elasticsearch7.6.2和logstash安装和初步
一、linux安装
参考以下链接:
Linux(centos7)如何部署ElasticSearch7.6.2单节点跟集群(es部署指南)
二、window安装
参考下文更加详细:windows ElasticSearch 7.6.0集群搭建
2.1 下载elasticsearch7.6.2window版
可去官网:
也可去社区:elastic中文社区下载地址
2.2 解压

2.3 节点配置
改elasticsearch7.6.2的配置文件elasticsearch.yml,该文件路径为es1/conf/elasticsearch.yml
2.3.1 节点一
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-1
#必须为本机的IP地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9201
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器IP集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#是否支持跨域,默认为false
http.cors.enabled: true
#当设置允许跨域,默认为*,表示支持所有域名
http.cors.allow-origin: "*"
#指定master
cluster.initial_master_nodes: node-1
2.3.2 节点二
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-2
#必须为本机的IP地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9202
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9302
#设置集群自动发现机器IP集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#是否支持跨域,默认为false
http.cors.enabled: true
#当设置允许跨域,默认为*,表示支持所有域名
http.cors.allow-origin: "*"
#指定master
cluster.initial_master_nodes: node-1
2.3.2 节点三
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-3
#必须为本机的IP地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9203
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9303
#设置集群自动发现机器IP集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#是否支持跨域,默认为false
http.cors.enabled: true
#当设置允许跨域,默认为*,表示支持所有域名
http.cors.allow-origin: "*"
#指定master
cluster.initial_master_nodes: node-1
2.4 分别启动三台机器
进入各自bin目录,执行:
./eslasticsearch
如上方法依次启动三个节点的,启动完成之后可以看到三个节点成功。
成功后使用浏览器进入:127.0.0.1:9200,查看是否成功。
三、Cerebro的使用(未设置账号密码)
本人在window测试环境搭建,es访问和cerebro访问都未设置密码,如果要设置账号密码,可参考此文:Elastic监控工具 - cerebro
3.1 下载window版本cerebro
下载地址:cerebro下载地址
因为我是window版本,下载.zip文件,linux可选择.tgz。
3.2 解压 cerebro-0.8.5.zip
略。
3.3 启动
打开命令行窗口,在cerebro/bin目录,执行
./cerebro
3.4 进入cerebro主页
启动完成之后在浏览器输入: http://localhost:9000/
3.5 在Node Address中输入节点地址
在上图Node Address中输入节点地址,任一节点地址都行:

点击Connect,即可看到当前集群中三个节点状态:
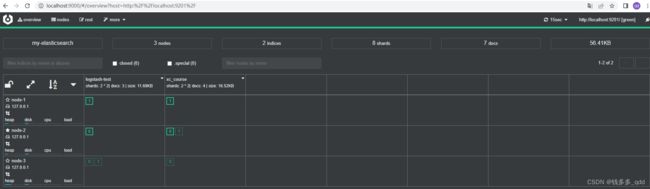
关于cerebro的一些基本功能,后续再详述。
四、logstash安装
4.1 安装及使用
参考文章:
logstash同步数据到es
4.2 我的安装及使用
4.2.1 增加xx.conf
增加logstash-test-log-sync.conf配置:
input {
stdin {}
jdbc {
type => "jdbc"
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/test_db?useUnicode=true&allowMultiQuerie=true&characterEncoding=utf-8&serverTimezone=UTC"
# 数据库连接账号密码;
jdbc_user => "root"
jdbc_password => "root"
# MySQL依赖包路径;
jdbc_driver_library => "E:\Java\Document\m2\repository\mysql\mysql-connector-java\5.1.21\mysql-connector-java-5.1.21.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
#是否开启分页
jdbc_paging_enabled => "true"
#分页条数
jdbc_page_size => "50000"
# 执行的sql 文件路径+名称
#statement_filepath => "/data/my_sql2.sql"
#SQL语句,也可以使用statement_filepath来指定想要执行的SQL
#statement => "SELECT * FROM `user` where id > :sql_last_value"
statement => "SELECT * FROM `user`"
#每一分钟做一次同步
schedule => "* * * * *"
#是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false)
lowercase_column_names => false
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;
use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "id"
# record_last_run上次数据存放位置;
last_run_metadata_path => "E:\\JavaSoftWare\\ES\\logstash-7.6.2\\sql_last_value"
#是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false)
clean_run => false
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
mutate {
remove_field => ["@timestamp","@version"]
}
}
output {
elasticsearch {
# 配置ES集群地址
hosts => ["127.0.0.1:9201","127.0.0.1:9202","127.0.0.1:9203"]
# 索引名字,必须小写
index => "logstash-test"
#数据唯一索引(建议使用数据库KeyID)
document_id => "%{id}"
}
stdout {
}
}
4.2.2 执行命令
执行命令:
./logstash -f ../conf/logstash-test-log-sync.conf
下面是我执行过程中遇到的报错日志,以及解决方法,逐一列出,希望对诸君有用。
4.2.2.1 报错一:

解决方法:把logstash-test-log-sync.conf配置字符集需要UTF-无BOM 保存。
参考文章:Elasticsearch解决分页慢以及日志整合监控的方案
4.2.2.2 报错二:
继续执行:
./logstash -f ../conf/logstash-test-log-sync.conf
报错如下:
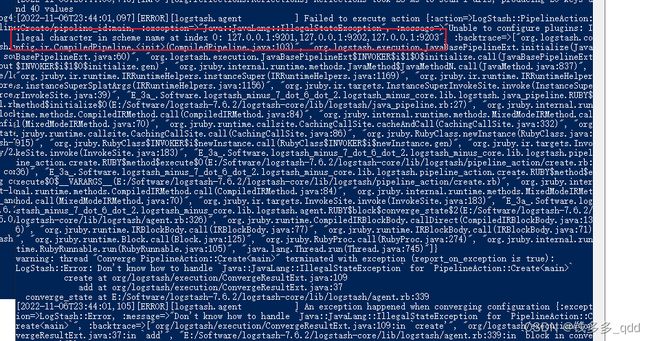
原因:es集群地址填写不对。
解决方法:如下地址填写正确:
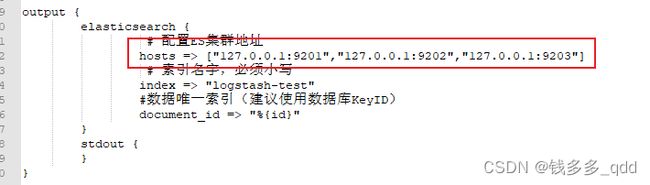
4.2.2.3 报错三
不是报错,是卡在这里一致不执行,我设置的是默认,一分钟执行一次:

4.2.2.4 报错四

原来是mysql链接错误,改为:

4.3 结果
最终logstash执行成功。
查看执行结果:

五、es的demo
5.1 spring-boot-starter-data-elasticsearch(基于es 5.1)
优点:
- 封装了很多通用方法以及注解式操作简化了开发流程。
- 与springBoot 集成更快速。
缺点:
- elasticsearch官方更新的版本速度太快,而springboot速度明显略慢。
- elasticsearch随着版本升级API略有变化,spring-data-elasticsearch容易遇到版本不兼容问题。
5.1.1 引入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
<version>2.1.0.RELEASEversion>
dependency>
5.1.2 配置
spring:
data:
elasticsearch:
cluster-name: my-elasticsearch
cluster-nodes: 127.0.0.1:9301,127.0.0.1:9302,127.0.0.1:9303
5.1.3 创建实体类
@Data
@ToString
@Document(indexName = "global_search_index",type = "global_search")
public class ESGlobalSearch implements Serializable {
/**
* ID,唯一字段
*/
@Id
@Field(type= FieldType.Keyword,store = true)
private String id;
/**
* 主题(搜索关键字)
*/
@Field(type = FieldType.Text,store = true,analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")
private String title;
/**
* 主题副本(提高搜索精度)
*/
@Field(type = FieldType.Text,store = true,analyzer = "standard")
private String roughTitle;
/**
* 标签(预留字段,搜索扩展)
*/
@Field(type = FieldType.Text,store = true,analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")
private String label;
/**
* 内容(预留字段)
*/
@Field(type = FieldType.Text,store = true,analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")
private String content;
/**
* 应用类型(1.医生;2.医院;3.应用)
*/
@Field(type = FieldType.Integer,store = true)
private Integer applicationType;
/**
* 应用类型信息
*/
@Field(type = FieldType.Text,store = true)
private String applicationInfo;
}
5.1.4 创建xxRepository
public interface ESGlobalSearchMapper extends ElasticsearchRepository<ESGlobalSearch,String> {
/**
* 根据标题检索
* @param title
* @param roughTitle
* @return
*/
List<ESGlobalSearch> findByTitleOrRoughTitle(String title, String roughTitle);
}
5.1.5 测试
@SpringBootTest(classes = EsApplication.class)
@RunWith(SpringRunner.class)
public class EsGlobalSearchTest {
@Autowired
ESGlobalSearchMapper esGlobalSearchMapper;
@Test
public void saveTest(){
ESGlobalSearch esGlobalSearch = new ESGlobalSearch();
esGlobalSearch.setApplicationInfo("1");
esGlobalSearch.setApplicationType(1);
esGlobalSearch.setContent("测试Content");
esGlobalSearch.setId("1");
esGlobalSearch.setLabel("测试Label");
esGlobalSearch.setRoughTitle("测试");
esGlobalSearch.setTitle("测试title");
ESGlobalSearch save = esGlobalSearchMapper.save(new ESGlobalSearch());
}
@Test
public void findAllTest(){
Iterable<ESGlobalSearch> iter = esGlobalSearchMapper.findAll();
for (ESGlobalSearch esGlobalSearch : iter) {
System.out.println(esGlobalSearch);
}
}
/**
* 它可以根据名称,自动实现功能
*/
@Test
public void findByTitleOrRoughTitle(){
List<ESGlobalSearch> list = esGlobalSearchMapper.findByTitleOrRoughTitle("张", "张");
for (ESGlobalSearch esGlobalSearch : list) {
System.out.println(esGlobalSearch);
}
}
/**
* 基本查询
*/
@Test
public void testQuery(){
// 词条查询
MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "周国岭");
//执行查询
Iterable<ESGlobalSearch> items = this.esGlobalSearchMapper.search(queryBuilder);
items.forEach(item -> System.out.println(item));
}
@Test
public void testFuzzyQuery(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withQuery(QueryBuilders.fuzzyQuery("title","杭州"));
Page<ESGlobalSearch> page = this.esGlobalSearchMapper.search(queryBuilder.build());
List<ESGlobalSearch> list = page.getContent();
list.forEach(esGlobalSearch -> System.out.println(esGlobalSearch));
}
/**
* es分页处理
*/
@Test
public void testNativeQuery2(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本的分词查询
queryBuilder.withQuery(QueryBuilders.termQuery("title", "杭州"));
queryBuilder.withQuery(QueryBuilders.matchAllQuery());
// 初始化分页参数
int page = 0;
int size = 3;
// 设置分页参数
queryBuilder.withPageable(PageRequest.of(page, size));
// 执行搜索,获取结果
Page<ESGlobalSearch> pages = this.esGlobalSearchMapper.search(queryBuilder.build());
// 打印总条数
System.out.println(pages.getTotalElements());
// 打印总页数
System.out.println(pages.getTotalPages());
// 每页大小
System.out.println(pages.getSize());
// 当前页
System.out.println(pages.getNumber());
List<ESGlobalSearch> list = pages.getContent();
list.forEach( esGlobalSearch -> System.out.println(esGlobalSearch));
}
/**
* 排序
*/
@Test
public void testSort(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//查询全部
queryBuilder.withQuery(QueryBuilders.matchAllQuery());
// 初始化分页参数
int page = 0;
int size = 3;
// 设置分页参数
queryBuilder.withPageable(PageRequest.of(page, size));
queryBuilder.withSort(SortBuilders.fieldSort("id").order(SortOrder.DESC));
// 执行搜索,获取结果
Page<ESGlobalSearch> pages = this.esGlobalSearchMapper.search(queryBuilder.build());
List<ESGlobalSearch> list = pages.getContent();
list.forEach( esGlobalSearch -> System.out.println(esGlobalSearch));
}
@Test
public void testBooleanQuery() {
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
builder.withQuery(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("title", "周国岭"))
.must(QueryBuilders.termQuery("roughTitle", "周国岭"))
);
Page<ESGlobalSearch> list = this.esGlobalSearchMapper.search(builder.build());
for (ESGlobalSearch item : list) {
System.out.println(item);
}
}
}
5.1.6 更多查询
简介
spring data elsaticsearch提供了三种构建查询模块的方式:
基本的增删改查:继承spring data提供的接口就默认提供
接口中声明方法:**无需实现类。**spring data根据方法名,自动生成实现类,方法名必须符合一定的规则
接口只要继承 ElasticsearchRepository 类即可。默认会提供很多实现,比如 CRUD 和搜索相关的实现。类似于 JPA 读取数据。
支持的默认方法有:
count(), findAll(), findOne(ID), delete(ID), deleteAll(), exists(ID), save(DomainObject), save(Iterable)。
接口的命名是遵循规范的。常用命名规则如下:
表格内容摘自官网(官方文档:传送门)
| 关键字 | 方法命名 | Elasticsearch查询DSL语法示例 |
|---|---|---|
| And | findByNameAndPrice | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “?”, “fields” : [ “name” ] } }, { “query_string” : { “query” : “?”, “fields” : [ “price” ] } } ] } }} |
| Or | findByNameOrPrice | { “query” : { “bool” : { “should” : [ { “query_string” : { “query” : “?”, “fields” : [ “name” ] } }, { “query_string” : { “query” : “?”, “fields” : [ “price” ] } } ] } }} |
| Is | findByName | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “?”, “fields” : [ “name” ] } } ] } }} |
| Not | findByNameNot | { “query” : { “bool” : { “must_not” : [ { “query_string” : { “query” : “?”, “fields” : [ “name” ] } } ] } }} |
| Between | findByPriceBetween | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : ?, “to” : ?, “include_lower” : true, “include_upper” : true } } } ] } }} |
| LessThan | findByPriceLessThan | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : null, “to” : ?, “include_lower” : true, “include_upper” : false } } } ] } }} |
| LessThanEqual | findByPriceLessThanEqual | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : null, “to” : ?, “include_lower” : true, “include_upper” : true } } } ] } }} |
| GreaterThan | findByPriceGreaterThan | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : ?, “to” : null, “include_lower” : false, “include_upper” : true } } } ] } }} |
| GreaterThanEqual | findByPriceGreaterThan | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : ?, “to” : null, “include_lower” : true, “include_upper” : true } } } ] } }} |
| Before | findByPriceBefore | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : null, “to” : ?, “include_lower” : true, “include_upper” : true } } } ] } }} |
| After | findByPriceAfter | { “query” : { “bool” : { “must” : [ {“range” : {“price” : {“from” : ?, “to” : null, “include_lower” : true, “include_upper” : true } } } ] } }} |
| Like | findByNameLike | |
| StartingWith | findByNameStartingWith | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “?*”, “fields” : [ “name” ] }, “analyze_wildcard”: true } ] } }} |
| EndingWith | findByNameEndingWith | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “*?”, “fields” : [ “name” ] }, “analyze_wildcard”: true } ] } }} |
| Contains/Containing | findByNameContaining | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “?”, “fields” : [ “name” ] }, “analyze_wildcard”: true } ] } }} |
| In (when annotated as FieldType.Keyword) | findByNameIn(Collectionnames) | { “query” : { “bool” : { “must” : [ {“bool” : {“must” : [ {“terms” : {“name” : [“?”,“?”]}} ] } } ] } }} |
| In | findByNameIn(Collectionnames) | { “query”: {“bool”: {“must”: [{“query_string”:{“query”: “”?" “?”", “fields”: [“name”]}}]}}} |
| NotIn | (when annotated as FieldType.Keyword) | findByNameNotIn(Collectionnames) { “query” : { “bool” : { “must” : [ {“bool” : {“must_not” : [ {“terms” : {“name” : [“?”,“?”]}} ] } } ] } }} |
| NotIn | findByNameNotIn(Collectionnames) | {“query”: {“bool”: {“must”: [{“query_string”: {“query”: “NOT(”?" “?”)", “fields”: [“name”]}}]}}} |
| Near | findByStoreNear | Not Supported Yet ! |
| True | findByAvailableTrue | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “true”, “fields” : [ “available” ] } } ] } }} |
| False | findByAvailableFalse | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “false”, “fields” : [ “available” ] } } ] } }} |
| OrderBy | findByAvailableTrueOrderByNameDesc | { “query” : { “bool” : { “must” : [ { “query_string” : { “query” : “true”, “fields” : [ “available” ] } } ] } }, “sort”:[{“name”:{“order”:“desc”}}] } |
按接口的命名方法示例:
如 5.1.4
5.1.7 创建索引
@SpringBootTest(classes = EsApplication.class)
@RunWith(SpringRunner.class)
public class EsXcCourseTest {
@Autowired
ElasticsearchTemplate elasticsearchTemplate;
@Test
public void createIndex(){
// 创建索引,会根据Item类的@Document注解信息来创建
boolean createFlag = elasticsearchTemplate.createIndex(EsXcCourse.class);
System.out.println("####:"+createFlag);
// 配置映射,会根据Item类中的id、Field等字段来自动完成映射
elasticsearchTemplate.putMapping(EsXcCourse.class);
}
}
5.1.8 高级查询
Data ElasticSearch 支持了一些常见的查询
但是一些高级查询呢?可以使用类组装DSL语法支持
/**
* 聚合查询-groupBy
* 聚合所有的年龄
*/
@Test
public void groupByAge() {
//1.构建查询对象
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("groupByAge")
.field("age").size(30));
SearchHits<EmployeeInfo> search = elasticsearchRestTemplate.search(nativeSearchQueryBuilder.build(), EmployeeInfo.class);
Aggregations aggregations = search.getAggregations();
//解析聚合分组后结果数据
ParsedLongTerms parsedLongTerms = aggregations.get("groupByAge");
//groupBy后的年龄集
List<String> ageList = parsedLongTerms.getBuckets().stream().map(Terms.Bucket::getKeyAsString).collect(Collectors.toList());
System.out.println(ageList);
}
/**
* 分页查询
* 带参数
*/
@Test
public void listPageMatch() {
int pageNo = 1;
int pageSize = 5;
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.withQuery(QueryBuilders.matchQuery("name", "小"));
//注:Pageable类中 pageNum需要减1,如果是第一页 数值为0
Pageable pageable = PageRequest.of(pageNo - 1, pageSize);
nativeSearchQueryBuilder.withPageable(pageable);
SearchHits<EmployeeInfo> searchHitsResult = elasticsearchRestTemplate.search(nativeSearchQueryBuilder.build(), EmployeeInfo.class);
//7.获取分页数据
SearchPage<EmployeeInfo> searchPageResult = SearchHitSupport.searchPageFor(searchHitsResult, pageable);
System.out.println("分页查询");
System.out.println(String.format("totalPages:%d, pageNo:%d, size:%d", searchPageResult.getTotalPages(), pageNo, pageSize));
System.out.println(JSON.toJSONString(searchPageResult.getSearchHits(), SerializerFeature.PrettyFormat));
}
5.1.9 gitee地址
传送门
5.1.10 参考文章:
SpringBoot-starter-data整合Elasticsearch
5.2 elasticsearch-rest-high-level-client
5.2.1 引入依赖
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>7.6.2version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-clientartifactId>
<version>7.6.2version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.6.2version>
dependency>
5.2.2 配置
yml配置:
elasticsearch:
hostlist: ${eshostlist:127.0.0.1:9201,127.0.0.1:9202,127.0.0.1:9203,} #多个结点中间用逗号分隔
配置类:
@Slf4j
@Configuration
public class ElasticsearchConfig {
@Value("${elasticsearch.hostlist}")
private String hostlist;
@Bean
public RestHighLevelClient restHighLevelClient(){
//解析hostlist配置信息
String[] split = hostlist.split(",");
//创建HttpHost数组,其中存放es主机和端口的配置信息
HttpHost[] httpHostArray = new HttpHost[split.length];
for(int i=0;i<split.length;i++){
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http");
}
//创建RestHighLevelClient客户端
return new RestHighLevelClient(RestClient.builder(httpHostArray));
}
//项目主要使用RestHighLevelClient,对于低级的客户端暂时不用
@Bean
public RestClient restClient(){
//解析hostlist配置信息
String[] split = hostlist.split(",");
//创建HttpHost数组,其中存放es主机和端口的配置信息
HttpHost[] httpHostArray = new HttpHost[split.length];
for(int i=0;i<split.length;i++){
String item = split[i];
httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http");
}
return RestClient.builder(httpHostArray).build();
}
}
5.2.3 操作
@RestController
@RequestMapping("/demo")
@Slf4j
public class DemoController {
@Autowired
RestHighLevelClient restHighLevelClient;
@RequestMapping("/test")
public String test() throws IOException {
// 1 创建检索请求
SearchRequest searchRequest = new SearchRequest("xc_course");
// 指定索引
//searchRequest.indices("global_search_index");
// 构造检索条件 DSL
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
/*sourceBuilder.query(); 匹配查询
sourceBuilder.from(); 分页查询 from 起始,size 尺寸
sourceBuilder.size();
sourceBuilder.aggregation(); 聚合
*/
//全文检索
//MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("name", "java");
//精准搜索
//TermQueryBuilder queryBuilder = QueryBuilders.termQuery("name", "java");
TermQueryBuilder queryBuilder=QueryBuilders.termQuery("studymodel","201002");
sourceBuilder.query(queryBuilder);
System.out.println(sourceBuilder.toString());
searchRequest.source(sourceBuilder);
// 2 执行检索
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 3 分析响应结果
System.out.println("========:"+response.toString());
return response.toString();
}
@RequestMapping("/test2")
public String test2() throws IOException {
// 1 创建检索请求
SearchRequest searchRequest = new SearchRequest("xc_course");
// 指定索引
//searchRequest.indices("global_search_index");
// 构造检索条件 DSL
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//TermQueryBuilder queryBuilder=QueryBuilders.termQuery("studymodel","201002");
MatchAllQueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(queryBuilder);
System.out.println(sourceBuilder.toString());
searchRequest.source(sourceBuilder);
// 2 执行检索
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 3 分析响应结果
System.out.println("========:"+response.toString());
return response.toString();
}
@RequestMapping("/test3")
public String test3() throws IOException {
// 1 创建检索请求
SearchRequest searchRequest = new SearchRequest("logstash-test");
// 指定索引
//searchRequest.indices("global_search_index");
// 构造检索条件 DSL
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//TermQueryBuilder queryBuilder=QueryBuilders.termQuery("studymodel","201002");
MatchAllQueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(queryBuilder);
System.out.println(sourceBuilder.toString());
searchRequest.source(sourceBuilder);
// 2 执行检索
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 3 分析响应结果
System.out.println("========:"+response.toString());
return response.toString();
}
}
5.2.3 gitee地址
传送门
5.2.4 参考文章:
参考文章
elasticsearch-rest-high-level-client操作
六、使用对应的ik分词器
analyzer [ik_smart] not found for field [name]
七、ES内存设置
ES默认安装后设置的内存是1GB,对任何一个现实业务来说,这个设置太小了。如果是通过解压安装的ES,则在es安装文件中包含一个jvm.option文件,添加如下命令来设置ES的堆大小,Xms表示堆的初始大小,Xms表示可分配的最大内存,都是1GB。
确保 Xmx 和 Xms 的大小是相同的,其目的是为了能够在 Java 垃圾回收机制清理完 堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力。 假设你有一个 64G 内存的机器,按照正常思维思考,你可能会认为把 64G 内存都给 ES 比较好,但现实是这样吗, 越大越好?虽然内存对 ES 来说是非常重要的,但是答案 是否定的! 因为 ES 堆内存的分配需要满足以下两个原则:
- 不要超过物理内存的 50%:Lucene 的设计目的是把底层 OS 里的数据缓存到内存中。 Lucene
的段是分别存储到单个文件中的,这些文件都是不会变化的,所以很利于缓存,同时操作系 统也会把这些段文件缓存起来,以便更快的访问。如果我们设置的堆内存过大,Lucene 可用的内存将会减少,就会严重影响降低 Lucene 的全文本查 询性能。 - 堆内存的大小最好不要超过 32GB(总内存64G):在 Java 中,所有对象都分配在堆上,然后有一个 Klass Pointer 指 针指向它的类元数据。 这个指针在 64 位的操作系统上为 64 位,64 位的操作系统可以使用更多的内存(2^64)。在 32 位 的系统上为 32 位,32 位的操作系统的最大寻址空间为 4GB(2^32)。 但是 64 位的指针意味着更大的浪费,因为你的指针本身大了。浪费内存不算,更糟糕的是,更大的 指针在主内存和缓存器(例如 LLC, L1 等)之间移动数据的时候,会占用更多的带宽。 最终我们都会采用 31 G 设置 -Xms 31g -Xmx 31g 。
- 假设你有个机器有 128 GB 的内存,你可以创建两个节点,每个节点内存分配不超过 32 GB。 也就是说 不超过 64 GB 内存给 ES 的堆内存,剩下的超过 64 GB 的内存给 Lucene。
参考文章:
ES的内存设置
ElasticSearch系列(七)es内存大小设置
八、其他的参考文章
这些参考文章也很重要,烦请诸君有空一定要看:
ES的内存设置
使用Logstash来实时同步MySQL数据到ES
使用LOGSTASH 将数据导入到ES
logstash同步数据到es
Logstash 从Mysql同步数据到ES
ES数据类型