Hive 常用DML操作
一、加载文件数据到表
1.1 语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE]
INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOCAL关键字代表从本地文件系统加载文件,省略则代表从 HDFS 上加载文件:
-
从本地文件系统加载文件时,
filepath可以是绝对路径也可以是相对路径 (建议使用绝对路径); -
从 HDFS 加载文件时候,
filepath为文件完整的 URL 地址:如hdfs://namenode:port/user/hive/project/ data1
-
filepath可以是文件路径 (在这种情况下 Hive 会将文件移动到表中),也可以目录路径 (在这种情况下,Hive 会将该目录中的所有文件移动到表中); -
如果使用 OVERWRITE 关键字,则将删除目标表(或分区)的内容,使用新的数据填充;不使用此关键字,则数据以追加的方式加入;
-
加载的目标可以是表或分区。如果是分区表,则必须指定加载数据的分区;
-
加载文件的格式必须与建表时使用
STORED AS指定的存储格式相同。
使用建议:
不论是本地路径还是 URL 都建议使用完整的。虽然可以使用不完整的 URL 地址,此时 Hive 将使用 hadoop 中的 fs.default.name 配置来推断地址,但是为避免不必要的错误,建议使用完整的本地路径或 URL 地址;
加载对象是分区表时建议显示指定分区。在 Hive 3.0 之后,内部将加载 (LOAD) 重写为 INSERT AS SELECT,此时如果不指定分区,INSERT AS SELECT 将假设最后一组列是分区列,如果该列不是表定义的分区,它将抛出错误。为避免错误,还是建议显示指定分区。
1.2 示例
新建分区表:
CREATE TABLE emp_ptn(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
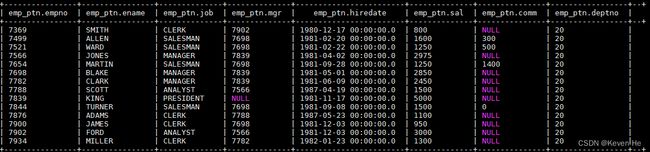
从 HDFS 上加载数据到分区表:
LOAD DATA INPATH "hdfs://hadoop001:8020/mydir/emp.txt" OVERWRITE INTO TABLE emp_ptn PARTITION (deptno=20);
emp.txt 文件可在本仓库的 resources 目录中下载
加载后表中数据如下,分区列 deptno 全部赋值成 20:
二、查询结果插入到表
2.1 语法
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]]
select_statement1 FROM from_statement;
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1 FROM from_statement;
-
Hive 0.13.0 开始,建表时可以通过使用 TBLPROPERTIES(“immutable”=“true”)来创建不可变表 (immutable table) ,如果不可以变表中存在数据,则 INSERT INTO 失败。(注:INSERT OVERWRITE 的语句不受
immutable属性的影响); -
可以对表或分区执行插入操作。如果表已分区,则必须通过指定所有分区列的值来指定表的特定分区;
-
从 Hive 1.1.0 开始,TABLE 关键字是可选的;
-
从 Hive 1.2.0 开始 ,可以采用 INSERT INTO tablename(z,x,c1) 指明插入列;
-
可以将 SELECT 语句的查询结果插入多个表(或分区),称为多表插入。语法如下:
FROM from_statement INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 [INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2] [INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] ...;
2.2 动态插入分区
INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...)
select_statement FROM from_statement;
INSERT INTO TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...)
select_statement FROM from_statement;
在向分区表插入数据时候,分区列名是必须的,但是列值是可选的。如果给出了分区列值,我们将其称为静态分区,否则它是动态分区。动态分区列必须在 SELECT 语句的列中最后指定,并且与它们在 PARTITION() 子句中出现的顺序相同。
注意:Hive 0.9.0 之前的版本动态分区插入是默认禁用的,而 0.9.0 之后的版本则默认启用。以下是动态分区的相关配置:
| 配置 | 默认值 | 说明 |
|---|---|---|
hive.exec.dynamic.partition |
true |
需要设置为 true 才能启用动态分区插入 |
hive.exec.dynamic.partition.mode |
strict |
在严格模式 (strict) 下,用户必须至少指定一个静态分区,以防用户意外覆盖所有分区,在非严格模式下,允许所有分区都是动态的 |
hive.exec.max.dynamic.partitions.pernode |
100 | 允许在每个 mapper/reducer 节点中创建的最大动态分区数 |
hive.exec.max.dynamic.partitions |
1000 | 允许总共创建的最大动态分区数 |
hive.exec.max.created.files |
100000 | 作业中所有 mapper/reducer 创建的 HDFS 文件的最大数量 |
hive.error.on.empty.partition |
false |
如果动态分区插入生成空结果,是否抛出异常 |
2.3 示例
- 新建 emp 表,作为查询对象表
CREATE TABLE emp(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
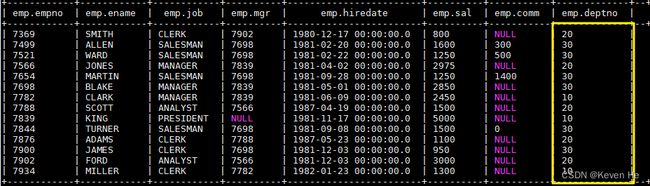
-- 加载数据到 emp 表中 这里直接从本地加载
load data local inpath "/usr/file/emp.txt" into table emp;
完成后 emp 表中数据如下:
- 为清晰演示,先清空
emp_ptn表中加载的数据:
TRUNCATE TABLE emp_ptn;
- 静态分区演示:从
emp表中查询部门编号为 20 的员工数据,并插入emp_ptn表中,语句如下:
INSERT OVERWRITE TABLE emp_ptn PARTITION (deptno=20)
SELECT empno,ename,job,mgr,hiredate,sal,comm FROM emp WHERE deptno=20;
完成后 emp_ptn 表中数据如下:

- 接着演示动态分区:
-- 由于我们只有一个分区,且还是动态分区,所以需要关闭严格默认。因为在严格模式下,用户必须至少指定一个静态分区
set hive.exec.dynamic.partition.mode=nonstrict;
-- 动态分区 此时查询语句的最后一列为动态分区列,即 deptno
INSERT OVERWRITE TABLE emp_ptn PARTITION (deptno)
SELECT empno,ename,job,mgr,hiredate,sal,comm,deptno FROM emp WHERE deptno=30;
完成后 emp_ptn 表中数据如下:

三、使用SQL语句插入值
INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)]
VALUES ( value [, value ...] )
- 使用时必须为表中的每个列都提供值。不支持只向部分列插入值(可以为缺省值的列提供空值来消除这个弊端);
- 如果目标表表支持 ACID 及其事务管理器,则插入后自动提交;
- 不支持支持复杂类型 (array, map, struct, union) 的插入。
四、更新和删除数据
4.1 语法
更新和删除的语法比较简单,和关系型数据库一致。需要注意的是这两个操作都只能在支持 ACID 的表,也就是事务表上才能执行。
-- 更新
UPDATE tablename SET column = value [, column = value ...] [WHERE expression]
--删除
DELETE FROM tablename [WHERE expression]
4.2 示例
1. 修改配置
首先需要更改 hive-site.xml,添加如下配置,开启事务支持,配置完成后需要重启 Hive 服务。
<property>
<name>hive.support.concurrencyname>
<value>truevalue>
property>
<property>
<name>hive.enforce.bucketingname>
<value>truevalue>
property>
<property>
<name>hive.exec.dynamic.partition.modename>
<value>nonstrictvalue>
property>
<property>
<name>hive.txn.managername>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManagervalue>
property>
<property>
<name>hive.compactor.initiator.onname>
<value>truevalue>
property>
<property>
<name>hive.in.testname>
<value>truevalue>
property>
2. 创建测试表
创建用于测试的事务表,建表时候指定属性 transactional = true 则代表该表是事务表。需要注意的是,按照官方文档 的说明,目前 Hive 中的事务表有以下限制:
- 必须是 buckets Table;
- 仅支持 ORC 文件格式;
- 不支持 LOAD DATA …语句。
CREATE TABLE emp_ts(
empno int,
ename String
)
CLUSTERED BY (empno) INTO 2 BUCKETS STORED AS ORC
TBLPROPERTIES ("transactional"="true");
3. 插入测试数据
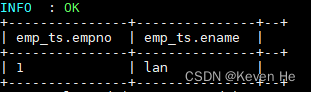
INSERT INTO TABLE emp_ts VALUES (1,"ming"),(2,"hong");
插入数据依靠的是 MapReduce 作业,执行成功后数据如下:

4. 测试更新和删除
--更新数据
UPDATE emp_ts SET ename = "lan" WHERE empno=1;
--删除数据
DELETE FROM emp_ts WHERE empno=2;
更新和删除数据依靠的也是 MapReduce 作业,执行成功后数据如下:
五、查询结果写出到文件系统
5.1 语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...
-
OVERWRITE 关键字表示输出文件存在时,先删除后再重新写入;
-
和 Load 语句一样,建议无论是本地路径还是 URL 地址都使用完整的;
-
写入文件系统的数据被序列化为文本,其中列默认由^A 分隔,行由换行符分隔。如果列不是基本类型,则将其序列化为 JSON 格式。其中行分隔符不允许自定义,但列分隔符可以自定义,如下:
-- 定义列分隔符为'\t' insert overwrite local directory './test-04' row format delimited FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ',' MAP KEYS TERMINATED BY ':' select * from src;
5.2 示例
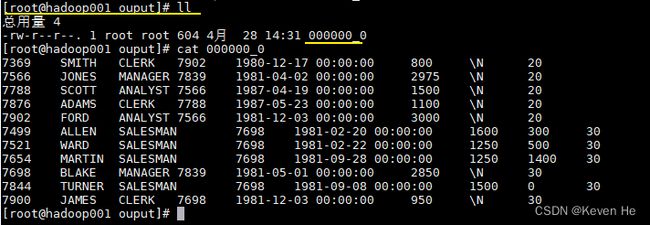
这里我们将上面创建的 emp_ptn 表导出到本地文件系统,语句如下:
INSERT OVERWRITE LOCAL DIRECTORY '/usr/file/ouput'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
SELECT * FROM emp_ptn;
导出结果如下: