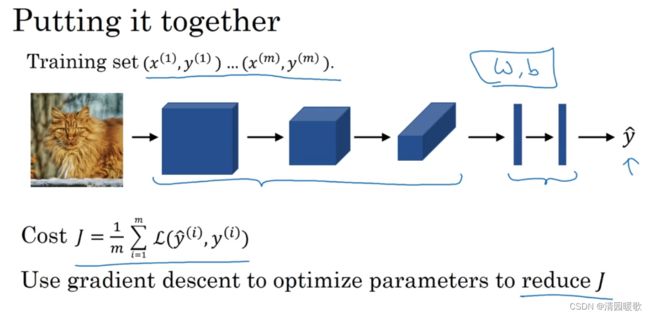
深度学习第四课——卷积神经网络(week 1)
目录
一、前言
1.1 卷积
1.2 其他滤波器
1.3 Padding
1.3.1 解释
1.3.2 填充多少像素的选择
1.4 卷积步长
1.5 三维卷积
1.6 单层卷积网络
1.7 深度卷积神经网络的一个示例
1.8 池化层
1.8.1 最大池化
1.8.2 平均池化
1.8.3 总结
1.9 卷积神经网络示例
1.10 为什么使用卷积
一、前言
1.1 卷积
为了检测出这个 6 ×6 图像的垂直边缘,构建一个 3×3 的过滤器(filter),或者称为 核,进行卷积运算 *,输出得到一个 4×4 的矩阵,里面元素的运算过程如下图所示,以第一行第一列的元素为例:
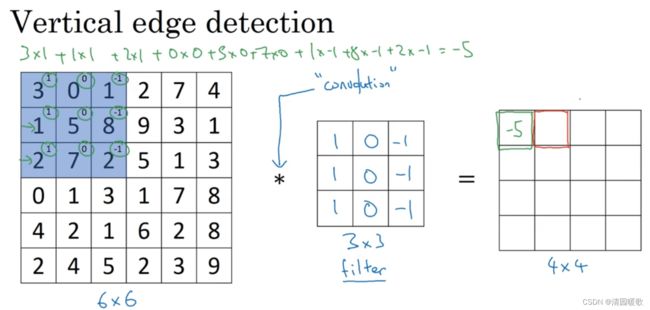
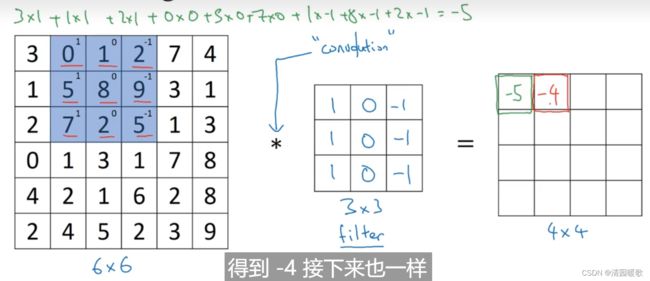
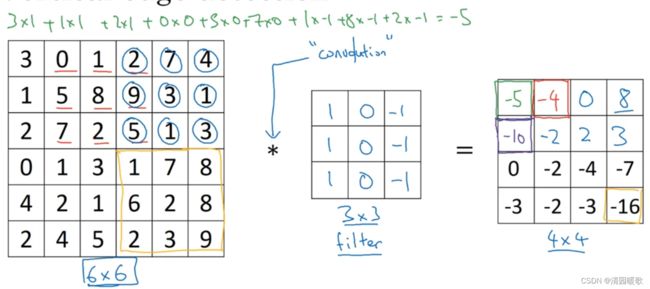
这个即为:垂直边缘检测器
不同编程框架下的卷积运算:
python:conv_forward 函数
tensorflow:tf.nn.conv2d 函数
Keras:Conv2D 函数
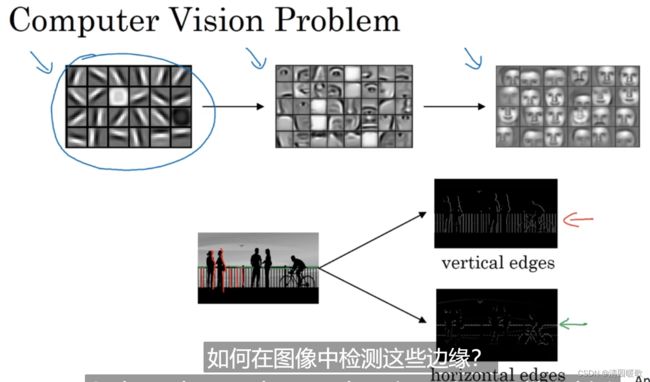
为什么这个可以做 垂直边缘检测?
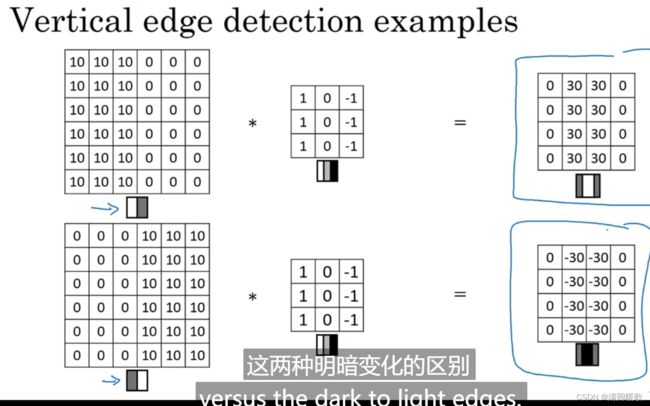
如图,10像素表示 偏亮一点

在这个例子中,输出图像的中间区域的亮处,表示在图像中间,有一个特别明显的垂直边缘;且这个例子里会发现,检测出来的边缘维度不对,太粗了,这是因为输入的图片太小了,如果是1000×1000 的图片,其实会很好的检测出图片的垂直边缘
可以发现,明亮的像素在左边,深色的像素在右边,就被视为一个垂直边缘
同时,这个滤波器可以提供明暗变化的区别,30是由亮到暗,-30是由暗到亮
1.2 其他滤波器
sobel 滤波器:增加了中间的权值,也就是处在图像中间的像素点,这使得结果的鲁棒性更高
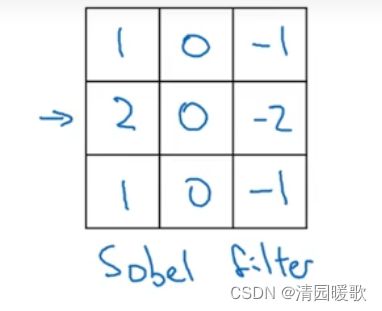
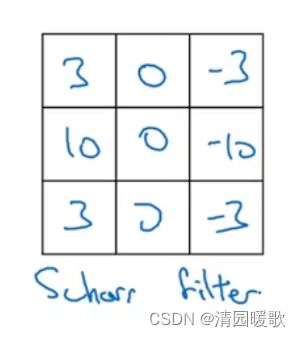
Scharr 滤波器:与之前有完全不一样的特性,但也是一种垂直边缘检测
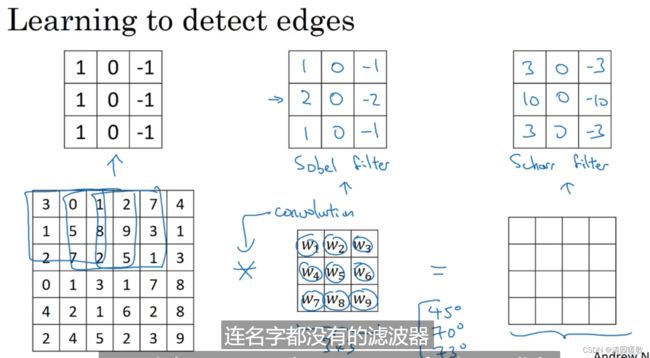
如果把这些元素都当成参数,通过深度学习反向传播去自动学习这些参数,以得到任何角度的边缘
1.3 Padding
1.3.1 解释
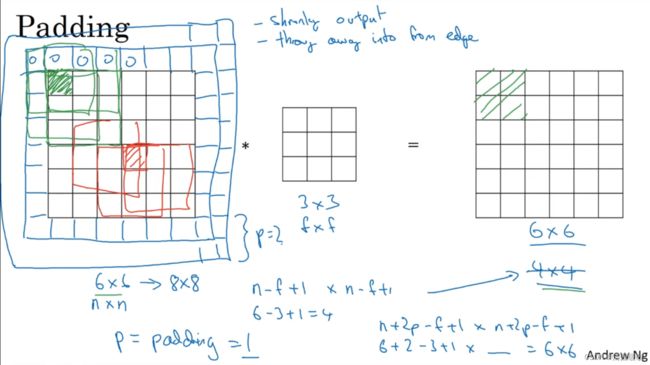
若对一个 n × n 的图像使用一个 f × f 的滤波器,会输出一个 (n-f+1)×(n-f+1)的图像
这样有一些缺点:
(1)就是每做一个图像都会被缩小
(2)角落的像素点只被一个输出所触碰或被使用,而中间的像素点,则会有多个3×3 的区域与之重叠,所以那些在角落或是在边缘的像素点,在输出中采用较小,意味着你丢掉了图像边缘的位置的许多信息
所以要想解决,可以在卷积之前,给原图像的外层再填充一层像素;如将一个 6 × 6 的图像填充成 8 × 8 的图像,习惯上用 0 填充,填充的数量 p = padding = 1 的话,相当于填充了1 层,此时输出为(n+2p-f+1)×(n+2p-f+1),这样一来角落或边缘的像素发挥的作用较小,缺点就被削弱了
1.3.2 填充多少像素的选择
(1)Valid 卷积
不填充,输出 (n-f+1)×(n-f+1)
(2)Same 卷积
意味着填充后的输出大小和输入大小一样,输出(n+2p-f+1)×(n+2p-f+1)
而要相等,则令: n = n+2p-f+1,=> p = (f - 1)/ 2
习惯上,f 通常是 奇数,
可能有两种原因:
(1)偶数过滤器的话只能使用 不对称填充,只有f是奇数,Same卷积才会有自然的填充,而不是左边多一点、右边少一点这类不对称填充
(2)奇数维过滤器会有一个中心点,计算机视觉中有个中心像素点会更方便,便于指出过滤器的位置

1.4 卷积步长
卷积中的步长(步幅)是另一个构建卷积神经网络的基本操作。初始步长为1,而步长为2时,也就是让过滤器再原图像上每次跳过2个步长,由第一个像素起始。下一次到第三个像素
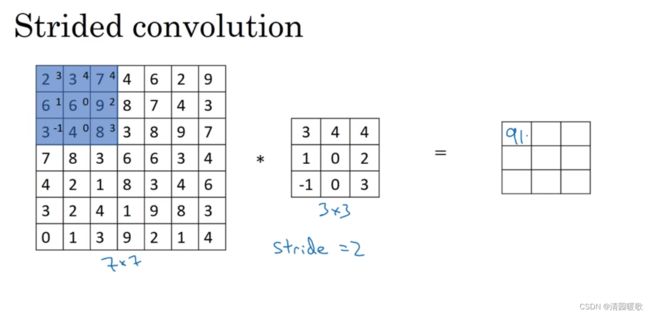
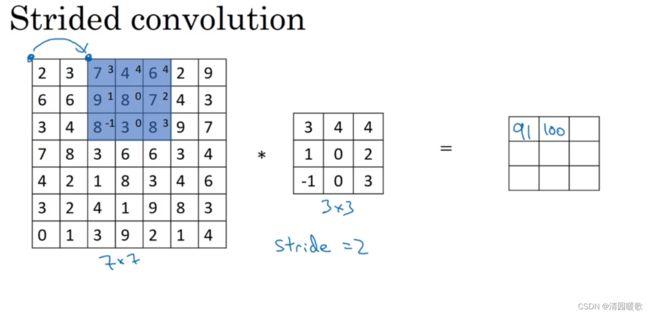
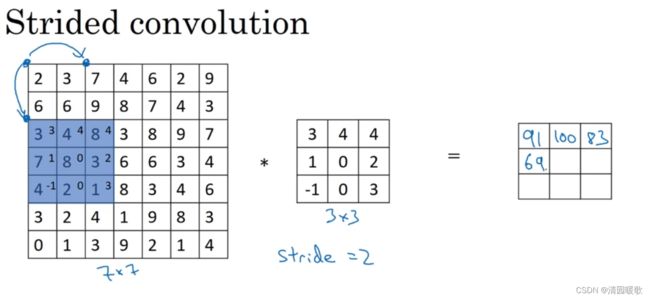
设padding为p,步长stride为s。则输出为(n+2p-f+1)/ s + 1 ×(n+2p-f+1)/ s + 1
如果商不是一个整数,就向下取整,符号为:" |_ z_| ",也叫对 z 进行地板除,即将z向下取整到最近的整数,原则就是如果过滤器框超出就不进行卷积
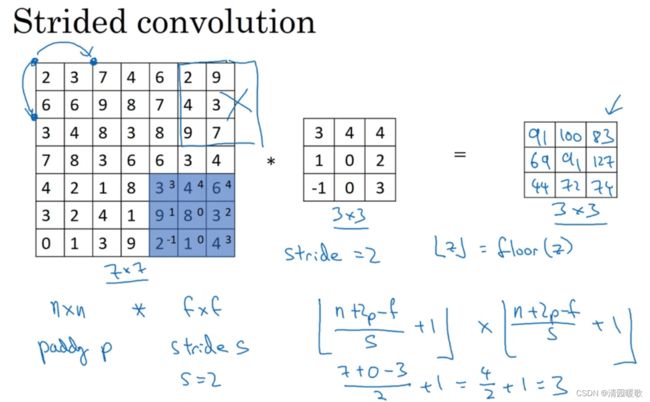

实际上的卷积操作,首先还要给过滤器再水平和垂直轴上做翻转,类似镜像, 将翻转后的矩阵作为过滤器。而我们的操作跳过了这个镜像操作,所以实际上我们之前做的操作有时被称为互相关,而不是卷积,但深度学习文献中,按照惯例,我们将这称为 卷积操作
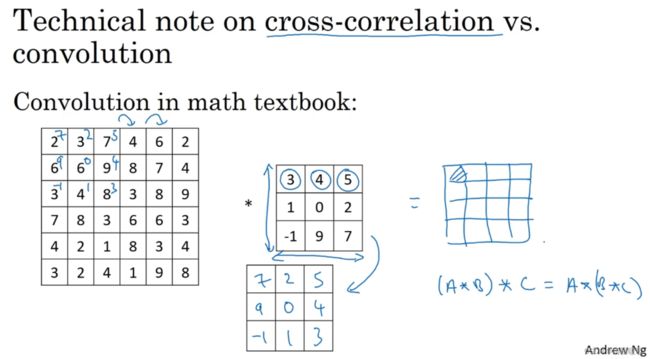
1.5 三维卷积
如不是对一个灰度图像进行检测,而是对一个有3个通道的RGB图像进行检测
图像的通道数和过滤器的通道数必须要一致,如 6×6×6 * 3×3×3 = 4×4×1
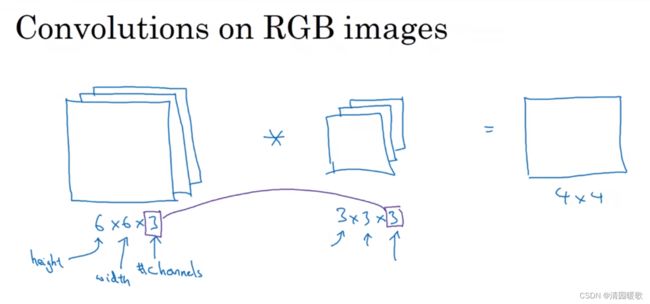
与二维的类似,只不过图像和过滤器对应卷积
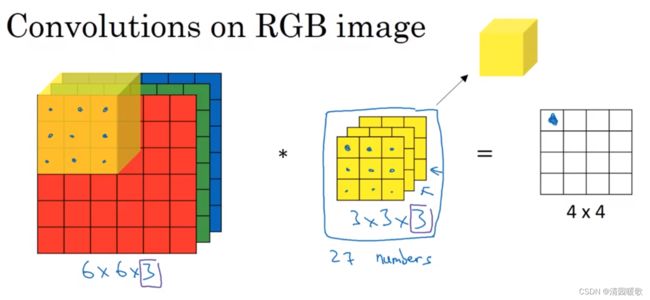
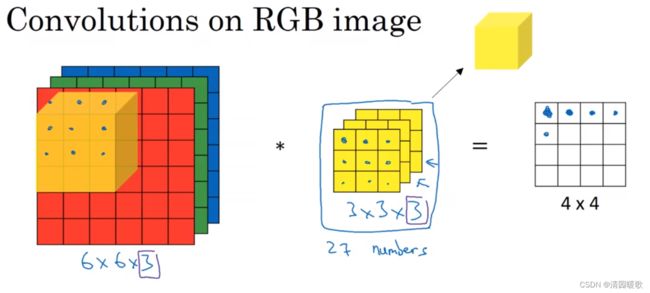
作用是什么?
如要只对红色通道有用的垂直检测过滤器,只需G,B都为0,R过滤器正常1,0,-1即可,若不关心通道,就所有过滤器都为1,0,-1
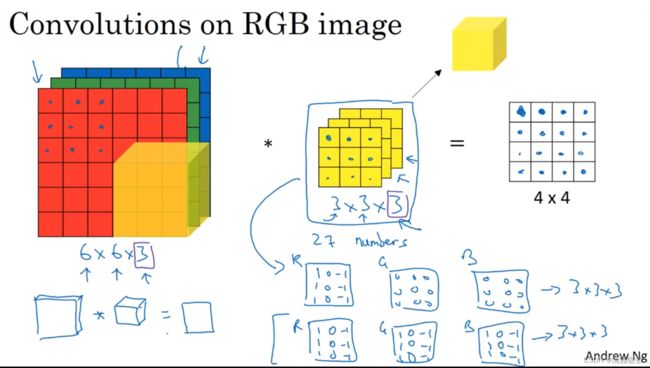
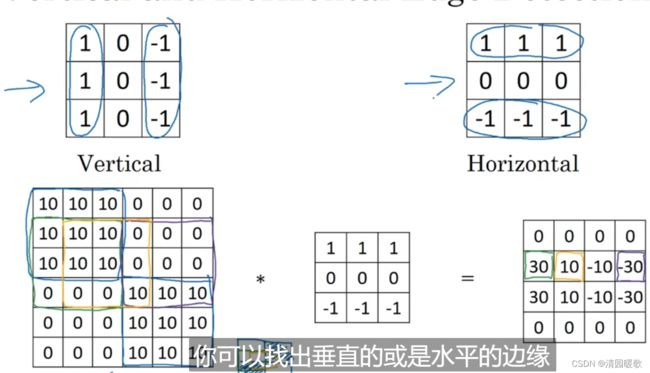
如果想要同时使用多个过滤器,例如下图,上面是垂直检测,下面是水平检测,然后把两个输出堆叠在一起,就获得了一个 4×4×2 的输出,这就是多卷积核形成的多特征平面
总结一下,一个 n×n×n_c * f×f×f_c = (n-f+1) × (n-f+1) × n_c' (n_c'是过滤器的个数),如果用了不同的步幅还会发生变化,所以,我们可以使用多个过滤器,来检测多个特征,并输出这些特征,输出的通道数就等于你要检测的特征数,
这里的通道数,在一些文献里也被称为 3维立方体的深度
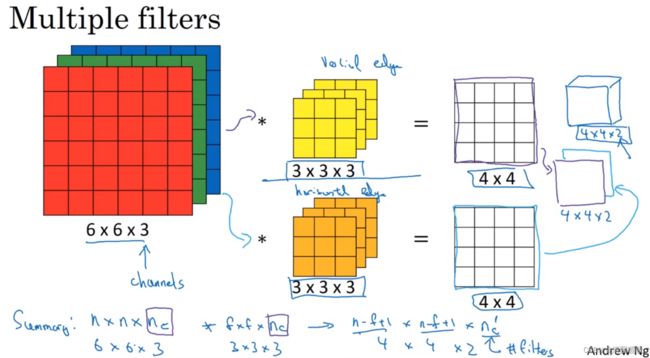
1.6 单层卷积网络
上例中,通过两个过滤器输出的结果都各自形成一个卷积神经网络层,然后可以各自增加不同的偏差 b,再运用非线性激活函数 ReLU,得到两个4×4 的矩阵,堆叠一起得到 4×4×2的输出,它是卷积神经网络的一层,把它映射到标准神经网络中四个卷积层中的某一层,或者一个非卷积神经网络中。
注意,前向传播其中一个操作就是z[1] = W[1] a[0] + b[1],a[0]相当于x,执行非线性函数,a[1] = g(z[1]),左边的 6×6×3 的输入就是a[0],就是x;过滤器用变量W[1]表示,输出结果相当于W[1] a[0] ,到加上b之前都是应用非线性函数ReLU之前的值,最后运用ReLU,称为神经网络的下一层,也就是激活层,这就是a[0]到a[1]的演变过程
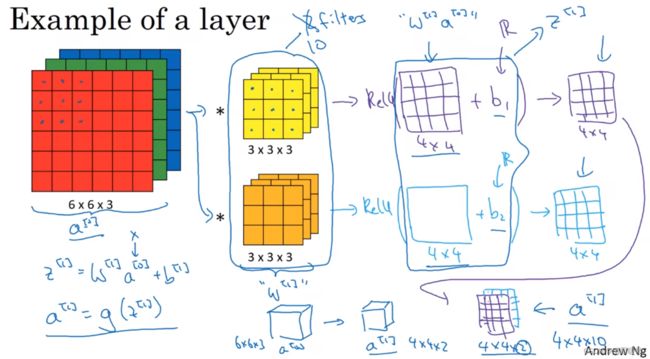
用10个3×3×3的过滤器,一个过滤器加上偏差就是28个,10个就是280个,无论输入的图片大小多大,是1000×1000,还是5000×5000,参数始终都是280个,这就是卷积神经网络的一个特征,叫做“避免过拟合”

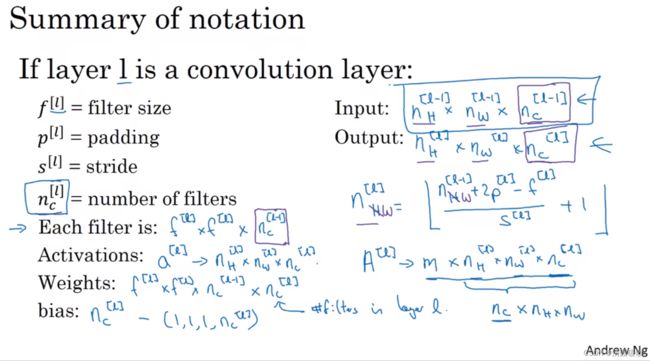
上标 ^[l] ,用来表示 l 层
在第 l 层,图片大小为 n_H^[l-1] × n_W^[l-1] × n_C^[l-1],而 l 层的输入为上一层 l-1层的输出
所以输出图像大小为 n_H^[l] × n_W^[l] × n_C^[l]
具体计算为:
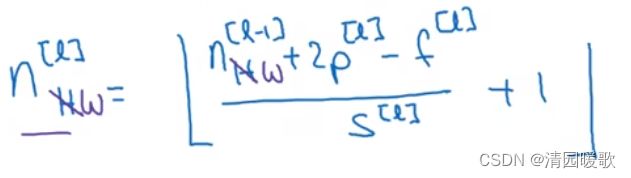
每层过滤器的大小 n_C^[l] = f^[l] × f^[l] × n_C^[l-1]
当执行批量梯度下降或小批量梯度下降,有m个例子,就是有m个激活值的集合,那么输出A[l]为:

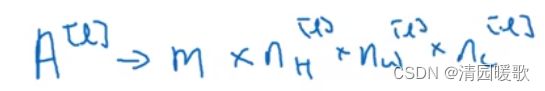
参数 W 和偏差 b 该如何确定
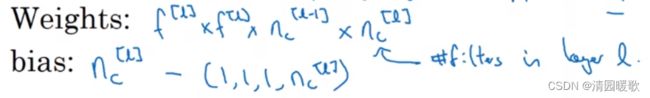
1.7 深度卷积神经网络的一个示例
如图,要做图像分类

一个典型的卷积网络通常有三层:一个是卷积层,常用 Conv(Convolution)标注;还有池化层,称为 POOL(Pooling);还有全连接层,用 FC(Fully connected)表示。

虽然仅用卷积层,也可能构建出和好的神经网络,但大部分神经网络架构师依然会添加池化层和全连接层
1.8 池化层
池化层 可用来缩减模型的大小,提高计算速度,提高所提取特征的鲁棒性
1.8.1 最大池化
假设输入是一个4×4的矩阵,用到的池化类型是 最大池化(max pooling),执行最大池化的输出是一个2×2的矩阵;执行过程非常简单,把4×4输入拆分成不同的区域,对于2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值,为了得到输出的元素值,需要对输入矩阵的2×2区域做最大值运算,相当于应用了一个规模是2,即2×2的过滤器,步长也为2,这就是最大池化的超级参数,f=2,s=2
可以把这个4×4的区域看作是某些特征的集合,也就是神经网络中某一层的反激活值集合,数字大意味着可能提取了某些特定特征,而这里左上象限的特征,可能就是一个垂直边缘,一只眼睛,或者CAP特征;然而右上象限并不存在这个特征,最大化操作的功能就是只要在任何一个象限内提取到某个特征,他都会保留在最大池化的输出里。
最大化运算的实际作用就是,如果在过滤器中提取到某个特征,那么保留其最大值;如果没有提取到这个特征,可能不存在这个特征,那么其中的最大值也还是很小

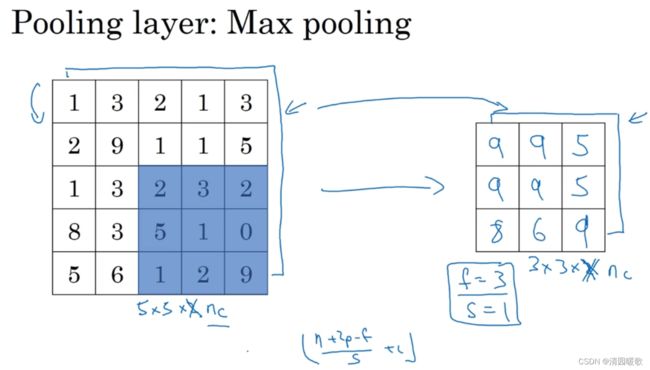
下面,输入为5×5的矩阵,假设3×3过滤器,即f=3,s=1,所以池化层的输出为
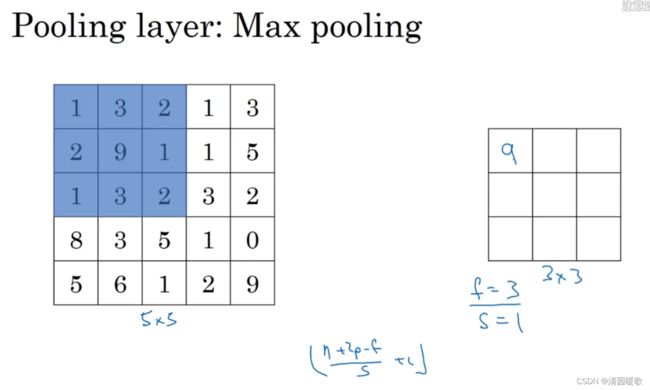
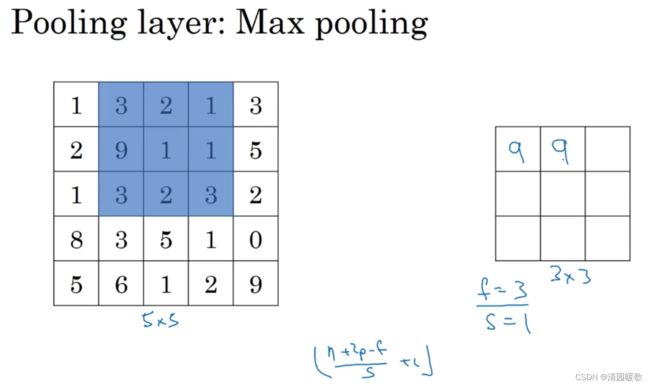
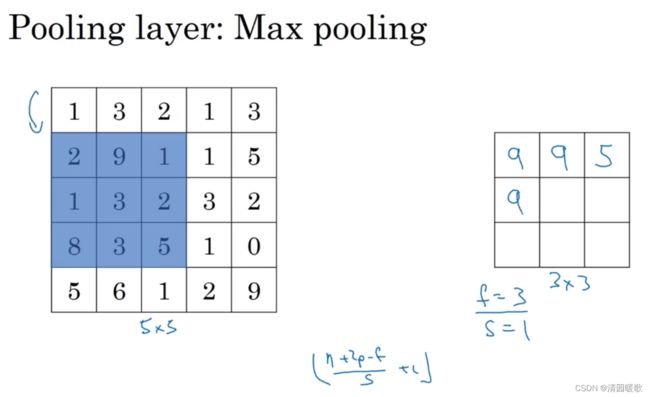
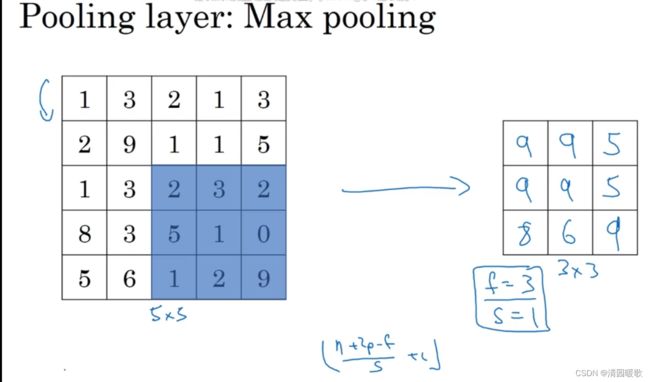
这就是二维的最大池化输出演示,如果输入是三维的,那么输出也是三维的,即对每个信道进行相对应的池化计算
1.8.2 平均池化
顾名思义,取得不是每个过滤器的最大值,而是平均值
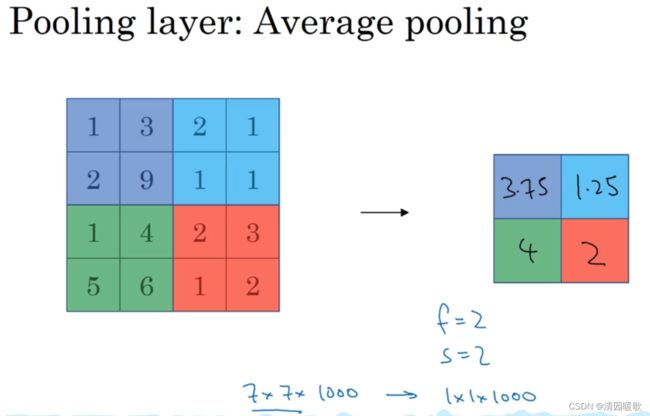
目前来说,最大池化必平均池化更常用,但也有例外,就是深度很深的神经网络,
1.8.3 总结
池化层的超级参数,一般来说是f=2,s=2,相当于表示层的高度和宽度缩减一半,也有f=3,s=2的,其他参数就要看用最大池化还是平均池化了,也可以根据自己的意愿去增加 p 这样的参数,虽然很少用
输出也是计算为:
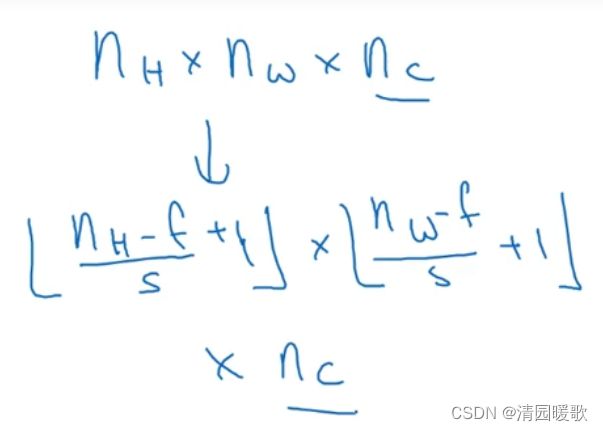
需要注意的是,池化过程中没有需要学习的参数
执行反向传播时,反向传播没有参数适用于最大池化,只有这些设置过的参数f、s,可能是手动设置的,也可能是通过交叉验证设置的
最大池化只是计算神经网络某一层的静态属性

1.9 卷积神经网络示例
下例,假设有一张大小为 32×32×3 的输入图片,是RGB模式的,若想做手写数字识别,该图片含有某个数字,比如7,我们想识别他是0-9的哪个数字,构建神经网络来实现,这个网络模型和经典网络LeNet-5非常相似,灵感也来于此
第一层过滤器f=5,s=1,p=0,6个过滤器,那么输出为 28×28×6 ,这层标记为 CONV1;构建最大池化层,f=2,s=2,输出为 14×14×6 ,标记为 POOL1;把 CONV1 和 POOL1共同作为一卷积层,标记为 Layer1;一般在统计网络层数时,只计算具有权重的层
再构建一个卷积层,10个f=5,s=1的过滤器,输出一个 10×10×10的矩阵,标记为 CONV2;再做最大池化f=2,s=2,减半,输出为 5×5×10,,标记为 POOL2;标记为Layer2
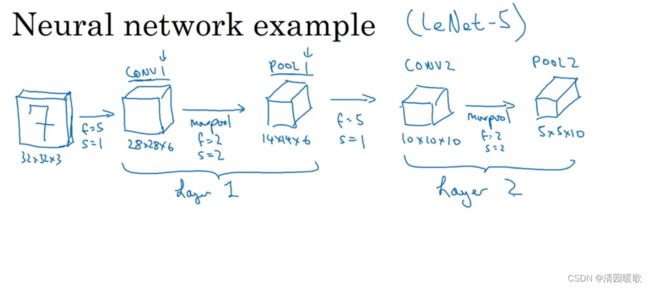
如果应用另一个卷积层,16个f=5,s=1的过滤器,CONV2输出为 10×10×16;执行最大池化f=2,s=2,输出为 5×5×16,为POOL2,有400个元素;将POOL2平整化为一个大小为400的一维向量,可以把平整化结果想象成这样一个神经元集合,利用这400个单元构建下一层,下一层含有120个单元,这就是我们第一个全连接层,标记为FC3;这400个的单元与这120个单元中的每一个连接,有参数w和偏差b,输出120个维度,再添加一个全连接层,假设这一层含有84个单元,标记为FC4;最后用这84个单元填充一个 softmax 单元,如果要识别0-9个数字,那么 softmax 就有10个输出,尽量不要自己设置超级参数,而实查看文献中别人采用的
神经网络中,另一种常见模式就是一个或多个卷积层后面跟随一个池化层,然后是几个全连接层,最后是一个softmax

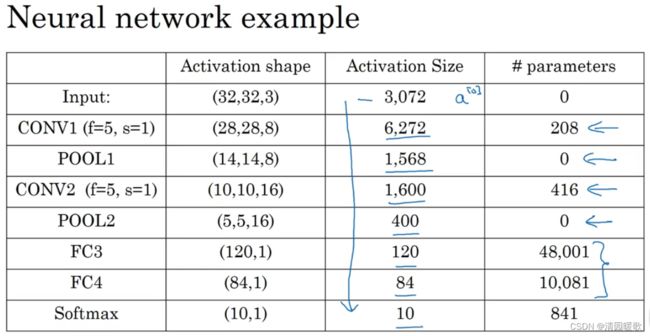
208 = (5*5+1)* 6
48001 = 400 * 120 +1
1.10 为什么使用卷积
和只用全连接层相比,卷积层的两个主要优势在于参数共享和稀疏连接
假设有 32×32×3 (3072个元素)的图片,用6个5×5 的过滤器,输出为 28×28×6(4704个元素),权重矩阵有 3072×4704 =1400万个参数;如果是1000×1000的图片,那么权重矩阵会更大
这里参数 6×26 = 156个
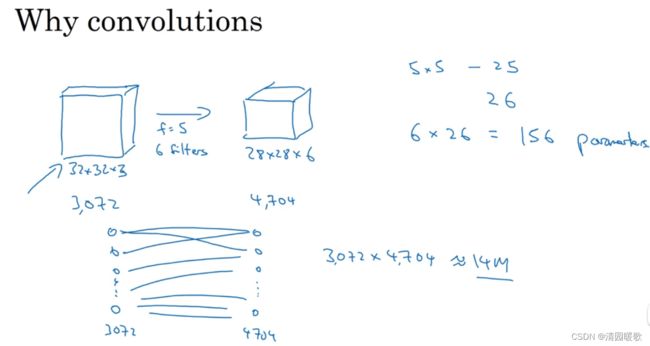
卷积网络映射这么少参数有两个原因:参数共享、稀疏连接
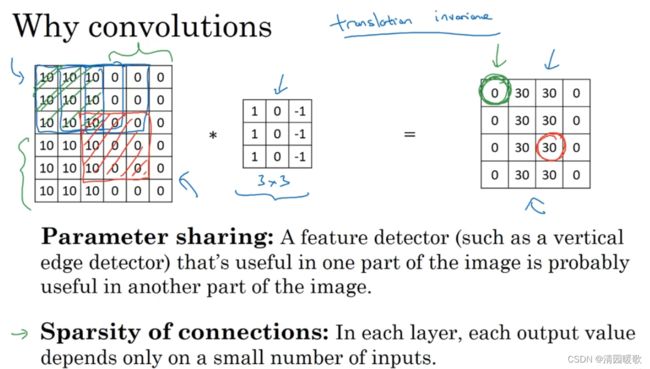
(1)参数共享:特征检测如垂直边缘检测如果适用于图片的某个区域,那么它也可能适用于图片的其它区域,也就是说,如果用一个3×3的过滤器检测垂直边缘,那么图片的左上角区域以及旁边的各个区域都可以使用这个3×3的过滤器,每个特征检测器以及输出都可以在输入图片的不同区域中使用同样的参数,以便提取垂直边缘或其他特征。它不仅适用于边缘特征这种低级特征,也适用于高价特征,如提取脸上的眼睛,即使减少参数个数,这9个参数也能计算出16个输出
(2)稀疏连接:输出的第一个元素只与输入的左上的3×3的9个元素有关,而其他像素无法影响这个输出的元素,这就是稀疏连接
神经网络可以通过这两种机制减少参数,以便于我们用更小的训练集来训练它,从而预防过度拟合
因为神经网络的结构,即使移动几个像素,这张图片依然具有非常相似的特征,属于同样的输出标记。实际上,我们用同一个过滤器生成各层中图片的所有像素值,希望网络通过自动学习变得更加健壮,以便更好地取得所期望的平移不变的属性,这就是卷积或卷积神经网络在计算机视觉任务中表现良好的原因
最后整合,训练神经网络,使用梯度下降算法或其他梯度下降来优化神经网络中的所有参数,以减少代价函数J的值,