Bert预训练模型
之前的:基于特征(feature-based)ELMO 预训练的表示作为附加特征
基于微调( fine-tuning)GPT
BERT(Bidirectional Encoder Representation from Transformers)
2018年提出基于深层transformer的预训练语言模型。
利用无标注文本挖掘语义信息
BERT_BASE (L=12, H=768, A=12, Total Param-
eters=110M) and BERT_LARGE (L=24, H=1024,
A=16, Total Parameters=340M).
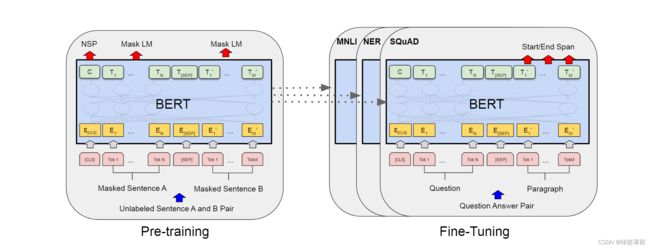
1.Bert建模方法
两个预训练任务:MLM(掩码语言模型),NSP(下一个句子预测)
输入表示由三部分组成

位置向量+块向量+词向量
(1)词向量:通过词向量矩阵将输入文本转换成实值向量表示。
假设输入序列x对应的独热向量表示为
et∈RNx|V|
其对应的词向量表示vt为:
vt=etWt
Wt∈R|V|xe :表示可以训练的词向量矩阵,|V|表示词表大小;e表示词向量的维度。
(2)块向量(segment)
编码当前词属于哪一块,当前词所在块的序号(从0开始)
输入序列是单个块(单句文本分类),所有词的块编码为0
输入是两个块(句对文本分类),第一句每个字对应块编码为0,第二句每个词对应为1
[CLS],[SEP]开始和结束对应块编码均为0
利用可训练的块向量矩阵Ws∈R|S|xe(|S|:块数量,e表示块向量维度)将块编码es∈RNx|S|转换为实值向量得到块向量:vs:
vs=esWs
(3)位置向量
位置向量编码每个词的绝对位置,将输入序列中每个词按照其下标顺序依次转换成位置独热编码,然后利用位置向量矩阵Wp∈RNxe(N:最大长度,e:位置向量的维度)将独热码ep∈RNxN转换成实值向量,得到位置向量vp:
vp=epWp
bert采用自编码的预训练任务进行训练
基本预训练任务
1.掩码语言模型 (MLM)
类似完形填空,部分单词掩码
(1)输入层
原文本:x1x2…xn
掩码后文本:x’1x’2…x’n
处理后:X = [CLS]x’1x’2…x’n[SEP]
长截短补
得v=位置向量+块向量+词向量
(2)BERT编码层
得到上下文语义表示h
h[l] = Transformer-Block(h[l-1]), 任意l 属于{1,2,…,L}
表示第l层Transformer的隐含层输出,规定h[0]=v
(3)输出层·
预测已经掩码的位置
从h中抽取出掩码的表示,并且将这些表示拼接得到掩码表示hm
利用词向量矩阵W将掩码表示h映射到词表空间
计算掩码位置在对应词表上的概率分布Pi
Pi = Softmax(hmiWtT + bo)
Pi 与·标签yi (原单词的xi的独热向量表示),计算交叉熵损失,学习模型参数
下一个句子预测(NSP)
构建两段文本之间的关系 ,判断句子B是否是句子A的下一个句子
正样本:来自自然文本中相邻的两个句子,构成“下一个句子”关系
负样本:构成“非下一个句子”
(1)输入层
给定的经过掩码处理后的输入文本
x(1) = x(1)1x(1)2…x(1)n ,
x(2) =x(2)1x(2)2…x(2)m ,
Bert输入表示v:
X = [CLS]x(1) = x(1)1x(1)2…x(1)n[SEP] x(2) =x(2)1x(2)2…x(2)m[SEP]
v = 位置向量+块向量+词向量
(2)BERT编码层
h[l] = Transformer-Block(h[l-1]), 任意l 属于{1,2,…,L}
(3)输出层
与MLM不同,NSP只需要判断输入文本x(2)是否为x(1)下一句,因此,在NSP中BERT使用[CLS]位的隐含层表示进行分类预测。
[CLS]位的隐含层表示由上下文语义表示h的首个分量 h0构成。
得到h0之后,预测输入文本的分类概率P
P = Softmax(h0 Wp + bo)
得到分类概率P后,与真实标签y计算交叉熵损失,学习模型参数。
参考:自然语言处理