Redis—大key问题讨论及解决方案
一、问题背景
所谓的bigkey就是存储本身的key值空间太大,或者hash,list,set等存储中value值过多。
主要包括:
1、单个简单的key存储的value很大
2、hash, set,zset,list 中存储过多的元素
3、一个集群存储了上亿的key
bigkey会带来一些问题,如:
1.读写bigkey会导致超时严重,甚至阻塞服务。
2.大key相关的删除或者自动过期时,会出现qps突降或者突升的情况,极端情况下,会造成主从复制异常,Redis服务阻塞无法响应请求。bigkey的体积与删除耗时可参考下表:
| key类型 |
field数量 |
耗时 |
| Hash |
100万 |
1000ms |
| List |
100万 |
1000ms |
| Set |
100万 |
1000ms |
| ZSet |
100万 |
1000ms |
redis 是单线程,操作 bigkey 比较耗时,那么阻塞 redis 的可能性增大。每次获取 bigKey 的网络流量较大,假设一个 bigkey 为 1MB,每秒访问量为 1000,那么每秒产生 1000MB 的流量,对于普通千兆网卡,按照字节算 128M/S 的服务器来说可能扛不住。而且一般服务器采用单机多实例方式来部署,所以还可能对其他实例造成影响。
二、redis单线程模型
1、redis单线程操作过程
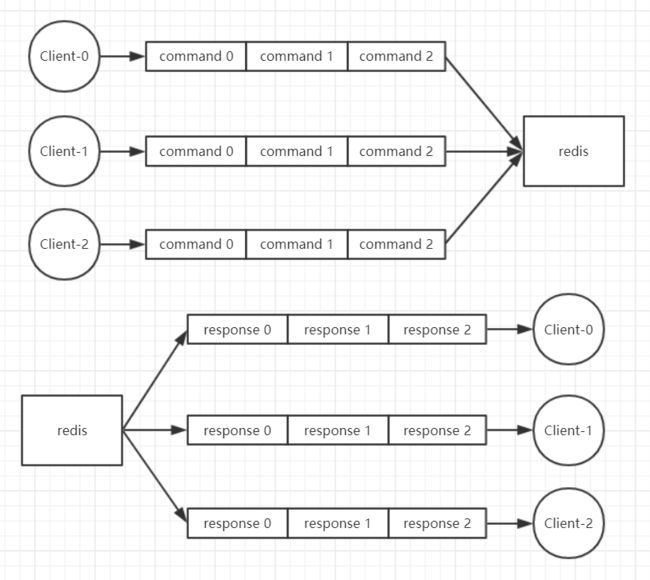
(1)redis 会将每个客户端都关联一个指令队列。客户端的指令通过队列来按顺序处理,先到先服务。
(2)在一个客户端的指令队列中的指令是顺序执行的,但是多个指令队列中的指令是无法保证顺序的。
(3)redis 同样也会为每个客户端关联一个响应队列,通过响应队列来顺序地将指令的返回结果回复给客户端。
(4)一个响应队列中的消息可以顺序的回复给客户端,多个响应队列之间是无法保证顺序的。
(5)所有的客户端的队列中的指令或者响应,redis 每次都只能处理一个,同一时间绝对不会处理超过一个指令或者响应。
2、redis内部操作过程
redis基于Reactor模式开发了自己的网络事件处理器,
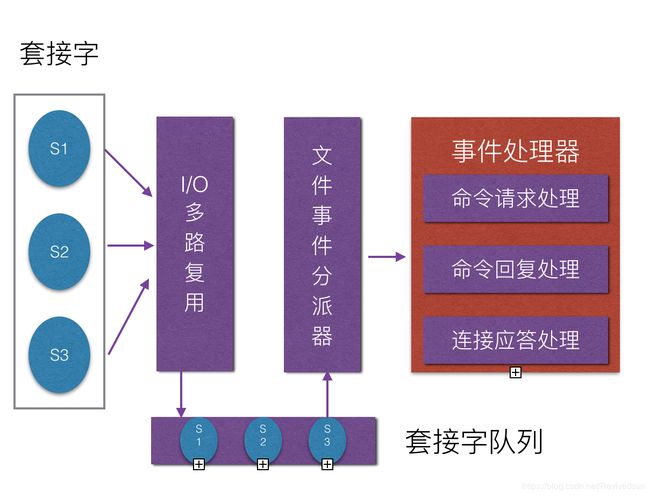
Redis通过socket与客户端进行连接,并将服务器对socket的操作抽象为文件事件。redis通过单线程,并通过I/O多路复用来处理来自客户端的多个连接请求,当产生连接后,i/o多路复用程序,会将产生事件的套接字放置一个队列,通过队列以有序、同步的、每次一个套接字的方式向文件事件分派发器传送套接字。当上一个套接字的事件被处理完毕后,I/O多路复用才会向文件分派器传送下一个套接字。服务端通过监听这些事件,并完成相应的处理。被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作,与操作相关的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
三、对于bigkey常用的解决办法
1、单个简单的key存储的value很大
(1)对象需要每次都整存整取
可以尝试将对象分拆成几个key-value, 使用multiGet获取值,这样分拆的意义在于分拆单次操作的压力,将操作压力平摊到多个redis实例中,降低对单个redis的IO影响;
(2)该对象每次只需要存取部分数据
可以像第一种做法一样,分拆成几个key-value, 也可以将这个存储在一个hash中,每个field代表一个具体的属性,使用hget,hmget来获取部分的value,使用hset,hmset来更新部分属性
2、 hash, set,zset,list 中存储过多的元素
可以对存储元素按一定规则进行分类,分散存储到多个redis实例中。
对于一些榜单类的场景,用户一般只会访问前几百及后几百条数据,可以只缓存前几百条以及后几百条,即对用户经常访问的数据做缓存(正序倒序的前几页),而不是全部都做,对于获取中间的数据则可以直接从数据库获取
3、一个集群存储了上亿的key
如果key的个数过多会带来更多的内存空间占用,
1.key本身的占用。
2.集群模式中,服务端有时需要建立一些slot2key的映射关系,这其中的指针占用在key多的情况下也是浪费巨大空间。
所以减少key的个数可以减少内存消耗,可以参考的方案是转Hash结构存储,即原先是直接使用Redis String 的结构存储,现在将多个key存储在一个Hash结构中
对缓存操作的改善可以利用pipeline管道
拆分之后可以考虑采用pipeline去取,由于redis是单线程的,一次只能执行一个命令,这里采用Pipeline模式,一次发送多个命令,无需等待服务端返回。这样就大大的减少了网络往返时间,提高了系统性能。
四、集思广益
大家有没有什么更好的解决方案呢?欢迎留言评论