卷积神经网络-keras识别数据集代码
目录
- 神经网络与深度学习的历史
-
- tensorflow
- keras
- imageNet
- 经典卷积网络模型
- 深度学习平台
- 映射
-
- 多层卷积核
- 激活函数使用方案
- 正则化手段
-
- Dropout的方法和特点
- 池化
- 卷积网络一般架构
-
- 规则化
- 卷积
- 非线性映射
- 池化
- 模型
- CNN之mnist数据集代码
- 代码运行结果
-
- 第二次卷积用到多少个参数
- 反卷积和空洞卷积
-
- 反卷积应用实例:UNet:图像分割
神经网络与深度学习的历史
Google开源的tensorflow,基于Python,效率不是优先,效果一般
keras对tensorflow进行封装
在使用tensorflow的时候可以使用keras.在使用的时候使用keras先使用训练模型,然后再转化为tensorflow。
Theano现在已经停更。
Torch是LUA写的。很早就存在,因为是用了LUA写的,很多人不愿使用,现在用python封装torch,变成了PyTorch.
tensorflow
要获取计算结果的值要进行session.run,没有指定名字会指定默认名字,不然只能获取变量名字。
keras
import keras
from tensorflow import keras
imageNet
1998 LetNet LeCun 进行数字图像识别 Mnis数据集合 60000张黑白图像
2006年 ML诞生
2009年发表,里面有1000个类别,看谁识别率最高。
2010年SVM
2011 SVM
2012 CNN AlexNet ImageNet数据集合
2016 alohaGO
经典卷积网络模型
AlexNet
VGGNet
GoogLeNet
ResNet
深度学习平台
不要直接安装torch,先下载下来,再进行安装。
映射
图像映射为高维空间上的一个点,也就是一个向量,向量生成图像,就是生成器,判别图像真假是判别器
现在的模型是关注一个特征。
多层卷积核
有两个卷积核有两个通道输出。卷积核之间是不相关的,
如果要对RGB做卷积,会有310 33个卷积核,第一个三是RGB,10是卷积核个数,33是卷积核的尺寸
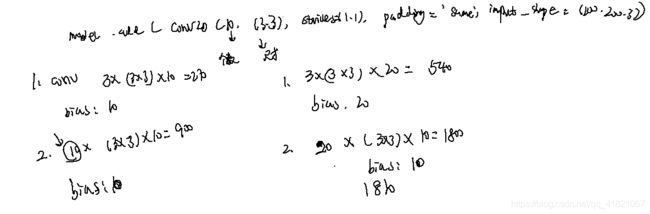
 卷积维度与数据维度有关,与通道数无关。
卷积维度与数据维度有关,与通道数无关。
卷积是一种特殊的全连接
激活函数使用方案
激活函数是非线性。
sigmoid tanh的区别是sigmoid是从0-1,tanh是从-1-1
Relu是小于0的全部为0,
以上全部是递增的,swish和mish小于0的时后是递减的。
网络层数多的时候,mish 函数的正确率还是很高的

上图是一些激活函数的图
正则化手段
1、增加正则项
2、样本、权重增加噪声
例如将256256的图像crop到224224作为网络输入,如果能将污染的数据进行识别,就会避免过拟合
3、Dropout:训练过程中保持部分连接
随机扔掉一部分神经元,在训练数据山防止单元之间共同起作用,隐层的单元不再依赖于其他单元,迫使每一个单元学习到有效的特征。
Dropout的方法和特点
对于每一个训练样本,以概率0.5选择隐层的单元是否有效
几乎每一个输入样本的网络都是不同的,但是有效单元的权重是相同的
输入层也可以采用dropout(0.2)
测试样本下的网络是训练样本得到网络的平均网络
平均网络保证比单个网络的精度更高
配合预处理得到更好的结果
池化
降低输出规模,增加可解释性
光滑数据,避免丢失过多信息
Max/min/mean/random pooling
卷积网络一般架构

规则化
白化,去均值
卷积
维度提升,过完备基
非线性映射
稀疏化,边界消除
池化
特征聚集,降维,光滑
模型
1、sequential
2、model
CNN之mnist数据集代码
x_train,y_train,x_test.y_test
x_train.shape=600002828
y_train.shape=60000,相当于是60000个标签
设置显示值的个数
np.set_printoptions(edgeitems=14,linewidth=1000)
edgeitems才省略号,linewidth才回车
import keras
from keras.models import load_model
from keras.layers import Conv2D,Maxpooling,Flatteen,Dense
from keras.datasets import mnist
from keras.optimizers import Adam,SGD,RMSprop
from keras.losses import categorical_accuracy
from keras.utils import to_categorial
import numpy as np
import cv2
import os
if __name__=='__main__':
np.set_printoptions(edgeitems=14,linewidth=1000)
(x_train,y_train),(x_test,y_test)=mnist.load_data()
#因为输入数据是28*28*60000,对其进行降维,保证输入模型是28*28*1,其中-1代表不计算个数
x_train=x_train.reshape(-1,28,28,1)
# 降低像素值,方便调参
x_train/=255
x_test=x_test.reshape(-1,28,28,1)
x_test/=255
# 将标签值转换为编码
y_train=to_categorical(y_train)
y_test=to_categorical(y_test)
if os.path.exist('mnist_cnn.h5'):
print("加载模型----")
model=load_model()
else:
print("创建并训练模型----")
model=Sequential()
# 增加一个单通道卷积层,卷积核的个数是6,输出一个6通道的值,5*5的 卷积核
# 在输入数据上补了两圈0变成大小为32*32,输出大小是28*28,所以说是valid,默认激活函数是线性激活
#28*28*1
model.add(Conv2D(6,5,stride=(1,1),padding='valid',activation='relu',input_shape=(28,28,1)))
#24*24*6
# 增加池化层
model.add(MaxPooling2D(pool_size=(2,2),padding='valid'))
#12*12*6
# 增加卷积层
model.add(Conv2D(16,5,stride=(1,1),padding='valid',activation='relu',input_shape=(28,28,1)))
#8*8*16
# 增加池化层
model.add(MaxPooling2D(pool_size=(2,2),padding='valid'))
#4*4*16
#拉成向量
model.add(Flatten())
#256
#增加全连接,目标是分为0-9个数字,也就是10个类别
# 256先降维维64
model.add(Dense(64,activation='relu')
#64,softmax可以使得输出是概率分布
model.add(Dense(10,activation='softmax')
#10
# 指定学习率为0.01的优化器,损失函数是交叉熵损失,categorical_accuracy为多分类正确率
model.compile(optimizer=Adam(0.001),loss=categorical_crossentropy,metrics=[categorical_accuracy])
#指定每64个样本做一次梯度下降,训练10轮,shuffle=True是每一次训练完之后对数据做一次改变,验证数据占比0.1,对于这一部分数据不进行训练
history=model.fit(x_train,y_train,batch_size=64,epoch=10,validation_split=0.1,shuffle=True)
# 保存模型为h5文件
model.save('mnist_cnn.h5')
print("history=",history)
print('history.history',history.history)
#查看模型的框架
model.summary()
#y_test_pred包含10000个10维度数组,10维数组的和为1,哪个值大就是哪个数字
y_test_pred=model.predict(x_test)
#输出预测值的最大值
y_test_pred=np.argmax(y_test_pred,axis=1)
#输出真实值的最大值
y_test_fact=np.argmax(y_test,axis=1)
# 返回数组中最大值的索引,axis=1是按行比较,axis=0是按列比较
print("y_test_pred=",y_test_pred)
print("y_test_fact=",y_test_fact)
print('测试集正确率',np.mean(y_test_pred==y_test_fact))
#输入数据和标签,输出损失和精确度.
result=model.evaluate(x_test,y_test)
# result的第一个值是损失,第二个值是准确率
print('测试结果',result)
测试集正确率和测试结果中的正确率是一致的
数据集可以在用户下新建一个.keras/datasets目录,将数据集文件放在下面。
代码运行结果
创建并训练模型----
2021-04-11 17:05:23.066355: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-04-11 17:05:23.068351: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'nvcuda.dll'; dlerror: nvcuda.dll not found
2021-04-11 17:05:23.068794: W tensorflow/stream_executor/cuda/cuda_driver.cc:326] failed call to cuInit: UNKNOWN ERROR (303)
2021-04-11 17:05:23.082325: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic information for host: DESKTOP-2Q7U7V3
2021-04-11 17:05:23.083745: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:176] hostname: DESKTOP-2Q7U7V3
2021-04-11 17:05:23.089421: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-04-11 17:05:34.262158: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
Epoch 1/10
844/844 [==============================] - 50s 51ms/step - loss: 0.5999 - categorical_accuracy: 0.8258 - val_loss: 0.0909 - val_categorical_accuracy: 0.9735
Epoch 2/10
844/844 [==============================] - 38s 45ms/step - loss: 0.1055 - categorical_accuracy: 0.9671 - val_loss: 0.0816 - val_categorical_accuracy: 0.9768
Epoch 3/10
844/844 [==============================] - 38s 45ms/step - loss: 0.0682 - categorical_accuracy: 0.9786 - val_loss: 0.0609 - val_categorical_accuracy: 0.9832
Epoch 4/10
844/844 [==============================] - 38s 45ms/step - loss: 0.0546 - categorical_accuracy: 0.9829 - val_loss: 0.0524 - val_categorical_accuracy: 0.9847
Epoch 5/10
844/844 [==============================] - 38s 45ms/step - loss: 0.0415 - categorical_accuracy: 0.9872 - val_loss: 0.0529 - val_categorical_accuracy: 0.9845
Epoch 6/10
844/844 [==============================] - 38s 45ms/step - loss: 0.0381 - categorical_accuracy: 0.9881 - val_loss: 0.0456 - val_categorical_accuracy: 0.9865
Epoch 7/10
844/844 [==============================] - 38s 45ms/step - loss: 0.0325 - categorical_accuracy: 0.9895 - val_loss: 0.0475 - val_categorical_accuracy: 0.9867
Epoch 8/10
844/844 [==============================] - 37s 44ms/step - loss: 0.0275 - categorical_accuracy: 0.9905 - val_loss: 0.0399 - val_categorical_accuracy: 0.9885
Epoch 9/10
844/844 [==============================] - 37s 44ms/step - loss: 0.0230 - categorical_accuracy: 0.9927 - val_loss: 0.0454 - val_categorical_accuracy: 0.9857
Epoch 10/10
844/844 [==============================] - 37s 44ms/step - loss: 0.0197 - categorical_accuracy: 0.9938 - val_loss: 0.0420 - val_categorical_accuracy: 0.9872
history= <tensorflow.python.keras.callbacks.History object at 0x000001CA9A25EE20>
history.history {'loss': [0.2923012375831604, 0.09467516839504242, 0.06698305159807205, 0.053013093769550323, 0.04492137208580971, 0.03851743042469025, 0.03224554285407066, 0.028370430693030357, 0.025210672989487648, 0.021295215934515], 'categorical_accuracy': [0.9142962694168091, 0.9703148007392883, 0.9788888692855835, 0.9833703637123108, 0.985870361328125, 0.9876111149787903, 0.9895370602607727, 0.9906851649284363, 0.9919999837875366, 0.9930740594863892], 'val_loss': [0.09086272120475769, 0.08156708627939224, 0.060872696340084076, 0.05244652181863785, 0.052887823432683945, 0.045575469732284546, 0.047482121735811234, 0.03989845886826515, 0.04540963098406792, 0.042015641927719116], 'val_categorical_accuracy': [0.9735000133514404, 0.9768333435058594, 0.9831666946411133, 0.984666645526886, 0.984499990940094, 0.9865000247955322, 0.9866666793823242, 0.9884999990463257, 0.9856666922569275, 0.9871666431427002]}
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 24, 24, 6) 156
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 12, 12, 6) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 8, 8, 16) 2416
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 4, 4, 16) 0
_________________________________________________________________
flatten (Flatten) (None, 256) 0
_________________________________________________________________
dense (Dense) (None, 64) 16448
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 19,670
Trainable params: 19,670
Non-trainable params: 0
_________________________________________________________________
y_test_pred= [7 2 1 0 4 1 4 9 5 9 0 6 9 0 ... 3 4 5 6 7 8 9 0 1 2 3 4 5 6]
y_test_fact= [7 2 1 0 4 1 4 9 5 9 0 6 9 0 ... 3 4 5 6 7 8 9 0 1 2 3 4 5 6]
测试集正确率 0.9882
313/313 [==============================] - 4s 12ms/step - loss: 0.0326 - categorical_accuracy: 0.9882
测试结果 [0.032633956521749496, 0.9882000088691711]
Process finished with exit code 0
第二次卷积用到多少个参数
输入 12126,输出8816,用到权重参数是556*16个,偏置是16个
反卷积和空洞卷积
将卷积步长小于1的叫反卷积,区别于空洞卷积,反卷积使图像变大,空洞卷积使得小卷积核的感受野变大,反卷积的卷积核是连续的卷积,空洞卷积不是连续卷积,被卷积的范围增大,也就是增加了感受野。