YOLOv3目标检测
文章目录
- 前言
- 一、前期准备
- 二、使用步骤
-
- 1.引入库
- 2.初始化配置
- 3.设置网络
- 4.帧处理
- 完整代码:
- 总结
前言
一直都对opencv很感兴趣,觉得它的能力真的很强大。而且yolo更是如雷贯耳早就想想学习一下了,刚好今天好了一个这类的视频,就顺便学习一下。
参考:
python与C++
枫333
一、前期准备
下载yolov3相关文件:下载链接
olov3.weights 文件包含了预训练的网络权重;
olov3.weights下载
yolov3.cfg 文件包含 了网络配置;
yolov3.cfg下载
coco.names 文件包含了 COCO 数据集中的 80 个不同类别名.
coco.names下载
注意:要把这三个文件放在程序文件相同目录下,不然需要改动这三个文件的导入地址。
二、使用步骤
1.引入库
import cv2
import numpy as np
安装cv库:
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
2.初始化配置
coco.names 包含了模型训练时的物体类别名. 首先读取该文件.
网络包含两部分:
yolov3.weights - 预训练的模型权重
yolov3.cfg - 网络配置文件
设置 DNN 后端为 OpenCV ,目标设置为 CPU. 也可以设置为 cv.dnn.DNN_TARGET_OPENCL 以在 GPU 上运行.注意当前 OpenCV 版本只支持 Intel 的 GPUs 测试。
# 获取摄像头或视频地址
cap = cv2.VideoCapture(r"./data/test.mp4")
# coco.names文件存储着80种已经训练好的识别类型名称,并且这些类别名称正好与yolo所训练的80种类别一一对应
classesFile = r"coco.names"
# 存储类型名称列表
classNames = []
with open(classesFile, "rt") as f:
# 依照行读取数据
classNames = f.read().splitlines()
# 显示所有类型名称
print(classNames)
# 配置yolov3
modelConfiguration = "yolov3.cfg" # 配置文件
modelWeights = "yolov3.weights" # 配置权重文件
net = cv2.dnn.readNetFromDarknet(modelConfiguration, modelWeights) # 将配置文件加入到dnn网络中
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV) # 将DNN后端设置成opencv
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU) # 将DNN前端设置成cpu驱动
3.设置网络
神经网络的输入图片需要以 blob 的特定格式组织.
当读取了一帧图片后,其需要经过 blobFromImage 函数的处理,以转换为网络的 input blob. 在该处理过程中,图片像素值被采用 1/255 的因子缩放到 [0, 1] 范围;且在不裁剪的情况下,将图片尺寸调整为 (416, 416).
注:并未进行任何减均值操作,因此,函数的均值参数采用的是 [0, 0, 0]。设置网络的输入图片的默认尺寸 :inpWidth 和 inpHeight. 这里均设置为 416,也可以设置为 320 以得到更快的速度,设置为 608 以得到更好的精度.
输入图处理后输出的 blob,被作为网络输入,进行前向计算,以得到输出的预测边界框列表. 网络输出的预测框再进行后处理,以过滤低置信度的边界框.
OpenCV 的 Net 类的 forward 函数需要知道网络的最终输出层.
由于要对整个网络进行运行,因此,需要确认网络的最后一层.采用 getUnconnectedOutLayers() 函数来获取无连接的输出层的名字,这些层一般都是网络的输出层.
while True:
# 读取数据
success, frame = cap.read()
# DNN网络的输入图像需要采用称为 blob 的特定格式
blob = cv2.dnn.blobFromImage(frame, 1 / 255, (inpWidth, inpHeight), [0, 0, 0], True, False)
# 将输出的blob作为传入网络的输入
net.setInput(blob)
# 获取输入层的名称
layerNames = net.getLayerNames()
# 获得输入层的最后一层,以此遍历整个网络
outputNames = [layerNames[i - 1] for i in net.getUnconnectedOutLayers()]
outputs = net.forward(outputNames)
findObjects(outputs, frame)
# 显示图像
cv2.imshow("img", frame)
# 等待按键ESC
if cv2.waitKey(10) == 27:
break
# 释放内存
cap.release()
cv2.destroyAllWindows()
4.帧处理
网络输出的每个边界框表示为 类别名 + 5个元素的向量.
向量的前 4 个元素分别为:center_x , center_y , width 和 height.
第 5 个元素表示包含物体的边界框的置信度.
其余的元素是与每个类别相关的置信度(概率). 边界框被分配到对应于最高分数的类别. box 的最高分数也被叫作 置信confidence. 如果 box 的置信低于给定阈值,则丢弃该边界框,并不进行进一步的后处理.
置信大于或等于给定置信阈值的 boxes,会进行 NMS 进一步处理,以减少重叠 boxes 的数量.
如果 nmsThreshold 参数过小,如 0.1,可能检测不到相同或不同类别的重叠物体.
如果 nmsThreshold 参数过大,如,1,则会得到同一个物体的多个框.
# yolov3检测并处理
def findObjects(outputs, img):
hT, wT, cT = img.shape # 获取原始帧图像的大小H,W
bbox = [] # 创建存储先验框的坐标列表
classIds = [] # 创建存储每帧检测到的类别信息名称
confs = [] # 创建每帧读取的置信度值
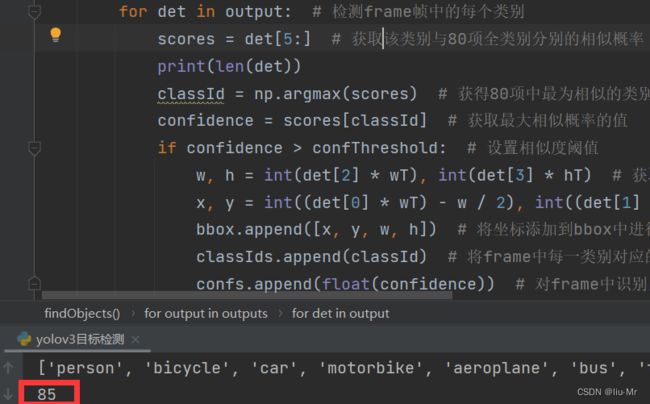
for output in outputs: # 对所有类别遍历
for det in output: # 检测frame帧中的每个类别
scores = det[5:] # 获取该类别与80项全类别分别的相似概率
classId = np.argmax(scores) # 获得80项中最为相似的类别(相似概率值最大的类别)的下标
confidence = scores[classId] # 获取最大相似概率的值
if confidence > confThreshold: # 判断相似度阈值
# 获取先验框的四个坐标点
w, h = int(det[2] * wT), int(det[3] * hT)
x, y = int((det[0] * wT) - w / 2), int((det[1] * hT) - h / 2)
bbox.append([x, y, w, h]) # 将坐标添加到bbox中进行存储,便于对frame帧中所有类别的先验框坐标进行存储
classIds.append(classId) # 将frame中每一类别对应的编号(1-80),便于在输出文本时,与对应coconame文件中的类别名称进行输出
confs.append(float(confidence)) # 对frame中识别出来的每一类信息进行最大抑制由参数nms阈值控制
# 对frame中识别出来的每一类信息进行最大抑制由参数nms阈值控制
indices = cv2.dnn.NMSBoxes(bbox, confs, confThreshold, nmsThreshold)
for i in indices:
box = bbox[i] # 依次读取最大已知参数nms阈值的先验框坐标
x, y, w, h = box[0], box[1], box[2], box[3]
# print(x,y,w,h)
# 对每个最终识别的目标进行矩形框选
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 255), 2)
# 对应coco.names相应的类别名称和相似概率进行文字输出
cv2.putText(img, f'{classNames[classIds[i]].capitalize()} {int(confs[i] * 100)}%',
(x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 255), 2)
完整代码:
import cv2
import numpy as np
# 获取摄像头或视频地址
cap = cv2.VideoCapture(r"./data/test.mp4")
# 识别置信度阈值
confThreshold = 0.5
# 最大抑制值
nmsThreshold = 0.2
# 网络输入图像的宽度和高度
inpWidth = 320
inpHeight = 320
# coco.names文件存储着80种已经训练好的识别类型名称,并且这些类别名称正好与yolo所训练的80种类别一一对应
classesFile = r"coco.names"
# 存储类型名称列表
classNames = []
with open(classesFile, "rt") as f:
# 依照行读取数据
classNames = f.read().splitlines()
# 显示所有类型名称
print(classNames)
# 配置yolov3
modelConfiguration = "yolov3.cfg" # 配置文件
modelWeights = "yolov3.weights" # 配置权重文件
net = cv2.dnn.readNetFromDarknet(modelConfiguration, modelWeights) # 将配置文件加入到dnn网络中
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV) # 将DNN后端设置成opencv
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU) # 将DNN前端设置成cpu驱动
# yolov3检测并处理
def findObjects(outputs, img):
hT, wT, cT = img.shape # 获取原始帧图像的大小H,W
bbox = [] # 创建存储先验框的坐标列表
classIds = [] # 创建存储每帧检测到的类别信息名称
confs = [] # 创建每帧读取的置信度值
for output in outputs: # 对所有类别遍历
for det in output: # 检测frame帧中的每个类别
scores = det[5:] # 获取该类别与80项全类别分别的相似概率
classId = np.argmax(scores) # 获得80项中最为相似的类别(相似概率值最大的类别)的下标
confidence = scores[classId] # 获取最大相似概率的值
if confidence > confThreshold: # 判断相似度阈值
# 获取先验框的四个坐标点
w, h = int(det[2] * wT), int(det[3] * hT)
x, y = int((det[0] * wT) - w / 2), int((det[1] * hT) - h / 2)
bbox.append([x, y, w, h]) # 将坐标添加到bbox中进行存储,便于对frame帧中所有类别的先验框坐标进行存储
classIds.append(classId) # 将frame中每一类别对应的编号(1-80),便于在输出文本时,与对应coconame文件中的类别名称进行输出
confs.append(float(confidence)) # 对frame中识别出来的每一类信息进行最大抑制由参数nms阈值控制
# 对frame中识别出来的每一类信息进行最大抑制由参数nms阈值控制
indices = cv2.dnn.NMSBoxes(bbox, confs, confThreshold, nmsThreshold)
for i in indices:
box = bbox[i] # 依次读取最大已知参数nms阈值的先验框坐标
x, y, w, h = box[0], box[1], box[2], box[3]
# print(x,y,w,h)
# 对每个最终识别的目标进行矩形框选
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 255), 2)
# 对应coco.names相应的类别名称和相似概率进行文字输出
cv2.putText(img, f'{classNames[classIds[i]].capitalize()} {int(confs[i] * 100)}%',
(x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 255), 2)
while True:
# 读取数据
success, frame = cap.read()
# DNN网络的输入图像需要采用称为 blob 的特定格式
blob = cv2.dnn.blobFromImage(frame, 1 / 255, (inpWidth, inpHeight), [0, 0, 0], True, False)
# 将输出的blob作为传入网络的输入
net.setInput(blob)
# 获取输入层的名称
layerNames = net.getLayerNames()
# 获得输入层的最后一层,以此遍历整个网络
outputNames = [layerNames[i - 1] for i in net.getUnconnectedOutLayers()]
outputs = net.forward(outputNames)
findObjects(outputs, frame)
# 显示图像
cv2.imshow("img", frame)
# 等待按键ESC
if cv2.waitKey(10) == 27:
break
# 释放内存
cap.release()
cv2.destroyAllWindows()
结果:
总结
yolov3用来做目标检测的功能还有很多,以后慢慢多分享这类有趣的代码,这篇是初学篇,基本就是官方代码没啥修改和增加。还请多谅解。