder model with skip connections)
We add skip connections to our autoencoder model. These skip connections provide better upsampling. By using max-pooling layers, much of the spatial information is lost as it goes down the encoder. In order to reconstruct the image from its latent representation ( produced by the encoder ), we add skip connections, which bring in information from the encoder to the decoder.
我们将跳跃连接添加到我们的自动编码器模型中。 这些跳过连接提供了更好的上采样。 通过使用最大池化层,许多空间信息在沿着编码器传输时会丢失。 为了从图像的潜在表示(由编码器生成)重建图像,我们添加了跳过连接,这些连接将信息从编码器引入解码器。
alpha = 0.2
inputs = Input( shape=input_size )
conv1 = Conv2D( 32 , kernel_size=( 3 , 3 ) , strides=1 )( inputs )
relu1 = LeakyReLU( alpha )( conv1 )
conv2 = Conv2D( 32 , kernel_size=( 3 , 3 ) , strides=1 )( relu1 )
relu2 = LeakyReLU( alpha )( conv2 )
maxpool1 = MaxPooling2D()( relu2 )
conv3 = Conv2D( 64 , kernel_size=( 3 , 3 ) , strides=1 )( maxpool1 )
relu3 = LeakyReLU( alpha )( conv3 )
conv4 = Conv2D( 64 , kernel_size=( 3 , 3 ) , strides=1 )( relu3 )
relu4 = LeakyReLU( alpha )( conv4 )
maxpool2 = MaxPooling2D()( relu4 )
conv5 = Conv2D( 128 , kernel_size=( 3 , 3 ) , strides=1 )( maxpool2 )
relu5 = LeakyReLU( alpha )( conv5 )
conv6 = Conv2D( 128 , kernel_size=( 3 , 3 ) , strides=1 )( relu5 )
relu6 = LeakyReLU( alpha )( conv6 )
maxpool3 = MaxPooling2D()( relu6 )
conv7 = Conv2D( 256 , kernel_size=( 1 , 1 ) , strides=1 )( maxpool3 )
relu7 = LeakyReLU( alpha )( conv7 )
conv8 = Conv2D( 256 , kernel_size=( 1 , 1 ) , strides=1 )( relu7 )
relu8 = LeakyReLU( alpha )( conv8 )
upsample1 = UpSampling2D()( relu8 )
concat1 = Concatenate()([ upsample1 , conv6 ])
convtranspose1 = Conv2DTranspose( 128 , kernel_size=( 3 , 3 ) , strides=1)( concat1 )
relu9 = LeakyReLU( alpha )( convtranspose1 )
convtranspose2 = Conv2DTranspose( 128 , kernel_size=( 3 , 3 ) , strides=1 )( relu9 )
relu10 = LeakyReLU( alpha )( convtranspose2 )
upsample2 = UpSampling2D()( relu10 )
concat2 = Concatenate()([ upsample2 , conv4 ])
convtranspose3 = Conv2DTranspose( 64 , kernel_size=( 3 , 3 ) , strides=1)( concat2 )
relu11 = LeakyReLU( alpha )( convtranspose3 )
convtranspose4 = Conv2DTranspose( 64 , kernel_size=( 3 , 3 ) , strides=1 )( relu11 )
relu12 = LeakyReLU( alpha )( convtranspose4 )
upsample3 = UpSampling2D()( relu12 )
concat3 = Concatenate()([ upsample3 , conv2 ])
convtranspose5 = Conv2DTranspose( 32 , kernel_size=( 3 , 3 ) , strides=1)( concat3 )
relu13 = LeakyReLU( alpha )( convtranspose5 )
convtranspose6 = Conv2DTranspose( 3 , kernel_size=( 3 , 3 ) , strides=1 , activation='relu' )( relu13 )
model = tf.keras.models.Model( inputs , convtranspose6 )
model.compile( loss='mse' , optimizer='adam' , metrics=[ 'mse' ] )Finally, we train our autoencoder model with skip connections,
最后,我们使用跳过连接来训练我们的自动编码器模型,
model.fit( x_train , y_train , epochs=150 , batch_size=25 , validation_data=( x_test , y_test ) )
The above results were obtained on a few test images. We observe the model has nearly learnt how to fill the black boxes! But we can still make out where the box lied in the original image. So this way, we can construct a model to predict the missing part of the image.
以上结果是在一些测试图像上获得的。 我们观察到该模型几乎学会了如何填充黑匣子! 但是我们仍然可以确定盒子在原始图像中的位置。 因此,通过这种方式,我们可以构建模型来预测图像的缺失部分。
进一步阅读 (Further Reading)
If you liked this blog, make sure you read more stories of mine here, on Medium.
如果您喜欢此博客,请确保在此处的Medium中阅读更多我的故事。
就这样! (That’s All!)
This is just a cool application of Auto Encoders. I got the inspiration for this video from here. Thanks for reading!
这只是自动编码器的一个很酷的应用程序。 我从这里获得了这段视频的灵感。 谢谢阅读!
翻译自: https://towardsdatascience.com/neural-implanting-with-autoencoders-and-tensorflow-9c2c7b532198
树莓派 神经网络植入