详解Pytorch中的torch.cat torch.stack
详解Pytorch中的torch.cat torch.stack
文章目录
- 详解Pytorch中的torch.cat torch.stack
-
- torch.cat
-
- 官方文档
- 分析
- 示例
- torch.stack
-
- 官方文档
- 分析
- 示例
- 总结
torch.cat
官方文档
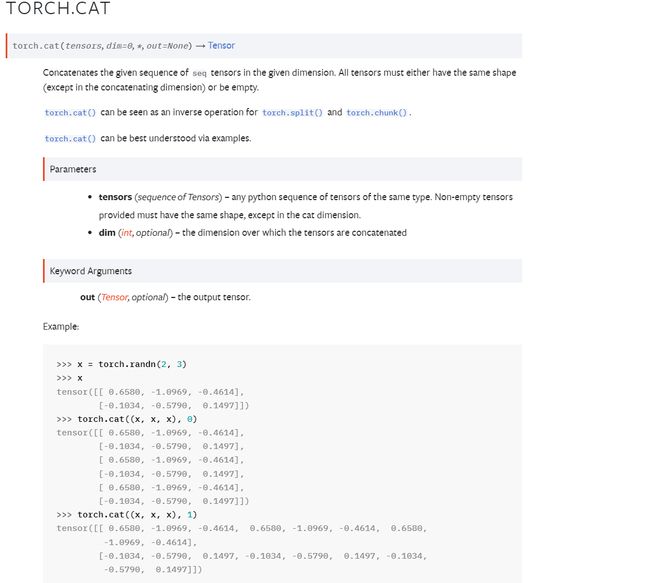
分析
-
函数作用:
将输入数据按照指定维度进行拼接(不产生新维度)
-
参数解析:
-
tensor : 目标tensor组成的tuple
-
dim:指定在哪个维度进行拼接(默认为0)
dim的取值范围为 输入tensor的维度数量
例如 输入tensor的shape为(1,3,5)。那么dim的取值范围为[0,2]
-
示例
生成数据
a=torch.randn((1,3,5))
b=torch.randn((1,3,5))
a,b
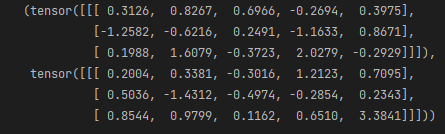
res=torch.cat((a,b),dim=0) #在第0维进行拼接 增加了第0维的数据长度
res,res.shape,res[0,:] == a #可以根据索引,找到原有的数据

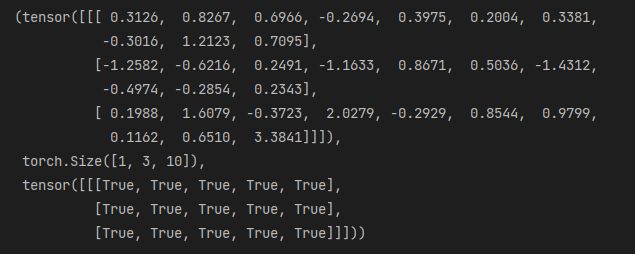
res=torch.cat((a,b),dim=1) #对于高维度矩阵,其最后两个维度 是其行和列 这里的dim=1指的就是矩阵的行
res,res.shape,res[0,0:3,:] == a #按照行进行拼接

res=torch.cat((a,b),dim=2) #对于高维度矩阵,其最后两个维度 是其行和列 这里的dim=2指的就是矩阵的列
res,res.shape,res[0,:,5:] == b#在列方向进行拼接 拓展列的数量
torch.stack
官方文档
分析
-
函数作用:
将输入数据按照指定维度进行拼接,将会产生新维度,且该维度的长度即为输入tuple中tensor的数量
-
参数解析:
-
tensor : 目标tensor组成的tuple
-
dim:指定在哪个维度进行拼接(默认为0),此处的dim更有插入维度的意味
dim的取值范围为 输入tensor的维度数量
例如 输入tensor的shape为(2,3,5)。那么dim的取值范围为[0,3]
-
示例
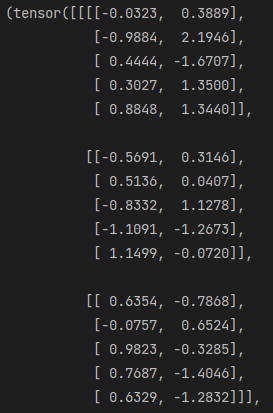
a=torch.randn((2,3,5)) #测试数据的生成
b=torch.randn((2,3,5))
a,b

为了更好地可视化数据,下面是示例数据的图
可以将其理解成 a和b每个数据都有两“片”,其中每一片都是一个3*5的矩阵
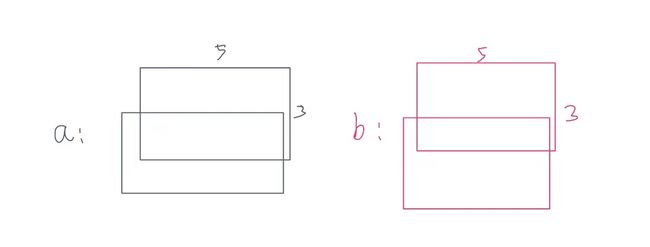
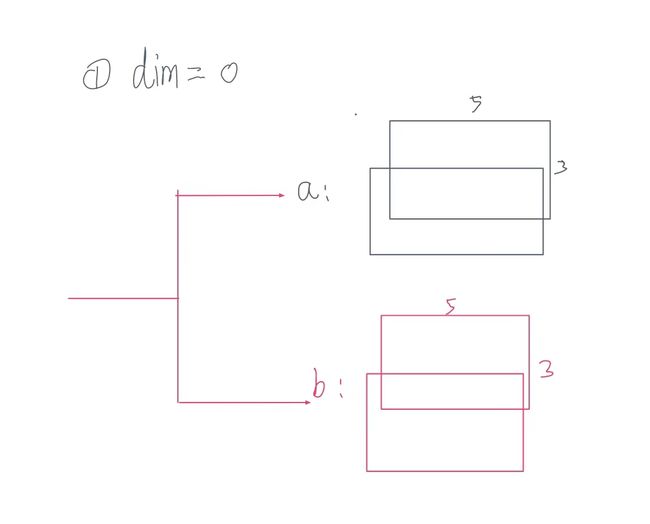
- dim = 0
相当于将 a b 视为一个整体 进行拼接
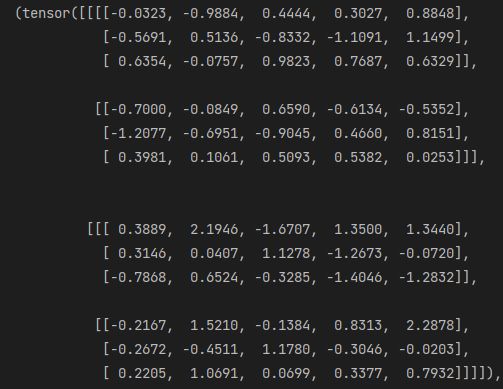
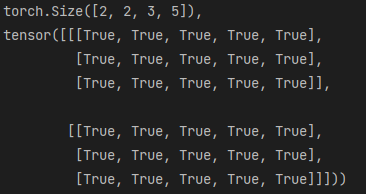
res=torch.stack((a,b),dim=0) #指定维度0 那么将在维度0位置插入数据 且该维度的长度为2
res,res.shape,res[0,:] == a #其作用等价于新建了一个容器 并将a b按输入顺序存放
#可以按照索引访问存放在里面的数据
可视化:
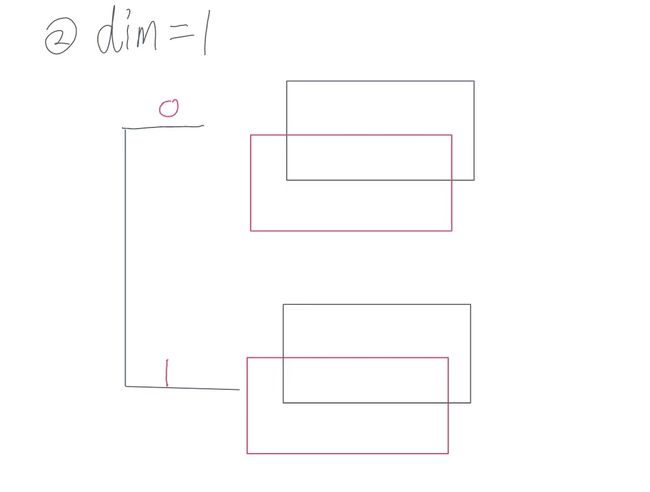
- dim = 1
相当于 取出 a b 中的维度0的数据,根据相同索引的数据进行拼接
例如 将 a[0]和b[0]的数据进行拼接形成一个新的通道内数据
res=torch.stack((a,b),dim=1)
res,res.shape,res[0,1,:] == b[0,:]
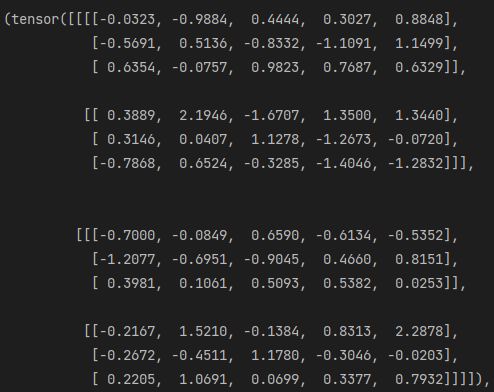
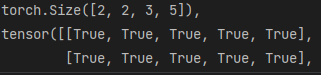
可视化
- dim = 2
参照dim=1的情况,按顺序取出 a b中维度1 的数据 并将相同索引的数据存放在一起 组成新的数据对象
由于此处输入数据为3维度的数据,那么其维度1 的数据就是每一行的数据
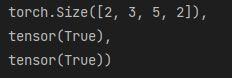
res=torch.stack((a,b),dim=2)
res,res.shape,res[0,0,0,:] == a[0,0,:],res[0,0,1,:] == b[0,0,:]
#在倒数第二个维度 将按照输入数据的行进行拼接
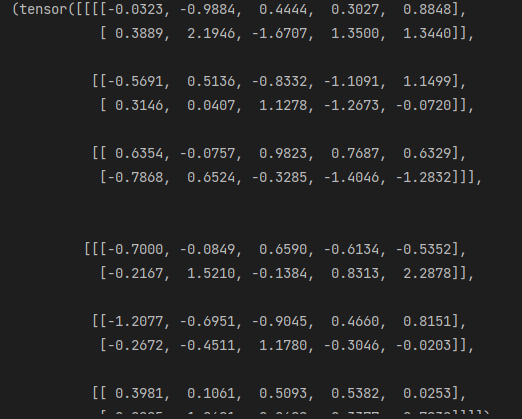
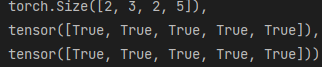
可视化
-
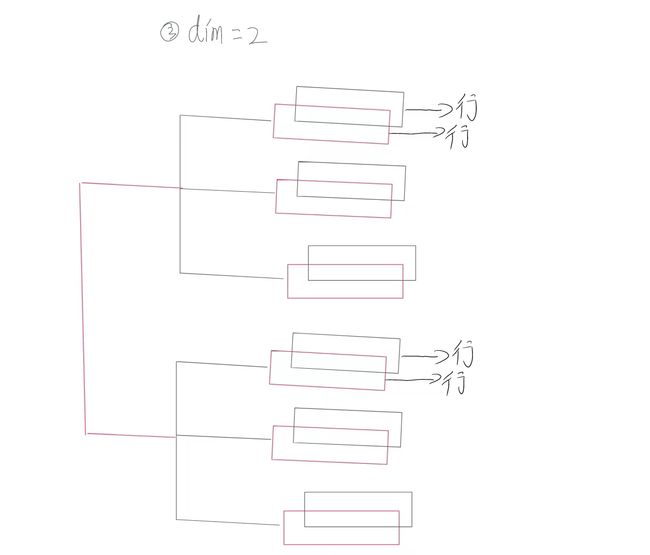
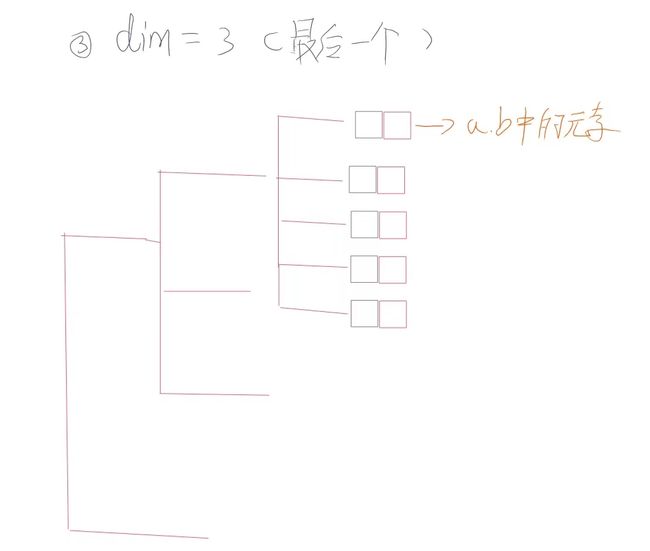
dim =3
在有前面示例的情况下,此处就很容易得出:
当dim取最后一个取值时,其是取出输入tensor中的每一个数据并根据索引进行拼接
res=torch.stack((a,b),dim=3) res,res.shape,res[0,0,0,0] == a[0,0,0],res[0,0,0,1] == b[0,0,0] #在倒数第一个维度 将按照输入数据 按元素进行拼接

可视化:
总结
-
tocch.cat将输入数据视为一个整个 dim参数只是改变其拼接数据的方向
在这个过程中,输入tensor将被视为一个整体进行处理
输出结果不会改变维度,只会改变某一维度的长度数值
-
torhc,stack 输出数据将会升维
dim参数指定的是在哪一个维度插入数据,且该维度的长度为输入tensor的数量
dim同时也可以认为其是取得第dim维的数据并根据索引值,将输入各个tensor中相对应的数据进行拼接