PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud论文解读
前言
PointRcnn的动机?
(1)

将点云投影到鸟瞰图或者正面图,又或者投射到体素中,效率比较低下,并且在量化过程中会遭受信息损失。
(2)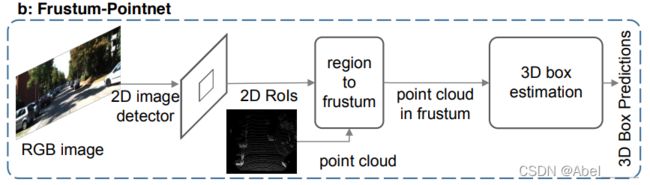
F-Pointnet根据2D RGB检测结果裁剪出的截锥点云估计出三维包围盒,该方法严重依赖于二维检测性能,无法利用三维信息的优势生成鲁棒的包围盒建议。
根据(1)(2)作者提出了PointRCNN:分为两个阶段
第一阶段是自下而上生成3D bounding box 提案
第二阶段进行规范的3D框优化
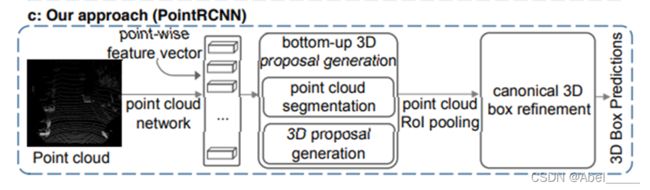
方法论
 PointRCNN的框架图
PointRCNN的框架图
它的第一阶段Stage1:
- 点云学习是通过PointNet++提取全局点云的特征(也可以用VoxelNet)
输入是(bs(batch size), n, 3)的点云,输出是(bs, n, 128)的特征
- 逐点的进行前景点分割
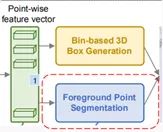
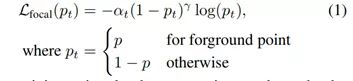
提取特征后,然后接了一个前景点分割网络(蓝色)和一个bin-based box生成网络(黄色)。一是前景点分割,二是生成预测框。分别得到1维向量和76维向量。
前景点分割网络,是由两个卷积层组成。输入是那个(bs, n, 128)的特征,输出是(bs, n, 1)的mask。1表示这个点属于前景点的概率,值越大,则它属于前景点的概率越高。加一个sigmoid限制到(0,1),然后用focal loss计算损失。
1.通过sigmoid函数将值映射到(0,1),设定阈值分割前景点
2.由于前景点的数量通常远小于背景点的数量,因此使用该函数来解决样本不均衡的问题。
- Bin-based 3D bounding box 的生成
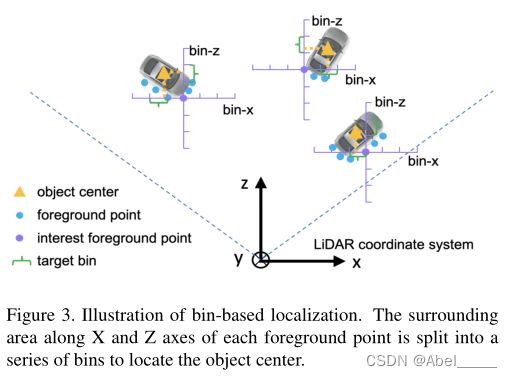
首先我们要了解什么是bin?
bin在上图中用绿色大括号表示,就相当于直尺上的刻度,作者这里设置,在x和z上的bin的大小为0.5m,θ则是将2π划分为12个bin。
基于bin的预测,是预测每个前景点对于bounding box中心点的偏移,偏移了几个bin,还需要预测中心点坐标在一个bin中的偏移量res,知道每个点对于中心点的偏移量之后,加上已知这个点本身的坐标,就可以得到中心点的坐标。
box生成网络,也是由两个卷积层组成。输入是那个(bs, n, 128)的特征,输出是(bs, n, 76)。
下图表示的是由76维的向量预测框,前12维预测x方向上的bin,12-24预测z方向上的bin,24-36预测x方向的残差res,36-48预测z方向的残差res,48-49预测y方向的距离,49-61预测角度的bin,61-73预测角度上的残差res,73-76对长宽高做出预测。基于bin的预测参数x,z,θ,我们首先选择具有最高预测信度的bin中心,并添加预测残差以获得重新定义的参数。其他参数则没有使用基于bin的预测方法。
知道每个点对于中心点的偏移量之后,加上已知这个点本身的坐标,就可以得到中心点的坐标。
由于y轴是垂直于地面,不用基于bin的预测。

此公式为计算偏差的公式。其中(x(p),y(p), z(p))是感兴趣的前景点的坐标,(xp,yp, zp)是其相应目标的中心坐标,bin(p)x和bin(p)z是沿X和Z轴的ground-truth bin assignments。 res(p)x和res(p)z是ground-truth residual,可用于在assigned bin中进一步细化位置,C是归一化的bin长度。S是前景点的search range,每个1D search range均分为相同长度δ的bin,以表示X-Z平面上不同目标的中心(x,z)。
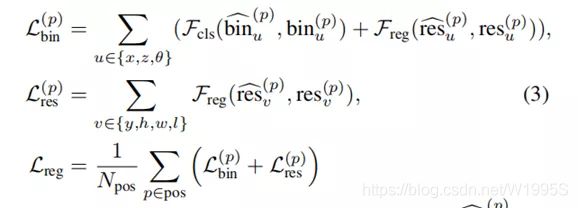
3D bounding box 的损失,其中Npos是前景点的数量,bin^(p)u是预测的bin assignments,res^(p)u是前景点p的残差,bin(p)u和res(p)u是ground-truth目标 按照上面的公式(2)计算的实际偏差,Fcls表示交叉熵分类损失,Freg表示平滑的L1损失。
- 基于BEV图做NMS去除冗余的bounding box,训练阶段只保留300个进入stage-2
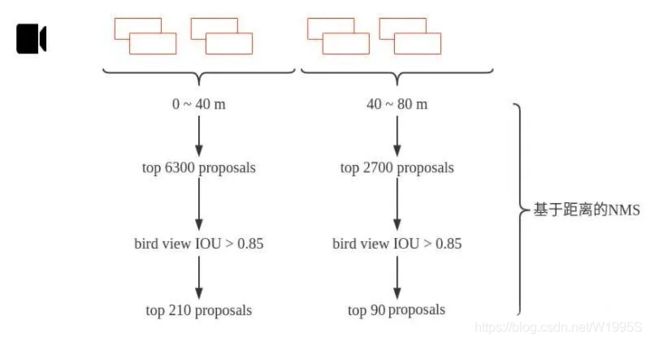
来解释一下上面的方法,训练时在相机0~40m距离内的bounding box,先取得分类得分最高的6300个,然后计算bird view IOU,把IOU大于0.85的都删掉,到这里bounding box 又少了一点。然后再取得分最高的210个。在距离相机40~80m的范围内用同样的方法取90个。这样第一阶段结束的时候只剩下300个bounding box了。
300个bounding box也还是很多。于是有了第二阶段置信度打分和bounding box优化。
而在实际预测时,使用具有IOU阈值0.8的定向NMS,并且只保留前100个bounding box。
第二阶段stage2:
把在每个bounding box proposal 内部的点聚集起来(池化),就得到大小为(bs,m,512,c)的数据。其中bs表示batch size, m表示每个batch中有多少个bounding box(这里减少冗余后剩下128), 512表示每个bounding box里面有多少个point。
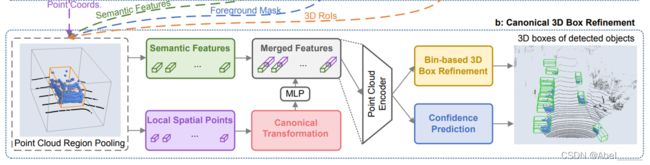
- 每个proposal的池化点及其特征都被喂入stage-2中,用来微调3D框的位置及其前景目标置信度
- 点云区域池的操作
1.放大它以创建新的三维长方体
2.判断是否每个点p,是否都在扩大的边界框内,若在则保留特征![]()
- Canonical 变换

①坐标系的中心点是proposal的center
②X ′ ,Z ′ 轴平行于地平面,X ′轴指向proposals的heading方向,Z ′ 轴垂直于X ′轴;
③Y′轴与LiDAR坐标系保持一致
使用canonical可以更好地了解每个方案的局部空间特征。
- 全局语义特征和坐标规范后得特征进行融合
- box proposal 优化

规范坐标系,预测b~i 和 真实b~gt i 分别为:




以与等式(2)相同的方式设置,不同之处在于我们使用较小的搜索范围S来细化3D提案的位置
- 第二阶段总体损失
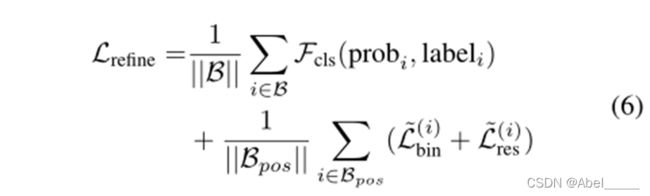
其中B是来自阶段1的3D proposals集合,Bpos存储了回归的positive proposals (正样本),probi是~bi的估计置信度,而labeli是相应的标签,Fcls是用于监督预测信度的交叉熵损失,~Lbin和 ~Lres类似于公式(3)中的 Lpbin和 Lpres。如上所述由~bi和 ~bgti计算的新目标。
实验
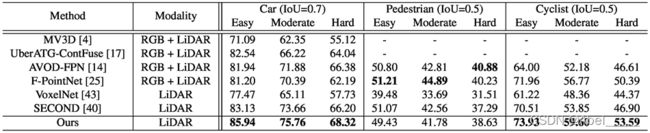
通过提交到官方测试服务器,将KITTI测试分割的3D对象检测与以前的方法进行性能比较,评估指标是平均精度(AP),汽车的阈值是0.7,行人/自行车的阈值是0.5

在KITTI val分割集的汽车类别上3D对象检测与先前的方法的性能比较
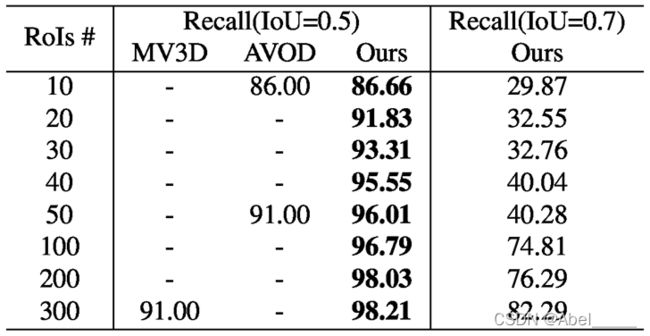 不同框的数量以及不同阈值下的3D边界框的召回。
不同框的数量以及不同阈值下的3D边界框的召回。
消融实验

改进网络的不同输入组合的性能,APE,APM,APH分别表示KITTI val split上的简单,中等,困难的平均精度。CT表示规范变换。结果表明规范变换对精度有很大提升。
 采用上下文感知点云池的不同上下文宽度η,结果表明本文提出的框架在η=1.0m时取得了最佳的性能。
采用上下文感知点云池的不同上下文宽度η,结果表明本文提出的框架在η=1.0m时取得了最佳的性能。
结论
1.点云自底向上生成三维提案,避免在3D空间中使用大量预定义的3D框,并且显著限制了生成的3D提案的搜索空间,比以往的提案生成方法具有更高的召回率
2.特征融合文章使用two-stage的方法,在proposal的过程中,每个个三维点都回归一个proposal,使得理论上所有的box都能够被找到
3.结合了前景点分割来预测框