DQN-TC搭建整理
算法伪代码:
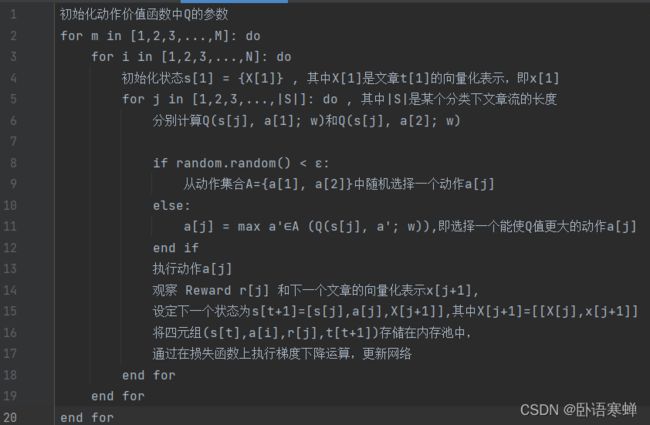
M:训练模型时遍历训练集的次数
N:训练集中类别的数量
s[t] = [ x[1] ,a[1],x[2],a[2],x[3],a[3],...,a[t-1], x[t] ]
当前的文本是当前episode的最后一个的时候r[j] = EG ,否则r[j] = 0 【EG:推文的期望增益】
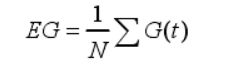 N : 文本数量,G(t) : 文本的增益
N : 文本数量,G(t) : 文本的增益
具体流程:
1、使用单层LSTM层作为编码器,用于生成文本的向量表示
2、强化学习中使用三层架构的神经网络来近似估计Q值
2_1、第一层是一个单层的LSTM层,用于生成输入的文本序列的高层抽象表示。在该估计函数中,激活函数是sigmoid。输入:X = [x[1],x[2],...,x[m]],隐藏层为 H = [h[1],h[2],...,h[m]],输出: h[m]
2_2、第二层为全连接层,该层接收来自上一层LSTM层的输出H[m]作为输入,激活函数时ReLU。输入: h[m] 输出:D[output]
2_3、第三层为全连接层,该层有两个神经元。输入:为上一层全连接层的输出D[output],输出:为含有两个值的向量(Q[1],Q[2]),激活函数为linear
该模型的输入是一个文本向量表示的序列,每篇作文的向量表示是通过单层的LSTM层对文本中的词序列进行编码得到的。LSTM网络的输入为三维的tensor(样本数,输入序列长度,序列中元素的向量维数)
Agent动作的选取采用两个策略:1、随机选取,然后进行探索 2、使用ε-greedy贪心策略进行选取。在训练过程中采取经验回放的方法,将之前的经验重新挑选出一部分重新进行训练,减少训练样本之间的相关度
具体步骤:
1、文本预处理
2、使用LSTM层对文本向量化
3、初始化模型参数,采用随机策略初始化内存记忆
4、以第一篇文本的向量表示作为Agent的初始状态,Agent动作的选取采用两个策略的融合形式,以一定概率去执行随机选择的动作,否则使用贪心策略选取动作执行
5、当环境接收到Agent传来的状态和动作后,使用深度神经网络来近似评估这组输入的Q值
6、环境的反馈定义为:当前的文本是当前episode的最后一个的时候r[j] = EG ,否则r[j] = 0 【EG:推文的期望增益】
7、设置强化学习网络中输入序列的长度K,K表示每次输入到LSTM网络的文本数量
8、每次输入K篇按文件名排序的文本的向量表示,输入到神经网络进行训练,在训练的过程中同时进行经验回放操作,减少训练样本之间的相关度【不太理解文本间的时序关系,不知道怎么解决,想要用文本排列顺序来替代时序关系,】
9、每隔一定的步数steps,将当前网络的权重复制到目标网络来
10、从每一次遍历中得到反馈,进而使用改反馈值来迭代更新Q(s,a),然后利用预测的Q值以基于贝尔曼方程得到的目标Q值来计算损失函数。最后使用随机梯度下降算法通过最小化损失函数来学习DQN-TC算法中的参数
11、使用测试集对模型进行测试,根据模型输出Q值的大小来决定下一步将要采取的动作