真*零基础入门CV--街景字符识别(阿里天池学习赛)
最新玩了一下阿里天池学习赛(当调参侠),觉得街景字符识别这个比赛还是对新手相对友好的,感兴趣的可以去参加。
传送门:https://link.zhihu.com/?target=https%3A//tianchi.aliyun.com/competition/entrance/531795/introduction
下面大概记录一下我大概的操作以及心得:
简介
首先看它们的数据组成以及特点,链接比赛里面的论坛的Task1-5是对这个比赛大致的讲解,大家可以先去看看。总的来说,train是3W张,val是1W张,test是4W张。里面都是数字,有1个,2个…6个数字组成,你要把它们识别出来,以准确率为衡量标准,大概就是这样了。
思路:这个比赛思路总的来说一般有两个:1.目标检测,2.分类网络。看了论坛的分享,貌似用了YOLO系列的都在90分以上,这非常吸引人,但是我觉得我们参加这个学习赛是为了学习东西,而且基础都是一般的人,(好的,其实是说我自己),所以我打算从分类网络学习起,一是思路相对简单且易懂,代码也是如此,所以比较容易入门,因此这次我只说分类网络。
操作步骤:
1.下载数据集,以及解压。
我刚开始参加的时候,也不太清楚如何下载数据集以及论坛也有人说自己下载的数据集不齐,所以这就是常说的si在了第一步。我捣鼓了一天了才发现有如下代码可以下载,而且自动解压,非常方便。
首先得报名,报了名才可以下载数据集。在这里下载

然后就执行这一段代码
import pandas as pd
import os
import requests
import zipfile
import shutil
links = pd.read_csv('/content/mchar_data_list_0515.csv')
dir_name = 'NDataset'
mypath = '/content/'
if not os.path.exists(mypath + dir_name):
os.mkdir(mypath + dir_name)
for i,link in enumerate(links['link']):
file_name = links['file'][i]
print(file_name, '\t', link)
file_name = mypath + dir_name + '/' + file_name
if not os.path.exists(file_name):
response = requests.get(link, stream=True)
with open( file_name, 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
zip_list = ['mchar_train', 'mchar_test_a', 'mchar_val']
for little_zip in zip_list: # 卖萌可耻
if not os.path.exists(mypath + dir_name + '/' + little_zip):
zip_file = zipfile.ZipFile(mypath + dir_name + '/' + little_zip + '.zip', 'r')
zip_file.extractall(path = mypath + dir_name )
if os.path.exists(mypath + dir_name + '/' + '__MACOSX'):
shutil.rmtree(mypath + dir_name + '/' + '__MACOSX')
links就是刚刚下载的文件,改成你们本地相对位置就好了,然后就执行,无脑等待
执行完之后就会有如下东西,

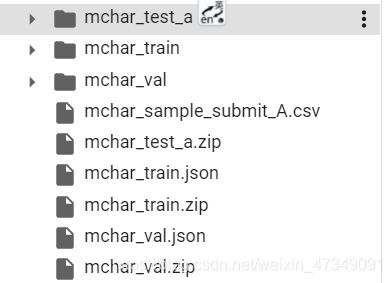
这时候第一步就完成了。
2.使用官方的baseline
传送门:https://link.zhihu.com/?target=https%3A//tianchi.aliyun.com/notebook-ai/detail%3FpostId%3D108342
这个代码是官方给的baseline顺利执行完,结果应该能达到56分左右,想要高分当然需要自己做修改,不然这个比赛就没意义了。

官方代码没有多大问题,跟着无脑执行就可以了,训练的时候也没问题,到检测的时候我就si了。执行test的时候,它提示我没有testa.json文件,我回头一看,对哦,只有train.json,val.json文件,妈耶,真的少了这个文件吗。然后我去论坛找了,发现有个老哥也是发了帖子问在哪可以找test_a.json文件,然后官方回复不提供,我就想原来找到了就可以了提交了,然后我句一直在搜索如何找到这个文件,一直都没找到(找了一段时间了…)。(难道你们还没发现哪里不对吗),直到我看到论坛有个帖子这段代码注释了
#test_json = json.load(open('../input/test_a.json'))
我顿时才恍然大悟,对呀json是包含了图片的所有信息,是什么数字,位置,长宽等。
如果直接给你json文件岂不是直接给你答案了,我怕不是个傻zi,然后马上把它注释了,顺利执行出来了。然后就会生成结果文件,把它提交了就可以看自己的分数以及排名了。

好了到这里,你已经完成了第一大步(照葫芦画瓢)。
-------------------------------------------分割线--------------------------------------------
第二大步:微调数据
据统计5个数字以及6个数字的图片占比例非常小,所以可以忽略不记,因此代码可以不用进行对第五个和第六个数字预测,
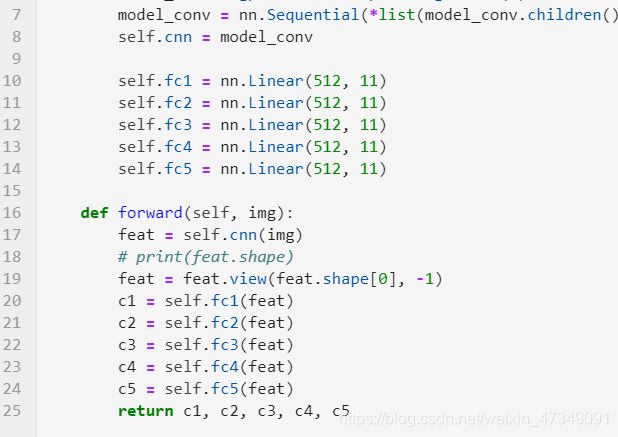
可以对c5进行注释或者删除。后面的代码依次同样处理,都是注释或者删除第五个和第六个就可以了,具体如何操作,大家还是多动动手,难度不大。这里我就不详细说了。
然后我们可以尝试换个优化器,SGD,Adam都很不错的,其它的优化器都可以。要去尝试,我就做了如下操作,换了个优化器,虽然准确率没有提升,但是起码我调参了,哈哈哈。
optimizer=torch.optim.RMSprop(model.parameters(),lr=0.001,alpha=0.9)
做了这一步,貌似目前好像没有什么可以无脑修改了。可以再试着训练然后生成结果提交一波。
--------------------------------------------分割线------------------------------------------
进阶阶段1:
这时候我们可以对数据集进行处理,因为数据太少了,容易过拟合,所以我们可以用数据增强的方法。比如裁剪,中心裁剪,调亮度等等。

这里就是源码进行的操作,可以在这基础上,进行添加自己认为可以的操作。但是因为这个数字识别的任务,所以不要进行旋转操作,本来是6倒过来就变成9了,这样会造成不必要错乱。
然后我们可以进行学习率的调整,比如到第几个epoch就进行调整,比较常用且有效的应该是等间距调整学习率,lr_scheduler,大家可以去查询如何操作,如何添加。多动手
这样搞了之后又尝试输出结果,应该算不错的。我第一次提交就有0.69分了,排145名了。

-------------------------------------------------分割线--------------------------------------
进阶阶段2:
后来进行了几次简单的小修小改,发现准确率基本上不去。然后看到有人提到了标签平滑的策略,然后尝试了确实效果还是挺好的,大家可以去尝试一下,具体如何操作,大家多动动手吧,共勉。
-------------------------------------------------分割线---------------------------------------
进阶阶段3:
这次感觉要对网络下手了,也就是进行优化网络,官方使用的baseline是用resnet18,所以我打算把它换成resnet50
class SVHN_Model2(nn.Module):
def __init__(self):
super(SVHN_Model2, self).__init__()
# resnet18
model_conv = models.resnet50(pretrained=True)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1]) # 去除最后一个fc layer
self.cnn = model_conv
self.hd_fc1 = nn.Linear(512, 128)
self.hd_fc2 = nn.Linear(512, 128)
self.hd_fc3 = nn.Linear(512, 128)
self.hd_fc4 = nn.Linear(512, 128)
self.hd_fc5 = nn.Linear(512, 128)
self.dropout_1 = nn.Dropout(0.25)
self.dropout_2 = nn.Dropout(0.25)
self.dropout_3 = nn.Dropout(0.25)
self.dropout_4 = nn.Dropout(0.25)
self.dropout_5 = nn.Dropout(0.25)
self.fc1 = nn.Linear(128, 11)
self.fc2 = nn.Linear(128, 11)
self.fc3 = nn.Linear(128, 11)
self.fc4 = nn.Linear(128, 11)
self.fc5 = nn.Linear(128, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
feat1 = self.hd_fc1(feat)
feat2 = self.hd_fc2(feat)
feat3 = self.hd_fc3(feat)
feat4 = self.hd_fc4(feat)
feat5 = self.hd_fc5(feat)
feat1 = self.dropout_1(feat1)
feat2 = self.dropout_2(feat2)
feat3 = self.dropout_3(feat3)
feat4 = self.dropout_4(feat4)
feat5 = self.dropout_5(feat5)
c1 = self.fc1(feat1)
c2 = self.fc2(feat2)
c3 = self.fc3(feat3)
c4 = self.fc4(feat4)
c5 = self.fc5(feat5)
return c1, c2, c3, c4,c5
大致的代码就是这样的,但还是存在一点问题,大家需要去修改一下,还是那句话,出现问题自己学着去处理。
好了,目前我就是做了那么多操作,得到最后的分数还是还不错的,下一步可能打算去尝试YOLO网络。

大家一起加油吧,如果有人有思路可以分享的,欢迎在下面交流呀。
知乎:https://zhuanlan.zhihu.com/p/359572604