机器学习(四)朴素贝叶斯算法
目录
1 贝叶斯定理
1.1 贝叶斯定理有什么用
1.2贝叶斯公式
2.朴素贝叶斯分类器
2.1 朴素贝叶斯公式
2.2拉普拉斯修正
2.3防溢出策略
3.朴素贝叶斯算法实例-过滤垃圾邮件
3.1问题分析
3.2代码实现
3.2.1 准备数据
3.2.2训练算法:从词向量计算概率
3.2.3朴素贝叶斯分类器实现
3.2.4 垃圾邮件邮件分类实现
3.3.实验总结
1 贝叶斯定理
1.1 贝叶斯定理有什么用
假设现在有一个装了7个小球的盒子,其中三个是白色的,四个是黑色的。如果从盒子中随机取出一个小球,那么是白球的可能性是多少,根据概率计算公式,我们很容易得出取到白球的概率为3/7。
那如果我们并不知道盒子里有什么,而是摸出一个球,通过观察这个球的颜色,是否可以预测这个盒子里白色球和黑色球的概率。贝叶斯定理正是解决这种“逆概率”的问题。
贝叶斯定理的作用就是在有限的信息下,能够帮助我们预测出概率。
贝叶斯定理在生活中的应用有很多,如天气预报说明天下雨的概率是50%,这个50%是怎么得到的,我们无法想计算频率概率那样,重复地把明天过上100次,算出大约有50次会下雨,而是只能利用过去天气测量数据,用贝叶斯定理可以预测出明天下雨的概率是多少。
1.2贝叶斯公式
贝叶斯公式: ![]()
先验概率P(A):先验概率是指根据以往经验和分析得到的概率,即一般情况下,认为A发生的概率
似然度P(B|A): A假设条件成立的情况下发生B的概率
后验概率P(A|B):表示事件B已经发生的前提下,事件A发生的概率。
贝叶斯公式背后的思想就是根据以往的的经验先预估一个“先验概率”P(A),然后加入新的信息(实验结果B),这样有了新的信息后,我们对事件A的预测更加准确
2.朴素贝叶斯分类器
朴素贝叶斯算法是基于贝叶斯定理与特征条件独立假设的分类方法。就文本分类而言,它认为词袋中的两两词之间的关系是相互独立的,即一个对象的特征向量中每个维度都是相互独立的
2.1 朴素贝叶斯公式
朴素:朴素贝叶斯算法是假设各个特征之间相互独立,那么贝叶斯公式中的P(X|Y)可写成:
![]()
朴素贝叶斯公式:
![]()
朴素贝叶斯分类器:朴素贝叶斯分类器采用了“属性条件独立性假设” ,即每个属性独立地对分类结果发生影响。记P(C=c|X=x)为P(c|x),基于属性条件独立性假设,贝叶斯公式可重写为:

其中d为属性数目, 为
为  在第
在第  个属性上的取值。
个属性上的取值。
朴素贝叶斯分类器的训练器的训练过程就是基于训练集D 估计类先验概率 P ( c ) ,并为每个属性估计条件概率 。
2.2拉普拉斯修正
若某个属性值在训练集中没有与某个类同时出现过,则训练后的模型会出现 over-fitting 现象。比如训练集中没有该样例,因此连乘后计算的概率值为0。所以为了避免其他属性携带的信息,被训练集中未出现的属性值“抹去”,在估计概率值时通常要进行“拉普拉斯修正”
贝叶斯公式可修正为:
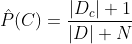
其中N 表示训练集 D 中可能的类别数, 表示第i个属性可能的取值数
表示第i个属性可能的取值数
2.3防溢出策略
条件概率乘法计算过程中,因子一般较小(均是小于1 的实数)。当属性数量增多时候,会导致累乘结果下溢出的现象。 在代数中有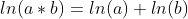 ,因此可以把条件概率累乘转化成对数累加。分类结果仅需对比概率的对数累加法运算后的数值,以确定划分的类别。
,因此可以把条件概率累乘转化成对数累加。分类结果仅需对比概率的对数累加法运算后的数值,以确定划分的类别。

3.朴素贝叶斯算法实例-过滤垃圾邮件
3.1问题分析
假设有一家科技公司,公司邮箱每天会收到一堆邮件,其中有正常邮件(ham),也有垃圾邮件(spam),如果现在有一封新的邮件到来,这封邮件中包含technology单词,那这封邮件是垃圾邮件的概率。
假设现在有500封正常邮件,200封垃圾邮件,检查一下所有的邮件,发现垃圾邮件中含有单词technology的有10封,正常邮件中含有technology的邮件有125封,那么
![]()
![]()
![]()
![]()
![]()
![]()
如果只考虑单词technology,我们有89%的把握认为这是一份正常文件。
实际情况是,一份邮件通常包含大量的单词,我们就需要计算给定单词向量,这份邮件是正常邮件的概率。此时就需要用到朴素贝叶斯算法了,具体实现及代码如下。
3.2代码实现
3.2.1 准备数据
我们把文本看成单词向量或者词条向量,也就是说将句子转换为向量。考虑出现在所有文档中的所有单词,再决定将哪些词纳入词汇表或者说所要的词汇集合,然后必须要将每一篇文档转换为词汇表上的向量。
# 创建不重复词的列表 ———— 词汇表
def createVocabList(dataSet):
vocabSet = set([]) # 创建一个空集
for document in dataSet:
vocabSet = vocabSet | set(document) # 创建两个集合的并集
return list(vocabSet) # 返回不重复的词条列表
# 输出文档向量
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) # 创建一个其中所含元素都为0的向量
for word in inputSet: # 遍历文档中的所有单词
if word in vocabList: # 如果出现了词汇表中的单词,则将输出的文档向量中的对应值设为1
returnVec[vocabList.index(word)] = 1
else:
print("单词 %s 不在词汇表中!" % word)
return returnVec测试函数效果:
# 创建实验样本
def loadDataSet():
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1] # 标签向量,1表示侮辱性文字,0表示正常言论
return postingList, classVec
# 创建实验样本
listPosts, listClasses = loadDataSet()
print('数据集\n', listPosts)
# 创建词汇表
myVocabList = createVocabList(listPosts)
print('词汇表:\n', myVocabList)
# 输出文档向量
print(setOfWords2Vec(myVocabList, listPosts[5])) 运行效果如图所示:

文档词袋模型:
将每个词的出现与否作为一个特征,这可以被描述为词集模型。如果一个词在文档中出现不止一次,这可能意味着包含该词是否出现在文档中所不能表达的某种信息,这种方法被称为词袋模型。在词袋中,每个单词可以出现多次,而在词集中,每个词只能出现一次。为适应词袋模型,需要对函数setOfWords2Vec() 稍加修改,修改后的函数称为bagOfWords2Vec()。
# 朴素贝叶斯词袋模型
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1 # 加1
return returnVec3.2.2训练算法:从词向量计算概率
该函数的伪代码如下:
计算每个类别中的文档数目
对每篇训练文档:
对每个类别:
如果词条出现在文档中→ 增加该词条的计数值
增加所有词条的计数值
对每个类别:
对每个词条:
将该词条的数目除以总词条数目得到条件概率
返回每个类别的条件概率
代码实现如下:
# 朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix) # 获得训练的文档总数
numWords = len(trainMatrix[0]) # 获得每篇文档的词总数
pAbusive = sum(trainCategory) / float(numTrainDocs) # 计算文档是侮辱类的概率
p0Num = zeros(numWords) # 创建numpy.zeros数组,初始化概率
p1Num = zeros(numWords) # 创建numpy.zeros数组,初始化概率
p0Denom = 0.0 # 初始化为0
p1Denom = 0.0 # 初始化为0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i] # 向量相加,统计侮辱类的条件概率的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i] # 向量相加,统计非侮辱类的条件概率的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num / p1Denom # 侮辱类,每个元素除以该类别中的总词数
p0Vect = p0Num / p0Denom # 非侮辱类,每个元素除以该类别中的总词数
return p0Vect, p1Vect, pAbusive # p0Vect非侮辱类的条件概率数组、p1Vect侮辱类的条件概率数组、pAbusive文档属于侮辱类的概率测试代码如下:
# 测试代码
listPosts, listClasses = loadDataSet() # 创建实验样本
myVocabList = createVocabList(listPosts) # 创建词汇表
trainMat = []
for postinDoc in listPosts: # for循环使用词向量来填充trainMat列表
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V, p1V, pAb = trainNB0(trainMat, listClasses)
print('p0V:\n', p0V)
print('p1V:\n', p1V)
print('pAb:\n', pAb)
p0V存放的是属于类别0的各单词的条件概率,即各个单词属于非侮辱类的条件概率;p1V存放的是属于类别1的各单词的条件概率,即各个单词属于侮辱类的条件概率。pAb是所有侮辱类的样本占所有样本的概率
3.2.3朴素贝叶斯分类器实现
# 朴素贝叶斯分类器分类函数
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) # 元素相乘,侮辱类概率
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) # 非侮辱类概率
if p1 > p0:
return 1
else:
return 03.2.4 垃圾邮件邮件分类实现
数据集说明:一共有40份邮件,其中20份为垃圾邮件,20份为非垃圾邮件。其中非垃圾邮件中设置的内容是从与科技相关的英语作文中摘录的,垃圾邮件中内容是随意在网上找的英语作文。其中的10封电子邮件被随机选择为测试集。
非垃圾邮件:

垃圾邮件:

垃圾邮件分类实现代码:
# 文件解析
def textParse(bigString): # 输入字符串, 输出单词列表
import re
listOfTokens = re.split(r'[\W*]', bigString) # 字符串切分,去掉除单词、数字外的任意字符串
return [tok.lower() for tok in listOfTokens if len(tok) > 2] # 除了单个字母外,其他字符串全部转换成小写# 完整的垃圾邮件测试函数
def spamTest():
docList = [] # 文档列表
classList = [] # 文档标签
fullText = [] # 全部文档内容集合
for i in range(1, 21): # 遍历垃圾邮件和非垃圾邮件各25个
wordList = textParse(open('D:/syy/MachineLearning/data/email/spam/%d.txt' % i,encoding='utf-8').read()) # 读取垃圾邮件,并生成单词向量
docList.append(wordList) # 垃圾邮件加入文档列表
fullText.extend(wordList) # 把当前垃圾邮件加入文档内容集合
classList.append(1) # 1表示垃圾邮件,标记垃圾邮件
wordList = textParse(open('D:/syy/MachineLearning/data/email/ham/%d.txt' % i,encoding='utf-8').read()) # 读非垃圾邮件,并生成单词向量
docList.append(wordList) # 非垃圾邮件加入文档列表
fullText.extend(wordList) # 把当前非垃圾邮件加入文档内容集合
classList.append(0) # 0表示垃圾邮件,标记非垃圾邮件,
vocabList = createVocabList(docList) # 创建不重复的词汇表
trainingSet = list(range(40)) # 为训练集添加索引
testSet = [] # 创建测试集
for i in range(10): # 目的为了从50个邮件中,随机挑选出40个作为训练集,10个做测试集
randIndex = int(random.uniform(0, len(trainingSet))) # 随机产生索引
testSet.append(trainingSet[randIndex]) # 添加测试集的索引值
del (trainingSet[randIndex]) # 在训练集中,把加入测试集的索引删除
trainMat = [] # 创建训练集矩阵训练集类别标签系向量
trainClasses = [] # 训练集类别标签
for docIndex in trainingSet: # for循环使用词向量来填充trainMat列表t
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) # 把词集模型添加到训练矩阵中
trainClasses.append(classList[docIndex]) # 把类别添加到训练集类别标签中
p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses)) # 朴素贝叶斯分类器训练函数
print('词表:\n', vocabList)
print('p0V:\n', p0V)
print('p1V:\n', p1V)
print('pSpam:\n', pSpam)
errorCount = 0 # 用于计数错误分类
for docIndex in testSet: # 循环遍历训练集
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]) # 获得测试集的词集模型
if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
errorCount += 1 # 预测值和真值不一致,则错误分类计数加1
print("分类错误集", docList[docIndex])
print('错误率: ', float(errorCount) / len(testSet))运行结果如下:

3.3.实验总结
朴素贝叶斯的算法逻辑实现简单,易于实现,在属性相关性小的时候,性能较为良好。
但在实际中,朴素贝叶斯模型的分类误差不一定比其他分类方法小,因为朴素贝叶斯模型设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
完整代码链接:
链接:https://pan.baidu.com/s/1ZuFF-7mNgfRNfQxeIIRwag
提取码:0m64